Recognition: no theorem link
SeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
Pith reviewed 2026-05-13 07:40 UTC · model grok-4.3
The pith
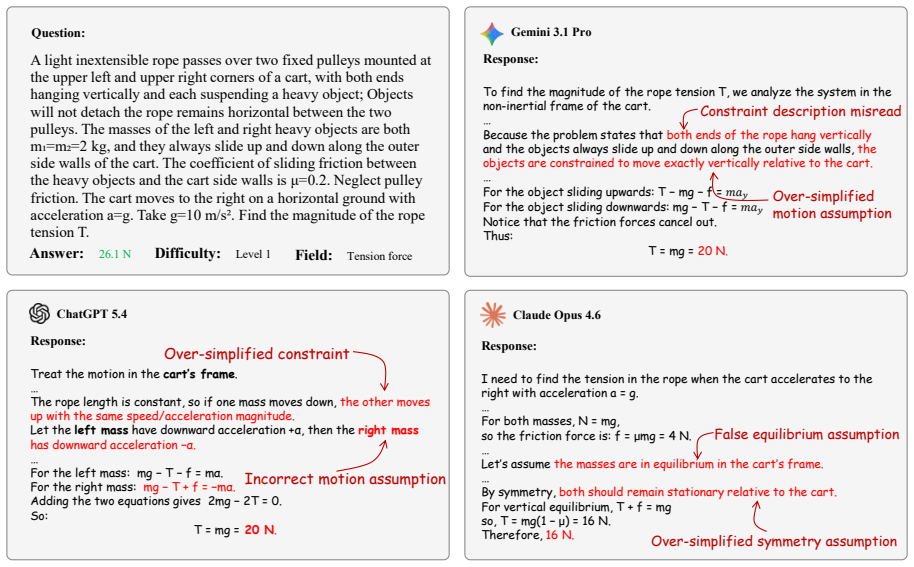
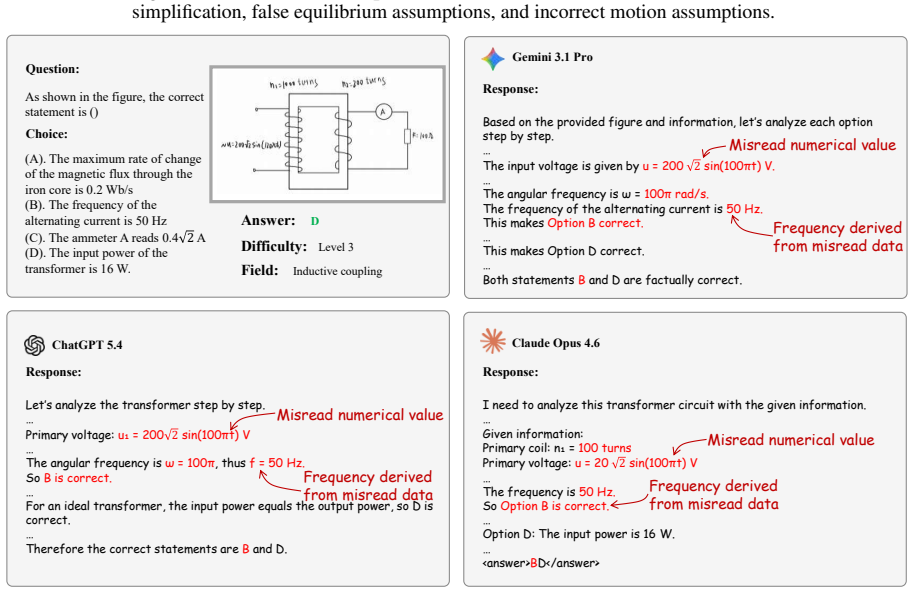
Frontier models lose physics reasoning ability as problems shift from text to diagrams, mainly from failures to ground visual variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
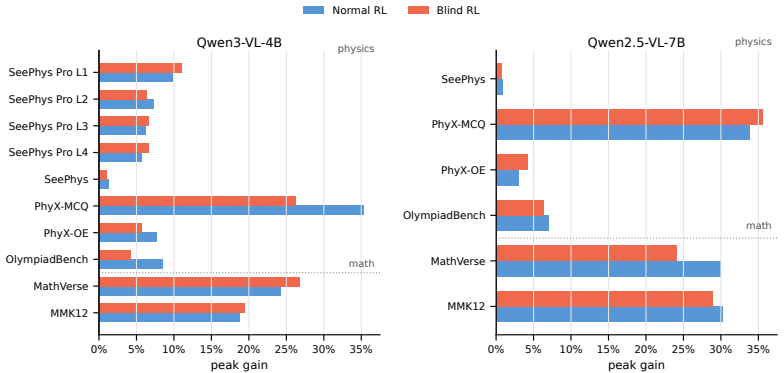
The paper establishes that current frontier multimodal models are not representation-invariant reasoners: their performance on physics reasoning degrades on average as critical information is transferred from language to diagrams, with visual variable grounding as the dominant bottleneck. It further shows that large-scale multimodal RLVR training can produce gains on unmasked validation sets even when all training images are masked, and that these gains survive only because of residual textual and distributional cues rather than reliance on task-critical visual content.
What carries the argument
SeePhys Pro's set of four semantically aligned problem variants per question, constructed to increase visual content in controlled steps while holding semantics fixed.
If this is right
- Multimodal evaluation must measure robustness under controlled modality transfer rather than accuracy alone.
- RLVR gains observed on standard tests can occur without the model using the visual portions of the input.
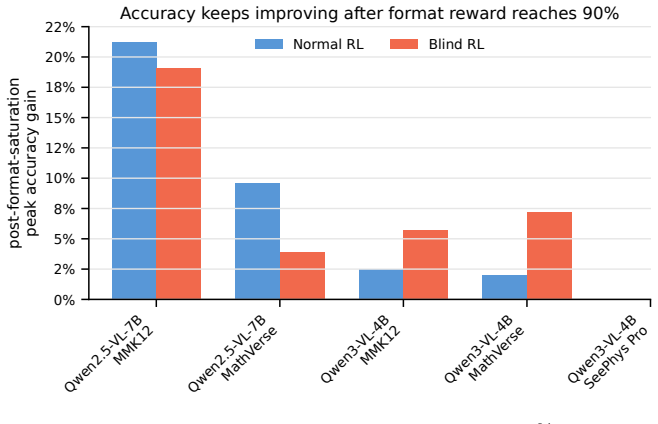
- Text-deletion, image-mask-rate, and format-saturation controls are necessary to confirm that training improvements depend on task-critical visual evidence.
- Representation invariance should become a standard requirement when claiming progress in multimodal physics reasoning.
Where Pith is reading between the lines
- Training pipelines may need explicit penalties for shortcuts that ignore visual content to force genuine cross-modal use.
- The same progressive-modality design could be extended to geometry or chemistry problems to test whether the grounding bottleneck is domain-specific.
- Architectures that add explicit alignment losses between text descriptions and diagram elements could be tested as a direct response to the observed fragility.
Load-bearing premise
The four variants of each problem are equivalent in difficulty and free of unintended cues that models might exploit differently depending on the version.
What would settle it
A result in which masked-image blind training produces no accuracy lift on unmasked validation once text-deletion controls have removed all residual language signals would falsify the claim that gains come from non-visual cues.
Figures













read the original abstract
We introduce SeePhys Pro, a fine-grained modality transfer benchmark that studies whether models preserve the same reasoning capability when critical information is progressively transferred from text to image. Unlike standard vision-essential benchmarks that evaluate a single input form, SeePhys Pro features four semantically aligned variants for each problem with progressively increasing visual elements. Our evaluation shows that current frontier models are far from representation-invariant reasoners: performance degrades on average as information moves from language to diagrams, with visual variable grounding as the most critical bottleneck. Motivated by this inference-time fragility, we further develop large training corpora for multimodal RLVR and use blind training as a diagnostic control, finding that RL with all training images masked can still improve performance on unmasked validation sets. To analyze this effect, text-deletion, image-mask-rate, and format-saturation controls suggest that such gains can arise from residual textual and distributional cues rather than valid visual evidence. Our results highlight the need to evaluate multimodal reasoning not only by final-answer accuracy, but also by robustness under modality transfer and by diagnostics that test whether improvements rely on task-critical visual evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SeePhys Pro, a fine-grained benchmark for physics reasoning consisting of problems with four semantically aligned variants that progressively transfer critical information from text to diagrams. Frontier models exhibit average performance degradation under this modality shift, with visual variable grounding identified as the primary bottleneck. The authors further construct multimodal RLVR training corpora and apply blind-training (image-masked) controls, showing that validation gains can arise from residual textual and distributional cues rather than task-critical visual evidence, as diagnosed via text-deletion, image-mask-rate, and format-saturation experiments.
Significance. If the results hold after validation of variant equivalence, the work would be significant for multimodal reasoning research. It supplies a diagnostic benchmark that directly tests representation invariance and exposes limitations in current RLVR pipelines that may exploit spurious cues. The combination of modality-transfer evaluation with blind-training controls offers a concrete methodology for distinguishing genuine visual reasoning from artifact-driven gains, which could influence evaluation standards in vision-language models for scientific domains.
major comments (2)
- [§3] §3 (Benchmark Construction): The central degradation claim requires that the four variants per problem are equivalent in intrinsic difficulty and free of differential cues. The manuscript describes them as 'semantically aligned' but reports no quantitative equivalence checks (human difficulty ratings, expert review, or cross-variant correlation), which is load-bearing for attributing drops to modality transfer rather than unintended hardness differences.
- [§4.2] §4.2 (Blind-Training Diagnostics): The conclusion that RLVR gains under masked images arise from residual cues rather than valid visual evidence depends on the text-deletion, image-mask-rate, and format-saturation controls. Without reported dataset sizes, statistical tests, or exclusion criteria for these controls, it is unclear whether the isolation of non-visual factors is robust enough to support the claim.
minor comments (2)
- [Abstract] Abstract: Specific numerical effect sizes, model identifiers, and total problem counts are omitted, which would allow immediate assessment of practical significance.
- [Figure 1] Figure 1 or equivalent: The progressive visual-element transfer across variants would benefit from an explicit side-by-side example with annotations for each modality level to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of rigor in benchmark validation and experimental controls, which we address point by point below. We will incorporate the suggested additions in the revised version.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The central degradation claim requires that the four variants per problem are equivalent in intrinsic difficulty and free of differential cues. The manuscript describes them as 'semantically aligned' but reports no quantitative equivalence checks (human difficulty ratings, expert review, or cross-variant correlation), which is load-bearing for attributing drops to modality transfer rather than unintended hardness differences.
Authors: We agree that quantitative equivalence validation is essential to confidently attribute performance degradation to modality transfer. While the variants were designed by physics experts to maintain semantic alignment and equivalent reasoning demands, the original manuscript did not report formal checks. In the revision, we will add a human study with expert difficulty ratings (on a 5-point scale) for a random subset of 150 problems, report inter-rater reliability (Cohen's kappa), and include cross-variant Pearson correlations of model accuracies to demonstrate equivalence. These additions will directly support the central claim. revision: yes
-
Referee: [§4.2] §4.2 (Blind-Training Diagnostics): The conclusion that RLVR gains under masked images arise from residual cues rather than valid visual evidence depends on the text-deletion, image-mask-rate, and format-saturation controls. Without reported dataset sizes, statistical tests, or exclusion criteria for these controls, it is unclear whether the isolation of non-visual factors is robust enough to support the claim.
Authors: We acknowledge that greater transparency on the control experiments is needed to substantiate the isolation of non-visual factors. The original submission summarized the controls without full numerical and statistical details. In the revised manuscript, we will explicitly report the dataset sizes for each control (text-deletion, image-mask-rate, format-saturation), include statistical significance tests (paired t-tests with p-values and effect sizes), and detail the exclusion criteria applied during corpus construction. These updates will strengthen the evidence that gains stem from residual cues. revision: yes
Circularity Check
No circularity: empirical benchmark and controls are self-contained
full rationale
The paper's central claims rest on direct empirical comparisons across four semantically aligned problem variants and on blind-training diagnostic experiments with text-deletion and mask-rate controls. No equations, fitted parameters, or predictions are defined in terms of the target quantities; the modality-transfer degradation and residual-cue findings are measured outcomes rather than reductions to inputs by construction. Any self-citations are incidental and not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. Introducing Claude 4. https://www.anthropic.com/news/claude-4, 2025. Accessed 2026-05-05
work page 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, et al. Qwen3-VL technical re- port.arXiv preprint arXiv:2511.21631, 2025. URL https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025. doi: 10.48550/arXiv.2502.13923. URL https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[4]
Song Dai, Yibo Yan, Jiamin Su, Dongfang Zihao, Yubo Gao, et al. PhysicsArena: The first multimodal physics reasoning benchmark exploring variable, process, and solution dimensions. arXiv preprint arXiv:2505.15472, 2025. doi: 10.48550/arXiv.2505.15472. URL https: //arxiv.org/abs/2505.15472
-
[5]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. DeepSeek-V3.2. https://arxiv.org/abs/2512.02556, 2025. Accessed 2026-05-05
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. doi: 10.48550/arXiv.2312.11805. URL https://arxiv.org/abs/ 2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[7]
Google DeepMind. Gemma open models. https://deepmind.google/models/gemma/,
-
[8]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, et al. Olympiad- Bench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 3828–3850, Bangkok, Thailand, August
-
[9]
URL https://aclanthology.org/2024
Association for Computational Linguistics. URL https://aclanthology.org/2024. acl-long.211/
work page 2024
-
[10]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, et al. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
work page 2023
-
[11]
Chengzhi Liu, Zhongxing Xu, Qingyue Wei, Juncheng Wu, James Zou, et al. More thinking, less seeing? assessing amplified hallucination in multimodal reasoning models.arXiv preprint arXiv:2505.21523, 2025. doi: 10.48550/arXiv.2505.21523. URL https://arxiv.org/abs/ 2505.21523
-
[12]
Hilbert’s sixth problem: derivation of fluid equations via Boltzmann’s kinetic theory,
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, et al. Visual-RFT: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. doi: 10.48550/arXiv.2503. 01785. URLhttps://arxiv.org/abs/2503.01785
-
[13]
LMMS-Eval: Evaluation Suite for Large Multimodal Models
LMMS-Eval Contributors. LMMS-Eval: Evaluation Suite for Large Multimodal Models. https://github.com/EvolvingLMMs-Lab/lmms-eval, 2024. Accessed 2026-05-05
work page 2024
-
[14]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, et al. Learn to explain: Multimodal reasoning via thought chains for science question answering. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[15]
MathVista: Evaluating math- ematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, et al. MathVista: Evaluating math- ematical reasoning of foundation models in visual contexts. InProceedings of the International Conference on Learning Representations, 2024
work page 2024
-
[16]
Mathpix: Document conversion done right
Mathpix. Mathpix: Document conversion done right. https://mathpix.com/, 2026. Ac- cessed 2026-05-07. 10
work page 2026
-
[17]
MMK12-Test: A multimodal K-12 mathematics evaluation set
Fanqing Meng. MMK12-Test: A multimodal K-12 mathematics evaluation set. https:// huggingface.co/datasets/FanqingM/MMK12, 2024. Hugging Face dataset card, accessed 2026-05-05
work page 2024
-
[18]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, et al. MM-Eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365, 2025. doi: 10.48550/arXiv.2503.07365. URL https://arxiv. org/abs/2503.07365
- [19]
-
[20]
OpenAI. GPT-5 system card. https://cdn.openai.com/gpt-5-system-card.pdf , 2025. Accessed 2026-05-05
work page 2025
- [21]
-
[22]
Li Puyin, Tiange Xiang, Ella Mao, Shirley Wei, Xinye Chen, et al. QuantiPhy: A quantitative benchmark evaluating physical reasoning abilities of vision-language models.arXiv preprint arXiv:2512.19526, 2025. doi: 10.48550/arXiv.2512.19526. URL https://arxiv.org/abs/ 2512.19526
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, et al. DeepSeekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Phyx: Does your model have the” wits” for physical reasoning?arXiv preprint arXiv:2505.15929, 2025
Hui Shen, Taiqiang Wu, Qi Han, Yunta Hsieh, Jizhou Wang, et al. PhyX: Does your model have the “Wits” for physical reasoning?arXiv preprint arXiv:2505.15929, 2025. URL https://arxiv.org/abs/2505.15929
- [25]
-
[26]
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, et al. VL-Rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025. doi: 10.48550/arXiv.2504.08837. URL https://arxiv. org/abs/2504.08837
-
[27]
Perception-Aware Policy Optimization for Multimodal Reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, et al. PAPO: Reinforcement learning for advanced perception and reasoning in vision-language models. arXiv preprint arXiv:2507.06448, 2025. doi: 10.48550/arXiv.2507.06448. URL https: //arxiv.org/abs/2507.06448
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06448 2025
-
[28]
Qiong Wu, Xiangcong Yang, Yiyi Zhou, Chenxin Fang, Baiyang Song, et al. Grounded chain- of-thought for multimodal large language models.arXiv preprint arXiv:2503.12799, 2025. doi: 10.48550/arXiv.2503.12799. URLhttps://arxiv.org/abs/2503.12799
-
[29]
Kun Xiang, Heng Li, Terry Jingchen Zhang, Yinya Huang, Zirong Liu, et al. SeePhys: Does seeing help thinking? – benchmarking vision-based physics reasoning.arXiv preprint arXiv:2505.19099, 2025. doi: 10.48550/arXiv.2505.19099. URL https://arxiv.org/abs/ 2505.19099
-
[30]
Do Vision-Language Models Truly Perform Vision Reasoning? A Rigorous Study of the Modality Gap
Yige Xu, Yongjie Wang, Zizhuo Wu, Kaisong Song, Jun Lin, et al. Do vision-language models truly perform vision reasoning? A rigorous study of the modality gap.arXiv preprint arXiv:2604.16256, 2026. URLhttps://arxiv.org/abs/2604.16256
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. doi: 10.48550/arXiv.2505.09388. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[32]
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, et al. R1-Onevision: Ad- vancing generalized multimodal reasoning through cross-modal formalization.arXiv preprint arXiv:2503.10615, 2025. doi: 10.48550/arXiv.2503.10615. URL https://arxiv.org/abs/ 2503.10615. 11
-
[33]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, et al. DAPO: An open- source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. doi: 10.48550/arXiv.2503.14476. URLhttps://arxiv.org/abs/2503.14476
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[34]
MMMU: A mas- sive multi-discipline multimodal understanding and reasoning benchmark for expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, et al. MMMU: A mas- sive multi-discipline multimodal understanding and reasoning benchmark for expert AGI. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[35]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, et al. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model?arXiv preprint arXiv:2504.13837, 2025. doi: 10.48550/arXiv.2504.13837. URL https://arxiv.org/abs/ 2504.13837
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13837 2025
-
[36]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, et al. MathVerse: Does your multi-modal LLM truly see the diagrams in visual math problems? InProceedings of the European Conference on Computer Vision, pages 169–186, 2024
work page 2024
-
[37]
PhysReason: A comprehensive benchmark towards physics-based reasoning
Xinyu Zhang, Yuxuan Dong, Yanrui Wu, Jiaxing Huang, Chengyou Jia, et al. PhysReason: A comprehensive benchmark towards physics-based reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 16593–16615, Vienna, Austria, July 2025. Association for Computational Linguistics. doi: 10...
-
[38]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. doi: 10.48550/arXiv.2507.18071. URLhttps://arxiv.org/abs/2507.18071. 12 A Additional Evaluation Results A.1 Evaluation Protocol Details All models are evaluated with the same answer-oriented prompt template. For ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.18071 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.