Recognition: unknown
Do Vision-Language Models Truly Perform Vision Reasoning? A Rigorous Study of the Modality Gap
Pith reviewed 2026-05-10 08:59 UTC · model grok-4.3
The pith
VLMs primarily reason in textual space with limited reliance on visual evidence, shown by consistent performance drops when images are added to text in a controlled aligned benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
current VLMs conduct reasoning primarily in the textual space, with limited genuine reliance on visual evidence.
Load-bearing premise
The text-only, image-only, and image+text versions of each problem contain identical task-relevant information, as verified by human annotators, allowing performance differences to be attributed solely to modality.
Figures

read the original abstract
Reasoning in vision-language models (VLMs) has recently attracted significant attention due to its broad applicability across diverse downstream tasks. However, it remains unclear whether the superior performance of VLMs stems from genuine vision-grounded reasoning or relies predominantly on the reasoning capabilities of their textual backbones. To systematically measure this, we introduce CrossMath, a novel multimodal reasoning benchmark designed for controlled cross-modal comparisons. Specifically, we construct each problem in text-only, image-only, and image+text formats guaranteeing identical task-relevant information, verified by human annotators. This rigorous alignment effectively isolates modality-specific reasoning differences while eliminating confounding factors such as information mismatch. Extensive evaluation of state-of-the-art VLMs reveals a consistent phenomenon: a substantial performance gap between textual and visual reasoning. Notably, VLMs excel with text-only inputs, whereas incorporating visual data (image+text) frequently degrades performance compared to the text-only baseline. These findings indicate that current VLMs conduct reasoning primarily in the textual space, with limited genuine reliance on visual evidence. To mitigate this limitation, we curate a CrossMath training set for VLM fine-tuning. Empirical evaluations demonstrate that fine-tuning on this training set significantly boosts reasoning performance across all individual and joint modalities, while yielding robust gains on two general visual reasoning tasks. Source code is available at https://github.com/xuyige/CrossMath.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CrossMath, a multimodal reasoning benchmark with math problems constructed in text-only, image-only, and image+text formats that contain identical task-relevant information (verified by human annotators). Evaluations across state-of-the-art VLMs reveal that models achieve highest performance on text-only inputs and frequently degrade when visual inputs are added, from which the authors conclude that current VLMs perform reasoning primarily in textual space with limited genuine reliance on visual evidence. The authors also release a CrossMath training set and show that fine-tuning on it improves results across modalities as well as on two external visual reasoning tasks. Source code is publicly released.
Significance. If the controlled benchmark construction holds and the performance patterns are robust, the work offers a clear empirical demonstration of a modality gap in VLM reasoning, with direct implications for multimodal model design. The fine-tuning mitigation and public code release are concrete strengths that support reproducibility and allow the community to build on the benchmark.
major comments (2)
- [Abstract] Abstract: The central interpretation that degradation on image+text versus text-only inputs demonstrates 'limited genuine reliance on visual evidence' is not fully supported by the reported results. If VLMs largely ignored visual tokens, performance on image+text should be statistically indistinguishable from the text-only baseline; the consistent degradation instead indicates that visual tokens are being attended to and alter the generated outputs. This pattern is equally compatible with defective multimodal fusion as with minimal reliance, and the manuscript would be strengthened by additional diagnostics (e.g., attention maps over visual tokens or feature-ablation experiments) to distinguish these accounts.
- [Section 4 (Experiments)] Section 4 (Experiments): The evaluation lacks reported statistical tests or confidence intervals for the modality performance gaps. Given that the central claim rests on consistent differences between text-only and image+text conditions, formal significance testing (or at minimum standard errors across multiple runs or problem subsets) is needed to establish that the gaps are reliable rather than attributable to sampling variability.
minor comments (2)
- [Benchmark Construction] Provide explicit counts of problems per split, details on how the text-only/image-only/image+text variants were generated while preserving information equivalence, and inter-annotator agreement statistics for the human verification step.
- [Tables] Tables reporting VLM accuracies should include exact sample sizes, number of evaluation runs, and clear model-version identifiers to improve clarity and reproducibility.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably verify that text-only, image-only, and image+text versions contain identical task-relevant information
Forward citations
Cited by 2 Pith papers
-
SeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
Multimodal AI models for physics reasoning lose performance when information shifts from text to images, and RLVR training gains often come from non-visual textual or distributional cues rather than actual visual evidence.
-
SeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
SeePhys Pro benchmark reveals multimodal models degrade on physics reasoning as information transfers from text to images, with blind training improvements often stemming from textual cues rather than visual evidence.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2601.03267. Yueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, and Xiang Yue. Visualpuzzles: Decoupling multimodal reasoning evaluation from domain knowledge.arXiv preprint arXiv:2504.10342, 2025. URL https://arxiv.org/abs/2504.10342. Ilias Stogiannidis, Steven McDonagh, and Sotirios A Tsaftaris. Mind the gap: Benchmark...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
URLhttps://openreview.net/forum?id=qLdX6TA19s. Mert Unsal and Aylin Akkus. EasyARC: Evaluating vision language models on true visual reasoning.arXiv preprint arXiv:2506.11595, 2025. URLhttps://arxiv.org/abs/2506.11595. 13 Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Qu...
-
[3]
T-VSL: text-guided visual sound source localization in mixtures
URLhttps://openreview.net/forum?id=1PL1NIMMrw. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022,...
-
[4]
URLhttps://doi.org/10.1007/978-3-031-73242-3 10
doi: 10.1007/978-3-031-73242-3\ 10. URLhttps://doi.org/10.1007/978-3-031-73242-3 10. Appendix A Example Instruction Templates In the appendix, we release the example instruction templates for reference. Example Input for Chain-of-Thought Trajectories Generation A **Cross Math Puzzle** is a grid-based arithmetic reasoning task in which numbers and arithmet...
-
[8]
You are given a **cross math puzzle** in a **textual markdown grid format**
maintain consistency across cells shared by both horizontal and vertical equations. You are given a **cross math puzzle** in a **textual markdown grid format**. Each cell in the grid may contain: - a number, - an arithmetic operator (‘+’, ‘-’, ‘×’, ‘÷’), - an equality sign (‘=’), - a missing value marked as ‘?’, - or an empty cell. The markdown table repr...
-
[12]
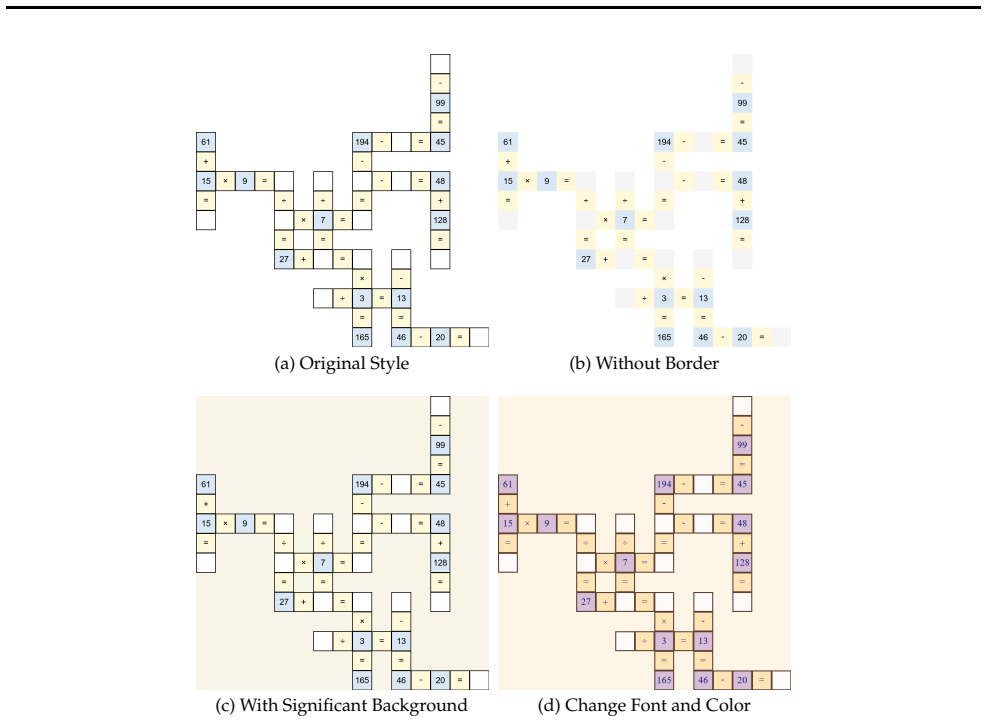
You are given a **cross math puzzle** in a **image format**
maintain consistency across cells shared by both horizontal and vertical equations. You are given a **cross math puzzle** in a **image format**. The puzzle is displayed as a 2D grid in which some cells contain numbers and arithmetic symbols (‘+’, ‘-’, ‘×’, ‘÷’, ‘=’), while other cells are blank or unknown. Unknown cells correspond to values that must be i...
-
[16]
You are given a **cross math puzzle** in **both image format and textual markdown format**
maintain consistency across cells shared by both horizontal and vertical equations. You are given a **cross math puzzle** in **both image format and textual markdown format**. The image provides the visual structure and appearance of the puzzle, while the markdown table provides an explicit symbolic representation of the same grid. The model may use both ...
-
[17]
understand the **2D spatial structure** of the puzzle,
-
[18]
identify which cells belong to the same equation,
-
[19]
reason over **multiple dependent equations**, and
-
[20]
You are given a **cross math puzzle** in a **textual markdown grid format**
maintain consistency across cells shared by both horizontal and vertical equations. You are given a **cross math puzzle** in a **textual markdown grid format**. Each cell in the grid may contain: - a number, - an arithmetic operator (‘+’, ‘-’, ‘×’, ‘÷’), - an equality sign (‘=’), - a missing value marked as ‘?’, - or an empty cell. The markdown table repr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.