Recognition: 2 theorem links
· Lean TheoremPiCA: Pivot-Based Credit Assignment for Search Agentic Reinforcement Learning
Pith reviewed 2026-05-13 07:31 UTC · model grok-4.3
The pith
PiCA reformulates credit assignment in LLM search agents by tying step rewards to pivot steps that raise the chance of eventual success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PiCA defines process rewards as success probabilities that depend on historical context using Potential-Based Reward Shaping. It identifies pivot steps—target golden sub-queries and sub-answers from trajectories—as information peaks that boost the likelihood of a correct final answer, providing dense, pivot-aware guidance anchored to the final objective while preserving distributional consistency.
What carries the argument
Pivot steps, which are information peaks in search trajectories consisting of golden sub-queries and sub-answers, used to shape rewards via Potential-Based Reward Shaping.
If this is right
- Search agents receive step-level signals that reflect cumulative progress toward the final answer.
- Credit assignment captures sequential dependencies rather than treating steps in isolation.
- Rewards stay consistent with the model's natural generation process, avoiding distributional shift.
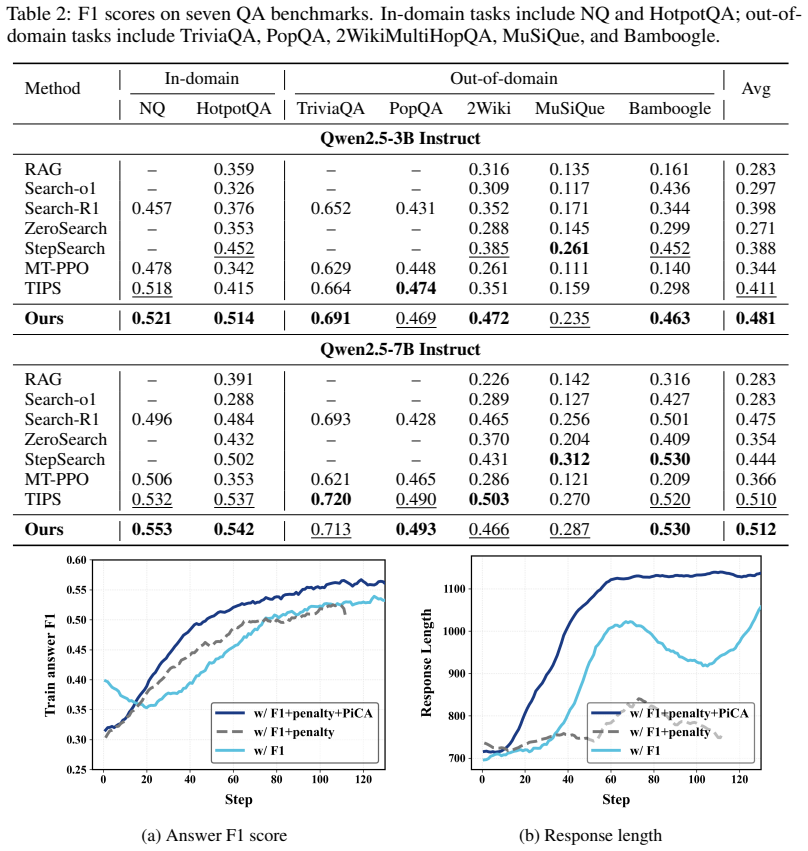
- Performance improves on seven knowledge-intensive QA benchmarks for both 3B and 7B models.
Where Pith is reading between the lines
- Similar pivot identification could help credit assignment in other long-horizon RL tasks beyond search agents.
- Extracting pivots from trajectories might reveal general patterns in how information accumulates in reasoning chains.
- Testing PiCA on non-QA tasks like code generation or planning could show broader applicability.
Load-bearing premise
That the pivot steps identified from historical trajectories accurately represent information peaks whose success probabilities can be estimated without bias from the model's own generation process.
What would settle it
Run an ablation where pivot steps are replaced with randomly chosen steps and measure whether the performance gains disappear on the QA benchmarks.
Figures






read the original abstract
Large Language Model (LLM)-based search agents trained with reinforcement learning (RL) have significantly improved the performance of knowledge-intensive tasks. However, existing methods encounter critical challenges in long-horizon credit assignment: (i) Reward Sparsity, where models receive only outcome feedback without step-level guidance to differentiate action quality; (ii) Isolated Credit, where credit is assigned to steps independently, failing to capture sequential dependencies; and (iii) Distributional Shift, where rewards are estimated on templates that deviate from the model's natural generative distribution. To address these issues, we propose Pivot-Based Credit Assignment (PiCA), a novel step reward mechanism that reformulates the search trajectory as a sequential process of cumulative search progress. Unlike prior isolated step rewards, PiCA defines process rewards as success probabilities dependent on the historical context based on Potential-Based Reward Shaping (PBRS). This approach identifies pivot steps, which comprise target golden sub-queries and sub-answers derived from historical trajectories, as information peaks that significantly boost the likelihood of a correct final answer. By anchoring these step rewards to the final task objective, PiCA provides dense, pivot-aware and trajectory-dependent guidance while maintaining distributional consistency. Extensive experiments show that PiCA outperforms existing strong baselines across seven knowledge-intensive QA benchmarks, achieving 15.2% and 2.2% improvements for 3B and 7B models. The consistent performance gains across various models show PiCA's robust generalization. The code is available at https://github.com/novdream/PiCA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PiCA, a pivot-based credit assignment method for reinforcement learning of LLM search agents. It uses Potential-Based Reward Shaping to define process rewards as success probabilities at pivot steps, which are golden sub-queries and sub-answers extracted from historical trajectories. These pivots are claimed to act as information peaks that provide dense, context-dependent guidance while preserving distributional consistency. The method is evaluated on seven knowledge-intensive QA benchmarks, reporting performance improvements of 15.2% for 3B models and 2.2% for 7B models over strong baselines.
Significance. If the pivot identification and probability estimation avoid selection bias and circularity, PiCA could represent a meaningful advance in addressing credit assignment challenges in long-horizon agentic RL for LLMs. The empirical gains suggest practical utility, and the availability of code supports reproducibility. However, the significance hinges on validating the core assumptions about unbiased pivots.
major comments (3)
- [§3.1] §3.1 (PBRS formulation): the process rewards are defined as success probabilities conditioned on historical context, but the manuscript does not specify whether these probabilities are estimated from held-out external data or fitted on the same policy-generated trajectories used for training and evaluation. This leaves the distributional-shift claim unverified and risks circularity.
- [§3.2] §3.2 (pivot identification): extracting pivot steps (golden sub-queries/sub-answers) from historical trajectories risks selection bias, as these steps are likely to over-represent high-progress actions that do not match the model's natural generative distribution at inference time. This directly undermines the claim that PiCA maintains distributional consistency and may inflate the reported gains.
- [§5] §5 (experimental results): the 15.2% and 2.2% improvements are reported without error bars, confidence intervals, or statistical significance tests across the seven benchmarks. No ablations are provided on alternative pivot-selection strategies or on the sensitivity of gains to the probability-estimation procedure, leaving the robustness of the central contribution untested.
minor comments (2)
- [Abstract] The abstract could briefly list the specific baselines against which the 15.2% and 2.2% gains are measured.
- [§3] Notation for the context-dependent success probability (e.g., an explicit equation relating it to the PBRS potential function) would improve clarity in §3.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and indicate the revisions we will incorporate to strengthen the presentation and empirical support for PiCA.
read point-by-point responses
-
Referee: [§3.1] §3.1 (PBRS formulation): the process rewards are defined as success probabilities conditioned on historical context, but the manuscript does not specify whether these probabilities are estimated from held-out external data or fitted on the same policy-generated trajectories used for training and evaluation. This leaves the distributional-shift claim unverified and risks circularity.
Authors: The success probabilities at pivot steps are estimated from a held-out collection of trajectories generated by a preliminary policy run prior to the main RL training loop. This separation ensures the estimates are independent of the trajectories encountered during policy optimization, supporting the claim of distributional consistency. We will revise §3.1 to explicitly describe this data partitioning procedure, include pseudocode for the estimation step, and add a diagram of the overall data flow. revision: yes
-
Referee: [§3.2] §3.2 (pivot identification): extracting pivot steps (golden sub-queries/sub-answers) from historical trajectories risks selection bias, as these steps are likely to over-represent high-progress actions that do not match the model's natural generative distribution at inference time. This directly undermines the claim that PiCA maintains distributional consistency and may inflate the reported gains.
Authors: Although pivots are identified from historical trajectories, the Potential-Based Reward Shaping formulation theoretically ensures that the shaped rewards preserve the optimal policy and do not introduce bias into the value function. To empirically address selection bias concerns, we will add an analysis comparing the distribution of selected pivots against the policy's generative distribution at inference time, plus an ablation using alternative pivot selection strategies (e.g., random step sampling and frequency-based selection). These results will be included in the revised §3.2 and §5. revision: partial
-
Referee: [§5] §5 (experimental results): the 15.2% and 2.2% improvements are reported without error bars, confidence intervals, or statistical significance tests across the seven benchmarks. No ablations are provided on alternative pivot-selection strategies or on the sensitivity of gains to the probability-estimation procedure, leaving the robustness of the central contribution untested.
Authors: We agree that the experimental results section requires additional statistical detail and robustness checks. In the revised manuscript we will report mean performance with standard deviations across five random seeds for all seven benchmarks, include paired statistical significance tests, and add ablations on pivot selection methods (success-probability-based vs. frequency-based) together with sensitivity analysis to the number of historical trajectories used for probability estimation. These will appear in an expanded §5 with new tables and figures. revision: yes
Circularity Check
Success probabilities for pivot steps are estimated from the same historical trajectories used to assign rewards
specific steps
-
fitted input called prediction
[Abstract]
"This approach identifies pivot steps, which comprise target golden sub-queries and sub-answers derived from historical trajectories, as information peaks that significantly boost the likelihood of a correct final answer. By anchoring these step rewards to the final task objective, PiCA provides dense, pivot-aware and trajectory-dependent guidance while maintaining distributional consistency."
Pivot steps and their associated success probabilities are derived directly from the historical trajectories generated by the model. These same trajectories are then assigned the resulting process rewards during RL training. The 'prediction' of information peaks therefore reduces to a quantity fitted or selected from the input data distribution rather than an independent estimate, creating partial circularity in the credit assignment mechanism.
full rationale
The derivation claims to solve distributional shift by defining process rewards as context-dependent success probabilities via PBRS, with pivots extracted from historical trajectories. However, the extraction and probability estimation occur on the policy-generated histories themselves, making the reward values statistically dependent on the trajectories being shaped rather than providing an independent external signal. This matches the fitted-input-called-prediction pattern at a moderate level; the central claim of 'distributional consistency' and 'anchoring to the final objective' still retains some independent content from PBRS, preventing a higher score. No self-citation load-bearing or self-definitional reduction to tautology is evident from the provided text.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PiCA defines process rewards as success probabilities dependent on the historical context based on Potential-Based Reward Shaping (PBRS)... identifies pivot steps... as information peaks
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reformulates the search trajectory as a sequential process of cumulative search progress
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jose A Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter. Rudder: Return decomposition for delayed rewards.Ad- vances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[2]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[3]
Learning to reason with search for llms via reinforcement learning,
M Chen, L Sun, T Li, H Sun, Y Zhou, C Zhu, H Wang, JZ Pan, W Zhang, H Chen, et al. Research: Learning to reason with search for llms via reinforcement learning. arxiv 2025.arXiv preprint arXiv:2503.19470, 2025
-
[4]
Deepseek-v3 technical report, 2025
DeepSeek-AI, Aixin Liu, Bei Feng, et al. Deepseek-v3 technical report, 2025
work page 2025
-
[5]
Wenfeng Feng, Chuzhan Hao, Yuewei Zhang, Jingyi Song, and Hao Wang. Airrag: Activating intrinsic reasoning for retrieval augmented generation via tree-based search.arXiv e-prints, pages arXiv–2501, 2025
work page 2025
-
[6]
A survey on llm-as-a-judge, 2025
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge, 2025
work page 2025
-
[7]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
work page 2020
-
[8]
Rag-star: Enhancing deliberative reasoning with retrieval augmented verification and refinement
Jinhao Jiang, Jiayi Chen, Junyi Li, Ruiyang Ren, Shijie Wang, Wayne Xin Zhao, Yang Song, and Tao Zhang. Rag-star: Enhancing deliberative reasoning with retrieval augmented verification and refinement. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V...
work page 2025
-
[9]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7969–7992, 2023
work page 2023
-
[10]
Bowen Jin, Jinsung Yoon, Priyanka Kargupta, Sercan O. Arik, and Jiawei Han. An empirical study on reinforcement learning for reasoning-search interleaved llm agents, 2025
work page 2025
-
[11]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
work page 2017
-
[13]
Training language models to self-correct via reinforcement learning, 2024
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Training language models to self-correct via reinforcement learning, 2024
work page 2024
-
[14]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
work page 2019
-
[15]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020. 10
work page 2020
-
[16]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
work page 2025
-
[17]
Retrollm: Empowering large language models to retrieve fine-grained evidence within gen- eration
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yongkang Wu, Zhonghua Li, Ye Qi, and Zhicheng Dou. Retrollm: Empowering large language models to retrieve fine-grained evidence within gen- eration. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16754–16779, 2025
work page 2025
-
[18]
Minhua Lin, Zongyu Wu, Zhichao Xu, Hui Liu, Xianfeng Tang, Qi He, Charu Aggarwal, Hui Liu, Xiang Zhang, and Suhang Wang. A comprehensive survey on reinforcement learning-based agentic search: Foundations, roles, optimizations, evaluations, and applications, 2025
work page 2025
-
[19]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
work page 2024
-
[20]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 9802–9822, 2023
work page 2023
-
[21]
Ng, Daishi Harada, and Stuart J
Andrew Y . Ng, Daishi Harada, and Stuart J. Russell. Policy invariance under reward transfor- mations: Theory and application to reward shaping. InProceedings of the 16th International Conference on Machine Learning (ICML), pages 278–287. Morgan Kaufmann, 1999
work page 1999
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[23]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
work page 2023
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Replug: Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8371–8384, 2024
work page 2024
-
[28]
Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, and Xiang Wang. Search and refine during think: Facilitating knowledge refinement for improved retrieval-augmented reasoning, 2025
work page 2025
-
[29]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward hacking, 2025
work page 2025
-
[30]
Zerosearch: Incentivize the search capability of llms without searching, 2025
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588, 2025. 11
-
[31]
R.S. Sutton and A.G. Barto. Reinforcement learning: An introduction.IEEE Transactions on Neural Networks, 9(5):1054–1054, 1998
work page 1998
-
[32]
Hindsight credit assignment for long-horizon llm agents, 2026
Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan-Zhe Guo, and Yu-Feng Li. Hindsight credit assignment for long-horizon llm agents, 2026
work page 2026
-
[33]
Zhengwei Tao, Haiyang Shen, Baixuan Li, Wenbiao Yin, Jialong Wu, Kuan Li, Zhongwang Zhang, Huifeng Yin, Rui Ye, Liwen Zhang, et al. Webleaper: Empowering efficiency and efficacy in webagent via enabling info-rich seeking.arXiv preprint arXiv:2510.24697, 2025
-
[34]
MiroMind Team, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Jifeng Dai, Xuan Dong, et al. Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling.arXiv preprint arXiv:2511.11793, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[36]
Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. Information gain-based policy optimization: A simple and effective approach for multi-turn search agents, 2026
work page 2026
-
[37]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Reward hacking in the era of large models: Mechanisms, emergent misalignment, challenges, 2026
Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, Zhengkang Guo, Qi Qian, Yifei Wang, Feiran Zhang, Ruicheng Yin, Shihan Dou, Changze Lv, Tao Chen, Kaitao Song, Xu Tan, Tao Gui, Xiaoqing Zheng, and Xuanjing Huang. Reward hacking in the era of large models: Mechanisms, emergent misal...
work page 2026
-
[39]
A theoretical understanding of self-correction through in-context alignment, 2024
Yifei Wang, Yuyang Wu, Zeming Wei, Stefanie Jegelka, and Yisen Wang. A theoretical understanding of self-correction through in-context alignment, 2024
work page 2024
-
[40]
Ziliang Wang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Yuhang Wang, and Yichao Wu. Stepsearch: Igniting llms search ability via step-wise proximal policy optimization.arXiv preprint arXiv:2505.15107, 2025
- [41]
-
[42]
Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Gang Fu, Yong Jiang, et al. Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
-
[43]
Tips: Turn-level information-potential reward shaping for search-augmented llms, 2026
Yutao Xie, Nathaniel Thomas, Nicklas Hansen, Yang Fu, Li Erran Li, and Xiaolong Wang. Tips: Turn-level information-potential reward shaping for search-augmented llms, 2026
work page 2026
-
[44]
Yutao Xie, Nathaniel Thomas, Nicklas Hansen, Yang Fu, Li Erran Li, and Xiaolong Wang. Tips: Turn-level information-potential reward shaping for search-augmented llms.arXiv preprint arXiv:2603.22293, 2026
-
[45]
Corrective Retrieval Augmented Generation
Shi-Qi Yan et al. Corrective retrieval augmented generation.arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[47]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[48]
Chenchen Zhang. From reasoning to agentic: Credit assignment in reinforcement learning for large language models, 2026
work page 2026
-
[49]
Training multi-turn search agent via contrastive dynamic branch sampling, 2026
Yubao Zhao, Weiquan Huang, Sudong Wang, Ruochen Zhao, Chen Chen, Yao Shu, and Chengwei Qin. Training multi-turn search agent via contrastive dynamic branch sampling, 2026
work page 2026
-
[50]
Deepresearcher: Scaling deep research via reinforcement learning in real-world environments, 2025
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments, 2025. 13 A Data Generation Process. As described in introduction aboutpivot steps, we enrich approximately 12,000 training instances from the StepSearch [40] dataset. F...
work page 2025
-
[51]
Step Quality (+): - The <search> query effectively matches the intent of the ’Golden Sub-Queries’ for that step. - If the <information> block is missing the ’Golden Sub-Answers’, but the model correctly recognizes this in <think> and searches again, it is still ’+’
-
[52]
reason": A brief explanation of where the logic failed
Step Failure (-): - Summary Omission: The <information> block contains the ’Golden Sub-Answers’, but the model’s <think> block ignores it or fails to summarize it, leading to a redundant or wrong next step. - Logic Deviation: The <search> query significantly departs from the ’Golden Sub-Queries’ logic or targets the wrong entity. - Hallucination: The <thi...
work page 1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.