Recognition: 2 theorem links
· Lean TheoremDo Self-Evolving Agents Forget? Capability Degradation and Preservation in Lifelong LLM Agent Adaptation
Pith reviewed 2026-05-12 04:07 UTC · model grok-4.3
The pith
Self-evolving LLM agents lose old capabilities as they adapt to new tasks across workflow, skill, model, and memory channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
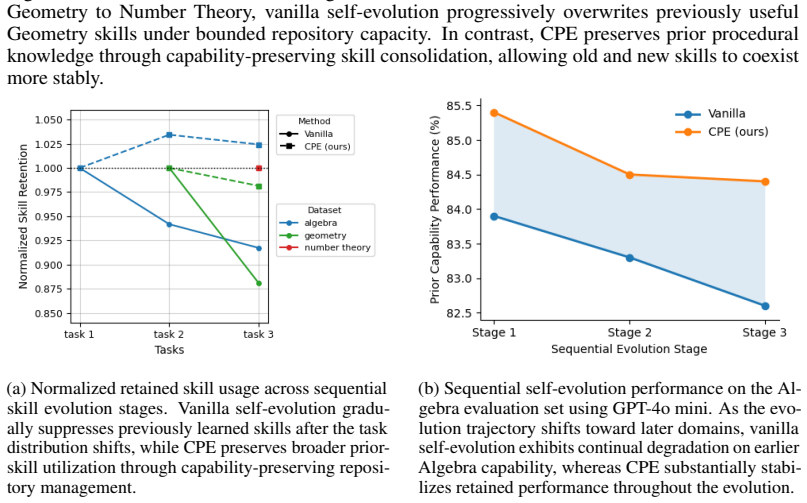
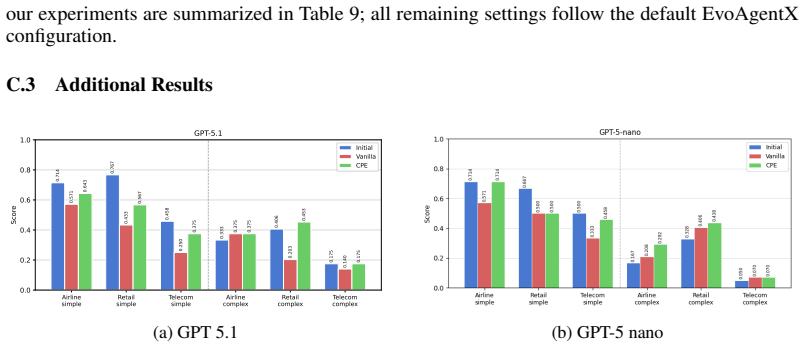
Self-evolution in LLM agents is often non-monotonic, with adaptation to new task distributions causing progressive degradation of prior capabilities across workflow, skill, model, and memory evolution channels. This phenomenon, called capability erosion under self-evolution, is addressed by Capability-Preserving Evolution (CPE), which improves retained capability stability while preserving adaptation performance. For instance, in workflow evolution under GPT-5.1 optimization, CPE raises retained simple-task performance from 41.8% to 52.8% while strengthening complex-task adaptation.
What carries the argument
Capability-Preserving Evolution (CPE), a stabilization principle that constrains destructive capability drift during continual adaptation of self-evolving LLM agents.
If this is right
- Long-horizon self-evolving agents require explicit preservation of old capabilities in addition to acquiring new ones.
- Without stabilization, adaptation to new tasks will progressively reduce performance on previously mastered tasks.
- CPE applies uniformly across workflow, skill, model, and memory evolution to maintain stability during continual adaptation.
- Practical agent systems must incorporate constraints against capability drift to achieve reliable lifelong operation.
Where Pith is reading between the lines
- The erosion pattern may resemble catastrophic forgetting in continual learning, suggesting agent designers could borrow regularization techniques from that literature.
- Developers should evaluate agents on multi-distribution benchmarks that track both new-task gains and old-task retention over extended horizons.
- If CPE generalizes, it could enable safer deployment of autonomous agents in environments where forgetting carries real costs, such as personal assistants or scientific workflows.
- The effect might intensify with longer adaptation sequences or more divergent task distributions, pointing to the need for scale and diversity experiments.
Load-bearing premise
The observed degradation stems from the self-evolution process itself rather than from particular implementation choices, task distributions, or model scale.
What would settle it
Running the same self-evolution protocols on a different model family or unrelated task distribution and finding no progressive loss of old capabilities would falsify the claim that erosion is inherent to self-evolution.
Figures





read the original abstract
Recent advances in LLM agents enable systems that autonomously refine workflows, accumulate reusable skills, self-train their underlying models, and maintain persistent memory. However, we show that such self-evolution is often non-monotonic: adapting to new task distributions can progressively degrade previously acquired capabilities across all major evolution channels. We identify this phenomenon as \emph{capability erosion under self-evolution} and show that it consistently emerges across workflow, skill, model, and memory evolution. To mitigate this issue, we propose \emph{Capability-Preserving Evolution} (CPE), a general stabilization principle that constrains destructive capability drift during continual adaptation. Across all four evolution dimensions, CPE consistently improves retained capability stability while preserving adaptation performance. For example, in workflow evolution, CPE improves retained simple-task performance from 41.8\% to 52.8\% under GPT-5.1 optimization while simultaneously achieving stronger complex-task adaptation. Our findings suggest that stable long-horizon self-evolving agents require not only acquiring new capabilities, but also explicitly preserving previously learned ones during continual adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that self-evolving LLM agents, which autonomously refine workflows, accumulate skills, self-train models, and update memory, exhibit non-monotonic capability degradation (termed 'capability erosion under self-evolution') when adapting to new task distributions. This degradation occurs across workflow, skill, model, and memory channels. The authors propose Capability-Preserving Evolution (CPE) as a stabilization principle that constrains destructive drift, reporting consistent improvements in retained capability (e.g., simple-task performance rising from 41.8% to 52.8% in workflow evolution under GPT-5.1) while preserving adaptation gains.
Significance. If the central empirical observations hold after addressing controls, the work identifies a practically important obstacle for long-horizon autonomous agents and supplies a concrete mitigation principle applicable across evolution channels. The cross-channel consistency and the specific numeric example of retention improvement provide a useful starting point for future agent design, though the absence of isolating baselines limits immediate impact.
major comments (2)
- [Results on workflow evolution (and parallel sections for other channels)] The attribution of degradation specifically to self-evolution mechanisms (workflow refinement, skill accumulation, etc.) rather than generic continual adaptation effects is not load-bearing supported. The reported 41.8% simple-task retention (improving to 52.8% with CPE) is shown only within the self-evolving GPT-5.1 setup; no non-self-evolving baseline receiving identical task sequences is presented to test whether the non-monotonic loss occurs under standard fine-tuning or prompting on the same distributions.
- [CPE definition and evaluation sections] CPE is presented as a 'general stabilization principle,' yet all quantitative evidence is confined to the GPT-5.1 workflow case. No ablation or transfer results are given for other models, scales, or the skill/model/memory channels, undermining the claim of consistent improvement 'across all four evolution dimensions.'
minor comments (2)
- [Abstract] The abstract states high-level results and one numeric example but omits experimental details such as number of runs, statistical tests, task distribution descriptions, or exact measurement protocols for 'retained capability.'
- [Related work] References to the broader continual learning and catastrophic forgetting literature are sparse; explicit positioning against standard mitigation techniques (e.g., replay buffers, regularization) would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below, clarifying our experimental design and outlining revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Results on workflow evolution (and parallel sections for other channels)] The attribution of degradation specifically to self-evolution mechanisms (workflow refinement, skill accumulation, etc.) rather than generic continual adaptation effects is not load-bearing supported. The reported 41.8% simple-task retention (improving to 52.8% with CPE) is shown only within the self-evolving GPT-5.1 setup; no non-self-evolving baseline receiving identical task sequences is presented to test whether the non-monotonic loss occurs under standard fine-tuning or prompting on the same distributions.
Authors: We agree that including non-self-evolving baselines on identical task sequences would provide stronger isolation of the effect. Our experiments are centered on the self-evolving paradigm because that is the novel setting under study, where autonomous mechanisms such as workflow refinement and skill accumulation introduce distinct dynamics not present in standard fine-tuning or prompting. To address the concern directly, we will add comparative baselines using standard continual adaptation methods on the same distributions in the revised manuscript, allowing explicit measurement of whether non-monotonic degradation is amplified under self-evolution. revision: yes
-
Referee: [CPE definition and evaluation sections] CPE is presented as a 'general stabilization principle,' yet all quantitative evidence is confined to the GPT-5.1 workflow case. No ablation or transfer results are given for other models, scales, or the skill/model/memory channels, undermining the claim of consistent improvement 'across all four evolution dimensions.'
Authors: The primary quantitative evaluation of CPE is presented in depth for the workflow channel under GPT-5.1 as a representative case study. The manuscript applies the same stabilization principle to the skill, model, and memory channels and reports consistent directional improvements, though these are less extensively quantified. We acknowledge that broader ablations across models, scales, and dedicated transfer experiments would better substantiate the generality claim. In the revision we will expand the evaluation sections to include additional quantitative results and ablations for the skill and model channels. revision: yes
Circularity Check
Empirical observation with no circular derivation chain
full rationale
The paper reports experimental observations of capability degradation across workflow, skill, model, and memory evolution channels in LLM agents, then proposes CPE as a mitigation principle. No equations, derivations, or first-principles claims appear; results are presented as direct measurements (e.g., retention percentages under GPT-5.1) rather than predictions derived from fitted parameters or self-referential definitions. The work is self-contained against external benchmarks via controlled experiments and does not rely on load-bearing self-citations or uniqueness theorems. This is the expected non-circular outcome for an empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents evolve autonomously along workflow, skill, model, and memory dimensions
invented entities (1)
-
Capability-Preserving Evolution (CPE)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify this phenomenon as capability erosion under self-evolution ... adaptation toward new task distributions can progressively degrade previously acquired capabilities across all major evolution channels.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CPE solves RCPEt ∈ arg min Lt(R) + λΩt(R, Rt−1) ... dimension-specific regularization strategies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of se...
work page internal anchor Pith review arXiv 2026
-
[2]
Automated Design of Agentic Systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems, 2025. URL https://arxiv.org/abs/2408.08435
work page internal anchor Pith review arXiv 2025
-
[3]
AFlow: Automating Agentic Workflow Generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. Aflow: Automating agentic workflow generation, 2025. URL https://arxiv.org/abs/ 2410.10762
work page internal anchor Pith review arXiv 2025
-
[4]
Evoagentx: An automated frame- work for evolving agentic workflows, 2025
Yingxu Wang, Siwei Liu, Jinyuan Fang, and Zaiqiao Meng. Evoagentx: An automated frame- work for evolving agentic workflows, 2025. URLhttps://arxiv.org/abs/2507.03616
-
[5]
arXiv preprint arXiv:2502.07373 , year=
Guibin Zhang, Kaijie Chen, Guancheng Wan, Heng Chang, Hong Cheng, Kun Wang, Shuyue Hu, and Lei Bai. Evoflow: Evolving diverse agentic workflows on the fly, 2025. URL https://arxiv.org/abs/2502.07373
-
[6]
SEW: Self-Evolving Agentic Workflows for Automated Code Generation
Siwei Liu, Jinyuan Fang, Han Zhou, Yingxu Wang, and Zaiqiao Meng. Sew: Self-evolving agentic workflows for automated code generation, 2026. URL https://arxiv.org/abs/ 2505.18646
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Dang Nguyen, Viet Dac Lai, Seunghyun Yoon, Ryan A. Rossi, Handong Zhao, Ruiyi Zhang, Puneet Mathur, Nedim Lipka, Yu Wang, Trung Bui, Franck Dernoncourt, and Tianyi Zhou. Dynasaur: Large language agents beyond predefined actions, 2025. URL https://arxiv. org/abs/2411.01747
-
[8]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents, 2026. URLhttps://arxiv.org/abs/2602.02474
work page internal anchor Pith review arXiv 2026
-
[9]
V oyager: An open-ended embodied agent with large language models,
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models,
-
[10]
URLhttps://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners, 2024. URLhttps://arxiv.org/abs/2308.10144
-
[12]
Tool-R0: Self-evolving LLM agents for tool-learning from zero data.arXiv, 2026
Emre Can Acikgoz, Cheng Qian, Jonas Hübotter, Heng Ji, Dilek Hakkani-Tür, and Gokhan Tur. Tool-r0: Self-evolving llm agents for tool-learning from zero data, 2026. URL https: //arxiv.org/abs/2602.21320
-
[13]
Skillcraft: Can llm agents learn to use tools skillfully?,
Shiqi Chen, Jingze Gai, Ruochen Zhou, Jinghan Zhang, Tongyao Zhu, Junlong Li, Kangrui Wang, Zihan Wang, Zhengyu Chen, Klara Kaleb, Ning Miao, Siyang Gao, Cong Lu, Manling Li, Junxian He, and Yee Whye Teh. Skillcraft: Can llm agents learn to use tools skillfully?,
- [14]
- [15]
-
[16]
B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners,
Weihao Zeng, Yuzhen Huang, Lulu Zhao, Yijun Wang, Zifei Shan, and Junxian He. B-star: Monitoring and balancing exploration and exploitation in self-taught reasoners, 2025. URL https://arxiv.org/abs/2412.17256
-
[17]
arXiv preprint arXiv:2404.12253 , year=
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, and Dong Yu. Toward self-improvement of llms via imagination, searching, and criticizing, 2024. URL https: //arxiv.org/abs/2404.12253. 10
-
[18]
Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory , journal =
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory, 2025. URL https://arxiv.org/abs/ 2504.07952
-
[19]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H. Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang- Cheng Kang, and Derek Zhiyuan Cheng. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory, 2025. URLhttps://arxiv.org/abs/2511.20857
work page internal anchor Pith review arXiv 2025
-
[20]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):352...
-
[21]
A comprehensive survey of continual learning: Theory, method and application, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application, 2024. URL https://arxiv.org/abs/2302. 00487
work page 2024
- [22]
-
[23]
SuRe: Surprise-driven prioritised replay for continual LLM learning
Zafeirios Fountas et al. SuRe: Surprise-driven prioritised replay for continual LLM learning. arXiv preprint arXiv:2511.22367, 2025
-
[24]
Ming Chen et al. Analyzing and reducing catastrophic forgetting in parameter efficient tuning. arXiv preprint arXiv:2402.18865, 2024
-
[25]
Wei Zhang et al. Mechanistic analysis of catastrophic forgetting in large language models during continual fine-tuning.arXiv preprint arXiv:2601.18699, 2026
-
[26]
Yuhao Luo et al. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.arXiv preprint arXiv:2308.08747, 2024
-
[27]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025. URL https://arxiv. org/abs/2506.07982
work page internal anchor Pith review arXiv 2025
-
[28]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, 12 Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher B...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Measuring mathematical problem solving with the math dataset,
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset,
-
[31]
URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Medmcqa : A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa : A large- scale multi-subject multi-choice dataset for medical domain question answering, 2022. URL https://arxiv.org/abs/2203.14371
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Revisiting weight regularization for low-rank continual learning, 2026
Yaoyue Zheng, Yin Zhang, Joost van de Weijer, Gido M van de Ven, Shaoyi Du, Xuetao Zhang, and Zhiqiang Tian. Revisiting weight regularization for low-rank continual learning, 2026. URL https://arxiv.org/abs/2602.17559
-
[36]
Jinyuan Fang, Yanwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, Zhaochun Ren, Nikos Aletras, Xi Wang, Han Zhou, and Zaiqiao Meng. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems, 2025. URLhttps://arxiv.org/abs/2508.07407
-
[37]
Shuai Shao, Qihan Ren, Chen Qian, Boyi Wei, Dadi Guo, Jingyi Yang, Xinhao Song, Linfeng Zhang, Weinan Zhang, Dongrui Liu, and Jing Shao. Your agent may misevolve: Emergent risks in self-evolving llm agents, 2026. URLhttps://arxiv.org/abs/2509.26354
-
[38]
Yujun Zhou, Yue Huang, Han Bao, Kehan Guo, Zhenwen Liang, Pin-Yu Chen, Tian Gao, Werner Geyer, Nuno Moniz, Nitesh V Chawla, and Xiangliang Zhang. Capability-oriented training induced alignment risk, 2026. URLhttps://arxiv.org/abs/2602.12124. 15 A Proofs for the Local CPE Analysis Proof of Proposition 1.By Taylor expansion ofL <t aroundR t−1, for a local u...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.