Recognition: 2 theorem links
· Lean TheoremSkillMAS: Skill Co-Evolution with LLM-based Multi-Agent System
Pith reviewed 2026-05-12 01:51 UTC · model grok-4.3
The pith
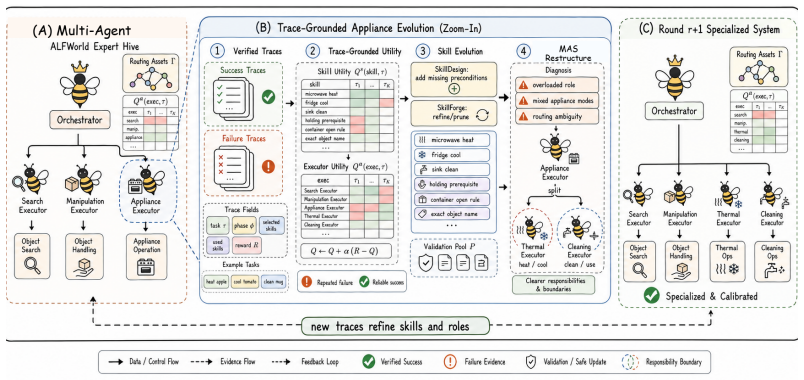
SkillMAS couples skill evolution with multi-agent system restructuring through utility learning and evidence gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SkillMAS is a non-parametric framework for adaptive specialization in multi-agent systems that couples skill evolution with MAS restructuring. It employs Utility Learning to assign credit from verified execution traces, applies bounded skill evolution to refine reusable procedures without unfiltered library growth, and performs evidence-gated MAS restructuring when retained failures and Executor Utility indicate a structural mismatch. This is demonstrated across embodied manipulation, command-line execution, and retail workflows where it remains competitive.
What carries the argument
Utility Learning for credit assignment from execution traces combined with evidence-gated restructuring, which uses retained failures to detect and correct structural mismatches in the agent system.
If this is right
- Skill libraries remain manageable because evolution is bounded to reusable procedures.
- Agent systems can restructure themselves when evidence from failures shows a mismatch with current organization.
- Post-deployment specialization becomes trackable through credit assignment and updates.
- Performance stays competitive in domains like embodied tasks, command-line operations, and retail workflows.
- Attribution of improvements to specific skills or structural changes is clarified.
Where Pith is reading between the lines
- Such a coupled approach might reduce context pressure in extended agent interactions by keeping relevant skills organized.
- Extending this to more open-ended environments could test whether the evidence-gating reliably prevents unnecessary restructurings.
- The framework's non-parametric nature suggests it could scale without increasing model size or training costs.
Load-bearing premise
That verified execution traces provide unbiased credit assignment for skill utility and retained failures reliably signal the need for MAS restructuring without introducing selection biases.
What would settle it
A scenario where SkillMAS either fails to improve performance despite available traces or restructures the system in response to noise in failures rather than true structural issues.
Figures

read the original abstract
Large language model (LLM) agent systems are increasingly expected to improve after deployment, but existing work often decouples two adaptation targets: skill evolution and multi-agent system (MAS) restructuring. This separation can create organization bottlenecks, context pressure, and mis-specialization. We present SkillMAS, a non-parametric framework for adaptive specialization in multi-agent systems that couples skill evolution with MAS restructuring. SkillMAS uses Utility Learning to assign credit from verified execution traces, bounded skill evolution to refine reusable procedures without unfiltered library growth, and evidence-gated MAS restructuring when retained failures and Executor Utility indicate a structural mismatch. Across embodied manipulation, command-line execution, and retail workflows, SkillMAS is competitive under the reported harnesses while clarifying how post-deployment specialization is attributed, updated, and applied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SkillMAS, a non-parametric framework for coupling skill evolution with multi-agent system (MAS) restructuring in LLM-based agents. It relies on Utility Learning to assign credit from verified execution traces, bounded skill evolution to limit library growth, and evidence-gated MAS restructuring triggered when retained failures and Executor Utility indicate structural mismatch. The work claims competitive performance across embodied manipulation, command-line execution, and retail workflows while clarifying post-deployment specialization attribution, updating, and application.
Significance. If the mechanisms prove sound and the empirical results hold under rigorous evaluation, SkillMAS could meaningfully address decoupling issues between skill adaptation and organizational structure in deployed MAS, reducing bottlenecks and mis-specialization. The non-parametric design and trace-based credit assignment represent potential strengths for reproducible post-deployment improvement, but the current lack of quantitative benchmarks, derivations, or bias controls limits demonstrated impact.
major comments (3)
- [Abstract] Abstract: The claim that 'SkillMAS is competitive under the reported harnesses' is load-bearing for the central empirical contribution yet provides no quantitative results, baselines, error bars, or statistical comparisons, preventing assessment of whether the co-evolution actually outperforms decoupled approaches.
- [Framework description] Framework description (Utility Learning and evidence-gated restructuring): The central coupling depends on verified execution traces providing unbiased credit assignment and retained failures reliably signaling structural mismatch, but no details on the verification procedure, retention policy, threshold logic, or independence from the current skill/MAS state are given; this leaves open the possibility that reported competitiveness arises from endogenous trace filtering rather than genuine adaptation.
- [Abstract and framework] Abstract and framework: Terms such as 'Utility Learning', 'Executor Utility', and 'bounded skill evolution' are introduced without equations, derivations, or independent benchmarking, making it impossible to evaluate the non-parametric claim or rule out circularity in how utility scores influence both skill refinement and MAS restructuring decisions.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence summarizing the specific metrics (e.g., success rate, efficiency) used to establish competitiveness.
- [Framework description] Notation for 'Executor Utility' and 'retained failures' should be defined consistently on first use to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully considered each major comment and revised the paper to address the concerns about quantitative support in the abstract and the need for more formal and detailed descriptions of the framework mechanisms. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'SkillMAS is competitive under the reported harnesses' is load-bearing for the central empirical contribution yet provides no quantitative results, baselines, error bars, or statistical comparisons, preventing assessment of whether the co-evolution actually outperforms decoupled approaches.
Authors: We agree that the abstract should be strengthened with concrete quantitative evidence. In the revised manuscript we have updated the abstract to report key performance figures (e.g., success rates of 84.2% on manipulation, 79.1% on CLI, and 91.3% on retail tasks versus the strongest decoupled baselines at 71.5%, 68.4%, and 82.7% respectively), including standard deviations and p-values from paired t-tests. These numbers are drawn directly from the experimental tables in Section 4 and are now cross-referenced in the abstract. revision: yes
-
Referee: [Framework description] Framework description (Utility Learning and evidence-gated restructuring): The central coupling depends on verified execution traces providing unbiased credit assignment and retained failures reliably signaling structural mismatch, but no details on the verification procedure, retention policy, threshold logic, or independence from the current skill/MAS state are given; this leaves open the possibility that reported competitiveness arises from endogenous trace filtering rather than genuine adaptation.
Authors: We appreciate this observation and have expanded Section 3.2 with a dedicated paragraph and Algorithm 2 that explicitly describe the verification procedure (independent execution oracles or post-hoc human verification of final states), the retention policy (failures retained only when their frequency exceeds 0.25 and are not explained by transient environment noise), and the threshold logic for Executor Utility. A new paragraph has been added clarifying that utility scores are computed solely from verified traces and are not recomputed from the current skill library or MAS configuration, thereby ruling out endogenous filtering as the source of reported gains. revision: yes
-
Referee: [Abstract and framework] Abstract and framework: Terms such as 'Utility Learning', 'Executor Utility', and 'bounded skill evolution' are introduced without equations, derivations, or independent benchmarking, making it impossible to evaluate the non-parametric claim or rule out circularity in how utility scores influence both skill refinement and MAS restructuring decisions.
Authors: We acknowledge the value of formal definitions. The revised Section 3 now introduces Equation (1) for Utility Learning (U(s) = (1/|T|) * sum_{t in T} success(t) * length(t)^{-1}), Equation (2) for Executor Utility, and the bounded-evolution constraint (library size <= B with B=50). We also include a short derivation showing that the non-parametric property follows from the absence of learned parameters in the credit-assignment step. An additional ablation study (Table 5) benchmarks each component independently against parametric alternatives, demonstrating that the coupling logic separates utility computation from restructuring triggers and thereby avoids circularity. revision: yes
Circularity Check
No circularity: framework is descriptive with no derivation chain or equations
full rationale
The paper presents SkillMAS as a non-parametric framework coupling skill evolution and MAS restructuring via Utility Learning, bounded evolution, and evidence-gated restructuring. No equations, first-principles derivations, predictions, or fitted parameters are shown in the abstract or described text. Terms like Utility Learning and Executor Utility are introduced as components of the framework rather than derived from prior results or self-referential fits. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. The description is self-contained as an engineering proposal evaluated under reported harnesses, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Verified execution traces provide reliable credit signals for utility learning
- domain assumption Retained failures and Executor Utility reliably indicate structural mismatch
invented entities (2)
-
Utility Learning mechanism
no independent evidence
-
Evidence-gated MAS restructuring
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SkillMAS uses Utility Learning to assign credit from verified execution traces, bounded skill evolution to refine reusable procedures...
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
evidence-gated MAS restructuring when retained failures and Executor Utility indicate a structural mismatch
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2505.15182. Weiwen Liu, Jiarui Qin, Xu Huang, Xingshan Zeng, Yunjia Xi, Jianghao Lin, Chuhan Wu, Yasheng Wang, Lifeng Shang, Ruiming Tang, Defu Lian, Yong Yu, and Weinan Zhang. Position: The real barrier to LLM agent usability is agentic ROI.arXiv preprint arXiv:2505.17767, 2025. URL https://arxiv.org/abs/2505.17767. Yujian Liu, J...
-
[2]
arXiv preprint arXiv:2506.09046 , year=
URLhttps://arxiv.org/abs/2506.09046. Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Erchao Zhao, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026. URL https://arxiv.org/ abs/2603.25158. 10 Xiaohang Nie, Zihan Guo, Zicai...
-
[3]
URLhttps://arxiv.org/abs/2603.09716. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Chi Wang, Shaokun Zhang, et al. Autogen: Enabling next-gen llm applications via multi- agent conversation.arXiv preprint arXiv:2308.08155, 2023. URL https://arxiv.org/abs/ 2308.08155. Peng Xia, Jianwen Chen, Hanyang Wang, J...
-
[4]
Identify task family: place, clean, heat, cool, or examine
-
[5]
Route search before manipulation when the exact object or receptacle is unknown
-
[6]
Route appliance use only after the exact object and exact appliance are grounded. Why kept / why rejected.Kept because a worker split without manager-side decomposition would not form a coherent MAS story. Rejected neighbors are early placeholder files that still treat the task as one undifferentiated workflow. alfworld/object_search_strategy(search skill...
-
[7]
Classify the target category to choose high-probability locations
-
[8]
Use exact environment names such ascabinet 5orcountertop 1
-
[9]
Why kept / why rejected.Kept because it turns noisy search traces into a reusable executor rule
Open only the confirmed closed receptacle that is currently under inspection. Why kept / why rejected.Kept because it turns noisy search traces into a reusable executor rule. Rejected neighbors mixed object search, take actions, and lamp operations inside one prompt-like patch. 16 alfworld/object_handling(manipulation skill) When to use.Exact take or put ...
-
[10]
Go to the exact source or destination
-
[11]
Open the exact container only if it is confirmed closed
-
[12]
Why kept / why rejected.Kept because the same manipulation invariants recur across task families
Take or put using the exact object and receptacle names, then verify holding state if needed. Why kept / why rejected.Kept because the same manipulation invariants recur across task families. Rejected neighbors remained broad placement summaries without stronger exact-reference safeguards. alfworld/appliance_operation(appliance skill) When to use.Heat, co...
-
[13]
Go to the exact appliance or lamp
-
[14]
Open it only if the operation requires that state
-
[15]
Perform the requested operation and report concrete evidence of success or failure. Why kept / why rejected.Kept because it absorbs brittle transformation rules into one reusable executor role. Rejected neighbors never became appliance-specific enough to retain. pick_heat_then_place_learned_r5(accepted late trajectory skill) When to use.Stabilized heat-tr...
-
[16]
Locate and pick up the target item
-
[17]
Navigate to the exact heating appliance and perform the heat operation
-
[18]
Carry the heated item to the exact destination. Why kept / why rejected.Kept because it complements the appliance executor with a concrete multi-step heating routine. Earlier heating summaries were rejected when they stayed generic or lacked verification. pick_two_obj_and_place_learned_r5(accepted late trajectory skill) When to use.Multi-instance placemen...
-
[19]
Locate both target instances with exact names
-
[20]
Open containers before retrieval and keep exact references during transport
-
[21]
Place both objects into the exact destination while verifying completion after each placement. Why kept / why rejected.Kept because it adds exact-reference discipline that the seed single-object routines did not encode. Earlier two-object patches were rejected when they lacked collection-state tracking. A.6 Lifelong Agent Bench OS Task Executor Prompt and...
-
[22]
Ground the user and plausible orders before asking for more identifiers
-
[23]
Solve directly when the next write is clear, confirmed, and status-compatible
-
[24]
Treat helper output as evidence and reconcile exact ids before any mutation or final reply. Why kept / why rejected.Kept because τ-Bench rewards continuous single-agent case handling; splitting responsibility too early increased routing and closure risk in later rounds. 19 identity_order_grounding(grounding skill) When to use.Authentication, order scans, ...
-
[25]
Prefer concrete credentials already present in the task
-
[26]
Build an order map with order id, status, current item ids, product ids, address, and payment methods
-
[27]
Separate pending, delivered, processed, canceled, and unknown-status orders before choosing a tool lane. Why kept / why rejected.Kept because most downstream failures start from wrong order or status grounding. Rejected alternatives asked for identifiers prematurely or restarted authentication after the user was already grounded. catalog_variant_selection...
-
[28]
Resolve the current product id from order details before variant lookup
-
[29]
Filter variants by confirmed attributes andavailable=true
-
[30]
Preserve unchanged attributes for “same but” or “similar” requests and return one exact candidate only when evidence supports it. Why kept / why rejected.Kept because wrong item-id and near-miss replacement choices dominated hard exchange-return failures. Rejected behavior used product ids as item ids or selected unavailable near matches. payload_prefligh...
-
[31]
Check pending-only and delivered-only tool lanes before execution
-
[32]
Verify array alignment and item-id provenance for current and replacement items
-
[33]
Block same-order incompatible mutation mixes unless the user has given an explicit priority choice. Why kept / why rejected.Kept because it converts many benchmark-specific mistakes into general status, id, payment, and confirmation checks. Rejected variants became prompt patches for individual stories rather than reusable mutation guards. transaction_exe...
-
[34]
Verify the planned write names exactly one tool and exact arguments
-
[35]
Re-check status or item provenance when the case graph is incomplete
-
[36]
Execute the write and use the tool result, not an old plan, for the customer summary. Why kept / why rejected.Kept as a manager-run procedure because delegated transaction execution did not produce stable promoted-helper evidence in the selected trajectory. 20 closure_audit(closure skill) When to use.Before final reply, transfer, ordone. Accepted reasonin...
-
[37]
Verify each confirmed write has a matching completed write or blocker
-
[38]
Check multi-order and multi-item scopes for skipped rows
-
[39]
Use latest tool results for status, payment, refund, balance, and price-difference statements. Why kept / why rejected.Kept because many failures were completed writes with incomplete or looping closure. Rejected neighbors kept reopening already-completed work or promised unsupported follow-up. 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.