Recognition: 2 theorem links
· Lean TheoremFrom Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs
Pith reviewed 2026-05-12 02:04 UTC · model grok-4.3
The pith
Multi-signal monitoring detects all 10 GPU failures in 504-GPU training cluster at low false positive rate
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
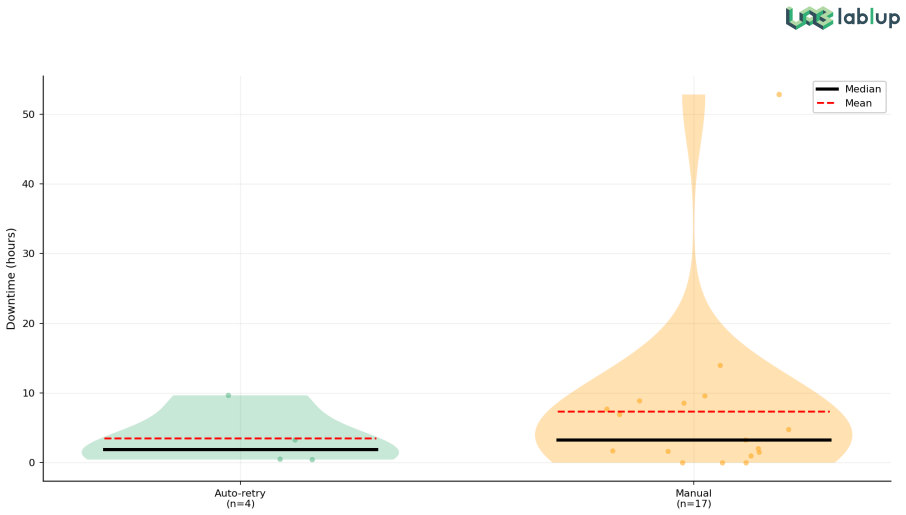
Statistical analysis over 751 Prometheus metrics and 10 XID-identified GPU failures achieves a 10/10 detection rate with 2/10 detected pre-XID at ~0.84 false positives per day in a 504-GPU cluster; checkpoint profiling attributes low RoCE utilization to NFS RPC saturation; and auto-retry chains succeed at 33.3% versus 12.5% manual.
What carries the argument
The unified cross-organizational monitoring pipeline using Prometheus time-series data and operational logs for 224 training sessions, enabling joint diagnosis of scale-specific issues.
If this is right
- No single metric dominates failure detection, so systems should integrate multiple signals rather than relying on one.
- The 128-slot NFS RPC layer becomes the bottleneck at 60-node scale, limiting effective bandwidth to 1.4-10.4% of link capacity.
- Auto-retry mechanisms achieve 33.3% success over 73 attempts compared to 12.5% for manual, suggesting automation reduces recovery time.
- Top three nodes account for over 50% of exclusions, indicating potential for targeted maintenance.
Where Pith is reading between the lines
- If the multi-signal approach generalizes, future training frameworks could embed similar detection without custom per-metric thresholds.
- The concentration of failures suggests that hardware heterogeneity or placement affects reliability more than average rates imply.
- Scaling to larger clusters might require rethinking storage architectures beyond NFS for checkpointing.
Load-bearing premise
The assumption that the observed patterns in this specific 63-node B200 cluster with cross-organizational monitoring generalize to other large-scale LLM pre-training environments and that the data collection comprehensively captures all relevant events without bias.
What would settle it
Observing a GPU failure in a similar 500+ GPU cluster that is not preceded by anomalous values in any of the 751 Prometheus metrics or XID errors.
Figures













read the original abstract
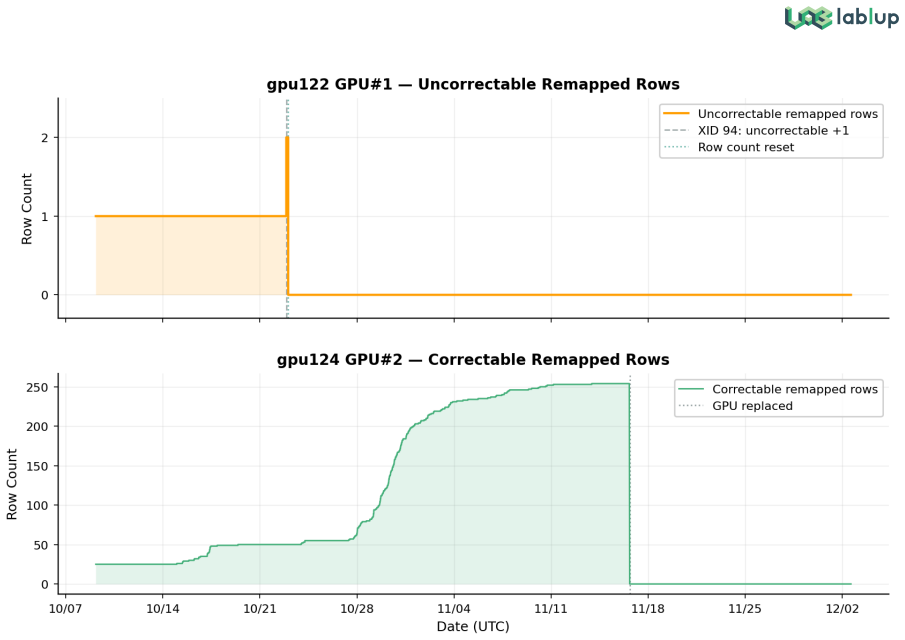
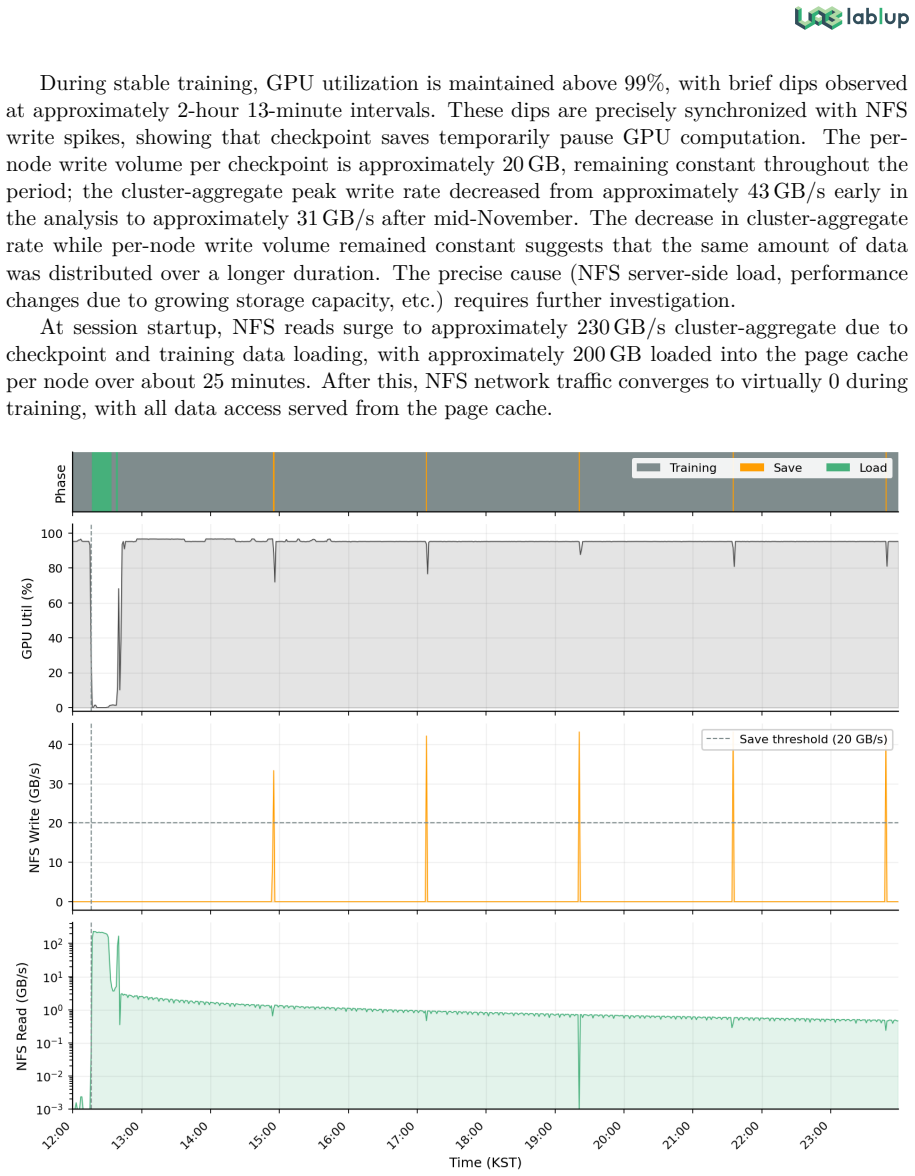
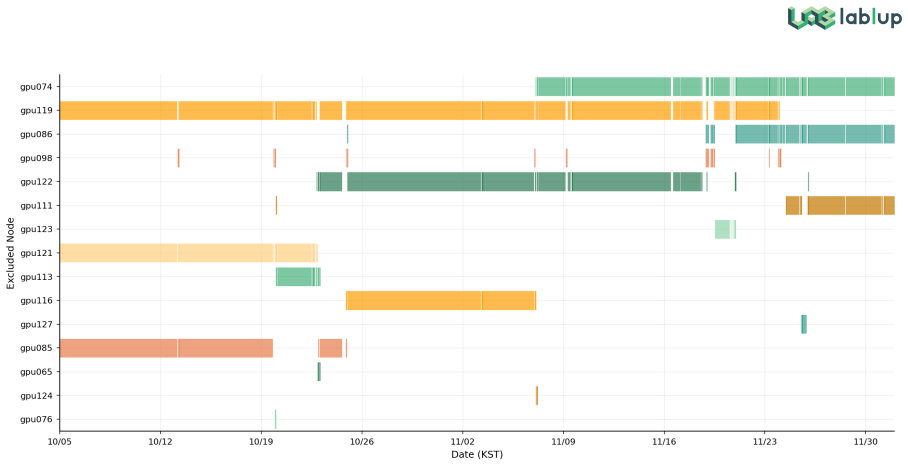
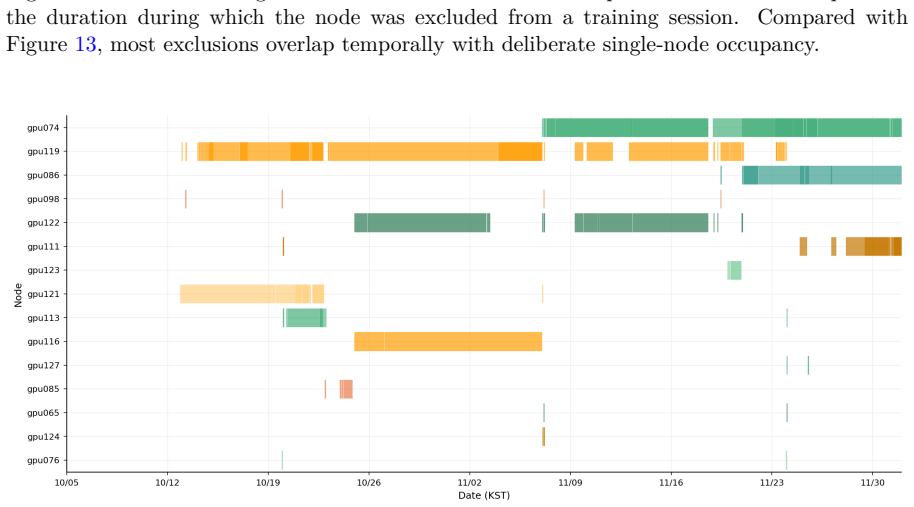
Large-scale AI training is now fundamentally a distributed systems problem, and hardware failures have become routine operating conditions rather than rare exceptions. Public operational evidence from production training clusters, however, remains scarce. This technical report presents an empirical analysis of a 63-node NVIDIA B200 production cluster (504 GPUs), using 55 days of Prometheus time-series data and 73 days of operational logs covering 224 multi-node training sessions. The cluster operates within a cross-organizational environment in which five parties (SKT, Upstage, Lablup, NVIDIA Korea, and VAST Data) share a unified monitoring pipeline. This arrangement enabled joint diagnosis of a 60-node-scale storage I/O bottleneck that did not appear at 2-4-node scale, a production-scale phenomenon no single team could isolate alone. Drawing on a months-long pre-training campaign, we perform three quantitative analyses yielding four findings. First, statistical analysis over 751 Prometheus metrics and 10 XID-identified GPU failures achieves a 10/10 detection rate (2/10 pre-XID) at ~0.84 false positives per day. No single metric is consistently dominant across failure types, motivating a multi-signal detection strategy. Second, profiling 523 checkpoint events along the GPU VRAM to NFS path attributes the "bandwidth paradox" (1.4-10.4% utilization of 200 Gbps RoCE) to saturation of the 128-slot NFS RPC layer. Third, multi-node failure response shows concentrated exclusions (top 3 of 63 nodes account for >50% of all exclusions) and an auto-retry chain success rate of 33.3% over 12 chains (73 attempts), 2.7x the 12.5% manual recovery rate; the median retry interval is 11 min (IQR 10-11). All analyses are grounded in production infrastructure providing session-level workload management, GPU-centric scheduling, and unified observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This technical report analyzes operational data from a 63-node (504 GPU) NVIDIA B200 cluster during LLM pre-training. It presents statistical results on detecting 10 GPU failures using 751 Prometheus metrics (achieving 10/10 detection at ~0.84 false positives/day), attributes low checkpoint bandwidth to NFS RPC saturation based on 523 events, and evaluates failure recovery showing auto-retry advantages over manual methods with concentrated node exclusions.
Significance. The results, if they hold, are significant because they supply scarce public empirical data from a real production LLM training environment involving multiple organizations. This enables identification of scale-dependent issues like storage bottlenecks and provides quantitative benchmarks for failure detection and recovery strategies that could influence the development of more resilient distributed training systems. The use of actual logs and metrics rather than synthetic data is a notable strength.
major comments (2)
- The headline result of a 10/10 detection rate (with 2/10 pre-XID) on 10 XID-identified failures using 751 metrics lacks supporting statistical rigor. No cross-validation, multiple testing correction, or baseline false positive rate (e.g., via permutation tests) is mentioned, making the claim susceptible to overfitting given the high number of metrics relative to the small positive class size.
- The auto-retry success rate of 33.3% over 12 chains (73 attempts) and the 2.7x improvement over manual recovery (12.5%) are derived from limited data. With such small samples, the reliability of these percentages and the recommendation for auto-retry chains is reduced, and no confidence intervals or statistical tests are provided.
minor comments (3)
- Clarify what the four findings are, as the abstract mentions three analyses yielding four findings but details only three.
- The methodology for choosing the specific metrics and thresholds for the detection analysis should be described in more detail to allow readers to evaluate potential selection bias.
- Consider adding a limitations section discussing the generalizability of findings from this specific 63-node B200 cluster to other LLM pre-training setups.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our technical report. The comments highlight important considerations regarding statistical rigor in an observational production dataset, which we have addressed by expanding the discussion of limitations and adding quantitative qualifiers where feasible. Our point-by-point responses follow.
read point-by-point responses
-
Referee: The headline result of a 10/10 detection rate (with 2/10 pre-XID) on 10 XID-identified failures using 751 metrics lacks supporting statistical rigor. No cross-validation, multiple testing correction, or baseline false positive rate (e.g., via permutation tests) is mentioned, making the claim susceptible to overfitting given the high number of metrics relative to the small positive class size.
Authors: We agree that the small number of observed failures (n=10) and the large metric space (751) make standard cross-validation or permutation testing impractical without risking data leakage or unstable estimates. Our analysis is threshold-based and domain-informed rather than a learned classifier, which mitigates but does not remove overfitting risk. In the revised manuscript we have added an explicit limitations subsection that discusses the observational nature of the data, the absence of multiple-testing correction, and the baseline false-positive rate computed over the 55-day non-failure periods. We also clarify that the 10/10 figure is presented as an empirical observation rather than a validated classifier performance claim. revision: partial
-
Referee: The auto-retry success rate of 33.3% over 12 chains (73 attempts) and the 2.7x improvement over manual recovery (12.5%) are derived from limited data. With such small samples, the reliability of these percentages and the recommendation for auto-retry chains is reduced, and no confidence intervals or statistical tests are provided.
Authors: We acknowledge the limited sample of 12 recovery chains. In the revision we have added 95% Clopper-Pearson confidence intervals for both success rates and a note that the observed 2.7x difference should be interpreted cautiously. We also include a Fisher's exact test comparing auto-retry versus manual outcomes (p=0.15), which we report as suggestive rather than conclusive. These additions are placed in the recovery analysis section together with an explicit statement on the constraints of production data. revision: yes
Circularity Check
No circularity: purely empirical observational analysis
full rationale
The paper reports direct statistical counts and rates computed from 751 Prometheus metrics, 10 XID failures, 523 checkpoint events, and 73 retry attempts in production logs. No equations, models, or first-principles derivations are claimed; findings are simple aggregates (detection rate 10/10, false-positive rate ~0.84/day, bandwidth utilization percentages, exclusion concentration, retry success 33.3%). No self-citations, fitted parameters renamed as predictions, or ansatzes appear. The work is self-contained against external benchmarks as raw operational data analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prometheus metrics and XID logs provide complete and accurate representation of GPU failures and system events.
Reference graph
Works this paper leans on
-
[1]
Aaron Grattafiori, Abhimanyu Dubey, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Revisiting reliability in large-scale machine learning research clusters
Apostolos Kokolis, Michael Kuchnik, John Hoffman, Adithya Kumar, Parth Malani, Faye Ma, Zachary DeVito, Shubho Sengupta, Kalyan Saladi, and Carole-Jean Wu. Revisiting reliability in large-scale machine learning research clusters. InProceedings of the 2025 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2025
work page 2025
-
[3]
Solar open technical report, 2026
Upstage Solar Team. Solar open technical report. Technical report, Upstage, January 2026. arXiv:2601.07022. 102B bilingual MoE (12B active) trained on 20T tokens. Also available athttps://huggingface.co/upstage/Solar-Open-100B
-
[4]
Analysis of Large-Scale Multi-Tenant GPU clusters for DNN training workloads
MyeongjaeJeon, ShivaramVenkataraman, AmarPhanishayee, JunjieQian, WencongXiao, and Fan Yang. Analysis of Large-Scale Multi-Tenant GPU clusters for DNN training workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 947–960, Renton, WA, July 2019. USENIX Association
work page 2019
-
[5]
Megascale: Scaling large language model training to more than 10,000 gpus
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, et al. Megascale: Scaling large language model training to more than 10,000 gpus. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 2024
work page 2024
-
[6]
Hardware failures won’t limit AI scaling
Alexander Erben and Ege Erdil. Hardware failures won’t limit AI scaling. Epoch AI, 2024
work page 2024
-
[7]
Minder: Faulty machine detection for large-scale distributed model training
Yangtao Deng, Xiang Shi, Zhuo Jiang, Xingjian Zhang, Lei Zhang, Zhang Zhang, Bo Li, Zuquan Song, Hang Zhu, Gaohong Liu, Fuliang Li, Shuguang Wang, Haibin Lin, Jianxi Ye, and Minlan Yu. Minder: Faulty machine detection for large-scale distributed model training. InProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI...
work page 2025
-
[8]
Tianyuan Wu, Wei Wang, Yinghao Yu, Siran Yang, Wenchao Yang, Qinkai Duan, Guodong Yang, Jiamang Wang, Lin Qu, and Liping Zhang. FALCON: Pinpointing and mitigating stragglers for large-scale hybrid-parallel training.arXiv preprint arXiv:2410.12588, 2024
-
[9]
Understanding stragglers in large model training using what-if analysis
Jinkun Lin, Ziheng Jiang, Zuquan Song, Sida Zhao, Menghan Yu, Zhanghan Wang, Chenyuan Wang, Zuocheng Shi, Xiang Shi, Wei Jia, Zherui Liu, Shuguang Wang, Haibin Lin, Xin Liu, Aurojit Panda, and Jinyang Li. Understanding stragglers in large model training using what-if analysis.arXiv preprint arXiv:2505.05713, 2025. 34
-
[10]
NVIDIA Corporation. Analyzing XID errors — GPU deployment and management doc- umentation.https://docs.nvidia.com/deploy/xid-errors/analyzing-xid-catalog. html, 2026. Accessed: 2026-02-15
work page 2026
-
[11]
NVIDIA Corporation. NVIDIA Blackwell architecture technical brief: Powering the new era of generative AI and accelerated computing. Technical brief, NVIDIA Corporation,
-
[12]
Per Blackwell GPU: up to 192 GB HBM3e, up to 8 TB/s
Version 1.1. Per Blackwell GPU: up to 192 GB HBM3e, up to 8 TB/s. Accessed: 2026-04-21
work page 2026
-
[13]
NVIDIA Corporation. DGX SuperPOD: Next generation scalable infrastructure for AI leadership reference architecture featuring DGX B200.https://docs.nvidia.com/ dgx-superpod/reference-architecture-scalable-infrastructure-b200/latest/,
- [14]
-
[15]
Topology-aware gpu scheduling for learning workloads in cloud environments
Marcelo Amaral, Jordà Polo, David Carrera, Seetharami Seelam, and Malgorzata Stein- der. Topology-aware gpu scheduling for learning workloads in cloud environments. In Proceedings of the International Conference for High Performance Computing, Network- ing, Storage and Analysis (SC), pages 1–12. ACM, 2017
work page 2017
-
[16]
Sokovan: Container orchestrator for accelerated AI/ML workloads and massive-scale GPU computing
Jeongkyu Shin and Joongi Kim. Sokovan: Container orchestrator for accelerated AI/ML workloads and massive-scale GPU computing. Presented at OpenInfra Sum- mit Vancouver, June 2023. Slides available athttps://www.backend.ai/ko/video/ 2023-06-11-openinfra-summit
work page 2023
-
[17]
Dcgm-exporter: NVIDIA GPU monitoring tool for Prometheus
NVIDIA Corporation. Dcgm-exporter: NVIDIA GPU monitoring tool for Prometheus. https://github.com/NVIDIA/dcgm-exporter, 2026. Accessed: 2026-02-15
work page 2026
-
[18]
Node exporter: Prometheus exporter for hardware and OS metrics
Prometheus Authors. Node exporter: Prometheus exporter for hardware and OS metrics. https://github.com/prometheus/node_exporter, 2026. Accessed: 2026-02-15
work page 2026
-
[19]
all-smi: Cross-platform ai accelerator monitoring tool.https://github.com/ lablup/all-smi, 2025
Lablup Inc. all-smi: Cross-platform ai accelerator monitoring tool.https://github.com/ lablup/all-smi, 2025. Accessed: 2026-02-05
work page 2025
-
[20]
NVIDIA GPU memory error management.https://docs.nvidia
NVIDIA Corporation. NVIDIA GPU memory error management.https://docs.nvidia. com/deploy/a100-gpu-mem-error-mgmt/index.html, 2025. v590. Accessed: 2026-03-24
work page 2025
-
[21]
John W. Young. A first order approximation to the optimum checkpoint interval.Com- munications of the ACM, 17(9):530–531, 1974
work page 1974
-
[22]
John T. Daly. A higher order estimate of the optimum checkpoint interval for restart dumps.Future Generation Computer Systems, 22(3):303–312, 2006
work page 2006
-
[23]
Leonardo Bautista-Gomez, Anne Benoit, Sheng Di, Thomas Herault, Yves Robert, and Hongyang Sun. A survey on checkpointing strategies: Should we always checkpoint à la Young/Daly?Future Generation Computer Systems, 161:315–328, 2024
work page 2024
-
[24]
Shin, Yibo Zhu, Myeongjae Jeon, Junjie Qian, HongqiangLiu, andChuanxiongGuo
Juncheng Gu, Mosharaf Chowdhury, Kang G. Shin, Yibo Zhu, Myeongjae Jeon, Junjie Qian, HongqiangLiu, andChuanxiongGuo. Tiresias: Agpuclustermanagerfordistributed deep learning. InProceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI), pages 485–500. USENIX Association, 2019
work page 2019
-
[25]
Gandiva: Introspective cluster scheduling for deep learning
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwa- tra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. Gandiva: Introspective cluster scheduling for deep learning. InProceed- ings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 595–610. US...
work page 2018
-
[26]
Aurick Qiao, Sang Keun Choe, Suhas Jayaram Subramanya, Willie Neiswanger, Qirong Ho, Hao Zhang, Gregory R. Ganger, and Eric P. Xing. Pollux: Co-adaptive cluster scheduling for goodput-optimized deep learning. InProceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 1–18. USENIX Association, 2021
work page 2021
-
[27]
Suhas Jayaram Subramanya, Daiyaan Arfeen, Shouxu Lin, Aurick Qiao, Zhihao Jia, and Gregory R. Ganger. Sia: Heterogeneity-aware, goodput-optimized ml-cluster scheduling. In Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), pages 642–657. ACM, 2023
work page 2023
-
[28]
Shockwave: Fair and efficient cluster scheduling for dynamic adaptation in machine learn- ing
Pengfei Zheng, Rui Pan, Tarannum Khan, Shivaram Venkataraman, and Aditya Akella. Shockwave: Fair and efficient cluster scheduling for dynamic adaptation in machine learn- ing. InProceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 2023
work page 2023
-
[29]
Cassini: Network-aware job scheduling in machine learning clusters
Sudarsanan Rajasekaran, Manya Ghobadi, and Aditya Akella. Cassini: Network-aware job scheduling in machine learning clusters. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 2024
work page 2024
-
[30]
Mast: Global scheduling of ml training across geo- distributed datacenters at hyperscale
Arnab Choudhury, Yang Wang, Tuomas Pelkonen, Kutta Srinivasan, Abha Jain, Shenghao Lin, DeliaDavid, SiavashSoleimanifard, MichaelChen, AbhishekYadav, RiteshTijoriwala, Denis Samoylov, and Chunqiang Tang. Mast: Global scheduling of ml training across geo- distributed datacenters at hyperscale. InProceedings of the 18th USENIX Symposium on Operating Systems...
work page 2024
-
[31]
Qinlong Wang, Tingfeng Lan, Yinghao Tang, Ziling Huang, Yiheng Du, Haitao Zhang, Jian Sha, Hui Lu, Yuanchun Zhou, Ke Zhang, and Mingjie Tang. DLRover-RM: Resource optimization for deep recommendation models training in the cloud.Proceedings of the VLDB Endowment, 17, 2024
work page 2024
-
[32]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[33]
Efficient large-scale language model training on gpu clusters using megatron- lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Pat- wary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kasber, Matei Zaharia, and Bryan Catanzaro. Efficient large-scale language model training on gpu clusters using megatron- lm. InProceedings of the International Conference for High Performance Computing, Networking, Storage ...
work page 2021
-
[34]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism. InProceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS), pages 103–112, 2019
work page 2019
-
[35]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). IEEE, 2020
work page 2020
-
[36]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Les Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16(12):3848– 3860, 2023. 36
work page 2023
-
[37]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. Alpa: Automating inter- and intra-operator parallelism for distributed deep learn- ing. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI),...
work page 2022
-
[38]
Checkfreq: Frequent, fine- grained dnn checkpointing
Jayashree Mohan, Amar Phanishayee, and Vijay Chidambaram. Checkfreq: Frequent, fine- grained dnn checkpointing. InProceedings of the 19th USENIX Conference on File and Storage Technologies (FAST), pages 203–216. USENIX Association, 2021
work page 2021
-
[39]
Just-in-time checkpoint- ing: Low cost error recovery from deep learning training failures
Tanmaey Gupta, Sanjeev Krishnan, Rituraj Kumar, Abhishek Vijeev, Bhargav Gulavani, Nipun Kwatra, Ramachandran Ramjee, and Muthian Sivathanu. Just-in-time checkpoint- ing: Low cost error recovery from deep learning training failures. InProceedings of the Nineteenth European Conference on Computer Systems (EuroSys), pages 1110–1125. ACM, 2024
work page 2024
-
[40]
Zhuang Wang, Zhen Jia, Shuai Zheng, Zhen Zhang, Xinwei Fu, T. S. Eugene Ng, and Yida Wang. Gemini: Fast failure recovery in distributed training with in-memory checkpoints. In Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), pages 364–381. ACM, 2023
work page 2023
-
[41]
Bytecheckpoint: A unified checkpointing system for large foundation model development
Borui Wan, Mingji Han, Yiyao Sheng, Yanghua Peng, Haibin Lin, Mofan Zhang, Zhichao Lai, Menghan Yu, Junda Zhang, Zuquan Song, Xin Liu, and Chuan Wu. Bytecheckpoint: A unified checkpointing system for large foundation model development. InProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 2025
work page 2025
-
[42]
Oobleck: Resilient distributed training of large models using pipeline templates
Insu Jang, Zhenning Yang, Zhen Zhang, Xin Jin, and Mosharaf Chowdhury. Oobleck: Resilient distributed training of large models using pipeline templates. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), pages 382–395. ACM, 2023
work page 2023
-
[43]
Bamboo: Making preemptible instances resilient for affordable training of large dnns
John Thorpe, Pengzhan Zhao, Jonathan Eyolfson, Yifan Qiao, Zhihao Jia, Minjia Zhang, Ravi Netravali, and Guoqing Harry Xu. Bamboo: Making preemptible instances resilient for affordable training of large dnns. InProceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 2023
work page 2023
-
[44]
Varuna: Scalable, low-cost training of massive deep learning models
SanjithAthlur, NitikaSaran, MuthianSivathanu, RamachandranRamjee, andNipunKwa- tra. Varuna: Scalable, low-cost training of massive deep learning models. InProceedings of the Seventeenth European Conference on Computer Systems (EuroSys), pages 472–487. ACM, 2022
work page 2022
-
[45]
TRANSOM: An efficient fault-tolerant system for training LLMs.arXiv preprint arXiv:2310.10046, 2023
Baodong Wu, Lei Xia, Qingping Li, Kangyu Li, Xu Chen, Yongqiang Guo, Tieyao Xiang, Yuheng Chen, and Shigang Li. TRANSOM: An efficient fault-tolerant system for training LLMs.arXiv preprint arXiv:2310.10046, 2023
-
[46]
Morley Mao, Matthew Lentz, Danyang Zhuo, and Ion Stoica
Yongji Wu, Wenjie Qu, Xueshen Liu, Tianyang Tao, Yifan Qiao, Zhuang Wang, Wei Bai, Yuan Tian, Jiaheng Zhang, Z. Morley Mao, Matthew Lentz, Danyang Zhuo, and Ion Sto- ica. Lazarus: Resilient and elastic training of mixture-of-experts models.arXiv preprint arXiv:2407.04656, 2024
-
[47]
Jungsuk Kang and Joongi Kim. Method and apparatus for automatic recovery of tasks using execution failure-based resource requirement adjustment. Lablup Inc., 2026. Korean Patent Application 10-2026-0024429. 37
work page 2026
-
[48]
NVIDIA Corporation. cuDNN backend release notes.https://docs.nvidia.com/ deeplearning/cudnn/backend/latest/release-notes.html, 2024. Cumulative release notes covering cuDNN 9.x; multiple FP8/MXFP8/NVFP4-related fixes across versions. Accessed: 2026-04-21
work page 2024
-
[49]
Scaling fp8 training to trillion-token llms,
Maxim Fishman, Brian Chmiel, Ron Banner, and Daniel Soudry. Scaling FP8 training to trillion-token LLMs. InProceedings of the Thirteenth International Conference on Learning Representations (ICLR), 2025. Spotlight. arXiv:2409.12517
-
[50]
Available: https://arxiv.org/abs/2405.18710
Joonhyung Lee, Jeongin Bae, Byeongwook Kim, Se Jung Kwon, and Dongsoo Lee. To FP8 and back again: Quantifying the effects of reducing precision on LLM training stability. arXiv preprint arXiv:2405.18710, 2024. A System Architecture Details This appendix describes the detailed implementation of the Backend.AI infrastructure summa- rized in Section 3. The c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.