Recognition: 2 theorem links
· Lean TheoremLet the Target Select for Itself: Data Selection via Target-Aligned Paths
Pith reviewed 2026-05-12 02:43 UTC · model grok-4.3
The pith
A short warmup on target validation data creates a reusable reference path that scores candidate training samples by their normalized loss drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a validation-induced flow from a short capacity-limited warmup on the target validation proxy supplies an aligned reference trajectory, and that scoring each candidate by its normalized endpoint loss drop along this trajectory produces effective data selection for the downstream task.
What carries the argument
The validation-induced flow obtained from the short warmup, used as the reference path along which candidates are scored by normalized endpoint loss drop.
If this is right
- Data selection no longer requires candidate gradients or second-order approximations.
- A single warmup computation can be reused across multiple heterogeneous candidate pools.
- Warmup cost and storage scale with the small validation proxy rather than the full candidate pool.
- The method remains competitive with dynamic attribution techniques on controlled logistic, vision, and instruction-tuning tasks.
Where Pith is reading between the lines
- The same warmup path could support repeated selection rounds as new candidates arrive without recomputing trajectories.
- Testing progressively shorter warmups would reveal the minimal target data needed to keep the flow representative.
- The loss-drop score could be combined with simple diversity filters to address potential sample interactions the current proxy ignores.
Load-bearing premise
The brief warmup on target validation data generates a flow whose dynamics closely match those of the full target task, and the endpoint loss drop reliably measures a candidate's standalone utility.
What would settle it
Run the same logistic, vision, and instruction-tuning experiments but measure whether the proposed scores produce subsets that underperform strong gradient-based attribution baselines by a clear margin on the target metric.
Figures
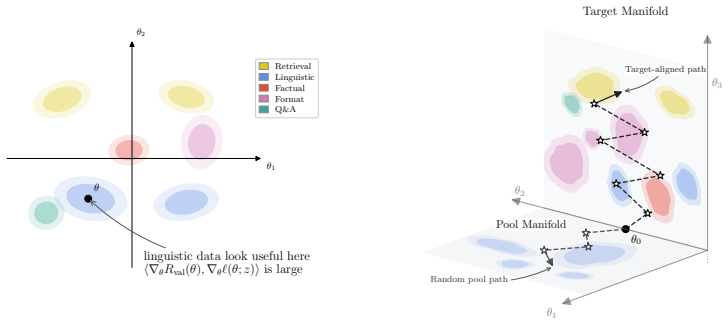





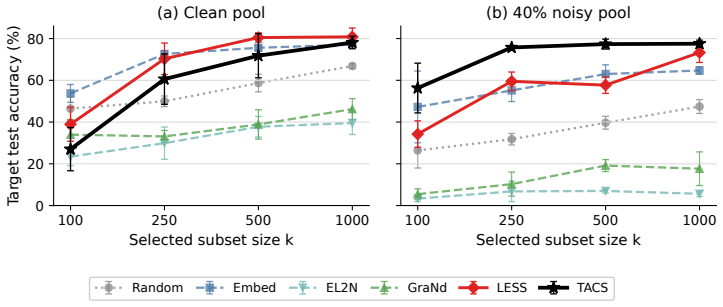
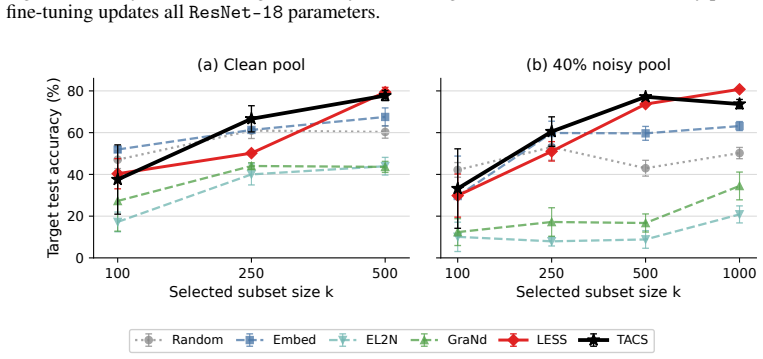


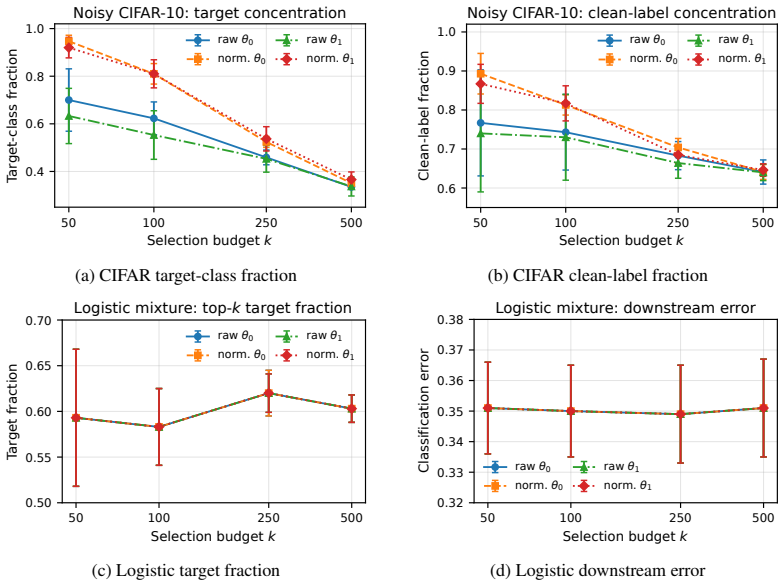
read the original abstract
Targeted data selection aims to identify training samples from a large candidate pool that improve performance on a specific downstream task. Many recent methods estimate candidate utility by aggregating local attribution scores along a trajectory induced by the candidate pool. When the pool is heterogeneous, however, this reference trajectory may be misaligned with the dynamics of a target-aligned selected subset, creating what we call reference path bias. We propose an alternative reference path: a validation-induced flow obtained from a short, capacity-limited warmup on the available target validation proxy. Along this path, candidates are scored by a normalized endpoint loss drop, yielding a simple zero-order selection rule that requires no candidate gradients or Hessian approximations. Across controlled logistic, vision, and instruction-tuning experiments, this score is competitive with strong dynamic attribution baselines while substantially reducing warmup and storage cost. Moreover, since the reference trajectory is decoupled from any specific candidate pool, the same compact warmup can be reused across additional pools without recomputing the trajectory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'target-aligned paths' for data selection: a short, capacity-limited warmup on the target validation proxy generates a reference trajectory, along which candidate samples are scored via their normalized endpoint loss drop. This zero-order rule is claimed to be competitive with dynamic attribution baselines in logistic, vision, and instruction-tuning experiments while reducing warmup and storage costs, and the trajectory can be reused across pools.
Significance. If the results hold, this provides a simple and efficient alternative to gradient-based attribution methods for targeted data selection. The decoupling of the reference path from the candidate pool is a notable strength, enabling reuse and lowering computational overhead. The approach addresses a relevant issue in data selection for heterogeneous datasets.
major comments (3)
- [§3 (Proposed Method)] The central assumption that the short capacity-limited warmup induces a flow representative of the target task's optimization dynamics is load-bearing but insufficiently validated. The skeptic note highlights that in heterogeneous pools or instruction-tuning, the loss landscape changes after the initial phase, so the induced flow may diverge. A concrete test, such as comparing trajectories from short vs. longer warmups or analyzing alignment metrics, is needed to support the claim.
- [Experiments section (likely §4)] The claim of competitive results lacks specific metrics, baseline details, and analysis of failure cases. For instance, without reported accuracy deltas, exact comparisons to methods like influence functions or TracIn, or R² values in the logistic experiments, it is difficult to assess if the data supports the competitiveness assertion.
- [§3.2 (Scoring rule)] The normalized endpoint loss drop is presented as a reliable proxy for utility, but it omits sample interactions and higher-order effects. While the paper treats these as negligible, no theoretical bounds or empirical ablation on this approximation are provided, which could undermine the zero-order rule's validity in complex settings.
minor comments (2)
- [Abstract] The abstract states 'substantially reducing warmup and storage cost' without quantifying the savings (e.g., number of epochs or memory footprint compared to baselines).
- [Notation and §3] Clarify the exact definition of the 'normalized endpoint loss drop' early in the paper, including the normalization factor and how the endpoint is chosen.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential of target-aligned paths as an efficient alternative for data selection. We address each major comment below and will revise the manuscript accordingly to strengthen the validation, quantitative details, and analysis of the proposed method.
read point-by-point responses
-
Referee: [§3 (Proposed Method)] The central assumption that the short capacity-limited warmup induces a flow representative of the target task's optimization dynamics is load-bearing but insufficiently validated. The skeptic note highlights that in heterogeneous pools or instruction-tuning, the loss landscape changes after the initial phase, so the induced flow may diverge. A concrete test, such as comparing trajectories from short vs. longer warmups or analyzing alignment metrics, is needed to support the claim.
Authors: We agree that further empirical validation of the reference path's alignment with target optimization dynamics would strengthen the paper, particularly for heterogeneous pools. In the revised manuscript, we will add direct comparisons of short versus extended warmups (e.g., 5% vs. 20% of training steps) along with alignment metrics such as average cosine similarity of parameter updates and divergence in validation loss curves. These additions will appear in Section 3 and the experimental analysis to address potential divergence concerns. revision: yes
-
Referee: [Experiments section (likely §4)] The claim of competitive results lacks specific metrics, baseline details, and analysis of failure cases. For instance, without reported accuracy deltas, exact comparisons to methods like influence functions or TracIn, or R² values in the logistic experiments, it is difficult to assess if the data supports the competitiveness assertion.
Authors: We will expand the experiments section with precise quantitative results, including accuracy deltas relative to full training and baselines, direct numerical comparisons to influence functions and TracIn (with reported values and standard deviations), and R² statistics for the logistic regression experiments. A new subsection will discuss observed failure cases and conditions under which performance degrades. revision: yes
-
Referee: [§3.2 (Scoring rule)] The normalized endpoint loss drop is presented as a reliable proxy for utility, but it omits sample interactions and higher-order effects. While the paper treats these as negligible, no theoretical bounds or empirical ablation on this approximation are provided, which could undermine the zero-order rule's validity in complex settings.
Authors: The normalized endpoint loss drop is intentionally a zero-order heuristic to avoid the computational cost of higher-order terms or pairwise interactions. While theoretical bounds on the approximation error are not derived in the current work (as the method prioritizes practicality), we will add an empirical ablation in the revised manuscript that measures the effect of sample interactions via controlled subsets and discusses limitations in highly complex or non-convex settings. revision: partial
Circularity Check
No circularity: reference path and scoring rule are direct constructions from independent validation data
full rationale
The paper defines a validation-induced flow via short capacity-limited warmup on the target validation proxy, then applies a normalized endpoint loss drop as the candidate score. This is a direct, zero-order computation on the induced trajectory and does not reduce by construction to any fitted parameter, self-citation chain, or input-derived prediction. No equations or claims in the provided text equate the output selection rule to its own inputs, rename a known result, or import uniqueness via author-overlapping citations. The method is presented as an alternative to existing attribution baselines with explicit decoupling from the candidate pool, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- warmup length
- capacity limit
axioms (2)
- domain assumption A short warmup on the target validation proxy generates a flow aligned with the target task.
- domain assumption Normalized endpoint loss drop is a valid zero-order measure of candidate utility.
invented entities (1)
-
reference path bias
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dR(θ_t) = ⟨∇R(θ_t), dθ_t⟩ = −η_t ⟨∇R(θ_t), ∇R_S(θ_t)⟩ dt; integrating yields R(θ_T) − R(θ_0) = −∫ η_t ⟨∇R, ∇R_S⟩ dt decomposed additively over examples as path-integrated alignment utility F(z,T).
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Validation-induced flow dθ_val_t = −η_t ∇R_val(θ_val_t) dt; zero-order score s(z) = [ℓ(θ_val_1;z) − ℓ(θ_val_T;z)] / max{ℓ(θ_val_1;z), ε} with LoRA capacity bottleneck.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning, 2020
Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning, 2020. URL https://arxiv.org/abs/2012. 13255. 9
work page 2020
-
[2]
arXiv preprint arXiv:2307.08701 , year=
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. Alpagasus: Training a better alpaca with fewer data, 2024. URLhttps://arxiv.org/abs/2307.08701
-
[3]
Influence-preserving proxies for gradient-based data selection in llm fine-tuning, 2026
Sirui Chen, Yunzhe Qi, Mengting Ai, Yifan Sun, Ruizhong Qiu, Jiaru Zou, and Jingrui He. Influence-preserving proxies for gradient-based data selection in llm fine-tuning, 2026. URL https://arxiv.org/abs/2602.17835
-
[4]
Task- aware data selection via proxy-label enhanced distribution matching for LLM finetuning
Hao Cheng, Rui Zhang, Ling Li, Na Di, Jiaheng Wei, Zhaowei Zhu, and Bo Han. Task- aware data selection via proxy-label enhanced distribution matching for LLM finetuning. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=R40WoYbYab
work page 2026
-
[5]
Jonathan H Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. TyDi QA: A benchmark for information-seeking question answering in typologically diverse languages.Transactions of the Association for Computational Linguistics, 8:454–470, 2020
work page 2020
-
[6]
Free Dolly: Introducing the world’s first truly open instruction-tuned LLM
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free Dolly: Introducing the world’s first truly open instruction-tuned LLM. https://www.databricks.com/blog/2023/04/ 12/dolly-first-open-commercially-viable-instruction-tuned-llm , Apr 2023. Databricks Blog
work page 2023
-
[7]
David R. Cox. The regression analysis of binary sequences.Journal of the Royal Statistical Society: Series B, 20(2):215–242, 1958
work page 1958
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
work page 2009
-
[9]
Influential language data selection via gradient trajectory pursuit, 2024
Zhiwei Deng, Tao Li, and Yang Li. Influential language data selection via gradient trajectory pursuit, 2024. URLhttps://arxiv.org/abs/2410.16710
-
[10]
Greedy information projection for llm data selection
Victor Ye Dong, Kuan-Yun Lee, Jiamei Shuai, Shen Liu, Yi Liu, and Jian Jiao. Greedy information projection for llm data selection. arXiv, March
-
[11]
URL https://www.microsoft.com/en-us/research/publication/ greedy-information-projection-for-llm-data-selection/
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Jonathan Frankle, David J. Schwab, and Ari S. Morcos. The early phase of neural network training, 2020. URLhttps://arxiv.org/abs/2002.10365
-
[14]
Gene H. Golub and Victor Pereyra. The differentiation of pseudo-inverses and nonlinear least squares problems whose variables separate.SIAM Journal on Numerical Analysis, 10(2): 413–432, 1973. doi: 10.1137/0710036
-
[15]
Jie Hao, Rui Yu, Wei Zhang, Huixia Wang, Jie Xu, and Mingrui Liu. Bliss: A lightweight bilevel influence scoring method for data selection in language model pretraining, 2026. URL https://arxiv.org/abs/2510.06048
-
[16]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[17]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InProceedings of the International Conference on Learning Representations (ICLR), 2021. 10
work page 2021
-
[18]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Train on validation (tov): Fast data selection with applications to fine-tuning, 2025
Ayush Jain, Andrea Montanari, and Eren Sasoglu. Train on validation (tov): Fast data selection with applications to fine-tuning, 2025. URLhttps://arxiv.org/abs/2510.00386
-
[20]
Grad-match: Gradient matching based data subset selection for efficient deep model training, 2021
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. Grad-match: Gradient matching based data subset selection for efficient deep model training, 2021. URLhttps://arxiv.org/abs/2103.00123
-
[21]
Glister: Generalization based data subset selection for efficient and robust learning, 2021
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer. Glister: Generalization based data subset selection for efficient and robust learning, 2021. URL https://arxiv.org/abs/2012.10630
-
[22]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1885–1894. PMLR, 06–11 Aug 2017. URLhttps://proceedings.mlr.press/v70/koh17a.html
work page 2017
-
[23]
A study of cross-validation and bootstrap for accuracy estimation and model selection
Ron Kohavi. A study of cross-validation and bootstrap for accuracy estimation and model selection. InProceedings of the 14th International Joint Conference on Artificial Intelligence, pages 1137–1145, 1995
work page 1995
-
[24]
Openassistant conversations–democratizing large language model alignment, 2023
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations–democratizing large language model alignment, 2023
work page 2023
-
[25]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[26]
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning, 2024. URL https://arxiv.org/abs/2312.15685
-
[27]
The flan collection: Designing data and methods for effective instruction tuning
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, and Adam Roberts. The flan collection: Designing data and methods for effective instruction tuning. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 22631–22648, 2023
work page 2023
-
[28]
Gist: Targeted data selection for instruction tuning via coupled optimization geometry, 2026
Guanghui Min, Tianhao Huang, Ke Wan, and Chen Chen. Gist: Targeted data selection for instruction tuning via coupled optimization geometry, 2026. URL https://arxiv.org/abs/ 2602.18584
-
[29]
Prioritized training on points that are learnable, worth learning, and not yet learnt
Sören Mindermann, Jan M Brauner, Muhammed T Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal. Prioritized training on points that are learnable, worth learning, and not yet learnt. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sab...
work page 2022
-
[30]
Coresets for data-efficient training of machine learning models, 2020
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models, 2020. URLhttps://arxiv.org/abs/1906.01827
-
[31]
Token cleaning: Fine-grained data selection for llm supervised fine-tuning
Jinlong Pang, Na Di, Zhaowei Zhu, Jiaheng Wei, Hao Cheng, Chen Qian, and Yang Liu. Token cleaning: Fine-grained data selection for llm supervised fine-tuning. InProceedings of the 42nd International Conference on Machine Learning, pages 47837–47858, 2025. URL https://arxiv.org/abs/2502.01968
-
[32]
Trak: Attributing model behavior at scale, 2023
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale, 2023. URL https://arxiv.org/abs/2303. 14186. 11
work page 2023
-
[33]
Deep learning on a data diet: Finding important examples early in training, 2023
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training, 2023. URL https://arxiv.org/abs/2107. 07075
work page 2023
-
[34]
Geoff Pleiss, Tianyi Zhang, Ethan R. Elenberg, and Kilian Q. Weinberger. Identifying mislabeled data using the area under the margin ranking, 2020. URL https://arxiv.org/abs/2001. 10528
work page 2020
-
[35]
Estimating training data influence by tracing gradient descent, 2020
Garima Pruthi, Frederick Liu, Mukund Sundararajan, and Satyen Kale. Estimating training data influence by tracing gradient descent, 2020. URLhttps://arxiv.org/abs/2002.08484
-
[36]
Meisam Razaviyayn, Mingyi Hong, and Zhi-Quan Luo. A unified convergence analysis of block successive minimization methods for nonsmooth optimization.SIAM Journal on Optimization, 23(2):1126–1153, 2013. doi: 10.1137/120891009
-
[37]
Mervyn Stone. Cross-validatory choice and assessment of statistical predictions.Journal of the Royal Statistical Society: Series B, 36(2):111–133, 1974
work page 1974
-
[38]
Challenging BIG- bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. Challenging BIG- bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
work page 2023
-
[39]
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. Dataset cartography: Mapping and diagnosing datasets with training dynamics, 2020. URLhttps://arxiv.org/abs/2009.10795
-
[40]
Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck method,
-
[41]
URLhttps://arxiv.org/abs/physics/0004057
work page internal anchor Pith review Pith/arXiv arXiv
- [42]
-
[43]
Fangxin Wang, Peyman Baghershahi, Langzhou He, Henry Peng Zou, Sourav Medya, and Philip S. Yu. Two-stage optimizer-aware online data selection for large language models, 2026. URLhttps://arxiv.org/abs/2604.00001
work page internal anchor Pith review arXiv 2026
-
[44]
Wang, Tianji Yang, James Zou, Yongchan Kwon, and Ruoxi Jia
Jiachen T. Wang, Tianji Yang, James Zou, Yongchan Kwon, and Ruoxi Jia. Rethinking data shapley for data selection tasks: Misleads and merits, 2024. URL https://arxiv.org/abs/ 2405.03875
-
[45]
NICE data selection for instruction tuning in LLMs with non-differentiable evaluation metric
Jingtan Wang, Xiaoqiang Lin, Rui Qiao, Pang Wei Koh, Chuan-Sheng Foo, and Bryan Kian Hsiang Low. NICE data selection for instruction tuning in LLMs with non-differentiable evaluation metric. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=2wt8m5HUBs
work page 2025
-
[46]
Shaobo Wang, Xuan Ouyang, Tianyi Xu, Yuzheng Hu, Jialin Liu, Guo Chen, Tianyu Zhang, Junhao Zheng, Kexin Yang, Xingzhang Ren, Dayiheng Liu, and Linfeng Zhang. Opus: Towards efficient and principled data selection in large language model pre-training in every iteration,
- [47]
-
[48]
Smith, Iz Beltagy, and Hannaneh Ha- jishirzi
Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Ha- jishirzi. How far can camels go? exploring the state of instruction tuning on open resources,
- [49]
-
[50]
Target-Oriented Pretraining Data Selection via Neuron-Activated Graph
Zijun Wang, Haoqin Tu, Weidong Zhou, Yiyang Zhou, Xiaohuan Zhou, Bingni Zhang, Weiguo Feng, Taifeng Wang, Cihang Xie, and Fengze Liu. Target-oriented pretraining data selection via neuron-activated graph, 2026. URLhttps://arxiv.org/abs/2604.15706
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URLhttps://arxiv.org/abs/2201.11903. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Rose: A reward-oriented data selection framework for llm task-specific instruction tuning, 2025
Yang Wu, Huayi Zhang, Yizheng Jiao, Lin Ma, Xiaozhong Liu, Jinhong Yu, Dongyu Zhang, Dezhi Yu, and Wei Xu. Rose: A reward-oriented data selection framework for llm task-specific instruction tuning, 2025. URLhttps://arxiv.org/abs/2412.00631
-
[53]
arXiv preprint arXiv:2402.04333 , year=
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: Selecting influential data for targeted instruction tuning, 2024. URL https://arxiv.org/ abs/2402.04333
-
[54]
Gradalign: Gradient- aligned data selection for llm reinforcement learning, 2026
Ningyuan Yang, Weihua Du, Weiwei Sun, Sean Welleck, and Yiming Yang. Gradalign: Gradient- aligned data selection for llm reinforcement learning, 2026. URL https://arxiv.org/abs/ 2602.21492
-
[55]
Bolin Zhang, Jiahao Wang, Qianlong Du, Jiajun Zhang, Zhiying Tu, and Dianhui Chu. A survey on data selection for llm instruction tuning.Journal of Artificial Intelligence Research, 83, August 2025. ISSN 1076-9757. doi: 10.1613/jair.1.17625. URL http://dx.doi.org/10. 1613/jair.1.17625
-
[56]
The best instruction-tuning data are those that fit,
Dylan Zhang, Qirun Dai, and Hao Peng. The best instruction-tuning data are those that fit, 2025. URLhttps://arxiv.org/abs/2502.04194
-
[57]
Towards understanding valuable preference data for large language model alignment,
Zizhuo Zhang, Qizhou Wang, Shanshan Ye, Jianing Zhu, Jiangchao Yao, Bo Han, and Masashi Sugiyama. Towards understanding valuable preference data for large language model alignment,
- [58]
-
[59]
arXiv preprint arXiv:2305.11206 , year=
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Lima: Less is more for alignment, 2023. URL https://arxiv.org/abs/2305.11206. 13 A Limitations While our target-aligned trajectory framework offers a highly scalable and mod...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.