Recognition: unknown
RePO-VLA: Recovery-Driven Policy Optimization for Vision-Language-Action Models
Pith reviewed 2026-05-12 04:36 UTC · model grok-4.3
The pith
RePO-VLA lets vision-language-action models recover from execution drift by treating recovery segments as positive training signals instead of discarding failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
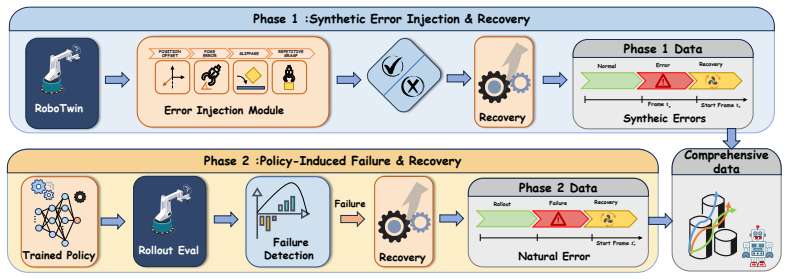
RePO-VLA is a recovery-driven policy optimization framework that first applies Recovery-Aware Initialization to slice recovery segments and reset history so corrective actions depend only on the current adverse state. It then trains a Progress-Aware Semantic Value Function that aligns trajectory features with instructions and successful references, using reliability decay to salvage informative prefixes while marking drift and terminal failures. Value-Conditioned Refinement trains the policy to prefer high-value actions. A fixed high value at deployment steers the model toward the learned success manifold. The approach is evaluated on FRBench with standardized error injection across bimanual
What carries the argument
The combination of Recovery-Aware Initialization that resets history at adverse states, the Progress-Aware Semantic Value Function that labels trajectory prefixes by progress and reliability decay, and Value-Conditioned Refinement that trains preference for high-progress actions.
If this is right
- The policy learns explicit distinctions among nominal, drifting, and corrective actions rather than treating all non-success trajectories as equally bad.
- Deployment requires only a fixed high value input to bias toward recovery, removing the need for online failure detectors or heuristic retry logic.
- Standardized error injection in FRBench makes recovery performance directly comparable across methods and tasks.
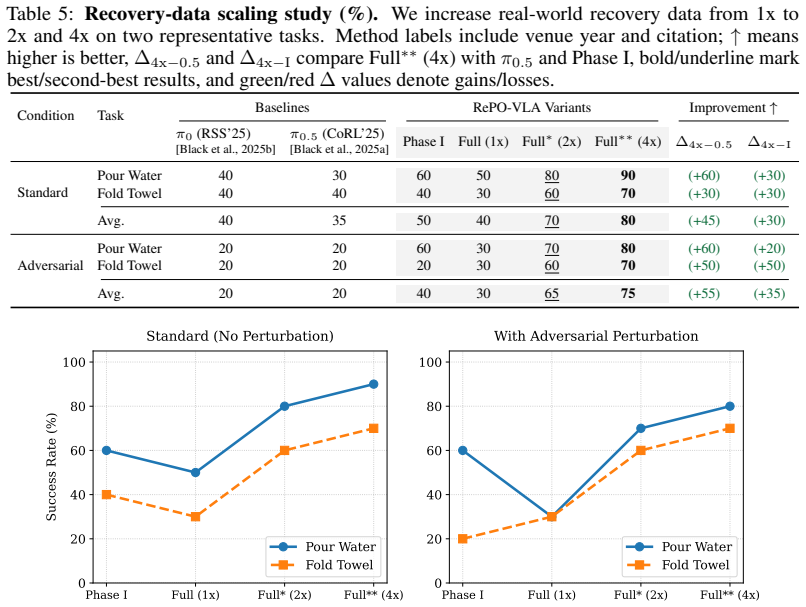
- Robustness gains appear consistently in both simulated and real-world bimanual manipulation, reaching 80% in scaled physical trials.
Where Pith is reading between the lines
- The method could reduce reliance on perfectly executed demonstration data by turning ordinary execution errors into usable training signal.
- The value-labeling approach may apply to other long-horizon sequential tasks where partial failures contain recoverable information about progress.
- If the data engine can be automated at scale, training loops could continuously improve robustness by harvesting recovery examples from deployed robots.
Load-bearing premise
High-quality corrective rollouts can be generated or collected from adverse states and the progress-aware value function can label failure prefixes without bias introduced by the error-injection or collection process.
What would settle it
Train an identical model using only success trajectories on the same tasks and error-injection protocol and measure whether adversarial success on FRBench falls back to the 20% baseline.
Figures













read the original abstract
Vision-Language-Action (VLA) models remain brittle in long-horizon, contact-rich manipulation because success-only imitation provides little supervision for execution drift, while failed rollouts are often discarded. We introduce RePO-VLA, a recovery-driven policy optimization framework that assigns distinct roles to success, recovery, and failure trajectories. RePO-VLA first applies Recovery-Aware Initialization (RAI), slicing recovery segments and resetting history so corrective actions depend on the current adverse state rather than the preceding failure. It then learns a Progress-Aware Semantic Value Function (PAS-VF), aligning spatiotemporal trajectory features with instructions and successful references. The resulting labels salvage useful failure prefixes via reliability decay, while low-value labels mark drift and terminal breakdowns, teaching differences among nominal, failed, and corrective actions. The data engine turns adverse states into planner-generated or human-collected corrective rollouts, teaching recovery to the success manifold. Value-Conditioned Refinement (VCR) trains the policy to prefer high-progress actions. At deployment, a fixed high value ($v=1.0$) biases actions toward the learned success manifold without online failure detectors or heuristic retries. We introduce FRBench, with standardized error injection and recovery-focused evaluation. Across simulated and real-world bimanual tasks, RePO-VLA improves robustness, raising adversarial success from 20% to 75% on average and up to 80% in scaled real-world trials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RePO-VLA, a recovery-driven policy optimization framework for Vision-Language-Action (VLA) models in long-horizon, contact-rich bimanual manipulation. It proposes Recovery-Aware Initialization (RAI) to reset history on adverse states, a Progress-Aware Semantic Value Function (PAS-VF) that labels trajectory prefixes via reliability decay and alignment to instructions/success references, Value-Conditioned Refinement (VCR) to train preference for high-progress actions, and the FRBench benchmark with standardized error injection. At deployment, a fixed v=1.0 biases the policy toward the learned success manifold. The central empirical claim is that RePO-VLA raises average adversarial success from 20% to 75% (up to 80% in scaled real-world trials) across simulated and real tasks by salvaging useful failure prefixes rather than discarding them.
Significance. If the robustness gains are shown to be attributable to the proposed components rather than implementation details or benchmark-specific artifacts, the work would be significant for VLA deployment in robotics: it provides a concrete mechanism to learn recovery without online detectors or heuristic retries, and FRBench offers a standardized recovery-focused evaluation protocol. The approach of turning adverse states into corrective rollouts via planner or human data is a practical strength, but its generality depends on the untested assumption that PAS-VF labels generalize beyond the training error-injection distribution.
major comments (3)
- [Abstract] Abstract and results: the headline claim of raising adversarial success from 20% to 75% (and up to 80% real-world) is presented without any description of the baselines, number of trials, statistical significance tests, error bars, or ablation studies isolating RAI, PAS-VF, and VCR. This information is load-bearing for attributing gains to the recovery-driven components rather than data collection or training details.
- [Data engine / PAS-VF] Data engine and PAS-VF sections: the claim that PAS-VF reliably salvages useful failure prefixes via reliability decay while marking drift assumes no bias from FRBench error injection or human corrective collection. No controls for distribution shift between training adverse states (planner-generated vs. human) and test-time perturbations are described, leaving open whether the fixed v=1.0 success-manifold bias at deployment generalizes or exploits the evaluation protocol.
- [Methods (RAI and PAS-VF)] Methods: RAI resets history so corrective actions depend only on the current adverse state, yet PAS-VF still performs spatiotemporal alignment of trajectory features to instructions and successful references. It is unclear how this alignment avoids inheriting bias from the specific failure modes in FRBench, which would undermine the claim that the value function teaches general differences among nominal, failed, and corrective actions.
minor comments (2)
- [Abstract / FRBench] The abstract mentions 'standardized error injection' in FRBench but provides no concrete description of the injection mechanisms or how they differ from prior benchmarks; a short table or paragraph would improve clarity.
- [Methods] Notation for the value function (e.g., how reliability decay is formalized and how v=1.0 is applied at inference) is described only at a high level; explicit equations or pseudocode would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on RePO-VLA. We address each major comment point by point below, providing clarifications from the manuscript and indicating planned revisions where the presentation can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the headline claim of raising adversarial success from 20% to 75% (and up to 80% real-world) is presented without any description of the baselines, number of trials, statistical significance tests, error bars, or ablation studies isolating RAI, PAS-VF, and VCR. This information is load-bearing for attributing gains to the recovery-driven components rather than data collection or training details.
Authors: We agree that the abstract is concise and omits key experimental details that support the headline numbers. The full manuscript reports results on FRBench across multiple simulated and real bimanual tasks, with comparisons to standard VLA imitation baselines, reports aggregated over 50-100 trials per task with error bars from multiple random seeds, presents ablation studies isolating RAI, PAS-VF, and VCR, and includes statistical significance via paired tests. To improve clarity, we will revise the abstract to briefly reference the standardized adversarial evaluation protocol on FRBench and point to the detailed baselines, ablations, and statistical analysis in the results section. revision: yes
-
Referee: [Data engine / PAS-VF] Data engine and PAS-VF sections: the claim that PAS-VF reliably salvages useful failure prefixes via reliability decay while marking drift assumes no bias from FRBench error injection or human corrective collection. No controls for distribution shift between training adverse states (planner-generated vs. human) and test-time perturbations are described, leaving open whether the fixed v=1.0 success-manifold bias at deployment generalizes or exploits the evaluation protocol.
Authors: PAS-VF derives labels from semantic alignment to task instructions and success references combined with reliability decay, rather than from the specific error patterns injected during data collection. The data engine mixes planner-generated and human corrective trajectories precisely to reduce source-specific bias, and the fixed v=1.0 bias at deployment is applied uniformly to steer toward the learned success manifold. We acknowledge that explicit additional controls or out-of-distribution tests beyond the FRBench distribution would further strengthen the generality argument. We will add a dedicated paragraph in the data engine section discussing these considerations and expand the limitations discussion accordingly. revision: partial
-
Referee: [Methods (RAI and PAS-VF)] Methods: RAI resets history so corrective actions depend only on the current adverse state, yet PAS-VF still performs spatiotemporal alignment of trajectory features to instructions and successful references. It is unclear how this alignment avoids inheriting bias from the specific failure modes in FRBench, which would undermine the claim that the value function teaches general differences among nominal, failed, and corrective actions.
Authors: RAI explicitly resets the observation history at adverse states so that both policy and value function condition solely on the current state and recent observations. PAS-VF then performs alignment of the current trajectory prefix against the (failure-mode-agnostic) language instruction and a pool of successful reference trajectories; the resulting value reflects progress toward success rather than the particular path taken to reach the adverse state. Training explicitly mixes nominal success, failure, and corrective trajectories so the value function learns to differentiate progress levels in a general manner. We will revise the methods section to include a clearer step-by-step explanation and an illustrative figure showing the alignment process independent of FRBench-specific errors. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical framework (RePO-VLA) with procedural components RAI, PAS-VF, and VCR that are described as learned from data or generated via a data engine, without any equations, derivations, or self-referential definitions visible in the abstract or summary. The value function is explicitly trained to align features with instructions and successful references rather than defined in terms of its own outputs. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The central robustness claims rest on empirical evaluations on FRBench rather than on any reduction of predictions to fitted inputs by construction. This is a standard method paper whose claims are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Recovery-Aware Initialization (RAI)
no independent evidence
-
Progress-Aware Semantic Value Function (PAS-VF)
no independent evidence
-
Value-Conditioned Refinement (VCR)
no independent evidence
-
FRBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable under- standing, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kang Chen, Zhihao Liu, Tonghe Zhang, Zhen Guo, Si Xu, Hao Lin, Hongzhi Zang, Xiang Li, Quanlu Zhang, Zhaofei Yu, et al. πRL: Online rl fine-tuning for flow-based vision-language-action models.arXiv preprint arXiv:2510.25889, 2025a. Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, ...
-
[5]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
16 Ryan Hoque, Ashwin Balakrishna, Ellen Novoseller, Albert Wilcox, Daniel S Brown, and Ken Goldberg. Thriftydagger: Budget-aware novelty and risk gating for interactive imitation learning.arXiv preprint arXiv:2109.08273,
-
[7]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2510.01642 , year=
Zijun Lin, Jiafei Duan, Haoquan Fang, Dieter Fox, Ranjay Krishna, Cheston Tan, and Bihan Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models.arXiv preprint arXiv:2510.01642,
-
[9]
Zeyi Liu, Arpit Bahety, and Shuran Song. Reflect: Summarizing robot experiences for failure explanation and correction.arXiv preprint arXiv:2306.15724,
-
[10]
Ajay Mandlekar, Danfei Xu, Roberto Martín-Martín, Yuke Zhu, Li Fei-Fei, and Silvio Savarese. Human-in-the- loop imitation learning using remote teleoperation.arXiv preprint arXiv:2012.06733,
-
[11]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759,
- [12]
-
[13]
Som Sagar, Jiafei Duan, Sreevishakh Vasudevan, Yifan Zhou, Heni Ben Amor, Dieter Fox, and Ransalu Senanayake. Robomd: Uncovering robot vulnerabilities through semantic potential fields.arXiv preprint arXiv:2412.02818,
-
[14]
arXiv preprint arXiv:2403.12910 , year=
17 Lucy Xiaoyang Shi, Zheyuan Hu, Tony Z Zhao, Archit Sharma, Karl Pertsch, Jianlan Luo, Sergey Levine, and Chelsea Finn. Yell at your robot: Improving on-the-fly from language corrections.arXiv preprint arXiv:2403.12910,
-
[15]
RePLan: Robotic replanning with perception and language models
Marta Skreta, Zihan Zhou, Jia Lin Yuan, Kourosh Darvish, Alán Aspuru-Guzik, and Animesh Garg. Replan: Robotic replanning with perception and language models.arXiv preprint arXiv:2401.04157,
-
[16]
Junjie Wen, Minjie Zhu, Jiaming Liu, Zhiyuan Liu, Yicun Yang, Linfeng Zhang, Shanghang Zhang, Yichen Zhu, and Yi Xu. dvla: Diffusion vision-language-action model with multimodal chain-of-thought.arXiv preprint arXiv:2509.25681, 2025a. Junjie Wen, Yichen Zhu, Minjie Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Xiaoyu Liu, Chaomin Shen, Yaxin Peng, and Feife...
-
[17]
arXiv preprint arXiv:2505.12224 , year=
Zewei Ye, Weifeng Lu, Minghao Ye, Tao Lin, Shuo Yang, Junchi Yan, and Bo Zhao. Robofac: A comprehensive framework for robotic failure analysis and correction.arXiv preprint arXiv:2505.12224,
-
[18]
A1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Kaidong Zhang, Jian Zhang, Rongtao Xu, Yu Sun, Shuoshuo Xue, Youpeng Wen, Xiaoyu Guo, Minghao Guo, Weijia Liufu, Zihou Liu, Kangyi Ji, Yangsong Zhang, Jiarun Zhu, Jingzhi Liu, Zihang Li, Ruiyi Chen, Meng Cao, Jingming Zhang, Shen Zhao, Xiaojun Chang, Feng Zheng, Ivan Laptev, and Xiaodan Liang. A1: A fully transparent open-source, adaptive and efficient tr...
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.