Recognition: no theorem link
MAG-VLAQ: Multi-modal Aerial-Ground Query Aggregation for Cross-View Place Recognition
Pith reviewed 2026-05-12 02:52 UTC · model grok-4.3
The pith
MAG-VLAQ uses foundation-model tokens and ODE-conditioned query aggregation to achieve much higher accuracy in aerial-ground place recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that leveraging pre-trained foundation models to extract dense visual tokens from ground and aerial images plus geometric tokens from LiDAR, projecting them into a shared embedding space, and then tightly coupling neural ODE-based RGB-LiDAR fusion with vectors of locally aggregated queries produces global descriptors that preserve globally learned retrieval prototypes while remaining responsive to scene-specific visual and geometric evidence, thereby significantly improving aerial-ground matching.
What carries the argument
ODE-conditioned VLAQ, which dynamically adapts the centers of vectors of locally aggregated queries according to the state produced by neural ordinary differential equations fusing RGB and LiDAR information.
If this is right
- The final global descriptor preserves learned retrieval prototypes while adapting to scene-specific evidence.
- The method achieves 61.1 Recall@1 on the KITTI360-AG satellite setting, nearly double the 34.5 of the closest prior approach.
- Performance gains are also shown on the nuScenes-AG benchmark.
- Pre-trained foundation models supply tokens that become aligned and fused for cross-modal retrieval without losing their general knowledge.
Where Pith is reading between the lines
- The same ODE-driven adaptation of query centers could be tested on other cross-modal tasks such as matching images to point clouds from different platforms.
- If the dynamic adaptation proves robust, similar mechanisms might improve single-modality place recognition when training data are limited.
- The framework implies that continuous fusion via differential equations can make discrete token aggregation more responsive to local geometry.
Load-bearing premise
Projecting heterogeneous tokens from separate foundation models into a shared embedding space and then dynamically adapting VLAQ centers via ODE-based RGB-LiDAR fusion will produce descriptors that generalize across viewpoint and modality gaps without introducing new alignment errors or overfitting to the training scenes.
What would settle it
Evaluating MAG-VLAQ on an independent aerial-ground dataset recorded in unseen environments or with different sensor characteristics and finding that its Recall@1 improvement over the next-best method falls below 20 percent.
Figures



read the original abstract
Multi-modal cross-view place recognition remains a fundamental challenge in computer vision and robotics due to the severe viewpoint, modality, and spatial-structure discrepancies between ground observations and aerial references. To address this challenge, we present MAG-VLAQ, a foundation-model-enhanced query aggregation framework for multi-modal aerial-ground cross-view place recognition. Specifically, our approach leverages pre-trained foundation models to extract dense visual tokens from both ground and aerial images, as well as expressive geometric tokens from ground LiDAR observations. These heterogeneous tokens are then projected into a shared embedding space for cross-modal alignment and fusion. As our main contribution, we propose ODE-conditioned VLAQ, which tightly couples neural ordinary differential equations (ODE)-based RGB-LiDAR fusion with vectors of locally aggregated queries (VLAQ). In this design, the VLAQ query centers are dynamically adapted according to the fused multi-modal state. This mechanism allows the final global descriptor to preserve globally learned retrieval prototypes while remaining responsive to scene-specific visual and geometric evidence, significantly improving aerial-ground matching. Extensive experiments on KITTI360-AG and nuScenes-AG validate the effectiveness of our proposed MAG-VLAQ. Notably, on KITTI360-AG, our MAG-VLAQ nearly doubles the state-of-the-art performance, achieving 61.1 Recall@1 in the satellite setting, compared with 34.5 from the closest competing approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to introduce MAG-VLAQ, a multi-modal query aggregation framework for cross-view place recognition that leverages pre-trained foundation models for token extraction from RGB and LiDAR data, projects them into a shared space, and uses ODE-conditioned VLAQ to dynamically adapt query centers for better fusion and descriptor generation. It reports substantial performance improvements on KITTI360-AG and nuScenes-AG, nearly doubling the state-of-the-art Recall@1 to 61.1 in the satellite setting.
Significance. Should the central claims hold upon verification, this work would represent a meaningful advance in multi-modal cross-view place recognition by showing how neural ODEs can be integrated with aggregated query vectors to handle modality and viewpoint gaps. The use of foundation models and the dynamic adaptation mechanism could influence future designs in visual localization for robotics. The reported performance jump indicates high potential impact if the mechanism is shown to be the causal factor.
major comments (2)
- [Abstract and §3.3] Abstract and §3.3 (ODE-conditioned VLAQ): The central claim that the ODE-based RGB-LiDAR fusion dynamically adapts VLAQ centers to produce descriptors that close the viewpoint/modality gap without new alignment errors is load-bearing for the reported 61.1 vs. 34.5 Recall@1 gain, yet the manuscript provides no direct supporting measurements such as pre/post-ODE alignment error, center-shift statistics, or an ablation isolating the ODE component from the foundation-model backbones.
- [§4] §4 (Experiments on KITTI360-AG): The headline result is presented without failure-case analysis or out-of-distribution geometry tests that would confirm the adaptation step generalizes rather than overfitting to the training scenes, undermining attribution of the doubling to the proposed mechanism.
minor comments (2)
- [Figure 1] The caption of the overall architecture figure should explicitly label the ODE module and the flow of VLAQ center adaptation.
- [§3.2] Notation for the shared embedding projection and VLAQ query centers could be introduced with a single equation in §3.2 for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract and §3.3] Abstract and §3.3 (ODE-conditioned VLAQ): The central claim that the ODE-based RGB-LiDAR fusion dynamically adapts VLAQ centers to produce descriptors that close the viewpoint/modality gap without new alignment errors is load-bearing for the reported 61.1 vs. 34.5 Recall@1 gain, yet the manuscript provides no direct supporting measurements such as pre/post-ODE alignment error, center-shift statistics, or an ablation isolating the ODE component from the foundation-model backbones.
Authors: We agree that direct measurements would provide stronger causal evidence for the ODE's role in the reported gains. The current manuscript validates overall effectiveness through end-to-end comparisons on two benchmarks, but lacks the specific pre/post-ODE alignment error, center-shift statistics, and isolated ODE ablation requested. In the revised version we will add these analyses, including quantitative center-shift distributions and alignment error reductions attributable to the ODE conditioning, to better substantiate the dynamic adaptation mechanism. revision: yes
-
Referee: [§4] §4 (Experiments on KITTI360-AG): The headline result is presented without failure-case analysis or out-of-distribution geometry tests that would confirm the adaptation step generalizes rather than overfitting to the training scenes, undermining attribution of the doubling to the proposed mechanism.
Authors: We acknowledge that explicit failure-case analysis and out-of-distribution tests would strengthen claims of generalization. Our evaluation already spans two datasets with differing characteristics (KITTI360-AG and nuScenes-AG), but does not include dedicated failure modes or OOD geometry experiments. We will add a new subsection with failure-case visualizations, quantitative error breakdowns, and additional OOD tests in the revised manuscript to better demonstrate that the performance improvements arise from the proposed adaptation rather than scene-specific overfitting. revision: yes
Circularity Check
No circularity: derivation relies on external pre-trained models and empirical validation
full rationale
The paper extracts tokens from separate pre-trained foundation models, projects them into a shared space, and introduces a new ODE-based conditioning mechanism on VLAQ centers for RGB-LiDAR fusion. No step defines a quantity in terms of the target retrieval metric or renames a fitted parameter as a prediction. No self-citation is used to justify uniqueness or load-bearing assumptions. The reported gains (e.g., 61.1 R@1) are presented as outcomes of experiments on KITTI360-AG and nuScenes-AG rather than algebraic identities or self-referential fits. The chain is therefore self-contained against external benchmarks and pre-trained components.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Ali-bey, B. Chaib-draa, and P. Giguère. GSV-Cities: Toward appropriate supervised visual place recognition.Neurocomputing, 513:194–203, 2022. doi: 10.1016/j.neucom.2022.09.127
-
[2]
Localized gaussian splatting editing with contextual awareness
A. Ali-bey, B. Chaib-draa, and P. Giguère. MixVPR: Feature mixing for visual place recognition. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2998–3007, 2023. doi: 10.1109/W ACV56688.2023.00301
work page doi:10.1109/w 2023
-
[3]
In: 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
A. Ali-bey, B. Chaib-draa, and P. Giguère. BoQ: A place is worth a bag of learnable queries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17794–17803, 2024. doi: 10.1109/CVPR52733.2024.01685
-
[4]
R. Arandjelovi´c, P. Gronat, A. Torii, T. Pajdla, and J. Sivic. NetVLAD: CNN architecture for weakly supervised place recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5297–5307, 2016. doi: 10.1109/CVPR.2016.572
-
[5]
nuScenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11618–11628, 2020. doi: 10.1109/CVPR42600.2020.01164
- [6]
-
[7]
A. García-Hernández, R. Giubilato, K. H. Strobl, J. Civera, and R. Triebel. Unifying local and global multimodal features for place recognition in aliased and low-texture environments. InProceedings of the IEEE International Conference on Robotics and Automation, pages 3991–3998, 2024. doi: 10.1109/ICRA57147.2024.10611563
-
[8]
S. Garg, T. Fischer, and M. Milford. Where is your place, visual place recognition? In30th International Joint Conference on Artificial Intelligence (IJCAI-21), 2021
work page 2021
-
[9]
S. Hu, M. Feng, R. M. H. Nguyen, and G. H. Lee. CVM-Net: Cross-view matching network for image-based ground-to-aerial geo-localization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7258–7267, 2018
work page 2018
-
[10]
S. Izquierdo and J. Civera. Close, but not there: Boosting geographic distance sensitivity in visual place recognition. InComputer Vision – ECCV 2024, pages 240–257, 2024. doi: 10.1007/978-3-031-73464-9_15
-
[11]
S. Izquierdo and J. Civera. Optimal transport aggregation for visual place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17658–17668, 2024
work page 2024
-
[12]
M. Jung, L. F. T. Fu, M. Fallon, and A. Kim. ImLPR: Image-based LiDAR place recognition using vision foundation models. InProceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 3318–3340, 2025
work page 2025
-
[13]
H. Jégou, M. Douze, C. Schmid, and P. Pérez. Aggregating local descriptors into a compact image representation. In2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 3304–3311, 2010. doi: 10.1109/CVPR.2010.5540039
-
[14]
N. Keetha, A. Mishra, J. Karhade, K. M. Jatavallabhula, S. Scherer, M. Krishna, and S. Garg. AnyLoc: Towards universal visual place recognition.IEEE Robotics and Automation Letters, 9 (2):1286–1293, 2023. doi: 10.1109/LRA.2023.3343602
-
[15]
J. Komorowski. Improving point cloud based place recognition with ranking-based loss and large batch training. InProceedings of the 26th International Conference on Pattern Recognition, pages 3699–3705, 2022. doi: 10.1109/ICPR56361.2022.9956458
-
[16]
J. Komorowski, M. Wysoczanska, and T. Trzcinski. MinkLoc++: Lidar and monocular image fusion for place recognition. arXiv preprint arXiv:2104.05327, 2021. URL https://arxiv. org/abs/2104.05327. 10
- [17]
-
[18]
G. Li, M. Qian, and G.-S. Xia. Unleashing unlabeled data: A paradigm for cross-view geo- localization. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16719–16729, 2024. doi: 10.1109/CVPR52733.2024.01582
-
[19]
Y .-J. Li, M. Gladkova, Y . Xia, R. Wang, and D. Cremers. VXP: V oxel-cross-pixel large- scale camera-lidar place recognition. In2025 International Conference on 3D Vision, pages 1233–1242, 2025. doi: 10.1109/3DV66043.2025.00117
- [20]
-
[21]
Y . Liao, J. Xie, and A. Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2023. doi: 10.1109/TPAMI.2022.3179507
-
[22]
P. Lindenberger, P.-E. Sarlin, J. Hosang, M. Balice, M. Pollefeys, S. Lynen, and E. Trulls. Scaling image geo-localization to continent level. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025), 2025
work page 2025
- [23]
-
[24]
S. Lowry, N. Sünderhauf, P. Newman, J. J. Leonard, D. Cox, P. Corke, and M. J. Milford. Visual place recognition: A survey.IEEE Transactions on Robotics, 32(1):1–19, 2016. doi: 10.1109/TRO.2015.2496823
-
[25]
F. Lu, X. Lan, L. Zhang, D. Jiang, Y . Wang, and C. Yuan. CricaVPR: Cross-image correlation- aware representation learning for visual place recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16772–16782, 2024
work page 2024
-
[26]
F. Lu, L. Zhang, X. Lan, S. Dong, Y . Wang, and C. Yuan. Towards seamless adaptation of pre-trained models for visual place recognition. InInternational Conference on Learning Representations, 2024
work page 2024
-
[27]
F. Lu, T. Jin, X. Lan, L. Zhang, Y . Liu, Y . Wang, and C. Yuan. SelaVPR++: Towards seamless adaptation of foundation models for efficient place recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. doi: 10.1109/TPAMI.2025.3629287
-
[28]
S. Lu, X. Xu, H. Yin, Z. Chen, R. Xiong, and Y . Wang. One ring to rule them all: Radon sinogram for place recognition, orientation and translation estimation. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2778–2785, 2022. doi: 10.1109/IROS47612.2022.9981308
- [29]
-
[30]
L. Luo, S. Zheng, Y . Li, Y . Fan, B. Yu, S.-Y . Cao, J. Li, and H.-L. Shen. BEVPlace: Learning lidar-based place recognition using bird’s eye view images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8700–8709, 2023
work page 2023
- [31]
-
[32]
A. Melekhin, D. A. Yudin, I. Petryashin, and V . D. Bezuglyj. MSSPlace: Multi-sensor place recognition with visual and text semantics.IEEE Access, 13:177098–177110, 2025. doi: 10.1109/ACCESS.2025.3618728. 11
-
[33]
L. Mi, C. Xu, J. Castillo-Navarro, S. Montariol, W. Yang, A. Bosselut, and D. Tuia. Congeo: Robust cross-view geo-localization across ground view variations. InComputer Vision – ECCV 2024, pages 214–230, 2025
work page 2024
-
[34]
M. Milford and T. Fischer. Going places: Place recognition in artificial and natural systems. Annual Review of Control, Robotics, and Autonomous Systems, 9, 2025
work page 2025
-
[35]
Y . Ming, X. Yang, G. Zhang, and A. Calway. Cgis-net: Aggregating colour, geometry and implicit semantic features for indoor place recognition. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6991–6997, 2022. doi: 10.1109/ IROS47612.2022.9981113
-
[36]
Y . Ming, J. Ma, X. Yang, W. Dai, Y . Peng, and W. Kong. Aegis-net: Attention-guided multi-level feature aggregation for indoor place recognition. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4030–4034, 2024. doi: 10.1109/ICASSP48485.2024.10447578
- [37]
-
[38]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jégou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without super...
work page 2024
- [39]
-
[40]
F. Radenovi´c, G. Tolias, and O. Chum. Fine-tuning cnn image retrieval with no human annotation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(7):1655–1668,
-
[41]
doi: 10.1109/TPAMI.2018.2846566
-
[42]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 8748–8763, 2021
work page 2021
- [43]
-
[44]
S. Schubert, P. Neubert, S. Garg, M. Milford, and T. Fischer. Visual place recognition: A tutorial [tutorial].IEEE Robotics & Automation Magazine, 31(3):139–153, 2023
work page 2023
-
[45]
P. Serio, G. Pisaneschi, A. D. Ryals, V . Infantino, L. Gentilini, V . Donzella, and L. Pollini. Polar perspectives: Evaluating 2-d lidar projections for robust place recognition with visual foundation models. arXiv preprint arXiv:2512.02897, 2025. URL https://arxiv.org/abs/ 2512.02897
-
[46]
Y . Shi, L. Liu, X. Yu, and H. Li. Spatial-aware feature aggregation for image based cross-view geo-localization. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[47]
Y . Shi, X. Yu, L. Liu, T. Zhang, and H. Li. Optimal feature transport for cross-view image geo-localization. InProceedings of the AAAI Conference on Artificial Intelligence, pages 11990–11997, 2020. doi: 10.1609/aaai.v34i07.6875
-
[48]
S. Shubodh, M. Omama, H. Zaidi, U. S. Parihar, and M. Krishna. LIP-Loc: Lidar image pretraining for cross-modal localization. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, pages 948–957, 2024
work page 2024
-
[49]
M. Shugaev, I. Semenov, K. Ashley, M. Klaczynski, N. Cuntoor, M. W. Lee, and N. Jacobs. ArcGeo: Localizing limited field-of-view images using cross-view matching. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 209–218, 2024. 12
work page 2024
-
[50]
J. Sivic and A. Zisserman. Efficient visual search of videos cast as text retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(4):591–606, 2009. doi: 10.1109/ TPAMI.2008.111
work page 2009
-
[51]
L. Suomela, J. Kalliola, H. Edelman, and J.-K. Kämäräinen. Placenav: Topological navigation through place recognition. InIEEE International Conference on Robotics and Automation (ICRA), 2024. URLhttps://arxiv.org/abs/2309.17260
-
[52]
A. Torii, J. Sivic, T. Pajdla, and M. Okutomi. Visual place recognition with repetitive structures. In2013 IEEE Conference on Computer Vision and Pattern Recognition, pages 883–890, 2013. doi: 10.1109/CVPR.2013.119
- [53]
-
[54]
doi: 10.1109/TPAMI.2017.2667665
-
[55]
M. A. Uy and G. H. Lee. Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4470–4479, 2018. doi: 10.1109/CVPR.2018.00470
-
[56]
S. Wang, R. She, Q. Kang, S. Li, D. Li, T. Geng, S. Yu, and W. P. Tay. Multi-modal aerial-ground cross-view place recognition with neural odes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11717–11728, 2025
work page 2025
-
[57]
T. Wang, Z. Zheng, C. Yan, J. Zhang, Y . Sun, B. Zheng, and Y . Yang. Each part matters: Local patterns facilitate cross-view geo-localization.IEEE Transactions on Circuits and Systems for Video Technology, 32(2):867–879, 2022. doi: 10.1109/TCSVT.2021.3061265
-
[58]
nuScenes: A multimodal dataset for autonomous driving,
F. Warburg, S. Hauberg, M. López-Antequera, P. Gargallo, Y . Kuang, and J. Civera. Mapillary street-level sequences: A dataset for lifelong place recognition. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2623–2632, 2020. doi: 10.1109/ CVPR42600.2020.00270
-
[59]
S. Workman, R. Souvenir, and N. Jacobs. Wide-area image geolocalization with aerial reference imagery. InProceedings of the IEEE International Conference on Computer Vision, pages 3961–3969, 2015
work page 2015
- [60]
-
[61]
W. Xie, L. Luo, N. Ye, Y . Ren, S. Du, M. Wang, J. Xu, R. Ai, W. Gu, and X. Chen. ModaLink: Unifying modalities for efficient image-to-pointcloud place recognition. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3326–3333, 2024. doi: 10.1109/IROS58592.2024.10801556
-
[62]
X. Xu, S. Lu, J. Wu, H. Lu, Q. Zhu, Y . Liao, R. Xiong, and Y . Wang. Ring++: Roto-translation invariant gram for global localization on a sparse scan map.IEEE Transactions on Robotics, 39 (6):4616–4635, 2023. doi: 10.1109/TRO.2023.3303035
-
[63]
H. Yang, X. Lu, and Y . Zhu. Cross-view geo-localization with layer-to-layer transformer. In Advances in Neural Information Processing Systems, volume 34, pages 29009–29020, 2021
work page 2021
-
[64]
J. Ye, Z. Lv, W. Li, J. Yu, H. Yang, H. Zhong, and C. He. Cross-view image geo-localization with panorama-bev co-retrieval network. InComputer Vision – ECCV 2024, pages 74–90, 2025
work page 2024
- [65]
-
[66]
Q. Zhang and Y . Zhu. Aligning geometric spatial layout in cross-view geo-localization via feature recombination.Proceedings of the AAAI Conference on Artificial Intelligence, 38(7): 7251–7259, 2024. doi: 10.1609/aaai.v38i7.28554. 13
-
[67]
X. Zhang, X. Li, W. Sultani, Y . Zhou, and S. Wshah. Cross-view geo-localization via learning disentangled geometric layout correspondence.Proceedings of the AAAI Conference on Artificial Intelligence, 37(3):3480–3488, 2023. doi: 10.1609/aaai.v37i3.25457
- [68]
-
[69]
Z. Zhou, J. Xu, G. Xiong, and J. Ma. LCPR: A multi-scale attention-based lidar-camera fusion network for place recognition.IEEE Robotics and Automation Letters, 9(2):1342–1349, 2024. doi: 10.1109/LRA.2023.3346753
- [70]
-
[71]
S. Zhu, T. Yang, and C. Chen. VIGOR: Cross-view image geo-localization beyond one-to- one retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3640–3649, 2021
work page 2021
-
[72]
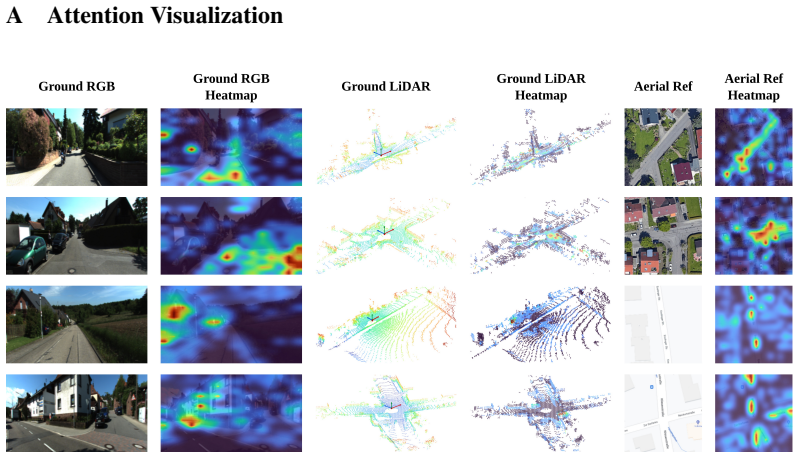
S. Zhu, M. Shah, and C. Chen. TransGeo: Transformer is all you need for cross-view image geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1162–1171, 2022. 14 A Attention Visualization Figure 4: Attention Visualization Fig. 4 provides qualitative attention visualizations for the ground RGB image, ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.