Recognition: no theorem link
AtteConDA: Attention-Based Conflict Suppression in Multi-Condition Diffusion Models and Synthetic Data Augmentation
Pith reviewed 2026-05-12 02:34 UTC · model grok-4.3
The pith
An attention mechanism in multi-condition diffusion models suppresses conflicts between segmentation, depth, and edge inputs to preserve more scene structure in generated driving images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
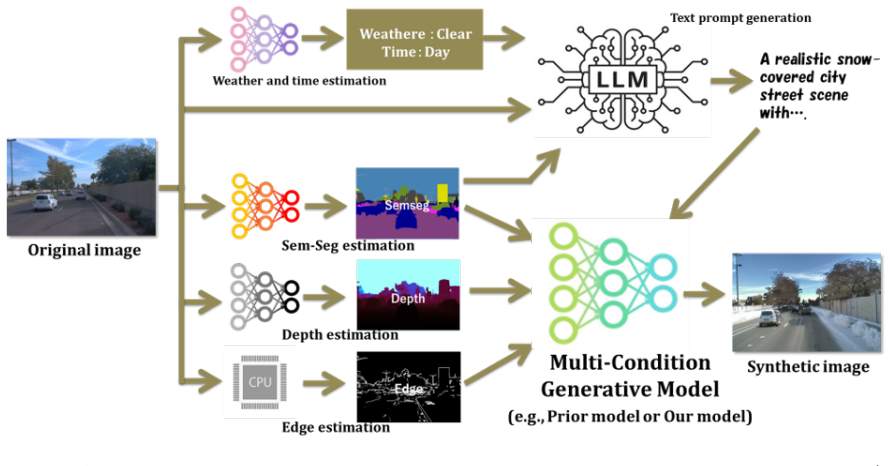
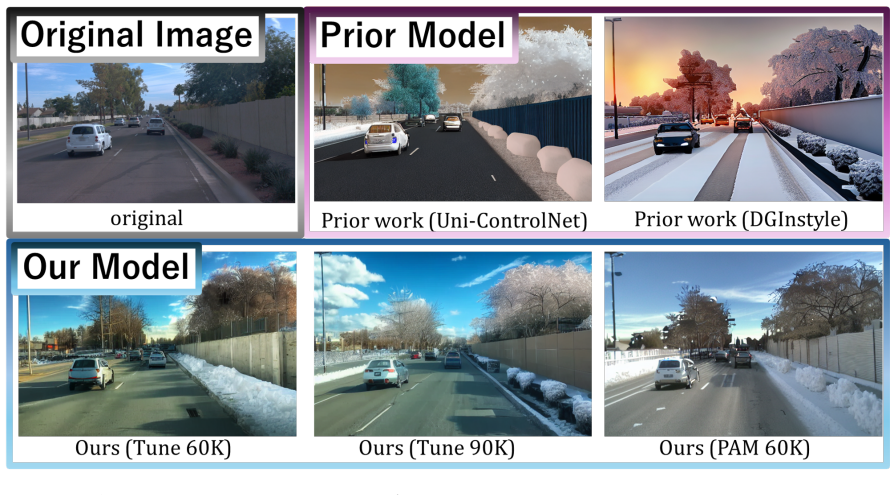
Inputting semantic segmentation, depth, and edge maps extracted from an original driving image into a diffusion model, combined with an attention-based conflict suppression step, produces generated images that retain stronger high-level structural cues than single-condition or unadjusted multi-condition baselines.
What carries the argument
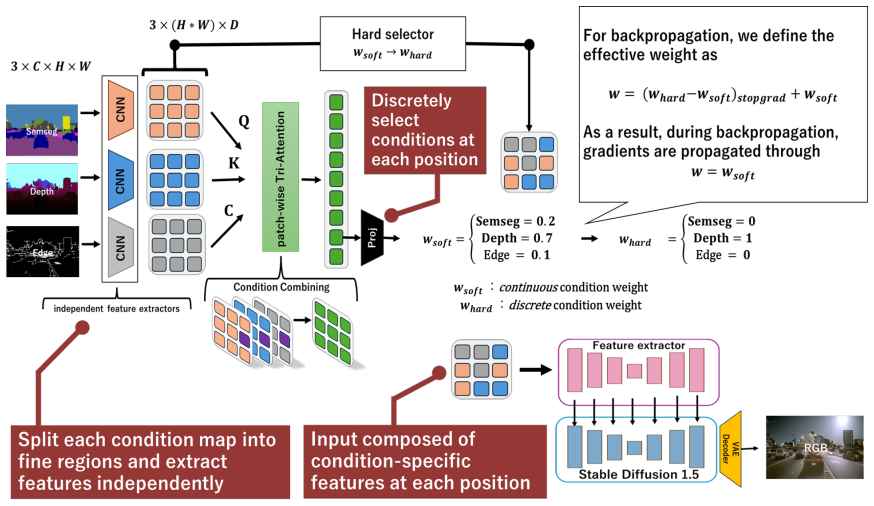
Attention-based conflict suppression that detects inconsistent signals across the segmentation, depth, and edge conditioning inputs and reduces their influence during the diffusion denoising process.
If this is right
- Generated images keep more detailed structural information, making them suitable for augmenting data used in traffic-rule extraction and driving-behavior models.
- Annotations from the original images remain usable on the synthetic outputs, allowing direct improvement of recognition performance without relabeling.
- A standardized generation framework and evaluation protocol now exists for measuring structural fidelity in multi-condition driving-scene generation.
- Condition conflicts are treated as a solvable modeling problem rather than an inherent limit of multi-condition diffusion.
Where Pith is reading between the lines
- The same attention suppression pattern could be tested on other sets of conflicting conditions, such as pose and depth in human-image generation.
- If the method scales without extra compute cost, it may lower the amount of real-world driving footage needed to train perception systems.
- Extending the conflict detector to handle temporal consistency across video frames would be a direct next step for video-based driving augmentation.
Load-bearing premise
That an attention mechanism can reliably detect and suppress conflicts among semantic segmentation, depth, and edge conditions without introducing new artifacts or reducing overall image fidelity in driving scenes.
What would settle it
Quantitative structure-preservation scores and downstream task performance on the authors' proposed evaluation protocol show no statistically significant gain, or show added artifacts, when the attention suppression module is added versus a plain multi-condition diffusion baseline.
Figures

















read the original abstract
Recent conditional image generation methods can improve controllability by generating images that are faithful to conditions such as sketches, human poses, segmentation maps, and depth. By applying these techniques to image augmentation while preserving annotations, generated images can be used as additional training data and can improve recognition performance. However, for high-level driving tasks such as traffic-rule extraction and driving-behavior understanding, simply using annotations as conditions is insufficient. Instead, images must be augmented while preserving the detailed high-level structure of the original scene. One possible solution is to use multiple conditions so that generated images retain diverse structural cues after generation. However, when multiple conditions are used, conflicts among conditions can prevent reliable structure preservation. In this work, we input semantic segmentation, depth, and edges extracted from the original image into a multi-condition image generation model, thereby providing rich structural information as conditions. We further propose a modeling approach for handling conflicts among multiple conditions and show that it enables image generation with stronger structural preservation. We also build a generation framework and evaluation protocol for driving tasks, establishing a basis for comparison with prior and future models. As a result, this work contributes to image generation research by addressing condition conflicts in multi-condition generation and provides an important step toward mitigating data scarcity in high-level autonomous-driving tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AtteConDA, an attention-based conflict suppression module inserted into a multi-condition diffusion pipeline. It takes semantic segmentation, depth, and edge maps extracted from the same source image as conditions, with the goal of generating augmented images that preserve detailed high-level structure in driving scenes better than naive multi-conditioning. The authors also describe a generation framework and evaluation protocol for driving tasks and position the work as addressing data scarcity for high-level autonomous-driving applications such as traffic-rule extraction.
Significance. If the attention mechanism demonstrably reduces condition conflicts while maintaining image fidelity and annotation consistency, the approach could provide a practical tool for synthetic data augmentation in computer vision for autonomous driving. The framing of conflicts as spatially incompatible signals and the introduction of a dedicated evaluation protocol for driving scenes are constructive steps that could serve as a basis for future comparisons, provided quantitative validation is supplied.
major comments (1)
- Abstract: the central claim that the proposed attention-based modeling approach 'enables image generation with stronger structural preservation' is asserted without any quantitative metrics, baseline comparisons, ablation studies, or error analysis. The evaluation protocol for driving tasks is mentioned but not described, leaving the load-bearing empirical support for the claim unaddressed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concern regarding the abstract and the supporting empirical evidence below, and we have revised the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: Abstract: the central claim that the proposed attention-based modeling approach 'enables image generation with stronger structural preservation' is asserted without any quantitative metrics, baseline comparisons, ablation studies, or error analysis. The evaluation protocol for driving tasks is mentioned but not described, leaving the load-bearing empirical support for the claim unaddressed.
Authors: We agree that the abstract, as a concise summary, does not itself contain the quantitative details or protocol description, which leaves the central claim insufficiently supported within that section alone. The body of the manuscript reports the relevant experiments, including quantitative metrics for structural preservation (e.g., consistency with input annotations), baseline comparisons against single-condition and naive multi-condition diffusion models, ablations isolating the attention-based conflict suppression component, and error analysis on generated driving scenes. The evaluation protocol is described in the dedicated section on the generation framework and driving-task metrics. To directly address the referee's point, we have revised the abstract to incorporate a brief summary of the key quantitative improvements and a short description of the evaluation protocol, ensuring the empirical support is referenced at the point where the claim is made. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript introduces an attention-based conflict suppression module as a novel modeling addition to multi-condition diffusion pipelines for driving scene augmentation. No equations, fitted parameters, or predictions are shown that reduce by construction to prior inputs or self-citations. The central claim—that the module enables stronger structural preservation—follows from the explicit construction of the module itself rather than from any re-expression of fitted quantities or load-bearing self-citations. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Li, Shai Dekel, Omri Fried, Idan Rubinstein, Michael Elad, and Lior Wolf
Omer Bar-Tal, Hila Manor, Kevin Y. Li, Shai Dekel, Omri Fried, Idan Rubinstein, Michael Elad, and Lior Wolf. Multidiffusion: Fusing diffusion paths for controlled image generation. InProceedings of the International Conference on Machine Learning, 2023
work page 2023
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013. 36 Algorithm 11CLIP-R-Precision evaluation Require:Generated images{yi}N i=1, matched prompts{t+ i}N i=1, mismatch prompt pool, depthK Ensure:R-Precision@K 1:fori= 1toNdo 2:C...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[3]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Zoedepth: Zero-shot transfer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
Sutherland, Michael Arbel, and Arthur Gretton
Mikołaj Bińkowski, Danica J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. InInternational Conference on Learning Representations, 2018
work page 2018
-
[5]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[6]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
work page 2020
-
[7]
John Canny. A computational approach to edge detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 8(6):679–698, 1986
work page 1986
-
[8]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InProceedings of the European Conference on Computer Vision, 2020
work page 2020
-
[9]
Driving by the rules: A benchmark for integrating traffic sign regulations into vectorized hd map
Xinyuan Chang, Maixuan Xue, Xinran Liu, Zheng Pan, and Xing Wei. Driving by the rules: A benchmark for integrating traffic sign regulations into vectorized hd map. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[10]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, 2018
work page 2018
-
[11]
Schwing, Alexander Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[12]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. 37
work page 2016
-
[13]
Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V
Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V. Le. Au- toaugment: Learning augmentation strategies from data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
work page 2019
-
[14]
Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V
Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V. Le. Randaugment: Practical automated data augmentation with a reduced search space. InAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[15]
Talk2car: Taking control of your self-driving car
Thierry Deruyttere, Simon Vandenhende, Davy Neven, Marc Proesmans, and Luc Van Gool. Talk2car: Taking control of your self-driving car. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019
work page 2019
-
[16]
Terrance DeVries and Graham W. Taylor. Improved regularization of convolutional neural networks with cutout.arXiv preprint arXiv:1708.04552, 2017
work page internal anchor Pith review arXiv 2017
-
[17]
Carla: An open urban driving simulator
Alexey Dosovitskiy, Germán Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InProceedings of the Conference on Robot Learning, 2017
work page 2017
-
[18]
Depth map prediction from a single image using a multi-scale deep network
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network. InAdvances in Neural Information Processing Systems, 2014
work page 2014
-
[19]
Steven K. Esser, Jeffrey L. McKinstry, Deepika Bablani, Rathinakumar Appuswamy, and Dharmendra S. Modha. Silq: Simple large language model quantization-aware training.arXiv preprint arXiv:2507.16933, 2025
-
[20]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2012
work page 2012
-
[21]
Clément Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J. Brostow. Digging into self-supervised monocular depth estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
work page 2019
-
[22]
Harsh Goel, Sai Shankar Narasimhan, Oguzhan Akcin, and Sandeep Chinchali. Syndiff-ad: Improving semantic segmentation and end-to-end autonomous driving with synthetic data from latent diffusion models.arXiv preprint arXiv:2411.16776, 2024
-
[23]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems, 2014
work page 2014
-
[24]
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Sch"olkopf, and Alexander Smola. A kernel two-sample test. InJournal of Machine Learning Research, volume 13, pages 723–773, 2012
work page 2012
-
[25]
Visual traffic knowledge graph generation from scene images
Yunfei Guo, Fei Yin, Xiao hui Li, Xudong Yan, Tao Xue, Shuqi Mei, and Cheng-Lin Liu. Visual traffic knowledge graph generation from scene images. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[26]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. 38
work page 2016
-
[27]
Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan
Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. Augmix: A simple data processing method to improve robustness and uncertainty. InInternational Conference on Learning Representations, 2020
work page 2020
-
[28]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.International Conference on Learning Representations, 2023
work page 2023
-
[29]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021
work page 2021
-
[30]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[31]
Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 2020
work page 2020
-
[32]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Kaixuan Wang, Hao Chen, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3dv2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[34]
Composer: Creative and controllable image synthesis with composable conditions
Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Composer: Creative and controllable image synthesis with composable conditions. InProceedings of the International Conference on Machine Learning, 2023
work page 2023
-
[35]
Multimodal unsupervised image- to-image translation
Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image- to-image translation. InProceedings of the European Conference on Computer Vision, 2018
work page 2018
-
[36]
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[37]
Oneformer: One transformer to rule universal image segmentation
Jitesh Jain, Jiachen Li, Mang-Tik Chiu, Ali Hassani, Nikita Orlov, and Humphrey Shi. Oneformer: One transformer to rule universal image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[38]
Rethinking fid: Towards a better evaluation metric for image generation
Sadeep Jayasumana, Srikumar Ramalingam, Andreas Veit, Daniel Glasner, Ayan Chakrabarti, and Sanjiv Kumar. Rethinking fid: Towards a better evaluation metric for image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[39]
Yuru Jia, Lukas Hoyer, Shengyu Huang, Tianfu Wang, Luc Van Gool, Konrad Schindler, and Anton Obukhov. Dginstyle: Domain-generalizable semantic segmentation with image diffusion models and stylized semantic control. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[40]
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes.International Conference on Learning Representations, 2014. 39
work page 2014
-
[41]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. InAdvances in Neural Information Processing Systems, 2012
work page 2012
-
[42]
Tarun Kumar et al. Image data augmentation approaches: A comprehensive survey and future directions.arXiv preprint arXiv:2301.02830, 2023
-
[43]
Improved precision and recall metric for assessing generative models
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. InAdvances in Neural Information Processing Systems, 2019
work page 2019
-
[44]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the International Conference on Machine Learning, 2023
work page 2023
-
[45]
Lincan Li, Wei Shao, Wei Dong, Yijun Tian, Qiming Zhang, Kaixiang Yang, and Wenjie Zhang. Data-centric evolution in autonomous driving: A comprehensive survey of big data system, data mining, and closed-loop technologies.arXiv preprint arXiv:2401.12888, 2024
-
[46]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[47]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Unsupervised image-to-image translation networks
Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[49]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InProceedings of the European Conference on Computer Vision, 2024
work page 2024
-
[50]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015
work page 2015
-
[51]
Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, and Peter Richtarik. Pv-tuning: Beyond straight-through estimation for extreme llm compression.arXiv preprint arXiv:2405.14852, 2024
-
[52]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jue Wang, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.International Conference on Learning Representations, 2022
work page 2022
-
[53]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.Proceedings of the AAAI Conference on Artificial Intelligence, 2024
work page 2024
-
[54]
Samuel G. M"uller and Frank Hutter. Trivialaugment: Tuning-free yet state-of-the-art data augmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021. 40
work page 2021
-
[55]
Alhassan Mumuni, Fuseini Mumuni, and Nana Kobina Gerrar. A survey of synthetic data augmentation methods in computer vision.arXiv preprint arXiv:2403.10075, 2024
-
[56]
The mapillary vistas dataset for semantic understanding of street scenes
Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The mapillary vistas dataset for semantic understanding of street scenes. InProceedings of the IEEE International Conference on Computer Vision, 2017
work page 2017
-
[57]
Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models.Pro- ceedings of the International Conference on Machine Learning, 2021
work page 2021
-
[58]
Yanjie Pan, Qingdong He, Zhengkai Jiang, Pengcheng Xu, Chaoyi Wang, Jinlong Peng, Haoxuan Wang, Yun Cao, Zhenye Gan, Mingmin Chi, Bo Peng, and Yabiao Wang. Pixelponder: Dynamic patch adaptation for enhanced multi-conditional text-to-image generation.arXiv preprint arXiv:2503.06684, 2025
-
[59]
Semantic image synthesis with spatially-adaptive normalization
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
work page 2019
-
[60]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[61]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. Proceedings of Machine Learning Research, 139:8748–8763, 2021
work page 2021
-
[62]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[63]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637, 2022
work page 2022
-
[64]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. InAdvances in Neural Information Processing Systems, 2015
work page 2015
-
[65]
Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun
Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. InProceedings of the European Conference on Computer Vision, 2016
work page 2016
-
[66]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj"orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[67]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention, 2015. 41
work page 2015
-
[68]
German Ros, Laura Sellart, Joanna Materzynska, David Vázquez, and Antonio M. López. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016
work page 2016
-
[69]
Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models.ACM Transactions on Graphics, 41(6), 2022
work page 2022
-
[70]
Languagempc: Large language models as deci- sion makers for autonomous driving,
Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, and Mingyu Ding. Languagempc: Large language models as decision makers for autonomous driving.arXiv preprint arXiv:2310.03026, 2023
-
[71]
Connor Shorten and Taghi M. Khoshgoftaar. A survey on image data augmentation for deep learning.Journal of Big Data, 6(1):60, 2019
work page 2019
-
[72]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beisswenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InProceedings of the European Conference on Computer Vision, 2024
work page 2024
-
[73]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsu- pervised learning using nonequilibrium thermodynamics.Proceedings of the International Conference on Machine Learning, 2015
work page 2015
-
[74]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. International Conference on Learning Representations, 2021
work page 2021
-
[75]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. International Conference on Learning Representations, 2021
work page 2021
-
[76]
Pixel difference networks for efficient edge detection
Zhenyu Su, Wenzhe Liu, Sheng Wang, Xiaofei Zhai, and Kui Ren. Pixel difference networks for efficient edge detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[77]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurélien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception...
work page 2020
-
[78]
Yanan Sun, Yanchen Liu, Yinhao Tang, Wenjie Pei, and Kai Chen. Anycontrol: Create your artwork with versatile control on text-to-image generation.arXiv preprint arXiv:2406.18958, 2024
-
[79]
Training deep networks with synthetic data: Bridging the reality gap by domain randomization
Jonathan Tremblay, Thang To, Balakumar Sundaralingam, Yu Xiang, Dieter Fox, and Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2018. 42
work page 2018
-
[80]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.