Recognition: no theorem link
When Few Steps Are Enough: Training-Free Acceleration of Identity-Preserved Generation
Pith reviewed 2026-05-12 04:29 UTC · model grok-4.3
The pith
A frozen identity adapter trained on a slow diffusion model transfers directly to a distilled fast backbone, cutting latency by 5.9x while raising identity similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
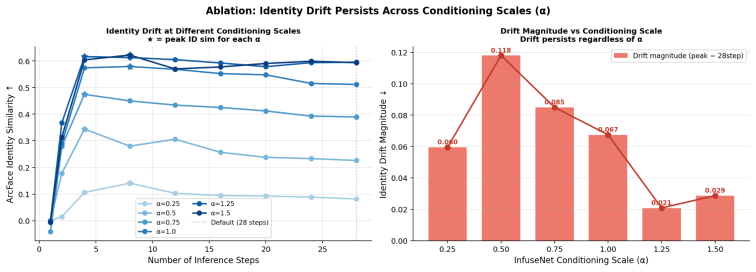
A frozen InfuseNet identity adapter trained with the dev backbone transfers directly to the distilled schnell backbone without retraining. This two-line replacement—changing the backbone path and disabling classifier-free guidance—reduces latency by 5.9x while improving ArcFace identity similarity by +0.028 and lpips by -0.016 over the standard 28-step dev baseline. Identity fidelity enters an effective regime within 4-8 steps while later steps refine visual detail, sharpness, and contrast; adapter ablations isolate the identity contribution and attention-stream norms show the conditioning signal weakening as sampling proceeds.
What carries the argument
The two-line backbone replacement (dev to distilled schnell plus CFG disable) that exploits early concentration of identity conditioning in the denoising trajectory.
If this is right
- Identity preservation succeeds with 4-8 steps rather than 28 while meeting or exceeding baseline fidelity metrics.
- No retraining is required when moving the adapter from dev to distilled FLUX variants.
- Disabling classifier-free guidance preserves identity in this distilled setting.
- Style and object adapters on SDXL and SD1.5 exhibit comparable diminishing returns after intermediate steps.
Where Pith is reading between the lines
- Consumer devices could run personalized image generation without server-scale compute if the early-regime pattern generalizes.
- Step schedules might be made conditioning-dependent rather than fixed across all tasks.
- Adapter compatibility across model families could become a primary design goal instead of per-model retraining.
- The same early-lock-in observation could be tested on video or 3D diffusion backbones.
Load-bearing premise
The identity adapter's conditioning effect is largely complete after only the first few steps of the distilled model, so later steps and classifier-free guidance can be removed without losing identity fidelity.
What would settle it
Running the adapter on the schnell backbone at 4 steps and measuring ArcFace similarity substantially below the 28-step dev baseline would falsify the early-regime claim.
Figures







read the original abstract
Identity-preserved image generation is typically built on many-step diffusion backbones, making personalized generation expensive at deployment time. We show that this cost is often unnecessary for identity-conditioned FLUX generation. A frozen InfuseNet identity adapter trained with dev transfers directly to the distilled schnell backbone without retraining. This two-line replacement -- changing the backbone path and disabling classifier-free guidance -- reduces latency by 5.9x while improving ArcFace identity similarity by +0.028 and lpips by -0.016 over the standard 28-step dev baseline. To explain why this works, we analyze the denoising trajectory and find that identity fidelity enters an early effective regime, often within 4-8 steps, while later steps primarily refine visual detail, sharpness, and contrast. Adapter ablations confirm that identity formation depends on the identity adapter, while attention-stream norm probes suggest that the relative conditioning contribution decreases as sampling proceeds. Preliminary style-adapter and object-adapter sweeps on SDXL and SD1.5 show similar diminishing returns after intermediate steps. These results position distilled backbone replacement as a simple, training-free strategy for improving the efficiency-fidelity tradeoff of identity-preserved generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
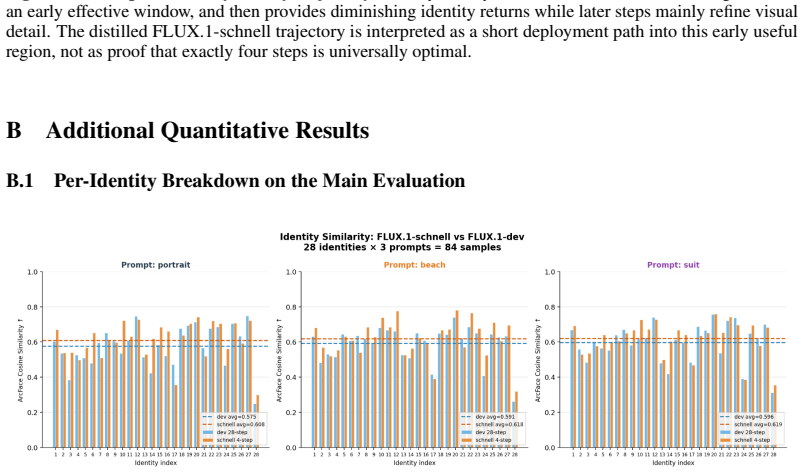
Summary. The manuscript claims that a frozen InfuseNet identity adapter trained with the FLUX dev model transfers directly to the distilled schnell backbone without retraining. A two-line replacement (backbone swap plus disabling classifier-free guidance) yields 5.9× latency reduction while improving ArcFace identity similarity by +0.028 and LPIPS by -0.016 over the 28-step dev baseline. Trajectory analysis shows identity fidelity stabilizes early (4-8 steps), later steps refine detail; adapter ablations and attention-norm probes support that identity formation depends on the adapter. Preliminary sweeps on SDXL/SD1.5 indicate similar diminishing returns for style/object adapters.
Significance. If the transfer result holds, the work offers a simple training-free route to accelerate identity-preserved generation, which is practically significant for deployment. The empirical trajectory analysis and cross-model preliminary results provide useful mechanistic insight beyond the headline speed-up.
major comments (1)
- [Results and Ablations] Results/Ablations: The claim that the frozen InfuseNet adapter transfers directly to schnell is load-bearing for the training-free story, yet no controlled ablation keeps the schnell backbone, frozen adapter, and step count fixed while toggling only classifier-free guidance. All reported gains are versus the 28-step dev baseline (which uses CFG), so it remains possible that CFG removal, rather than adapter transfer, accounts for the +0.028 ArcFace / -0.016 LPIPS deltas. The trajectory and norm analyses address step-wise contribution but do not isolate guidance scale on the distilled model.
minor comments (2)
- [Experiments] The abstract and experimental sections would benefit from reporting standard deviations or multiple runs for the metric deltas to allow assessment of variability.
- [Methodology] Implementation details for the exact 'two-line replacement' (model loading, CFG scale value, and scheduler settings) are not provided, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for recognizing the practical value of the training-free acceleration approach. We address the major comment below.
read point-by-point responses
-
Referee: The claim that the frozen InfuseNet adapter transfers directly to schnell is load-bearing for the training-free story, yet no controlled ablation keeps the schnell backbone, frozen adapter, and step count fixed while toggling only classifier-free guidance. All reported gains are versus the 28-step dev baseline (which uses CFG), so it remains possible that CFG removal, rather than adapter transfer, accounts for the +0.028 ArcFace / -0.016 LPIPS deltas. The trajectory and norm analyses address step-wise contribution but do not isolate guidance scale on the distilled model.
Authors: We agree that the suggested control would more cleanly isolate the contribution of the adapter transfer from the effect of disabling CFG. Although the distilled schnell backbone is designed to operate without CFG, we will add the requested ablation in the revision: results on the schnell backbone with the frozen adapter at fixed step count, both with CFG enabled and disabled. This will directly address whether the reported gains in ArcFace similarity and LPIPS are driven primarily by CFG removal or by the adapter transfer itself. revision: yes
Circularity Check
No derivation chain present; purely empirical transfer result
full rationale
The paper's central claim is an empirical observation: a frozen InfuseNet adapter trained on dev transfers to the schnell backbone via a two-line change (backbone swap plus CFG disable), yielding measured latency and fidelity gains over the 28-step baseline. No equations, first-principles derivation, or predictive model is introduced whose outputs are shown to equal their inputs by construction. Trajectory analysis and norm probes are post-hoc explanations of observed behavior, not load-bearing steps that reduce to fitted parameters or self-citations. The work contains no self-definitional loops, fitted-input predictions, or uniqueness theorems imported from prior author work. Therefore the result is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of diffusion model sampling trajectories and adapter conditioning behavior
Reference graph
Works this paper leans on
- [1]
-
[2]
FLUX.1: Official inference repository for FLUX.1 models
Black Forest Labs. FLUX.1: Official inference repository for FLUX.1 models. https://github.com/ black-forest-labs/flux, 2024
work page 2024
- [3]
-
[4]
X. Liu, C. Gong, and Q. Liu. Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. InICLR, 2023
work page 2023
-
[5]
J. Ho, A. Jain, and P. Abbeel. Denoising Diffusion Probabilistic Models. InNeurIPS, 2020
work page 2020
-
[6]
J. Song, C. Meng, and S. Ermon. Denoising Diffusion Implicit Models. InICLR, 2021
work page 2021
-
[7]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency Models. InICML, 2023
work page 2023
-
[8]
T. Salimans and J. Ho. Progressive Distillation for Fast Sampling of Diffusion Models. InICLR, 2022
work page 2022
-
[9]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. InCVPR, 2019
work page 2019
-
[10]
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang. IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models.arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
-
[12]
Z. Guo, Y . Wu, Z. Chen, L. Chen, P. Zhang, and Q. He. PuLID: Pure and Lightning ID Customization via Contrastive Alignment. InNeurIPS, 2024
work page 2024
-
[13]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-Rank Adaptation of Large Language Models. InICLR, 2022
work page 2022
-
[14]
M. Wortsman, G. Ilharco, S. Y . Gadre, et al. Model Soups: Averaging Weights of Multiple Fine-tuned Models Improves Accuracy without Increasing Inference Time. InICML, 2022
work page 2022
- [15]
- [16]
-
[17]
Z. Liu, P. Luo, X. Wang, and X. Tang. Deep Learning Face Attributes in the Wild. InICCV, 2015
work page 2015
-
[18]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv:2304.07193, 2023. 9 A Conceptual Early-Window Model Figure 7 illustrates the qualitative early-window interpretation used throughout the paper. We keep this conceptual plot in the appendix because the main paper emphasizes measured deployment resu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.