Recognition: 2 theorem links
· Lean TheoremAPCD: Adaptive Path-Contrastive Decoding for Reliable Large Language Model Generation
Pith reviewed 2026-05-12 05:18 UTC · model grok-4.3
The pith
APCD improves large language model reliability by branching paths only at high-entropy points and attenuating interactions between diverging paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
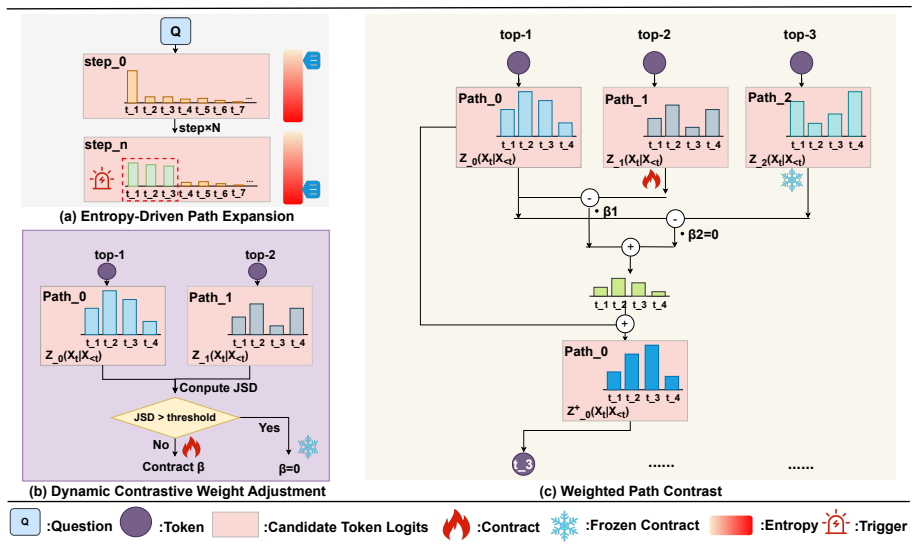
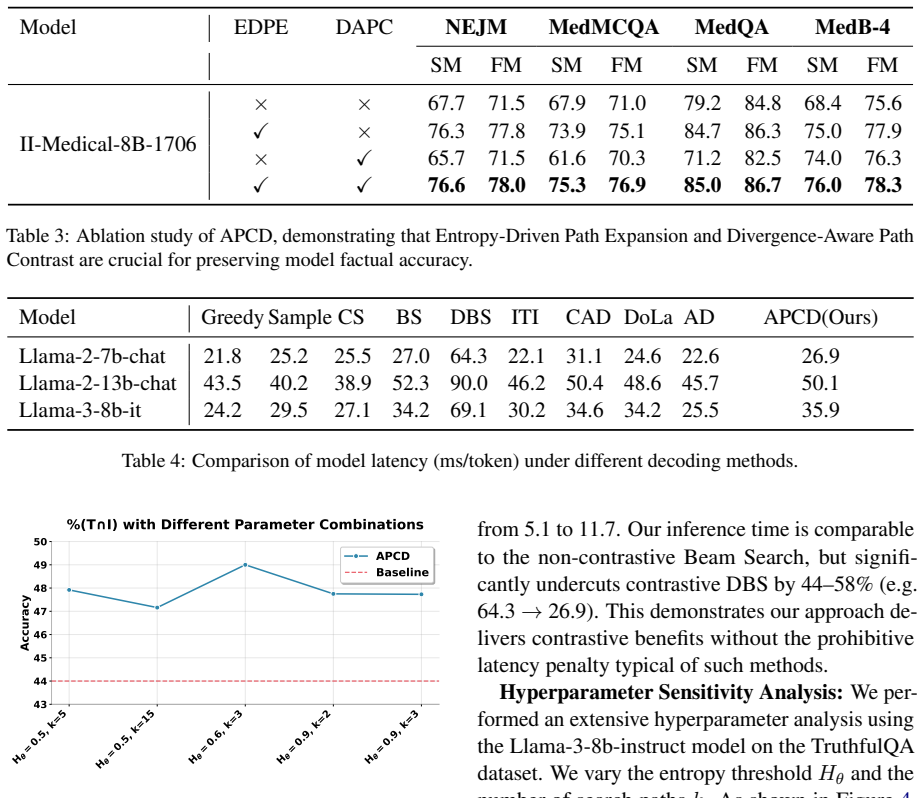
APCD is a multi-path decoding framework that improves output reliability through adaptive exploration and controlled path interaction. It uses Entropy-Driven Path Expansion to delay branching until Shannon entropy over top candidate tokens signals multiple plausible continuations, and Divergence-Aware Path Contrast to encourage diverse trajectories while dynamically attenuating inter-path influence as prediction distributions diverge. Experiments across eight benchmarks show gains in factual accuracy with maintained decoding efficiency.
What carries the argument
Entropy-Driven Path Expansion paired with Divergence-Aware Path Contrast, which together time the creation of alternative trajectories and regulate their mutual influence according to distributional divergence.
Load-bearing premise
Shannon entropy over top candidate tokens reliably flags moments when branching helps, and attenuating influence between diverging paths reduces error buildup without discarding useful information.
What would settle it
Running APCD on a factual question-answering benchmark and observing no statistically significant accuracy gain or an increase in hallucinations relative to standard single-path decoding.
Figures


read the original abstract
Large language models (LLMs) often suffer from hallucinations due to error accumulation in autoregressive decoding, where suboptimal early token choices misguide subsequent generation. Although multi-path decoding can improve robustness by exploring alternative trajectories, existing methods lack principled strategies for determining when to branch and how to regulate inter-path interactions. We propose Adaptive Path-Contrastive Decoding (APCD), a multi-path decoding framework that improves output reliability through adaptive exploration and controlled path interaction. APCD consists of two components: (1) Entropy-Driven Path Expansion, which delays branching until predictive uncertainty - measured by Shannon entropy over top candidate tokens - indicates multiple plausible continuations; and (2) Divergence-Aware Path Contrast, which encourages diverse reasoning trajectories while dynamically attenuating inter-path influence as prediction distributions diverge. Experiments on eight benchmarks demonstrate improved factual accuracy while maintaining decoding efficiency. Our code is available at https://github.com/zty-king/APCD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Adaptive Path-Contrastive Decoding (APCD), a multi-path decoding framework for LLMs consisting of Entropy-Driven Path Expansion (branching delayed until Shannon entropy over top-k tokens indicates uncertainty) and Divergence-Aware Path Contrast (encouraging diversity while attenuating inter-path influence as distributions diverge). It claims this reduces hallucinations from error accumulation in autoregressive generation and reports improved factual accuracy on eight benchmarks while preserving decoding efficiency, with code released.
Significance. If the adaptive mechanisms prove effective under controlled conditions, APCD would provide a principled alternative to fixed multi-path or contrastive decoding strategies, addressing a practical limitation in reliable LLM output. The public code release is a clear strength that supports reproducibility and further testing of the entropy trigger and divergence attenuation rules.
major comments (2)
- [Experiments] Experiments section: the abstract reports empirical gains on eight benchmarks but supplies no details on baselines (e.g., standard beam search, fixed-branching multi-path, or non-attenuated contrastive variants), statistical significance tests, or controls for the extra compute incurred by maintaining multiple paths. Without matched-compute ablations, it is impossible to determine whether observed accuracy improvements stem from the proposed entropy-driven branching and divergence-aware attenuation or simply from increased exploration budget.
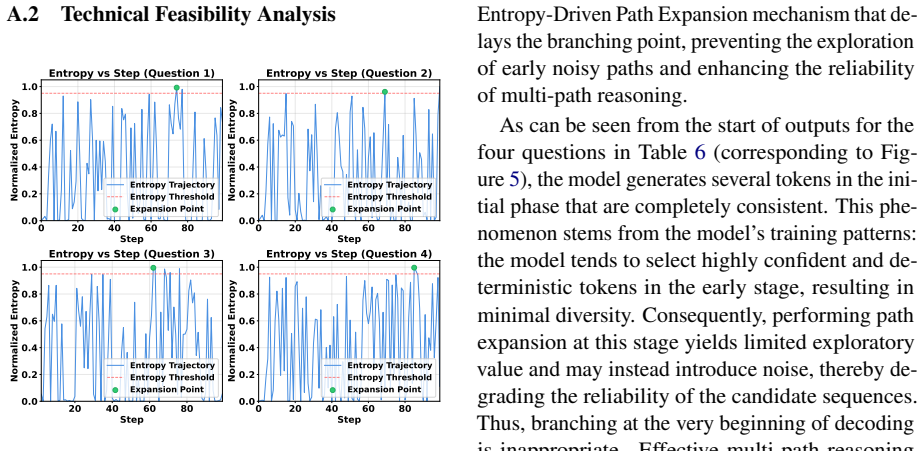
- [Method] Method (Entropy-Driven Path Expansion): the central reliability claim rests on the assumption that high Shannon entropy over top candidate tokens reliably flags moments with multiple factually plausible continuations worth exploring. No analysis or ablation is presented showing that entropy distinguishes correct alternatives from cases where all top continuations are already hallucinated; if the latter occurs, the adaptive expansion could amplify rather than mitigate error accumulation.
minor comments (2)
- [Abstract] Abstract: the claim of 'maintaining decoding efficiency' is stated without quantitative comparison (e.g., tokens per second or wall-clock time relative to single-path baselines), which should be added for clarity.
- [Method] Notation: the description of 'attenuating inter-path influence' would benefit from an explicit equation or pseudocode step showing how the attenuation factor is computed from distribution divergence, to avoid ambiguity in implementation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of experimental rigor and the validation of our core assumptions. We address each point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract reports empirical gains on eight benchmarks but supplies no details on baselines (e.g., standard beam search, fixed-branching multi-path, or non-attenuated contrastive variants), statistical significance tests, or controls for the extra compute incurred by maintaining multiple paths. Without matched-compute ablations, it is impossible to determine whether observed accuracy improvements stem from the proposed entropy-driven branching and divergence-aware attenuation or simply from increased exploration budget.
Authors: We agree that the experimental presentation requires greater detail and controls. The original manuscript compares APCD against several standard decoding strategies, but the baselines and their configurations are not enumerated exhaustively in the main text. In the revised version we will (1) explicitly tabulate all baselines including standard beam search, fixed-branching multi-path decoding with equivalent average path count, and contrastive decoding without the divergence-attenuation term; (2) report statistical significance via paired bootstrap tests or Wilcoxon signed-rank tests across the eight benchmarks with multiple random seeds; and (3) add matched-compute ablations that fix the total decoding budget (measured in cumulative tokens or approximate FLOPs) for the baselines so that any accuracy gains can be attributed to the adaptive entropy trigger and attenuation mechanism rather than raw exploration volume. revision: yes
-
Referee: [Method] Method (Entropy-Driven Path Expansion): the central reliability claim rests on the assumption that high Shannon entropy over top candidate tokens reliably flags moments with multiple factually plausible continuations worth exploring. No analysis or ablation is presented showing that entropy distinguishes correct alternatives from cases where all top continuations are already hallucinated; if the latter occurs, the adaptive expansion could amplify rather than mitigate error accumulation.
Authors: This is a substantive methodological concern. While the overall factual-accuracy improvements on the benchmarks provide indirect support for the entropy-driven trigger, we did not include a targeted diagnostic that measures how often high-entropy steps contain at least one factually correct continuation versus cases where all top-k tokens are already erroneous. In the revision we will insert a new analysis subsection that samples high-entropy decoding steps from the evaluation sets, annotates whether any top-k token is factually correct (using the same ground-truth references as the main benchmarks), and reports the fraction of useful versus potentially harmful branching opportunities. We will also discuss the role of the divergence-aware contrast term in limiting error propagation even when an occasional unhelpful branch is introduced. revision: yes
Circularity Check
APCD's adaptive rules are defined algorithmically without reduction to fitted inputs or self-citations.
full rationale
The paper defines APCD via two explicit algorithmic components—entropy-driven expansion using Shannon entropy over top tokens and divergence-aware contrast with dynamic attenuation—presented as a proposed framework rather than a derivation from data or prior self-cited theorems. No equations appear that equate a 'prediction' to a fitted parameter by construction, and the abstract invokes no load-bearing self-citations for uniqueness or ansatzes. Experiments on benchmarks are offered as external validation, keeping the central claims independent of the method's own definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Shannon entropy over top-k token probabilities is a sufficient signal for deciding when to branch decoding paths.
- domain assumption Divergence between path distributions can be used to attenuate inter-path influence without discarding correct information.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearDivergence-Aware Path Contrast... βb,b′=βmax·max(0,1−JSD(ˆpb∥ˆpb′)/δlog2)
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
ACM Transactions on Management Information Systems , volume=
Designing heterogeneous llm agents for financial sentiment analysis , author=. ACM Transactions on Management Information Systems , volume=. 2025 , publisher=
work page 2025
-
[3]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
(A) I am not a lawyer, but...: engaging legal experts towards responsible LLM policies for legal advice , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
work page 2024
-
[6]
The Curious Case of Neural Text Degeneration
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
work page internal anchor Pith review arXiv 1904
-
[7]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[9]
Faithful chain-of-thought reasoning , author=. The 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL 2023) , year=
work page 2023
-
[10]
Mutual reasoning makes smaller llms stronger problem-solvers,
Mutual reasoning makes smaller llms stronger problem-solvers , author=. arXiv preprint arXiv:2408.06195 , year=
-
[11]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Large language models are better reasoners with self-verification , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[14]
arXiv preprint arXiv:2310.00752 , year=
Tigerscore: Towards building explainable metric for all text generation tasks , author=. arXiv preprint arXiv:2310.00752 , year=
-
[19]
Advances in neural information processing systems , volume=
Sequence to sequence learning with neural networks , author=. Advances in neural information processing systems , volume=
-
[20]
Contrastive decoding: Open-ended text generation as optimization , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[22]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Complex & Intelligent Systems , volume=
Sentence-level heuristic tree search for long text generation , author=. Complex & Intelligent Systems , volume=. 2024 , publisher=
work page 2024
-
[27]
Advances in Neural Information Processing Systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[31]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
work page 2018
-
[32]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
work page 2019
-
[33]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
work page 2021
-
[34]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , editor =
work page 2022
-
[35]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
ECO Decoding: Entropy-Based Control for Controllability and Fluency in Controllable Dialogue Generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[36]
arXiv preprint arXiv:2302.06784 , year=
The stable entropy hypothesis and entropy-aware decoding: An analysis and algorithm for robust natural language generation , author=. arXiv preprint arXiv:2302.06784 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Alphamath almost zero: process supervision without process , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
II-Medical-8B: Medical Reasoning Model , author=
- [41]
- [43]
-
[44]
Trusting your evidence: Hallucinate less with context-aware decoding , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
work page 2024
-
[47]
Advances in Neural Information Processing Systems , volume=
Fast best-of-n decoding via speculative rejection , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for
Shenzhi Wang and Le Yu and Chang Gao and Chujie Zheng and Shixuan Liu and Rui Lu and Kai Dang and Xiong-Hui Chen and Jianxin Yang and Zhenru Zhang and Yuqiong Liu and An Yang and Andrew Zhao and Yang Yue and Shiji Song and Bowen Yu and Gao Huang and Junyang Lin , booktitle=. Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement...
work page 2025
-
[49]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
work page 2020
- [51]
-
[52]
Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. 2025. https://doi.org/10.18653/v1/2025.naacl-long.182 Benchmarking large language models on answering and explaining challenging medical questions . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technol...
- [53]
-
[54]
Zheng Chen and Zhejun Liu. 2024. Sentence-level heuristic tree search for long text generation. Complex & Intelligent Systems, 10(2):3153--3167
work page 2024
-
[55]
Inyoung Cheong, King Xia, KJ Kevin Feng, Quan Ze Chen, and Amy X Zhang. 2024. (a) i am not a lawyer, but...: engaging legal experts towards responsible llm policies for legal advice. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2454--2469
work page 2024
- [56]
-
[57]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv e-prints, pages arXiv--2407
work page 2024
- [58]
- [59]
- [60]
-
[61]
Intelligent Internet. 2025. Ii-medical-8b: Medical reasoning model
work page 2025
-
[62]
Xinke Jiang, Ruizhe Zhang, Yongxin Xu, Rihong Qiu, Yue Fang, Zhiyuan Wang, Jinyi Tang, Hongxin Ding, Xu Chu, Junfeng Zhao, and 1 others. 2023. Hykge: A hypothesis knowledge graph enhanced framework for accurate and reliable medical llms responses. arXiv preprint arXiv:2312.15883
-
[63]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421
work page 2021
-
[64]
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[65]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, and 1 others. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453--466
work page 2019
-
[66]
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. 2023 a . Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36:41451--41530
work page 2023
-
[67]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023 b . Contrastive decoding: Open-ended text generation as optimization. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 12286--12312
work page 2023
-
[68]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214--3252
work page 2022
-
[69]
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. 2023. Faithful chain-of-thought reasoning. In The 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL 2023)
work page 2023
-
[70]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. https://proceedings.mlr.press/v174/pal22a.html Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering . In Proceedings of the Conference on Health, Inference, and Learning, volume 174 of Proceedings of Machine Learning Research, pages 248--260. PMLR
work page 2022
-
[71]
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. 2024. Trusting your evidence: Hallucinate less with context-aware decoding. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 783--791
work page 2024
-
[72]
Seungmin Shin, Dooyoung Kim, and Youngjoong Ko. 2025. Eco decoding: Entropy-based control for controllability and fluency in controllable dialogue generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28297--28309
work page 2025
- [73]
-
[74]
Hanshi Sun, Momin Haider, Ruiqi Zhang, Huitao Yang, Jiahao Qiu, Ming Yin, Mengdi Wang, Peter Bartlett, and Andrea Zanette. 2024. Fast best-of-n decoding via speculative rejection. Advances in Neural Information Processing Systems, 37:32630--32652
work page 2024
-
[75]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27
work page 2014
-
[76]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
Ashwin K Vijayakumar, Michael Cogswell, Ramprasath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. 2016. Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv preprint arXiv:1610.02424
work page Pith review arXiv 2016
-
[78]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. 2025. https://openreview.net/forum?id=yfcpdY4gMP Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning f...
work page 2025
-
[79]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[80]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
work page 2022
- [81]
-
[82]
Frank Xing. 2025. Designing heterogeneous llm agents for financial sentiment analysis. ACM Transactions on Management Information Systems, 16(1):1--24
work page 2025
- [83]
- [84]
-
[85]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2369--2380
work page 2018
- [86]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.