Recognition: no theorem link
Hidden Error Awareness in Chain-of-Thought Reasoning: The Signal Is Diagnostic, Not Causal
Pith reviewed 2026-05-12 05:08 UTC · model grok-4.3
The pith
Models internally detect errors in their chain-of-thought traces but cannot use that detection to correct the errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that hidden states during chain-of-thought generation encode a strong, early signal of trace correctness that is invisible both in the generated text and in the model's stated . This signal persists across model families and scales, including RL-trained reasoning models, yet four distinct interventions that attempt to make the signal causal—activation steering, probe-guided best-of-N sampling, self-correction prompts, and activation patching—all leave error rates essentially unchanged or destroy output quality. The authors therefore locate error representations in reasoning as fundamentally different from the editable factual knowledge representations studied inprior
What carries the argument
A linear probe trained on hidden-state activations to classify whether a completed chain-of-thought trace is correct or incorrect.
If this is right
- Verbalized is a poor proxy for internal reasoning quality.
- Error detection during reasoning does not participate in the forward computation that produces the answer.
- Mechanistic interventions that succeed on factual recall are unlikely to transfer directly to multi-step reasoning.
- The dissociation between internal detection and output generation persists even after reinforcement learning on reasoning tasks.
Where Pith is reading between the lines
- Improving chain-of-thought reliability may require architectures or training methods that make the error signal directly influence token generation rather than merely detect it after the fact.
- The same hidden-state probe could be used at inference time to route questions to different reasoning strategies without changing model weights.
- The gap between internal and external signals may widen or shrink under different prompting or decoding regimes that the paper does not test.
Load-bearing premise
That the four tested interventions were strong enough to prove the internal signal cannot be made causal rather than simply being poorly targeted or implemented.
What would settle it
An intervention that reads the hidden-state error signal and measurably raises the fraction of correct traces while preserving output coherence would falsify the claim that the signal is not causal.
Figures


read the original abstract
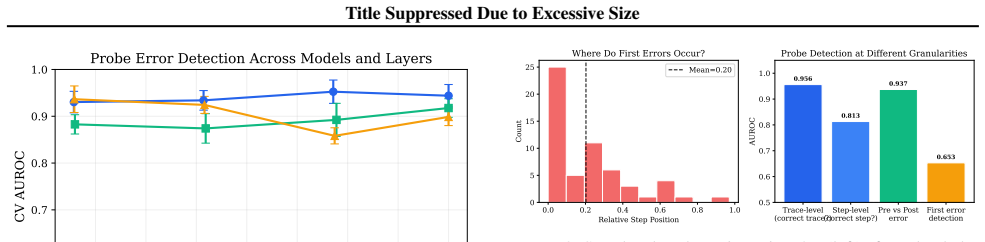
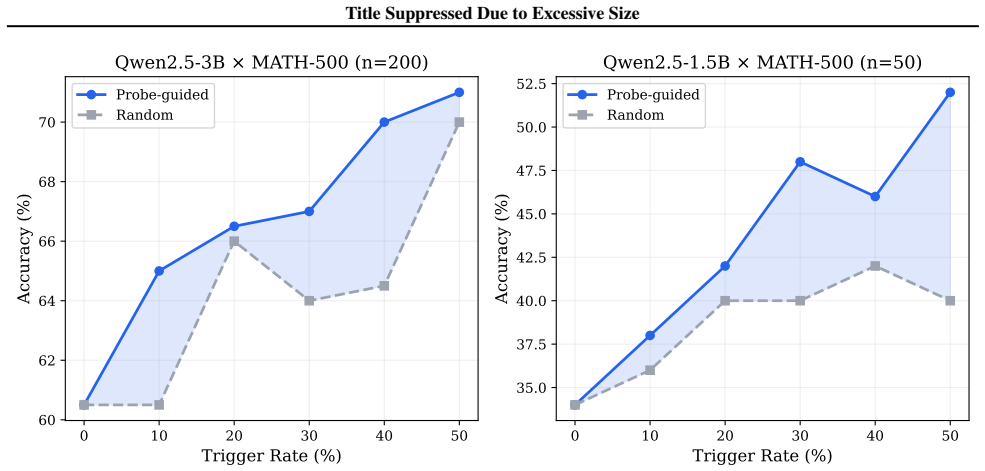
Chain-of-thought (CoT) prompting assumes that generated reasoning reflects a model's internal computation. We show this assumption is wrong in a specific, measurable way: models internally detect their own reasoning errors but outwardly express confidence in them. A linear probe on hidden states predicts trace correctness with 0.95 AUROC -- from the very first reasoning step (0.79) -- while verbalized confidence for wrong traces is 4.55/5, nearly identical to correct ones (4.87/5). A text-surface classifier achieves only 0.59 on the same data, confirming a 0.20-point gap invisible in the generated text. This hidden error awareness holds across three model families (Qwen, Llama, Phi), 1.5B-72B parameters, and RL-trained reasoning models (DeepSeek-R1, 0.852 AUROC). The natural question is whether this signal can fix the errors it detects. It cannot. Four interventions -- activation steering, probe-guided best-of-N, self-correction, and activation patching -- all fail; patching destroys output coherence entirely. The signal is diagnostic, not causal: a readout of computation quality, not a lever to redirect it. This delineates a boundary for mechanistic interpretability: error representations during reasoning are fundamentally different from the factual knowledge representations that prior work has successfully edited.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language models internally detect errors in their chain-of-thought reasoning traces via hidden-state representations, as shown by linear probes achieving 0.95 AUROC (0.79 from the first step) across model families, while verbalized confidence remains high and similar for correct (4.87/5) and incorrect (4.55/5) traces. A text-surface classifier reaches only 0.59 AUROC, confirming the signal is hidden. Four interventions (activation steering, probe-guided best-of-N, self-correction, activation patching) all fail to improve outputs, leading to the conclusion that the signal is diagnostic of computation quality but not causal and thus not usable to redirect reasoning, unlike editable factual knowledge.
Significance. If the empirical measurements and negative intervention results hold after addressing methodological gaps, the work would be significant for mechanistic interpretability of reasoning. It provides evidence of early, model-internal error awareness that is invisible in generated text and distinguishes error representations from prior successes in editing factual knowledge, with implications for CoT reliability and the limits of using probes for control. The cross-scale and cross-family consistency strengthens the finding.
major comments (2)
- [Intervention Experiments] Intervention section: The claim that the signal 'is diagnostic, not causal' is load-bearing and rests on the failure of the four tested interventions. However, the manuscript provides no argument or ablation showing these interventions were exhaustive, optimally targeted, or free of confounds (e.g., steering vector granularity, probe integration timing in best-of-N, or coherence side-effects in patching). Negative results on these specific methods do not rule out causal relevance under different manipulations, as a detectable signal can still be causally relevant yet resistant to the tested approaches.
- [Experimental Setup] Experimental Setup and Results sections: The reported AUROC values (0.95 overall, 0.79 first-step, 0.59 text classifier) and confidence scores lack sufficient detail on trace labeling for correctness, probe training (data splits, regularization, cross-validation), baseline controls, and statistical tests. These omissions undermine verifiability of the quantitative gap and cross-model claims, even though the core diagnostic finding is not circular.
minor comments (2)
- [Abstract] Abstract and §2: Clarify the exact definition of 'trace correctness' used for labeling and whether it relies on external verification or model self-assessment.
- [Results] Presentation: Ensure all figures reporting AUROC curves include error bars, exact sample sizes, and clear legends distinguishing probe vs. text classifier performance.
Simulated Author's Rebuttal
Thank you for the constructive referee report. We address each major comment point by point below, providing clarifications and indicating revisions where the manuscript will be updated to improve clarity and rigor.
read point-by-point responses
-
Referee: [Intervention Experiments] Intervention section: The claim that the signal 'is diagnostic, not causal' is load-bearing and rests on the failure of the four tested interventions. However, the manuscript provides no argument or ablation showing these interventions were exhaustive, optimally targeted, or free of confounds (e.g., steering vector granularity, probe integration timing in best-of-N, or coherence side-effects in patching). Negative results on these specific methods do not rule out causal relevance under different manipulations, as a detectable signal can still be causally relevant yet resistant to the tested approaches.
Authors: We agree that the four interventions are not exhaustive and that their failure does not rule out causal relevance under every conceivable alternative manipulation. These methods were chosen because they represent the main categories of approaches used in mechanistic interpretability to act on internal signals: activation steering, probe-based selection (best-of-N), natural-language self-correction, and causal patching. Their uniform failure, in contrast to successful editing of factual knowledge in prior work, supports the interpretation that the error signal is not readily usable for redirecting reasoning. In revision we will add a limitations subsection that (a) explicitly states the interventions are representative rather than exhaustive, (b) discusses potential confounds such as steering granularity and patching coherence effects, and (c) tempers the phrasing of the 'diagnostic, not causal' claim to reflect these boundaries while preserving the empirical contrast with editable factual representations. revision: partial
-
Referee: [Experimental Setup] Experimental Setup and Results sections: The reported AUROC values (0.95 overall, 0.79 first-step, 0.59 text classifier) and confidence scores lack sufficient detail on trace labeling for correctness, probe training (data splits, regularization, cross-validation), baseline controls, and statistical tests. These omissions undermine verifiability of the quantitative gap and cross-model claims, even though the core diagnostic finding is not circular.
Authors: We thank the referee for identifying these gaps in methodological detail. The core diagnostic result is not circular, but verifiability requires the requested information. In the revised manuscript we will expand the Experimental Setup and Results sections to specify: (1) the exact procedure for labeling trace correctness, including ground-truth answer matching and step-wise verification criteria; (2) probe training details such as train/test splits, regularization strength, and cross-validation folds; (3) construction and performance of the text-surface baseline classifier; and (4) the statistical tests applied to AUROC differences and cross-model consistency. These additions will not change the reported numbers but will make the quantitative claims fully reproducible. revision: yes
Circularity Check
No circularity: claims rest on independent empirical measurements
full rationale
The paper's central results derive from training linear probes on hidden states to classify trace correctness (reporting AUROC) and from running four separate interventions whose outcomes are directly observed. These steps do not reduce to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The diagnostic claim follows from the probe's measured performance gap versus text classifiers; the 'not causal' claim follows from the observed failure of the listed interventions. Both are falsifiable against external data and do not rely on equations or prior results that presuppose the target conclusion. This is the standard non-circular pattern for an empirical interpretability study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
International Conference on Learning Representations , year=
Discovering latent knowledge in language models without supervision , author=. International Conference on Learning Representations , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Representation engineering: A top-down approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , journal=. Representation engineering: A top-down approach to
-
[7]
International Conference on Learning Representations , year=
Large language models cannot self-correct reasoning yet , author=. International Conference on Learning Representations , year=
- [8]
-
[9]
International Conference on Learning Representations , year=
Self-consistency improves chain of thought reasoning in language models , author=. International Conference on Learning Representations , year=
-
[10]
International Conference on Learning Representations , year=
Let's verify step by step , author=. International Conference on Learning Representations , year=
-
[11]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[13]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Measuring mathematical problem solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , journal=. Measuring mathematical problem solving with the
-
[15]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , journal=. Locating and editing factual associations in
-
[16]
Advances in Neural Information Processing Systems , volume=
Investigating gender bias in language models using causal mediation analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Azaria, Amos and Mitchell, Tom , journal=. The internal state of an
-
[19]
Think you have solved question answering?
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have solved question answering?
-
[20]
Conference on Causal Learning and Reasoning (CLeaR) , series=
Finding alignments between interpretable causal variables and distributed neural representations , author=. Conference on Causal Learning and Reasoning (CLeaR) , series=
-
[21]
Reasoning Models Know When They're Right: Probing Hidden States for Self-Verification , author=. arXiv preprint arXiv:2504.05419 , year=
-
[22]
Shen, Yuanzhe and Liu, Yide and Huang, Zisu and others , booktitle=
-
[23]
The Curious Case of Hallucinatory (Un)answerability: Finding Truths in the Hidden States of Over-Confident Large Language Models , author=. Proceedings of EMNLP , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.