Recognition: 2 theorem links
· Lean TheoremEmpirical Bayes 1-bit matrix completion
Pith reviewed 2026-05-12 04:53 UTC · model grok-4.3
The pith
An empirical Bayes method adapts the Efron-Morris estimator to shrink singular values and complete unobserved entries in binary matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the logit-scale matrix as approximately low-rank and applying empirical Bayes shrinkage to its singular values, the method recovers missing binary entries while automatically handling the discrete nature of the observations and providing uncertainty estimates.
What carries the argument
empirical Bayes shrinkage of singular values, generalizing the Efron-Morris estimator to 1-bit observations
If this is right
- Prediction error decreases when the singular-value shrinkage correctly captures the dominant low-rank signal in the binary matrix.
- Uncertainty intervals derived from the posterior shrinkage become better calibrated than those from non-Bayesian competitors.
- Runtime remains lower than methods that optimize over full parameter spaces because the procedure operates directly on singular values.
- The same shrinkage logic extends naturally to settings that resemble multidimensional item response models.
Where Pith is reading between the lines
- The method could be tested on binary matrices arising from user-item interactions to check whether the calibration gains translate into improved ranking quality in recommender systems.
- If the low-rank assumption is relaxed, the same empirical Bayes machinery might be applied to matrices with other discrete or count-valued entries.
- The connection to item response theory suggests the procedure could serve as a fast alternative for estimating latent traits in large-scale testing data.
Load-bearing premise
Binary matrices have an underlying low-rank structure that empirical Bayes shrinkage of singular values can recover even when only binary observations are available.
What would settle it
On a collection of binary matrices with verified low-rank structure, the method produces higher prediction error or worse-calibrated probabilities than standard nuclear-norm or logistic matrix factorization baselines.
Figures
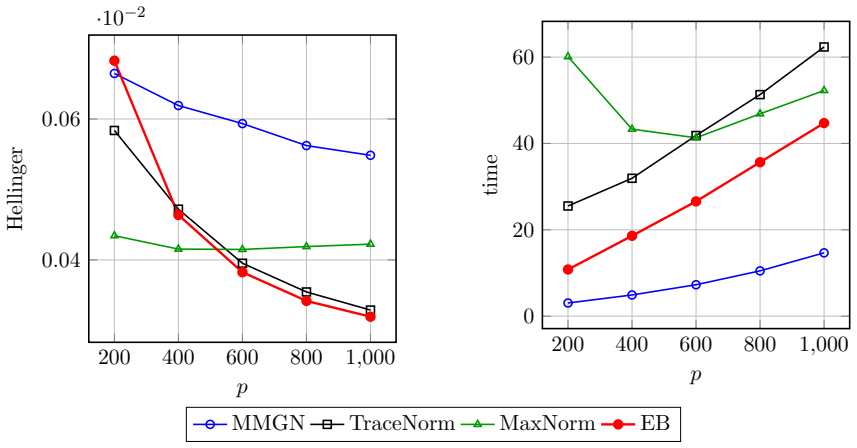
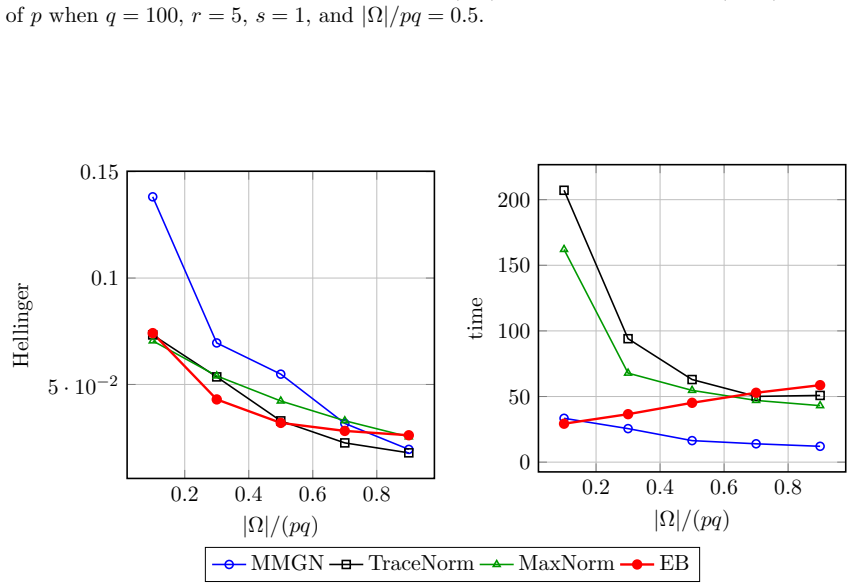
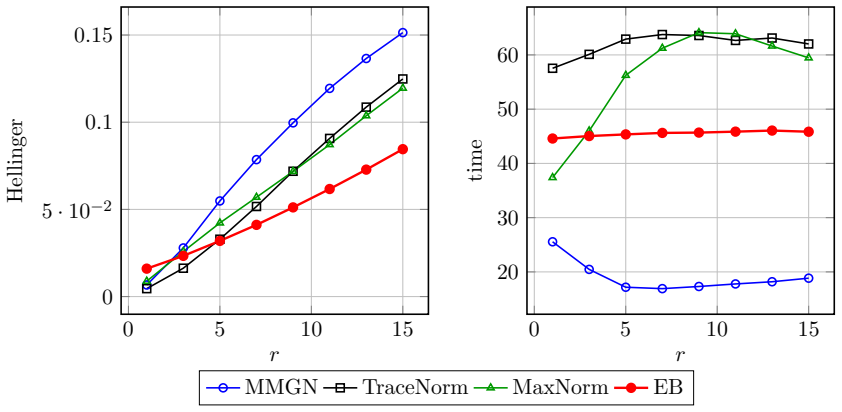
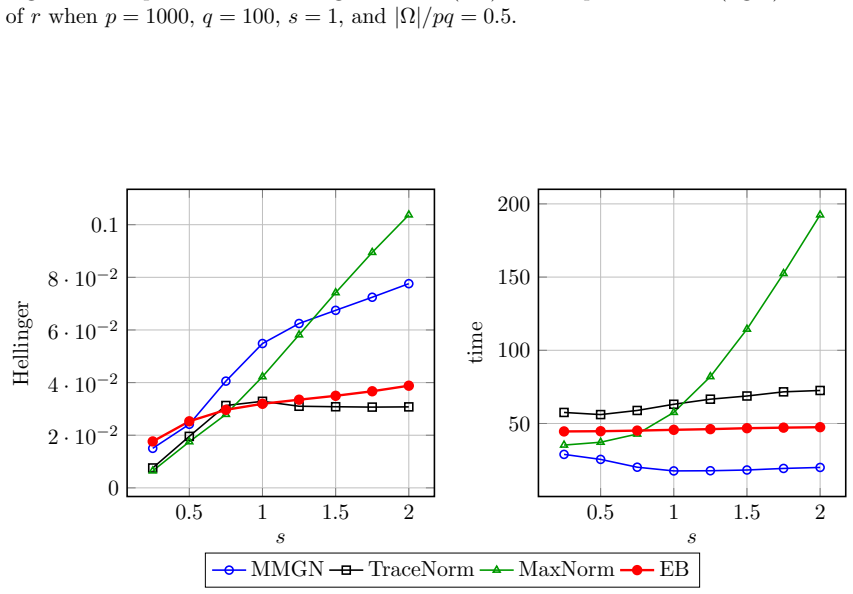
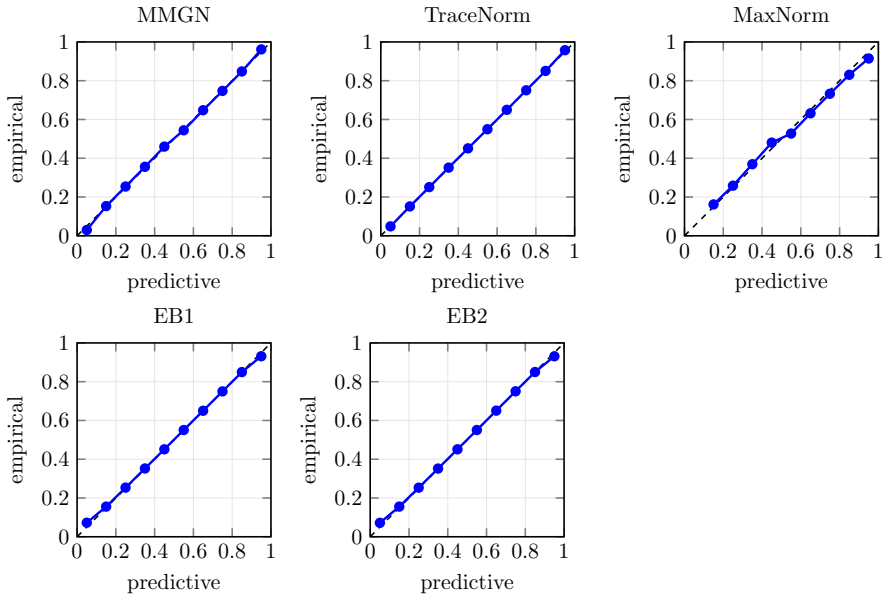
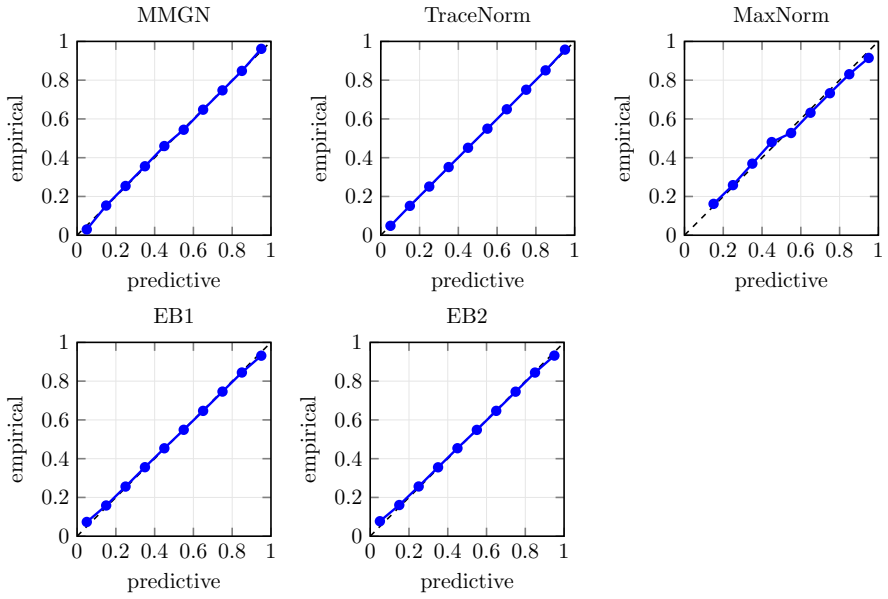
read the original abstract
The problem of predicting unobserved entries in a binary matrix, known as 1-bit matrix completion, has found diverse applications in fields such as recommendation systems. In this study, we develop an empirical Bayes method for 1-bit matrix completion motivated by the Efron--Morris estimator, a matrix generalization of the James--Stein estimator that shrinks singular values toward zero. The proposed method exploits the underlying low-rank structure of binary matrices, drawing parallels with multidimensional item response theory. Simulation studies and real-data applications demonstrate that the proposed method achieves a superior balance of predictive accuracy, calibration reliability (uncertainty quantification), and computational efficiency compared to existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an empirical Bayes procedure for 1-bit matrix completion that generalizes the Efron-Morris singular-value shrinkage estimator to binary observations. It exploits an assumed low-rank structure, draws an analogy to multidimensional item-response theory, and reports that the resulting method outperforms existing approaches in predictive accuracy, uncertainty calibration, and computational speed on both simulated and real data sets.
Significance. If the reported empirical gains are reproducible and the method scales reliably, the work would supply a practical, shrinkage-based alternative for binary matrix completion tasks common in recommendation systems. The explicit link to the Efron-Morris estimator and the emphasis on calibration are positive features that distinguish it from purely optimization-driven competitors.
major comments (2)
- [§3] §3 (method derivation): the precise mapping from the continuous Efron-Morris shrinkage rule to the 1-bit likelihood is not fully specified; it is unclear whether the singular-value shrinkage is applied to the latent continuous matrix before or after the probit link, which affects whether the procedure remains a direct empirical-Bayes extension or introduces an additional approximation.
- [Table 2] Table 2 (simulation results): the reported superiority in calibration (e.g., coverage of predictive intervals) is shown only for a single noise level and rank; without additional rows or figures varying the signal-to-noise ratio or the fraction of observed entries, it is difficult to assess whether the claimed balance of accuracy and calibration generalizes beyond the chosen simulation design.
minor comments (3)
- [Abstract] The abstract states that the method achieves 'superior balance' but does not quantify the trade-off (e.g., via a Pareto front or weighted score); a short sentence clarifying the primary metric used for comparison would help readers interpret the claim.
- [§2] Notation for the observed binary matrix and the latent continuous matrix is introduced without an explicit table of symbols; adding such a table would improve readability for readers unfamiliar with 1-bit completion literature.
- [§5] Real-data experiments mention 'several public data sets' but report only aggregate metrics; listing the exact data sets, their sizes, and the train/test split ratios in a table would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment. We address each major point below and will incorporate clarifications and additional results in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (method derivation): the precise mapping from the continuous Efron-Morris shrinkage rule to the 1-bit likelihood is not fully specified; it is unclear whether the singular-value shrinkage is applied to the latent continuous matrix before or after the probit link, which affects whether the procedure remains a direct empirical-Bayes extension or introduces an additional approximation.
Authors: We appreciate the referee's attention to this detail. The procedure applies the Efron-Morris singular-value shrinkage to the estimated latent continuous matrix (obtained by inverting the probit link on the observed binary data) and then maps the shrunk latent values back through the probit link to obtain binary predictions. This is a direct empirical-Bayes extension within the latent-variable model; no further approximation is introduced beyond the standard probit assumption. In the revision we will add an explicit algorithmic outline and a small diagram in §3 that sequences the steps (latent estimation, shrinkage, link re-application) to remove any ambiguity. revision: yes
-
Referee: [Table 2] Table 2 (simulation results): the reported superiority in calibration (e.g., coverage of predictive intervals) is shown only for a single noise level and rank; without additional rows or figures varying the signal-to-noise ratio or the fraction of observed entries, it is difficult to assess whether the claimed balance of accuracy and calibration generalizes beyond the chosen simulation design.
Authors: We agree that demonstrating robustness across a wider range of conditions would strengthen the simulation section. In the revised manuscript we will expand Table 2 (or add a supplementary table) with results for two additional noise levels and two additional observation fractions while keeping the same rank settings. This will allow direct comparison of accuracy and calibration metrics across the expanded design. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical Bayes method for 1-bit matrix completion explicitly motivated by the classic Efron-Morris estimator (a known matrix generalization of James-Stein shrinkage). Central claims rest on simulation studies and real-data applications demonstrating predictive accuracy, calibration, and efficiency, rather than on any derivation that reduces by construction to fitted parameters, self-definitional equations, or load-bearing self-citations. The low-rank exploitation via shrinkage is stated as a deliberate modeling choice, with no internal reduction of predictions to inputs or uniqueness theorems imported from the authors' prior work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe proposed method is based on a hierarchical model motivated from the Efron–Morris estimator... mi ∼ Nq(0, Σ)... Monte Carlo EM algorithm... Bayesian predictive distribution
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclearexploits the underlying low-rank structure of binary matrices, drawing parallels with multidimensional item response theory
Reference graph
Works this paper leans on
-
[1]
Aitchison, J. (1975). Goodness of prediction fit . Biometrika 62, 547--554
work page 1975
-
[2]
Albert, J. H. & Chib, S. (1993). Bayesian analysis of binary and polychotomous response data . Journal of the American Statistical Association 88, 669--679
work page 1993
-
[3]
Alquier, P. , Cottet, V. , Chopin, N. & Rousseau, J. (2014). Bayesian matrix completion: prior specification . arXiv:1406.1440
-
[4]
Athey, S. , Bayati, M. , Doudchenko, N. , Imbens, G. & Khosravi, K. (2021). Matrix completion methods for causal panel data models . Journal of the American Statistical Association 88, 1716--1730
work page 2021
-
[5]
Bennett, J. & Lanning, S. (2007). The Netflix Prize . In Proceedings of KDD Cup and Workshop 2007
work page 2007
-
[6]
Bhaskar, S. A. & Javanmard, A. (2015). 1-bit matrix completion under exact low-rank constraint . In 49th Annual Conference on Information Sciences and Systems (CISS), 1--6
work page 2015
-
[7]
Cai, J. F. , Cand e s, E. J. & Shen, Z. (2010). A singular value thresholding algorithm for matrix completion . SIAM Journal on Optimization 20, 1956--1982
work page 2010
- [8]
-
[9]
Cand e s, E. J. & Recht, B. (2008). Exact matrix completion via convex optimization . Foundations of Computational Mathematics 9, 717--772
work page 2008
- [10]
-
[11]
Cottet, V. & Alquier, P. (2018). 1-bit matrix completion: PAC-Bayesian analysis of a variational approximation . Machine Learning 107, 579--603
work page 2018
-
[12]
Davenport, M. A. , Plan, Y. , van den Berg, E. & Wootters, M. (2014). 1-bit matrix completion . Information and Inference 3, 189--223
work page 2014
-
[13]
Dawid, A. P. (1982). The well-calibrated Bayesian . Journal of the American Statistical Association 77, 605--610
work page 1982
-
[14]
de Leeuw, J. (2006). Principal component analysis of binary data by iterated singular value decomposition . Computational Statistics & Data Analysis 50, 21--39
work page 2006
-
[15]
Dempster, A. P. , Laird, N. M. & Rubin, D. B. (1972). Maximum likelihood from incomplete data via the EM algorithm . Journal of the Royal Statistical Society B 39, 1--38
work page 1972
-
[16]
Efron, B. (2010). Large-scale inference: empirical Bayes methods for estimation, testing, and prediction. Cambridge University Press
work page 2010
-
[17]
Efron, B. & Morris, C. (1972). Empirical Bayes on vector observations: an extension of Stein's method . Biometrika 59, 335--347
work page 1972
-
[18]
Goldberg, K. , Roeder, T. , Gupta, D. & Perkins, C. (2001). Eigentaste: A Constant Time Collaborative Filtering Algorithm . Information Retrieval 4, 133--151
work page 2001
-
[19]
Guo, C. , Pleiss, G. , Sun, Y. & Weinberger, K. Q. (2017). On calibration of modern neural networks . In International Conference on Machine Learning, 1321--1330
work page 2017
-
[20]
Hui, F. , Warton, D. I. , Ormerod, J. T. , Haapaniemi, V. & Taskinen, S. (2017). Variational approximations for generalized linear latent variable models . Journal of Computational and Graphical Statistics 26, 35--43
work page 2017
-
[21]
Johnson, C. C. (2014). Logistic matrix factorization for implicit feedback data . In Advances in Neural Information Processing Systems 27, 1--9
work page 2014
-
[22]
Keshavan, R. H. , Montanari, A. & Oh, S. (2010). Matrix completion from noisy entires . Journal of Machine Learning Research 11, 2057--2078
work page 2010
-
[23]
Levine, R. A. & Casella, G. (2001). Implementations of the Monte Carlo EM Algorithm . Journal of Computational and Graphical Statistics 10, 422--439
work page 2001
-
[24]
Li, X. , Matsuda, T. & Komaki, F. (2024). Empirical Bayes Poisson matrix completion , Computational Statistics & Data Analysis, 197, 107976
work page 2024
- [25]
-
[26]
Matsuda, T. (2024). Adapting to general quadratic loss via singular value shrinkage . IEEE Transactions on Information Theory 70, 3640--3657
work page 2024
-
[27]
Matsuda, T. & Komaki, F. (2015). Singular value shrinkage priors for Bayesian prediction . Biometrika 102, 843--854
work page 2015
-
[28]
Matsuda, T. & Komaki, F. (2019). Empirical Bayes matrix completion , Computational Statistics & Data Analysis, 137, 195--210
work page 2019
-
[29]
Matsuda, T. & Strawderman, W. E. (2022). Estimation under matrix quadratic loss and matrix superharmonicity . Biometrika 109, 503--519
work page 2022
-
[30]
Mazumder, R. , Hastie, T. & Tibshirani, R. (2010). Spectral regularization algorithms for learning large incomplete matrices . Journal of Machine Learning Research 11, 2287--2322
work page 2010
-
[31]
Ni, R. & Gu, Q. (2016). Optimal statistical and computational rates for one bit matrix completion . In Artificial Intelligence and Statistics 51, 426--434
work page 2016
-
[32]
Polson, N. G. , Scott, J. G. & Windle, J. (2013). Bayesian inference for logistic models using Polya--Gamma latent variables , Journal of the American Statistical Association, 108, 1339--1349
work page 2013
-
[33]
Recht, B. (2011). A simpler approach to matrix completion . Journal of Machine Learning Research 12, 3413--3430
work page 2011
-
[34]
Reckase, M. D. (2006). Multidimensional item response theory , Handbook of Statistics, 26, 607--642
work page 2006
-
[35]
Robbins, H. (1956). An empirical Bayes approach to statistics . Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability 2, 157--163
work page 1956
-
[36]
Stein, C. (1974). Estimation of the mean of a multivariate normal distribution . Proceedings of Prague Symposium on Asymptotic Statistics 2, 345--381
work page 1974
-
[37]
Wei, G. C. G. & Tanner, M. A. (1990). A Monte Carlo implementation of the EM algorithm and the poor man's data augmentation algorithms . Journal of the American Statistical Association 85, 699--704
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.