Recognition: 3 theorem links
· Lean TheoremA Game Theoretic Free Energy Analysis of Higher Order Synergy in Attention Heads of Large Language Models
Pith reviewed 2026-05-12 03:43 UTC · model grok-4.3
The pith
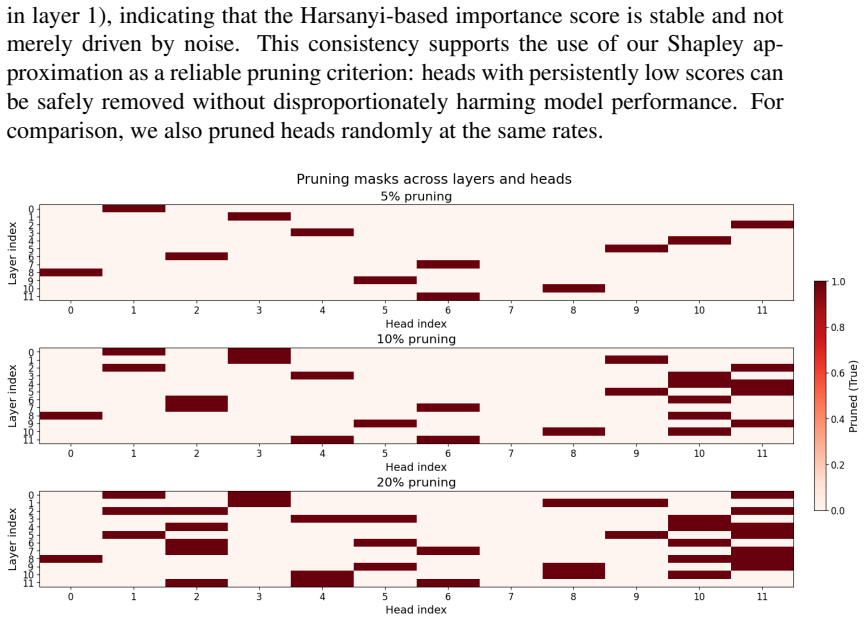
Attention heads in large language models display negative triple dividends that indicate higher-order redundancy and allow pruning 20 percent of heads with only modest performance loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the free energy of attention-head coalitions is reduced to the joint Shannon entropy of their discretized outputs, the resulting pairwise contributions are nonnegative while the triple contributions are negative on every tested model and task. Negative triple contributions mean the heads are redundant at higher order. The correspondence between stationary points of the collective free energy and approximate Nash equilibria then implies that heads with small marginal contributions can be removed without large shifts in model behavior.
What carries the argument
The reduction of coalition free energy to joint Shannon entropy of the argmax key indices, which converts higher-order dividends into measures of mutual and interaction information.
If this is right
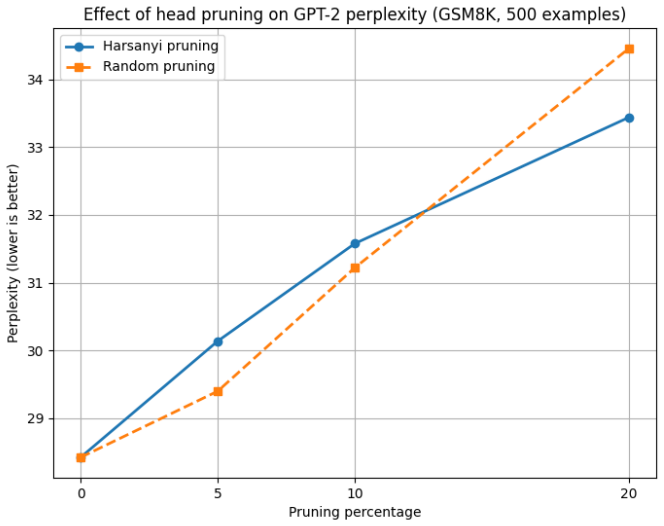
- Pruning 20 percent of heads in GPT2 reduces FLOPs by 18 percent and raises throughput by 22 percent.
- Perplexity on GSM8K rises only from 28.4 to 33.4 after the same pruning step.
- Heads identified by low marginal contribution can be removed while the remaining system stays near an approximate equilibrium.
- The same dividend test can be applied to other transformer layers or model sizes to locate further redundancy.
Where Pith is reading between the lines
- The same negative-triple pattern may appear in other overparameterized components such as feed-forward layers, suggesting a general compression route.
- Models whose triple dividends are more strongly negative should show larger efficiency gains from the pruning procedure than models with mixed signs.
- The dividend analysis could be run after each training checkpoint to decide which heads to drop dynamically during inference.
- If the redundancy finding holds, it supplies one concrete reason why massively overparameterized transformers still generalize: many heads largely duplicate one another.
Load-bearing premise
The uniform prior and deterministic dynamics used to turn coalition free energy into joint entropy still preserve the original game-theoretic meaning of the dividends.
What would settle it
An exact computation of the triple dividends on the same head outputs but without the uniform-prior approximation that finds the values positive would show the reported redundancy to be an artifact of the simplification.
Figures




read the original abstract
Large language models rely on multihead attention, but interactions among heads remain poorly understood. We apply the Game Theoretic Free Energy Principle (GTFEP): a framework casting multiagent systems as distributed variational inference to analyze attention heads as bounded rational agents. According to GTFEP, each head minimizes its variational free energy, and collective behavior follows a Gibbs distribution over coalition structures whose energy is decomposed into Harsanyi dividends. Using a tractable approximation (uniform prior, deterministic dynamics), coalition free energy reduces to joint Shannon entropy of discretized head outputs (argmax key index). Pairwise dividends become mutual information (nonnegative), while triple dividends correspond to interaction information and can be negative. On BERT, GPT2, and Llama with GSM8K, triple dividends are consistently negative, revealing higher order redundancy. The Nash FEP correspondence guarantees that stationary points of collective free energy are epsilon Nash equilibria; thus, heads with negligible contribution can be pruned with minimal performance loss. Pruning heads with low marginal contribution reduces computational cost with minimal performance loss: for example, pruning 20% of heads in GPT2 reduces FLOPs by 18%, increases throughput by 22%, and raises perplexity only modestly (from 28.4 to 33.4 on GSM8K). Our work shows GTFEP provides a principled foundation for analyzing and optimizing transformer architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by applying the Game Theoretic Free Energy Principle (GTFEP) to attention heads in LLMs, treating them as agents, and using a tractable approximation that equates coalition free energy to joint Shannon entropy of argmax-discretized outputs, one can identify higher-order redundancy through negative triple dividends (interaction information). This, combined with the Nash equilibrium correspondence, allows pruning of heads with low marginal contribution, as demonstrated by a 20% pruning in GPT2 yielding 18% FLOP reduction, 22% throughput increase, and only modest perplexity rise from 28.4 to 33.4 on GSM8K, with similar patterns in other models.
Significance. If the approximation is rigorously justified, this work could significantly impact the field by providing a game-theoretic and information-theoretic basis for understanding synergies and redundancies in transformer attention mechanisms. The empirical results on pruning suggest immediate practical applications for model compression. The consistent negative triple dividends across BERT, GPT2, and Llama strengthen the observation of higher-order redundancy. However, the current presentation leaves the theoretical mapping open to the concerns raised about preservation of the free energy structure.
major comments (3)
- [Abstract (tractable approximation)] The tractable approximation using uniform prior and deterministic dynamics to reduce coalition free energy to joint Shannon entropy of discretized head outputs (argmax key index) is central to the claims but lacks a detailed derivation showing it preserves the variational free-energy decomposition of GTFEP. As attention outputs are stochastic and input-dependent, this discretization may not maintain the game-theoretic interpretation, making the negativity of triple dividends (corresponding to interaction information) insufficient to conclude higher-order redundancy in the multi-agent sense. This directly impacts the justification for the pruning strategy.
- [Abstract (pruning example)] The specific pruning results are reported without accompanying error bars, statistical significance tests, or ablations (e.g., random pruning controls or sensitivity to the discretization choice). Additionally, detailed numbers are provided only for GPT2 on GSM8K, while the abstract mentions results on BERT, GPT2, and Llama; this limits the generalizability of the performance claims.
- [Abstract (Nash FEP correspondence)] The assertion that 'the Nash FEP correspondence guarantees that stationary points of collective free energy are epsilon Nash equilibria' is stated without supporting derivation or reference to how the approximation affects this guarantee. This is load-bearing for linking the negative dividends to pruning with minimal performance loss.
minor comments (2)
- The abstract would benefit from a brief mention of the specific datasets and models used for the triple dividend analysis beyond the pruning example.
- Consider adding a table summarizing the triple dividend signs across models and layers for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the theoretical and empirical foundations of the work.
read point-by-point responses
-
Referee: [Abstract (tractable approximation)] The tractable approximation using uniform prior and deterministic dynamics to reduce coalition free energy to joint Shannon entropy of discretized head outputs (argmax key index) is central to the claims but lacks a detailed derivation showing it preserves the variational free-energy decomposition of GTFEP. As attention outputs are stochastic and input-dependent, this discretization may not maintain the game-theoretic interpretation, making the negativity of triple dividends (corresponding to interaction information) insufficient to conclude higher-order redundancy in the multi-agent sense. This directly impacts the justification for the pruning strategy.
Authors: We agree that the manuscript would benefit from an expanded derivation of the tractable approximation. In the revised version we will add a dedicated appendix section that starts from the GTFEP variational free-energy expression, applies the uniform prior and deterministic argmax dynamics, and arrives at the joint Shannon entropy of the discretized outputs, while explicitly noting the conditions under which the game-theoretic interpretation is retained. We will also discuss the approximation's limitations with respect to stochasticity and input dependence, clarifying that negative triple dividends are interpreted as higher-order redundancy within the discretized coalition model that underpins the pruning heuristic. revision: yes
-
Referee: [Abstract (pruning example)] The specific pruning results are reported without accompanying error bars, statistical significance tests, or ablations (e.g., random pruning controls or sensitivity to the discretization choice). Additionally, detailed numbers are provided only for GPT2 on GSM8K, while the abstract mentions results on BERT, GPT2, and Llama; this limits the generalizability of the performance claims.
Authors: We accept that the current empirical presentation is insufficiently rigorous. The revised manuscript will include error bars computed over multiple random seeds, statistical significance tests comparing pruned and baseline models, and ablations that contrast our synergy-based pruning against random head removal and against alternative discretization thresholds. We will also report the full set of metrics (FLOPs, throughput, perplexity) for BERT and Llama in addition to the GPT2-GSM8K case, thereby improving the generalizability of the claims. revision: yes
-
Referee: [Abstract (Nash FEP correspondence)] The assertion that 'the Nash FEP correspondence guarantees that stationary points of collective free energy are epsilon Nash equilibria' is stated without supporting derivation or reference to how the approximation affects this guarantee. This is load-bearing for linking the negative dividends to pruning with minimal performance loss.
Authors: We acknowledge that the Nash-FEP link is stated without sufficient supporting material. In the revision we will insert a concise derivation (or a clear reference to the relevant game-theoretic result) showing that stationary points of the collective free energy correspond to epsilon-Nash equilibria, and we will explicitly examine how the uniform-prior/deterministic-dynamics approximation modifies the epsilon bound. This addition will make the theoretical justification for pruning heads with low marginal contribution fully transparent. revision: yes
Circularity Check
Tractable approximation equates GTFEP coalition free energy directly to joint Shannon entropy, making dividends equivalent to mutual information and interaction information by construction
specific steps
-
self definitional
[Abstract]
"Using a tractable approximation (uniform prior, deterministic dynamics), coalition free energy reduces to joint Shannon entropy of discretized head outputs (argmax key index). Pairwise dividends become mutual information (nonnegative), while triple dividends correspond to interaction information and can be negative."
The sentence states that the approximation makes coalition free energy identical to joint Shannon entropy; therefore the subsequent dividends are definitionally identical to mutual information and interaction information. The interpretation of negative triple dividends as 'higher order redundancy' then follows from the known properties of interaction information rather than from any additional game-theoretic derivation.
full rationale
The paper's central analysis rests on one explicit reduction: under the uniform-prior/deterministic-dynamics approximation, coalition free energy is set equal to the joint entropy of argmax-discretized head outputs. This forces pairwise Harsanyi dividends to equal mutual information and triple dividends to equal interaction information. Because these are pre-existing information-theoretic quantities whose negativity is already known to indicate certain forms of redundancy or synergy, the claim that negative triple dividends 'reveal higher order redundancy' and justify pruning does not constitute an independent game-theoretic prediction; it is the relabeling of a standard computation. The Nash FEP stationary-point guarantee is invoked to bridge to pruning, but that bridge inherits the same approximation. No other load-bearing self-citation or fitted-parameter steps appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- Uniform prior
- Discretization via argmax key index
axioms (2)
- domain assumption Attention heads behave as bounded rational agents minimizing variational free energy
- domain assumption Collective behavior follows a Gibbs distribution over coalition structures
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a tractable approximation (uniform prior, deterministic dynamics), coalition free energy reduces to joint Shannon entropy of discretized head outputs (argmax key index). ... triple dividends correspond to interaction information and can be negative.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Nash-FEP correspondence) establishes that stationary points of F correspond to ϵ-Nash equilibria
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pruning 20% of heads in GPT-2 reduces FLOPs by 18%, increases throughput by 22%, and raises perplexity only modestly (from 28.4 to 33.4 on GSM8K).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint (2019).arXiv:1810.04805. 15
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, Language models are unsupervised multitask learners, 2019. URL https://api.semanticscholar.org/CorpusID:160025533
work page 2019
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, et al., Llama 2: Open foundation and fine-tuned chat models, arXiv preprint (2023).arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
H. S. de Ocáriz Borde, Beyond parallelism: Synergistic computational graph effects in multi-head attention, in: Proceedings of the NeurIPS 2025 Work- shop on Symmetry and Geometry in Neural Representations, 2025, pp. 1–16. arXiv:2507.02944,doi:10.48550/arXiv.2507.02944. URL https://arxiv.org/abs/2507.02944
-
[5]
Z. Su, et al., Shrp: Specialized head routing and pruning for efficient encoder compression, arXiv preprint arXiv:2512.20635 (2025). URL https://arxiv.org/abs/2512.20635
-
[6]
Ju, C., Shi, W., Liu, C., Ji, J., Zhang, J., Zhang, R., Xu, J., Yang, Y ., Han, S., and Guo, Y
L. Zhong, F. Wan, R. Chen, X. Quan, L. Li, Blockpruner: Fine-grained pruning for large language models, in: Findings of the Association for Com- putational Linguistics: ACL 2025, Association for Computational Linguis- tics, Vienna, Austria, 2025, pp. 5065–5080.doi:10.18653/v1/2025. findings-acl.262. URL https://aclanthology.org/2025.findings-acl.262/
-
[7]
H. T. Nguyen, B. Nguyen, V . A. Nguyen, Structured pruning for diverse best- of-nreasoning optimization, in: W. Che, J. Nabende, E. Shutova, M. T. Pile- hvar (Eds.), Findings of the Association for Computational Linguistics: ACL 2025, Association for Computational Linguistics, Vienna, Austria, 2025, pp. 23911–23922.doi:10.18653/v1/2025.findings-acl.1225. ...
- [8]
-
[9]
A Collective Variational Principle Unifying Bayesian Inference, Game Theory, and Thermodynamics
D. Bouchaffra, F. Ykhlef, M. Lebbah, H. Azzag, A collective variational principle unifying bayesian inference, game theory, and thermodynam- ics, submitted to Nature Communications (2026).arXiv:2604.27942, doi:10.48550/arXiv.2604.27942. 16
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.27942 2026
-
[10]
D. Bouchaffra, F. Ykhlef, B. Faye, M. Lebbah, H. Azzag, Redesigning deep neural networks: Bridging game theory and statistical physics, Neural Net- works 191 (2025) 107807.doi:10.1016/j.neunet.2025.107807
-
[11]
Neu- rogame transformer: Gibbs-inspired attention driven by game theory and statistical physics
D. Bouchaffra, F. Ykhlef, H. Azzag, M. Lebbah, B. Faye, Neurogame transformer: Gibbs-inspired attention driven by game theory and statistical physics, arXiv preprint arXiv:2603.18761, submitted to IEEE Transactions on Cybernetics (2026).doi:10.48550/arXiv.2603.18761. URL https://arxiv.org/abs/2603.18761
-
[12]
P. T. Waade, C. L. Olesen, J. E. Laursen, S. W. Nehrer, C. Heins, K. Friston, C. Mathys, As one and many: Relating individual and emergent group-level generative models in active inference, Entropy 27 (2) (2025) 143.doi: 10.3390/e27020143
-
[13]
M. Albarracin, R. J. Pitliya, T. St. Clere Smithe, D. A. Friedman, K. Fris- ton, M. J. D. Ramstead, Shared protentions in multi-agent active inference, Entropy 26 (4) (2024) 303.doi:10.3390/e26040303
-
[14]
A. Shafiei, H. Jesawada, K. Friston, G. Russo, Distributionally robust free energy principle for decision-making, Nature Communications 17 (1) (2026) 707.doi:10.1038/s41467-025-67348-6. URL https://doi.org/10.1038/s41467-025-67348-6
-
[15]
K. Friston, J. Kilner, L. Harrison, A free energy principle for the brain, Journal of Physiology-Paris 100 (1-3) (2006) 70–87.doi:10.1016/j. jphysparis.2006.10.001
work page doi:10.1016/j 2006
-
[16]
K. J. Friston, J. Daunizeau, S. J. Kiebel, Reinforcement learning or active inference?, PLoS ONE 4 (7) (2009) e6421.doi:10.1371/journal. pone.0006421
-
[17]
K. J. Friston, J. Daunizeau, J. Kilner, S. J. Kiebel, Action and behavior: a free-energy formulation, Biological Cybernetics 102 (3) (2010) 227–260. doi:10.1007/s00422-010-0364-z
-
[18]
Trends in Cognitive Sciences (2018) https://doi.org/10.1016/j.tics
K. Friston, The free-energy principle: a rough guide to the brain?, Trends in Cognitive Sciences 13 (7) (2009) 293–301.doi:10.1016/j.tics. 2009.04.005. 17
-
[19]
Nature Reviews Neuroscience , year =
K. Friston, The free-energy principle: a unified brain theory?, Nature Re- views Neuroscience 11 (2) (2010) 127–138.doi:10.1038/nrn2787
-
[20]
Friston, et al., Active inference and artificial reasoning, arXiv preprint (2025).arXiv:2512.21129
K. Friston, et al., Active inference and artificial reasoning, arXiv preprint (2025).arXiv:2512.21129
-
[21]
K. J. Friston, T. Salvatori, T. Isomura, A. Tschantz, A. Kiefer, T. Verbelen, M. Koudahl, A. Paul, T. Parr, A. Razi, B. J. Kagan, Active inference and intentional behavior, Neural Computation 37 (4) (2025) 666–700.doi: 10.1162/neco_a_01738
- [22]
- [23]
- [24]
-
[25]
M. Il Idrissi, A. Charpentier, A. Fernandes Machado, Beyond shapley val- ues: Cooperative games for the interpretation of machine learning mod- els, in: International Joint Conference on Artificial Intelligence (IJCAI) - Workshop on Explainable Artificial Intelligence (XAI), Montréal, Québec, Canada, 2025
work page 2025
-
[26]
M. Roy, O. Abudayyeh, S. Roy, et al., The physics of thought: Reasoning as thermodynamic relaxation in generative models, Research Square (preprint), version 1 (Dec. 2025).doi:10.21203/rs.3.rs-8426467/v1. URL https://doi.org/10.21203/rs.3.rs-8426467/v1
- [27]
-
[28]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
E. V oita, D. Talbot, F. Moiseev, R. Sennrich, I. Titov, Analyzing multi- head self-attention: Specialized heads do the heavy lifting, the rest can be pruned, in: Proceedings of the 57th Annual Meeting of the Association for 18 Computational Linguistics, 2019, pp. 5797–5808.doi:10.18653/v1/ P19-1580. URL https://aclanthology.org/P19-1580/
-
[29]
X. Qu, Z. Yu, D. Liu, W. Wei, D. Liu, J. Dong, Y . Cheng, Cooperative or competitive? understanding the interaction between attention heads from a game theory perspective, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), As- sociation for Computational Linguistics, Vienna, Austria, 2025,...
-
[30]
K. Chakrabarti, N. Balachundar, Multi-head attention is a multi-player game, arXiv preprint arXiv:2602.00861, submitted to Nature (2026). URL https://arxiv.org/abs/2602.00861
-
[31]
F. Meng, P. Tang, F. Jiang, M. Zhang, Clover: Cross-layer orthogonal vec- tors pruning and fine-tuningArXiv:2411.17426v3 [cs.LG] (2025).arXiv: 2411.17426,doi:10.48550/arXiv.2411.17426. URL https://arxiv.org/abs/2411.17426
-
[32]
Y . Wang, H. He, S. Bao, H. Wu, H. Wang, Q. Zhu, W. Che, Proxy- attn: Guided sparse attention via representative heads, arXiv:2509.24745v2 [cs.CL], ICLR 2026 camera ready (2026).arXiv:2509.24745,doi: 10.48550/arXiv.2509.24745. URL https://arxiv.org/abs/2509.24745
-
[33]
J. Sok, J. Yeom, S. Park, J. Park, T. Kim, Garbage attention in large language models: BOS sink heads and sink-aware pruning, arXiv:2601.06787v1 [cs.CL] (2026).arXiv:2601.06787,doi:10.48550/arXiv. 2601.06787. URL https://arxiv.org/abs/2601.06787
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[34]
L. Xiong, N. Liu, A. Ren, Y . Bai, H. Fang, B. Zhang, Z. Jiang, Y . Tan, D. Liu,d 2prune: Sparsifying large language models via dual taylor expan- sion and attention distribution awareness, aAAI 2026, volume 40, number 32, pages 27171-27179, DOI 10.1609/aaai.v40i32.39932 (2026).arXiv: 2601.09176,doi:10.48550/arXiv.2601.09176. URL https://arxiv.org/abs/260...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.