Recognition: no theorem link
Assessment of RAG and Fine-Tuning for Industrial Question-Answering-Applications
Pith reviewed 2026-05-12 05:02 UTC · model grok-4.3
The pith
RAG outperforms fine-tuning as the most effective and cost-efficient adaptation method for both closed- and open-source models on automotive question-answering tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Premium closed models perform best out of the box, yet open-source models reach comparable quality when enhanced with retrieval-augmented generation. Across both closed- and open-source models, retrieval-augmented generation emerges as the most effective and cost-efficient adaptation method for the two automotive question-answering datasets.
What carries the argument
The extended Cost-of-Pass framework, which jointly measures output quality, generation cost, and user interaction cost to compare retrieval-augmented generation against fine-tuning.
If this is right
- Open-source models can match closed-model quality through retrieval-augmented generation.
- Retrieval-augmented generation reduces overall operational costs relative to fine-tuning for both model types.
- Premium models still benefit from retrieval-augmented generation but start from a higher baseline.
- Adaptation remains necessary for optimal domain performance even with strong base models.
Where Pith is reading between the lines
- Companies facing similar technical domains could favor retrieval-augmented generation pipelines to lower long-term adaptation expenses.
- The cost-quality trade-off may extend to other regulated industries if their internal data exhibits comparable structure.
- Further extensions of the cost model could incorporate data curation and maintenance expenses for a more complete operational picture.
Load-bearing premise
The two closed automotive datasets and the extended Cost-of-Pass model are representative of real industrial QA workloads and capture all relevant operational costs.
What would settle it
A replication on a different industrial domain dataset where fine-tuning produces either higher answer quality or lower total costs than retrieval-augmented generation would falsify the central finding.
Figures





read the original abstract
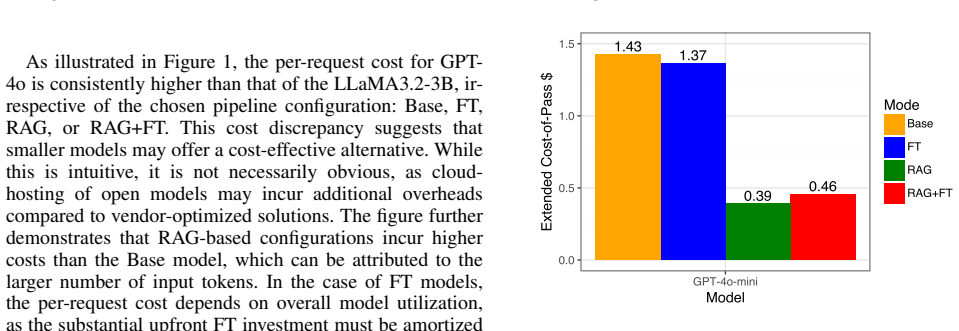
Large Language Models (LLMs) are increasingly employed in enterprise question-answering (QA) systems, requiring adaptation to domain-specific knowledge. Among the most prevalent methods for incorporating such knowledge are Retrieval-Augmented Generation (RAG) and fine-tuning (FT). Yet, from a cost-accuracy trade-off perspective, it remains unclear which approach best suits industry scenarios. This study examines the impact of RAG and FT on two closed datasets specific to the automotive industry, assessing answer quality and operational costs. We extend the Cost-of-Pass framework proposed by Erol et al. (arXiv:2504.13359) to jointly assess output quality, generation cost, and user interaction cost. Our findings reveal that while premium models perform best out of the box, open-source models can achieve comparable quality when enhanced with RAG. Overall, RAG emerges as the most effective and cost-efficient adaptation method for both closed- and open-source models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically compares Retrieval-Augmented Generation (RAG) and fine-tuning (FT) as adaptation methods for large language models in domain-specific question-answering tasks, using two proprietary automotive-industry datasets. It extends the Cost-of-Pass framework to jointly evaluate answer quality, generation costs, retrieval/indexing costs, and user-interaction costs, concluding that RAG yields the best quality-cost trade-off for both closed-source and open-source models.
Significance. If the empirical ranking holds under broader scrutiny, the work supplies practical guidance for industrial QA deployments by quantifying when RAG is preferable to fine-tuning on both quality and operational-cost dimensions. The explicit extension of the Cost-of-Pass model to include user-interaction costs is a constructive methodological step that could be reused in other enterprise settings.
major comments (3)
- [Abstract / Results] Abstract and Results sections: the headline claim that RAG is the most effective and cost-efficient method is stated without any numerical quality scores, cost values, dataset sizes, error bars, or statistical significance tests, preventing assessment of effect sizes or robustness.
- [Methods] Methods section: reliance on two closed automotive datasets without public release, cross-domain validation sets, or comparison against standard QA benchmarks leaves the representativeness assumption untested; any mismatch in query distribution or domain complexity would invalidate the cost-quality ranking.
- [Evaluation framework] Cost-model extension (presumably described in the evaluation framework): the extended Cost-of-Pass formulation must demonstrate that all operational components (generation, retrieval, indexing, and user time) are captured without systematic omissions or arbitrary weightings, as this directly supports the cost-efficiency conclusion.
minor comments (3)
- Clarify the exact closed- and open-source model families, parameter counts, and retrieval configurations (chunk size, embedding model, top-k) used in each condition.
- Add a table or figure that reports raw quality metrics (e.g., accuracy, F1, or human ratings) alongside the derived Cost-of-Pass scores for direct inspection.
- Ensure all cost units and assumptions in the extended Cost-of-Pass model are explicitly listed so readers can reproduce the arithmetic.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where revisions will be incorporated into the manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results sections: the headline claim that RAG is the most effective and cost-efficient method is stated without any numerical quality scores, cost values, dataset sizes, error bars, or statistical significance tests, preventing assessment of effect sizes or robustness.
Authors: We agree that the abstract would be strengthened by including key numerical results. In the revised manuscript we will insert specific quality metrics (e.g., exact-match and F1 scores), per-query generation and retrieval costs, and dataset sizes directly into the abstract. The Results section already contains tables reporting these quantities for each model and adaptation method; we will add error bars (standard deviations across query subsets) and pairwise statistical significance tests (paired t-tests with Bonferroni correction) to the tables and text. Dataset sizes are stated in Methods but will be repeated in Results for clarity. revision: yes
-
Referee: [Methods] Methods section: reliance on two closed automotive datasets without public release, cross-domain validation sets, or comparison against standard QA benchmarks leaves the representativeness assumption untested; any mismatch in query distribution or domain complexity would invalidate the cost-quality ranking.
Authors: The datasets are proprietary and subject to confidentiality agreements, so public release is not possible. We will expand the Methods section with a detailed characterization of query types, length distributions, domain-specific terminology density, and answer complexity to support the claim of industrial representativeness. While cross-domain validation sets cannot be created from these data, we will add a new subsection comparing the same models on two public QA benchmarks (SQuAD 2.0 and a subset of Natural Questions) under identical RAG and fine-tuning protocols. This will provide external calibration of the observed quality-cost trade-offs. revision: partial
-
Referee: [Evaluation framework] Cost-model extension (presumably described in the evaluation framework): the extended Cost-of-Pass formulation must demonstrate that all operational components (generation, retrieval, indexing, and user time) are captured without systematic omissions or arbitrary weightings, as this directly supports the cost-efficiency conclusion.
Authors: We will revise the Evaluation Framework section to include an explicit component-by-component mapping. For each term in the extended Cost-of-Pass equation we will state the measured quantity (generation tokens, retrieval latency, indexing storage, and measured user dwell time from interaction logs), the source of the measurement, and the justification for any weighting coefficients (taken from the original Erol et al. formulation or calibrated against internal automotive deployment logs). This will make transparent that no major operational cost category has been omitted and that weightings are not arbitrary. revision: yes
- Public release of the two proprietary automotive datasets is precluded by confidentiality agreements with the data providers.
Circularity Check
No circularity; purely empirical comparison on measured outcomes
full rationale
The paper reports experimental results from applying RAG and fine-tuning to two private automotive QA datasets, then measures answer quality and operational costs via an extension of the external Cost-of-Pass framework (Erol et al.). No mathematical derivations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the load-bearing claims. All headline findings rest on direct experimental measurements rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RAFT: Adapting Language Model to Domain Specific RAG , author=. 2024 , volume =
work page 2024
-
[2]
Pichlmeier, Josef and Ross, Philipp and Luckow, Andre , booktitle =. 2024 , volume =. doi:10.1109/BigData62323.2024.10826121 , url =
-
[3]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =. 2017 , bdsk-url-1 =
work page 2017
-
[4]
Don`t Stop Pretraining: Adapt Language Models to Domains and Tasks
Gururangan, Suchin and Marasovi \'c , Ana and Swayamdipta, Swabha and Lo, Kyle and Beltagy, Iz and Downey, Doug and Smith, Noah A. Don`t Stop Pretraining: Adapt Language Models to Domains and Tasks. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.740
-
[5]
arXiv preprint arXiv:2408.13296 (2024)
Venkatesh Balavadhani Parthasarathy and Ahtsham Zafar and Aafaq Khan and Arsalan Shahid , year=. 2408.13296 , archivePrefix =
-
[6]
arXiv preprint arXiv:2310.05492 , year=
Guanting Dong and Hongyi Yuan and Keming Lu and Chengpeng Li and Mingfeng Xue and Dayiheng Liu and Wei Wang and Zheng Yuan and Chang Zhou and Jingren Zhou , year=. 2310.05492 , archivePrefix=
-
[7]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han and Chao Gao and Jinyang Liu and Jeff Zhang and Sai Qian Zhang , year=. 2403.14608 , archivePrefix=
work page internal anchor Pith review arXiv
-
[8]
rlhf: Scaling reinforcement learning from human feedback with ai feedback , author=
Harrison Lee and Samrat Phatale and Hassan Mansoor and Thomas Mesnard and Johan Ferret and Kellie Lu and Colton Bishop and Ethan Hall and Victor Carbune and Abhinav Rastogi and Sushant Prakash , year=. 2309.00267 , archivePrefix=
-
[9]
arXiv preprint arXiv:2312.14925
Timo Kaufmann and Paul Weng and Viktor Bengs and Eyke Hüllermeier , year=. 2312.14925 , archivePrefix=
-
[10]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
work page 2023
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[12]
Fine Tuning LLM for Enterprise: Practical Guidelines and Recommendations , author=. 2024 , eprint=
work page 2024
-
[13]
A Practical Guide to Fine-tuning Language Models with Limited Data , author=. 2024 , eprint=
work page 2024
-
[14]
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness , author=. 2024 , eprint=
work page 2024
-
[15]
Continual Learning for Large Language Models: A Survey , author=. 2024 , eprint=
work page 2024
-
[16]
Revisiting Out-of-distribution Robustness in NLP: Benchmark, Analysis, and LLMs Evaluations , author=. 2023 , eprint=
work page 2023
-
[17]
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? , author=. 2024 , eprint=
work page 2024
-
[18]
arXiv preprint arXiv:2312.05934 , year=
Oded Ovadia and Menachem Brief and Moshik Mishaeli and Oren Elisha , title =. 2023 , volume =. 2312.05934 , archivePrefix =
-
[19]
Strategic Data Ordering: Enhancing Large Language Model Performance through Curriculum Learning , author=. 2024 , eprint=
work page 2024
-
[20]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich Küttler and Mike Lewis and Wen-tau Yih and Tim Rocktäschel and Sebastian Riedel and Douwe Kiela , year=. 2005.11401 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[21]
Retrieval-augmented generation for ai-generated content: A survey,
Penghao Zhao and Hailin Zhang and Qinhan Yu and Zhengren Wang and Yunteng Geng and Fangcheng Fu and Ling Yang and Wentao Zhang and Jie Jiang and Bin Cui , year=. 2402.19473 , archivePrefix=
- [22]
-
[23]
Heydar Soudani and Evangelos Kanoulas and Faegheh Hasibi , title =. 2024 , url =. 2403.01432 , archivePrefix =
-
[24]
Angels Balaguer and Vinamra Benara and Renato Luiz de Freitas Cunha and Roberto de M. Estevão Filho and Todd Hendry and Daniel Holstein and Jennifer Marsman and Nick Mecklenburg and Sara Malvar and Leonardo O. Nunes and Rafael Padilha and Morris Sharp and Bruno Silva and Swati Sharma and Vijay Aski and Ranveer Chandra , title =. 2024 , url =. 2401.08406 ,...
-
[25]
Zooey Nguyen and Anthony Annunziata and Vinh Luong and Sang Dinh and Quynh Le and Anh Hai Ha and Chanh Le and Hong An Phan and Shruti Raghavan and Christopher Nguyen , title =. 2024 , url =. 2404.11792 , archivePrefix =
-
[26]
Robert Lakatos and Peter Pollner and Andras Hajdu and Tamas Joo , title =. 2024 , url =. 2403.09727 , archivePrefix =
-
[27]
Alireza Salemi and Hamed Zamani , title =. 2024 , url =. 2409.09510 , archivePrefix =
-
[28]
Eric Wu and Kevin Wu and James Zou , title =. 2024 , url =. 2411.05059 , archivePrefix =
-
[29]
Plagiarism --- W ikipedia , The Free Encyclopedia
Wikipedia contributors. Plagiarism --- W ikipedia , The Free Encyclopedia. 2004
work page 2004
-
[30]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
work page 2004
-
[31]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
work page 2005
-
[32]
Bleu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[33]
BLEURT: Learning Robust Metrics for Text Generation , author =. 2020 , booktitle =
work page 2020
-
[34]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[35]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , url =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , biburl =. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , url =
-
[36]
Learning compact metrics for MT , author =. Proceedings of EMNLP , year =
-
[37]
Weinberger and Yoav Artzi , title =
Tianyi Zhang and Varsha Kishore and Felix Wu and Kilian Q. Weinberger and Yoav Artzi , title =. 2019 , url =
work page 2019
-
[38]
BLEURT : Learning Robust Metrics for Text Generation
Sellam, Thibault and Das, Dipanjan and Parikh, Ankur. BLEURT : Learning Robust Metrics for Text Generation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.704
-
[39]
Tri Nguyen and Mir Rosenberg and Xia Song and Jianfeng Gao and Saurabh Tiwary and Rangan Majumder and Li Deng , title =. CoRR , volume =. 2016 , url =
work page 2016
-
[40]
On the Opportunities and Risks of Foundation Models , author=. ArXiv , year=
-
[41]
Azure OpenAI Service Pricing Details , howpublished =
-
[42]
Cost-of-Pass: An Economic Framework for Evaluating Language Models , doi =
Erol, Mehmet Hamza and El, Batu and Suzgun, Mirac and Yuksekgonul, Mert and Zou, James , date =. Cost-of-Pass: An Economic Framework for Evaluating Language Models , doi =. 2025 , Eprint =. 2504.13359 , eprintclass =
-
[43]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[44]
Can Large Language Models Be an Alternative to Human Evaluations?
Chiang, Cheng-Han and Lee, Hung-yi. Can Large Language Models Be an Alternative to Human Evaluations?. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
work page 2023
-
[45]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
work page 2023
-
[46]
Lianghui Zhu and Xinggang Wang and Xinlong Wang , Title =. 2023 , Eprint =
work page 2023
-
[47]
C-Pack: Packaged Resources To Advance General Chinese Embedding , author=. 2023 , eprint=
work page 2023
-
[48]
RAGGED: Towards Informed Design of Retrieval Augmented Generation Systems , doi =
Hsia, Jennifer and Shaikh, Afreen and Wang, Zhiruo and Neubig, Graham , date =. RAGGED: Towards Informed Design of Retrieval Augmented Generation Systems , doi =. 2403.09040 , eprintclass =
-
[49]
arXiv preprint arXiv:2305.18703
Ling, Chen and Zhao, Xujiang and Lu, Jiaying and Deng, Chengyuan and Zheng, Can and Wang, Junxiang and Chowdhury, Tanmoy and Li, Yun and Cui, Hejie and Zhang, Xuchao and Zhao, Tianjiao and Panalkar, Amit and Mehta, Dhagash and Pasquali, Stefano and Cheng, Wei and Wang, Haoyu and Liu, Yanchi and Chen, Zhengzhang and Chen, Haifeng and White, Chris and Gu, Q...
-
[50]
Aditya Challapally and Chris Pease and Ramesh Raskar and Pradyumna Chari , year =. The GenAI Divide , type =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.