Recognition: no theorem link
TAD: Temporal-Aware Trajectory Self-Distillation for Fast and Accurate Diffusion LLM
Pith reviewed 2026-05-12 04:55 UTC · model grok-4.3
The pith
TAD improves the accuracy-parallelism trade-off in diffusion LLMs by distilling time-partitioned trajectories from a teacher conditioned on ground truth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
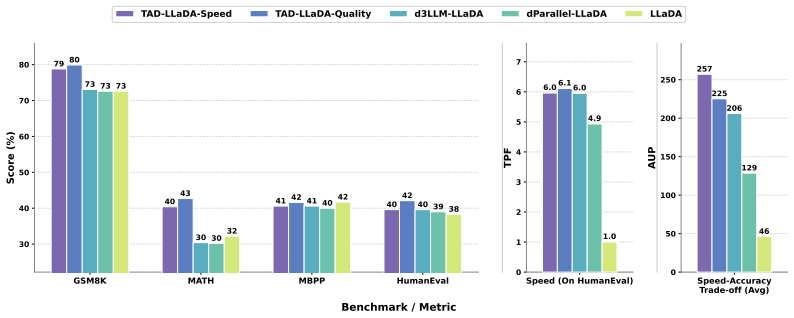
Conditioning the teacher on both prompt and ground-truth response to record masked states throughout decoding, then partitioning positions into near and distant subsets by remaining steps before revelation, and applying cross-entropy loss to near tokens while applying KL divergence to distant tokens, produces student models whose Quality variant raises average accuracy from 46.2 percent to 51.6 percent and whose Speed variant raises average AUP from 46.2 to 257.1 on LLaDA.
What carries the argument
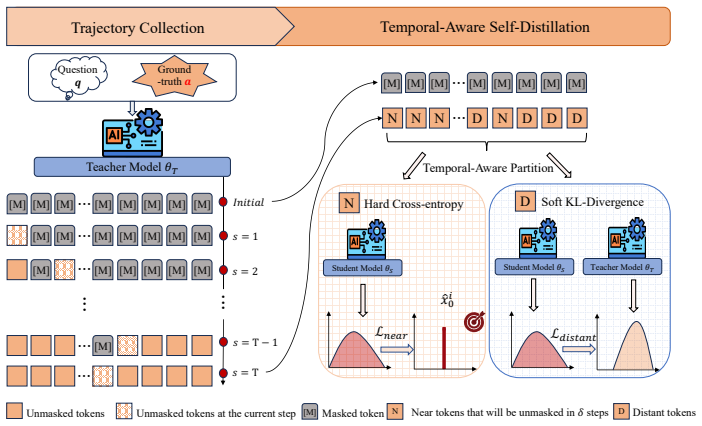
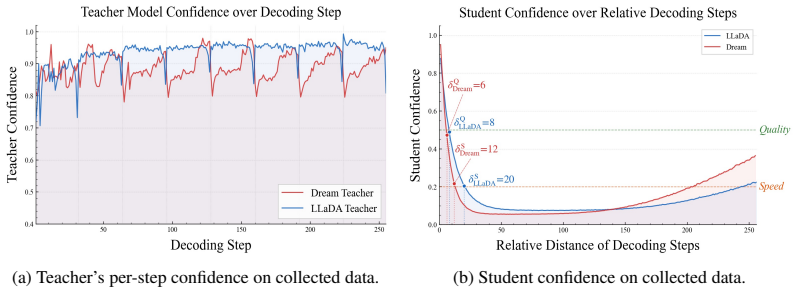
The temporal partition of masked positions into near and distant subsets according to remaining decoding steps, which selects between hard cross-entropy supervision and soft KL-divergence supervision.
Load-bearing premise
Conditioning the teacher on the complete ground-truth response yields trajectories that supply fair, non-leaking supervision to the student.
What would settle it
Train an otherwise identical student using teacher trajectories generated from the prompt alone without ground-truth access, then measure whether the reported gains in accuracy and AUP disappear.
Figures
read the original abstract
Diffusion large language models (dLLMs) offer a promising paradigm for parallel text generation, but in practice they face an accuracy-parallelism trade-off, where increasing tokens per forward (TPF) often degrades generation quality. Existing acceleration methods often gain speed at the cost of accuracy. To address this limitation, we propose TAD, a Temporal-Aware trajectory self-Distillation framework. During data construction, we condition a teacher model on both the prompt and the ground-truth response to generate decoding trajectories, recording the intermediate masked states throughout the process. Based on how many decoding steps remain before each masked token is revealed, we partition masked positions into near and distant subsets. For near tokens, we train the student with a hard cross-entropy loss using the teacher trajectory tokens as labels, encouraging confident predictions for tokens that are about to be decoded. For distant tokens, we apply a soft KL divergence loss between the teacher and student token distributions, providing softer supervision and preserving future planning knowledge. This temporal-aware partition naturally gives rise to two deployment configurations: a Quality model that prioritizes accuracy and a Speed model that favors more aggressive acceleration. Experiments show that TAD consistently improves the accuracy-parallelism trade-off. On LLaDA, it raises average accuracy from 46.2\% to 51.6\% with the Quality model and average AUP from 46.2 to 257.1 with the Speed model. Our code is available at: https://github.com/BHmingyang/TAD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TAD, a temporal-aware trajectory self-distillation method for diffusion LLMs to mitigate the accuracy-parallelism trade-off. During training, a teacher model is conditioned on both the prompt and full ground-truth response to generate decoding trajectories; masked positions are partitioned into near and distant subsets based on remaining decoding steps before each token is revealed. Near tokens receive hard cross-entropy supervision from the teacher trajectory, while distant tokens receive soft KL divergence. This yields two inference modes (Quality and Speed models). Experiments on LLaDA report lifting average accuracy from 46.2% to 51.6% (Quality) and average AUP from 46.2 to 257.1 (Speed). Code is released.
Significance. If the reported gains prove robust and free of supervision artifacts, TAD would offer a practical way to improve the speed-quality frontier for parallel decoding in diffusion LLMs, a currently active area. The explicit release of code and the concrete numerical claims on a public benchmark are positive factors that would facilitate follow-up work.
major comments (2)
- [Abstract / Method] Abstract (method description) and the data-construction procedure: conditioning the teacher on the full ground-truth response to record intermediate masked states and then partitioning by remaining decoding steps means that both the hard CE labels and the soft KL targets encode information about tokens that have not yet been generated at the corresponding diffusion step. At inference the student sees only the prompt, so any measured accuracy or AUP improvement could be an artifact of this oracle supervision rather than a genuine advance in the diffusion dynamics. This is load-bearing for the central empirical claim.
- [Experiments] Experiments section: the reported lifts (46.2 % → 51.6 % accuracy; 46.2 → 257.1 AUP) are given as single-point averages without error bars, multiple random seeds, or ablation on the near/distant threshold. Without these controls it is impossible to determine whether the gains are stable across hyper-parameter choices or data splits, weakening the claim that TAD “consistently improves” the trade-off.
minor comments (2)
- [Abstract] Notation for “TPF” (tokens per forward) and “AUP” is introduced without an explicit definition or reference to prior work; a short footnote or equation would improve clarity.
- [Method] The paper states that two deployment configurations “naturally arise” from the temporal partition, but does not specify how the Quality vs. Speed inference schedules are chosen at test time (e.g., different masking schedules or temperature settings).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below with clarifications and indicate planned changes to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract (method description) and the data-construction procedure: conditioning the teacher on the full ground-truth response to record intermediate masked states and then partitioning by remaining decoding steps means that both the hard CE labels and the soft KL targets encode information about tokens that have not yet been generated at the corresponding diffusion step. At inference the student sees only the prompt, so any measured accuracy or AUP improvement could be an artifact of this oracle supervision rather than a genuine advance in the diffusion dynamics. This is load-bearing for the central empirical claim.
Authors: We appreciate the referee highlighting this aspect of the teacher conditioning. The teacher is conditioned on the full ground-truth to produce high-quality trajectories that reflect effective unmasking sequences. The temporal partition then applies hard CE to near tokens (those revealed soon) to promote confident predictions and soft KL to distant tokens to retain planning information. Although the teacher has access to future tokens, the supervision is applied at diffusion steps that mirror the student's inference view, with the goal of transferring improved temporal dynamics. We will revise the method and abstract sections to explicitly discuss the teacher conditioning and its intended effect on the student's learned behavior, distinguishing it from direct future-token leakage. revision: partial
-
Referee: [Experiments] Experiments section: the reported lifts (46.2 % → 51.6 % accuracy; 46.2 → 257.1 AUP) are given as single-point averages without error bars, multiple random seeds, or ablation on the near/distant threshold. Without these controls it is impossible to determine whether the gains are stable across hyper-parameter choices or data splits, weakening the claim that TAD “consistently improves” the trade-off.
Authors: We agree that single-run results limit assessment of robustness. In the revised manuscript we will report results averaged over multiple random seeds with standard deviations or error bars. We will also add an ablation varying the near/distant threshold to show its effect on performance and support the consistency claim. revision: yes
Circularity Check
No significant circularity; method is an empirical training procedure measured on external benchmarks
full rationale
The paper describes a self-distillation training procedure that conditions a teacher on prompt plus ground-truth response to record masked trajectories, partitions positions by remaining steps, and applies hard CE or soft KL losses. The reported gains (accuracy from 46.2% to 51.6%, AUP from 46.2 to 257.1 on LLaDA) are obtained by evaluating the resulting student models on independent test sets and benchmarks. No equations or claims reduce any prediction to a quantity defined by the same fitted parameters or self-referential loop. No self-citations are invoked as load-bearing uniqueness theorems, and the central construction does not rename or smuggle in prior results by definition. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditioning the teacher on ground-truth responses yields valid and useful decoding trajectories for student training.
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
work page 2021
-
[2]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InProceedings of the 41st International Conference on Machine Learning, pages 32819–32848, 2024
work page 2024
-
[3]
Simple and effective masked diffusion language models
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[4]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
work page 2024
-
[5]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Wonjun Kang, Kevin Galim, Seunghyuk Oh, Minjae Lee, Yuchen Zeng, Shuibai Zhang, Coleman Hooper, Yuezhou Hu, Hyung Il Koo, Nam Ik Cho, et al. Parallelbench: Understanding the trade-offs of parallel decoding in diffusion llms.arXiv preprint arXiv:2510.04767, 2025
-
[7]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025
-
[8]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, and Hao Zhang. d3llm: Ultra-fast diffusion llm using pseudo-trajectory distillation.arXiv preprint arXiv:2601.07568, 2026
-
[10]
dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488,
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488, 2025
-
[11]
Feng Hong, Geng Yu, Yushi Ye, Haicheng Huang, Huangjie Zheng, Ya Zhang, Yanfeng Wang, and Jiangchao Yao. Wide-in, narrow-out: Revokable decoding for efficient and effective dllms.arXiv preprint arXiv:2507.18578, 2025
-
[12]
Lopa: Scaling dllm inference via lookahead parallel decoding.arXiv preprint arXiv:2512.16229,
Chenkai Xu, Yijie Jin, Jiajun Li, Yi Tu, Guoping Long, Dandan Tu, Mingcong Song, Hongjie Si, Tianqi Hou, Junchi Yan, et al. Lopa: Scaling dllm inference via lookahead parallel decoding.arXiv preprint arXiv:2512.16229, 2025
-
[13]
Amr Mohamed, Yang Zhang, Michalis Vazirgiannis, and Guokan Shang. Fast-decoding diffusion language models via progress-aware confidence schedules.arXiv preprint arXiv:2512.02892, 2025
-
[14]
Tunyu Zhang, Xinxi Zhang, Ligong Han, Haizhou Shi, Xiaoxiao He, Zhuowei Li, Hao Wang, Kai Xu, Akash Srivastava, Vladimir Pavlovic, et al. T3d: Few-step diffusion language models via trajectory self-distillation with direct discriminative optimization.arXiv preprint arXiv:2602.12262, 2026
-
[15]
Diffusion LLMs Can Do Faster- Than-AR Inference via Discrete Diffusion Forcing, August 2025c
Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. Diffusion llms can do faster-than-ar inference via discrete diffusion forcing.arXiv preprint arXiv:2508.09192, 2025
-
[16]
Efficient diffusion language models: A comprehensive survey.Authorea Preprints, 2026
Haokun Lin, Xinle Jia, Shaozhen Liu, Shujun Xia, Weitao Huang, Haobo Xu, Junyang Li, Yicheng Xiao, Xingrun Xing, Ziyu Guo, et al. Efficient diffusion language models: A comprehensive survey.Authorea Preprints, 2026
work page 2026
-
[17]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026. 10
work page internal anchor Pith review arXiv 2026
-
[20]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[23]
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran. Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6980–7008, 2025
work page 2025
-
[24]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[25]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025
-
[28]
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 45(9):10850–10869, 2023
work page 2023
-
[29]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025
-
[33]
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025
-
[34]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review arXiv 2025
- [35]
-
[36]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou. Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303, 2025
-
[37]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216, 2025
-
[38]
Revolutionizing reinforcement learning framework for diffusion large language models
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutionizing reinforcement learning framework for diffusion large language models.arXiv preprint arXiv:2509.06949, 2025. 11
-
[39]
wd1: Weighted policy optimization for reasoning in diffusion language models
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838, 2025
-
[40]
Principled rl for diffusion llms emerges from a sequence-level perspective, 2025
Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jianwen Xie, Stefano Ermon, Yi Wu, and Chongx- uan Li. Principled rl for diffusion llms emerges from a sequence-level perspective.arXiv preprint arXiv:2512.03759, 2025
-
[41]
Jiawei Liu, Xiting Wang, Yuanyuan Zhong, Defu Lian, and Yu Yang. Efficient and stable reinforcement learning for diffusion language models.arXiv preprint arXiv:2602.08905, 2026
-
[42]
Dllm agent: See farther, run faster.arXiv preprint arXiv:2602.07451, 2026
Huiling Zhen, Weizhe Lin, Renxi Liu, Kai Han, Yiming Li, Yuchuan Tian, Hanting Chen, Xiaoguang Li, Xiaosong Li, Chen Chen, et al. Dllm agent: See farther, run faster.arXiv preprint arXiv:2602.07451, 2026
-
[43]
Jiahao Zhao, Shaoxuan Xu, Zhongxiang Sun, Fengqi Zhu, Jingyang Ou, Yuling Shi, Chongxuan Li, Xiao Zhang, and Jun Xu. Dllm-searcher: Adapting diffusion large language model for search agents.arXiv preprint arXiv:2602.07035, 2026
-
[44]
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching.arXiv preprint arXiv:2506.06295, 2025
-
[45]
DKV-Cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025
-
[46]
Yuchu Jiang, Yue Cai, Xiangzhong Luo, Jiale Fu, Jiarui Wang, Chonghan Liu, and Xu Yang. d2 cache: Accelerating diffusion-based llms via dual adaptive caching.arXiv preprint arXiv:2509.23094, 2025
-
[47]
Jucheng Shen, Gaurav Sarkar, Yeonju Ro, Sharath Nittur Sridhar, Zhangyang Wang, Aditya Akella, and Souvik Kundu. Improving the throughput of diffusion-based large language models via a training-free confidence-aware calibration.arXiv preprint arXiv:2512.07173, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Shutong Wu and Jiawei Zhang. Free draft-and-verification: Toward lossless parallel decoding for diffusion large language models.arXiv preprint arXiv:2510.00294, 2025
-
[49]
CreditDecoding: Accelerating Parallel Decoding in Diffusion Large Language Models with Trace Credit
Kangyu Wang, Zhiyun Jiang, Haibo Feng, Weijia Zhao, Lin Liu, Jianguo Li, Zhenzhong Lan, and Weiyao Lin. Creditdecoding: Accelerating parallel decoding in diffusion large language models with trace credits. arXiv preprint arXiv:2510.06133, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Minseo Kim, Chenfeng Xu, Coleman Hooper, Harman Singh, Ben Athiwaratkun, Ce Zhang, Kurt Keutzer, and Amir Gholami. Cdlm: Consistency diffusion language models for faster sampling.arXiv preprint arXiv:2511.19269, 2025
-
[51]
Yihao Liang, Ze Wang, Hao Chen, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Emad Barsoum, Zicheng Liu, and Niraj K Jha. Cd4lm: Consistency distillation and adaptive decoding for diffusion language models.arXiv preprint arXiv:2601.02236, 2026
-
[52]
Wenrui Bao, Zhiben Chen, Dan Xu, and Yuzhang Shang. Learning to parallel: Accelerating diffusion large language models via learnable parallel decoding.arXiv preprint arXiv:2509.25188, 2025
-
[53]
Yanzhe Hu, Yijie Jin, Pengfei Liu, Kai Yu, and Zhijie Deng. Lightningrl: Breaking the accuracy-parallelism trade-off of block-wise dllms via reinforcement learning.arXiv preprint arXiv:2603.13319, 2026. 12 A Proof of Theoretical Analysis A.1 Equivalence of Joint KL Divergence and Expected Cross-Entropy We prove that minimizing the Kullback-Leibler diverge...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.