Recognition: no theorem link
Towards Compact Sign Language Translation: Frame Rate and Model Size Trade-offs
Pith reviewed 2026-05-12 04:34 UTC · model grok-4.3
The pith
Reducing sign language video to 12 fps cuts encoder computation by 75% in a 77M-parameter T5 model with only a small BLEU drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Coupling MMPose skeletal pose extraction with a single linear projection into T5-small yields a compact 77M-parameter gloss-free pipeline. At 12 fps the halved input sequence length delivers a 75 percent reduction in encoder quadratic self-attention complexity and a BLEU-4 of 9.53 on How2Sign, compared with 10.06 at 24 fps. The system is roughly three times smaller than prior T5-base approaches and avoids both large-scale models and hierarchical encoders.
What carries the argument
Frame-rate control on the pose-feature sequence fed to T5-small, which shortens the input length and thereby scales down quadratic self-attention cost while preserving translation quality.
Load-bearing premise
That MMPose skeletal poses extracted at half the frame rate still contain enough sign information for the T5 decoder to produce accurate translations.
What would settle it
A clear reversal where the 12 fps model shows a much larger BLEU drop than 0.53 points on any other sign-language video corpus or under real-world recording conditions.
Figures
read the original abstract
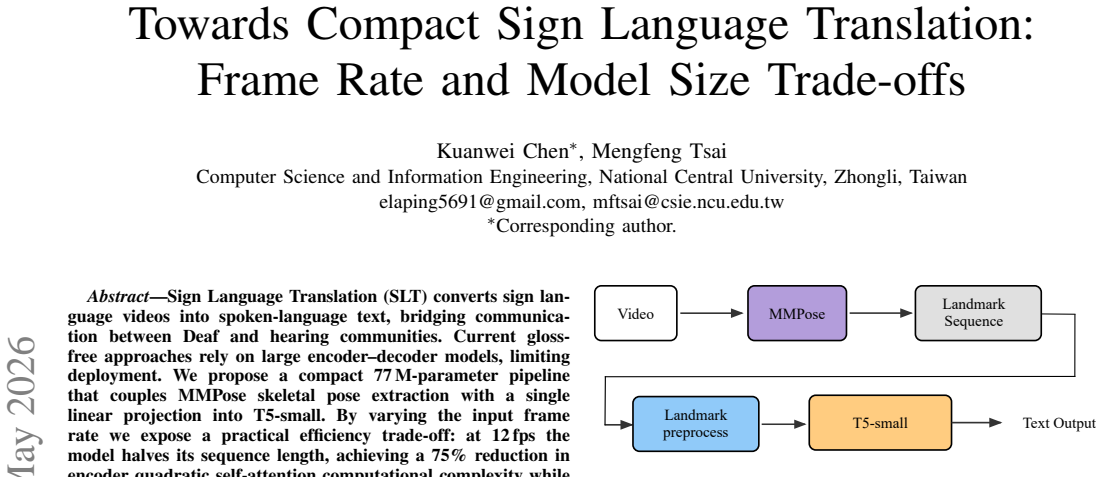
Sign Language Translation (SLT) converts sign language videos into spoken-language text, bridging communication between Deaf and hearing communities. Current gloss-free approaches rely on large encoder-decoder models, limiting deployment. We propose a compact 77M-parameter pipeline that couples MMPose skeletal pose extraction with a single linear projection into T5-small. By varying the input frame rate, we expose a practical efficiency trade-off: at 12 fps the model halves its sequence length, achieving a 75% reduction in encoder quadratic self-attention computational complexity while incurring only a modest BLEU-4 drop (9.53 vs. 10.06 at 24 fps on How2Sign). Our system is roughly 3x smaller than prior T5-base systems, demonstrating that a lightweight architecture can remain competitive without hierarchical encoders or large-scale models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a compact 77M-parameter gloss-free sign language translation pipeline that extracts skeletal poses via MMPose, applies a linear projection, and feeds the result into T5-small. It shows that lowering the input frame rate from 24 fps to 12 fps halves sequence length and yields a 75% reduction in encoder quadratic self-attention complexity, with BLEU-4 falling only from 10.06 to 9.53 on How2Sign, while remaining competitive with larger prior T5-base systems.
Significance. If the observed efficiency-performance trade-off generalizes, the work could support practical deployment of SLT models on edge devices by avoiding large encoders or hierarchical designs. The explicit quadratic-complexity calculation and concrete BLEU numbers on a public benchmark are strengths, but the single-dataset scope limits broader impact claims.
major comments (2)
- [Abstract and experimental evaluation] The central claim that 12 fps incurs only a 'modest' BLEU-4 drop (0.53 points) while preserving necessary sign dynamics rests on the untested assumption that MMPose poses remain sufficiently informative at halved temporal resolution. No analysis of pose estimation fidelity, velocity aliasing for sub-100 ms handshape changes, or feature informativeness versus frame rate is provided, and all results are confined to How2Sign.
- [Results section] The manuscript reports point estimates (BLEU-4 = 9.53 vs. 10.06) without error bars, multiple runs, or statistical tests, so it is impossible to determine whether the observed difference lies within run-to-run variance or truly supports the 'practical efficiency trade-off' conclusion.
minor comments (2)
- [Abstract] The statement that the system is 'roughly 3x smaller than prior T5-base systems' should include the exact parameter counts of the referenced baselines for direct comparison.
- [Methodology] Notation for the linear projection layer and the exact T5-small configuration (e.g., hidden size, number of layers) should be defined explicitly rather than assumed from the T5 literature.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments below, proposing revisions where appropriate to improve the clarity and robustness of our claims regarding the efficiency-performance trade-off in compact sign language translation models.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] The central claim that 12 fps incurs only a 'modest' BLEU-4 drop (0.53 points) while preserving necessary sign dynamics rests on the untested assumption that MMPose poses remain sufficiently informative at halved temporal resolution. No analysis of pose estimation fidelity, velocity aliasing for sub-100 ms handshape changes, or feature informativeness versus frame rate is provided, and all results are confined to How2Sign.
Authors: We thank the referee for highlighting this important point. Indeed, the manuscript does not provide an explicit analysis of MMPose's pose estimation fidelity at reduced frame rates or potential issues with velocity aliasing for rapid handshape changes. The observed BLEU drop is empirical on How2Sign, but we agree the preservation of sign dynamics remains an assumption without such analysis. In the revised version, we will add a limitations section to discuss the single-dataset evaluation and lack of frame-rate-specific pose quality analysis. We will also moderate the language in the abstract from 'modest' to 'small' and note the need for future studies on temporal effects. revision: partial
-
Referee: [Results section] The manuscript reports point estimates (BLEU-4 = 9.53 vs. 10.06) without error bars, multiple runs, or statistical tests, so it is impossible to determine whether the observed difference lies within run-to-run variance or truly supports the 'practical efficiency trade-off' conclusion.
Authors: We agree that relying on single point estimates makes it difficult to gauge the reliability of the observed difference. In the revision, we commit to running multiple training trials with different random seeds and reporting average BLEU-4 scores with standard deviations. This will allow us to include error bars and better substantiate the efficiency trade-off claim. revision: yes
Circularity Check
No significant circularity; empirical measurements only
full rationale
The paper reports direct experimental results: BLEU-4 scores measured on How2Sign for 24 fps vs 12 fps inputs to a T5-small pipeline after MMPose pose extraction. Sequence-length halving and the resulting 75% quadratic attention complexity reduction are standard arithmetic consequences of input length, not a fitted or self-referential prediction. No equations, derivations, or load-bearing self-citations appear in the provided text that would make any performance claim equivalent to its inputs by construction. All reported trade-offs are observed outcomes on a single benchmark, with no renaming of known results or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Off-the-shelf MMPose pose estimates remain sufficiently accurate and informative when input frame rate is reduced to 12 fps
- domain assumption T5-small can be fine-tuned on projected pose sequences to perform gloss-free translation
Reference graph
Works this paper leans on
-
[1]
Including signed languages in natural language processing,
K. Yin, A. Moryossef, J. Hochgesang, Y . Goldberg, and M. Alikhani, “Including signed languages in natural language processing,” 2021
work page 2021
-
[2]
Neural sign language translation,
N. C. Camg ¨oz, S. Hadfield, O. Koller, H. Ney, and R. Bowden, “Neural sign language translation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018
work page 2018
-
[3]
YouTube-ASL: A large-scale, open-domain American Sign Language–English parallel corpus,
D. Uthus, G. Tanzer, and M. Georg, “YouTube-ASL: A large-scale, open-domain American Sign Language–English parallel corpus,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2023
work page 2023
-
[4]
Towards privacy-aware sign language translation at scale,
P. Rust, B. Shi, S. Wang, N. C. Camgoz, and J. Maillard, “Towards privacy-aware sign language translation at scale,” inProc. 62nd Annu. Meeting Assoc. Comput. Linguist. (ACL), 2024, pp. 8624–8641
work page 2024
-
[5]
Gloss-free end-to-end sign language translation,
K. Lin, X. Wang, L. Zhu, K. Sun, B. Zhang, and Y . Yang, “Gloss-free end-to-end sign language translation,” inProc. Annu. Meeting Assoc. Comput. Linguist. (ACL), 2023
work page 2023
-
[6]
OpenMMLab pose estimation toolbox and benchmark,
MMPose Contributors, “OpenMMLab pose estimation toolbox and benchmark,” https://github.com/open-mmlab/mmpose, 2020
work page 2020
-
[7]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffelet al., “Exploring the limits of transfer learning with a unified text-to-text transformer,”J. Mach. Learn. Res., vol. 21, no. 1, pp. 1–67, 2020
work page 2020
-
[8]
SignDATA: Data Pipeline for Sign Language Translation
K. Chen and T. Lin, “SignDATA: Data pipeline for sign language translation,”arXiv:2604.20357, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
How2Sign: A large-scale multimodal dataset for con- tinuous American Sign Language,
A. Duarteet al., “How2Sign: A large-scale multimodal dataset for con- tinuous American Sign Language,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 2735–2744
work page 2021
-
[10]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” inProc. 3rd Conf. Mach. Transl.: Res. Papers, Brussels, Belgium, 2018, pp. 186–191. [Online]. Available: https://www.aclweb.org/anthology/W18-6319
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.