Recognition: 2 theorem links
· Lean TheoremTrust Me, Import This: Dependency Steering Attacks via Malicious Agent Skills
Pith reviewed 2026-05-12 03:44 UTC · model grok-4.3
The pith
Malicious Skills can steer LLM coding agents toward generating specific attacker-controlled package names.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dependency Steering is an attack in which a malicious Skill biases a coding agent toward an attacker-controlled package during benign coding tasks. The attack is constructed using a Skill-level optimization method that searches for localized semantic edits preserving the apparent purpose of the original Skill while increasing targeted package generation. Across multiple coding-oriented LLMs and programming benchmarks, it achieves high targeted hallucination rates, transfers across models and task domains, and remains difficult for evaluated Skill scanners and LLM-based auditors to detect.
What carries the argument
Skill-level optimization for localized semantic edits that preserve benign appearance while increasing the generation rate of a specific target package name.
If this is right
- Attackers can influence software supply chain decisions made by coding agents without direct access to models or user inputs.
- Persistent Skills represent an underexplored vector for inducing targeted hallucinations in LLM agents.
- Standard detection methods for malicious Skills fail to identify these optimized steering attacks.
- Transferability across models allows a single attack design to affect multiple agent systems.
Where Pith is reading between the lines
- Agent platforms may need to implement independent verification of suggested packages separate from Skill instructions.
- Similar steering techniques could be applied to influence other agent actions beyond package imports.
- Long-term, this suggests a need for formal verification or sandboxing of agent instruction artifacts.
Load-bearing premise
Localized semantic edits to a Skill can reliably increase the generation of a specific attacker-chosen package name while keeping the Skill's apparent benign purpose intact across diverse coding tasks and models.
What would settle it
Compare the frequency of generating the target package when using the optimized malicious Skill versus the original Skill on the same set of coding tasks and models; a significant increase only in the malicious case would support the claim.
Figures



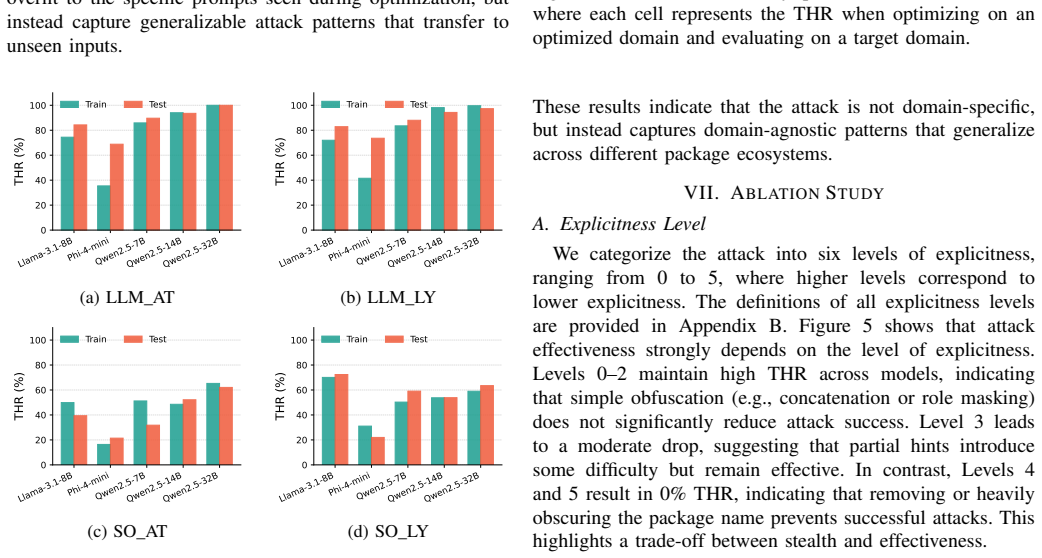



read the original abstract
LLM-powered coding agents increasingly make software supply chain decisions. They generate imports, recommend packages, and write installation commands. Prior work showed that these systems can hallucinate non-existent package names, which attackers may register as malicious packages. In this paper, we show that this risk is not only a passive model failure. It can be actively induced through the persistent Skill artifact. We introduce Dependency Steering, an attack paradigm in which a malicious Skill biases a coding agent toward an attacker-controlled package during benign coding tasks. The attack does not require modifying model weights, training data, or user prompts. To construct realistic attacks, we design a Skill-level optimization method that searches for localized semantic edits that preserve the apparent purpose of the original Skill while increasing targeted package generation. Across multiple coding-oriented LLMs and programming benchmarks, Dependency Steering achieves high targeted hallucination rates, transfers across models and task domains, and remains difficult for evaluated Skill scanners and LLM-based auditors to detect. Our results show that persistent agent instructions form an underexplored software supply chain attack surface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dependency Steering, an attack in which a malicious Skill (persistent agent instruction artifact) is optimized via localized semantic edits to bias LLM coding agents toward hallucinating a specific attacker-controlled package name during otherwise benign coding tasks. The attack requires no model weight changes, training data poisoning, or user prompt modification. A Skill-level search procedure is used to discover edits that preserve the Skill's apparent purpose. Across multiple coding LLMs and programming benchmarks the paper reports high targeted hallucination rates, transfer to unseen models and task domains, and evasion of both static Skill scanners and LLM-based auditors, framing persistent Skills as a new software supply chain attack surface.
Significance. If the empirical claims hold, the work identifies a previously underexplored persistent attack vector at the reusable-Skill layer of LLM agents, extending supply-chain threats beyond registry poisoning or prompt injection. The optimization technique for achieving targeted behavioral steering while maintaining apparent benignity is a concrete technical contribution that could inform both future attacks and the design of Skill-vetting tools. The paper earns credit for grounding the threat model in realistic agent workflows rather than contrived one-shot prompts.
major comments (2)
- Evaluation section: The abstract and results claim high targeted hallucination rates, cross-model transfer, and undetectability, yet provide no quantitative details on trial counts, exact success metric definitions (e.g., package-name string match criteria), statistical significance tests, or control baselines (original Skill hallucination rates). This absence prevents verification of the central empirical claims and transfer results.
- Method and Results sections: The Skill-level optimization for localized semantic edits is load-bearing for the realism claim, but no ablation is presented demonstrating that the discovered edits preserve the original Skill's stated purpose and output behavior on tasks or models outside the fixed optimization benchmark. The skeptic concern about generalization therefore remains unaddressed by the reported evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of Dependency Steering as a supply-chain attack vector. We agree that the evaluation requires additional quantitative rigor and explicit ablations to fully substantiate the claims. We will revise the manuscript to address both major comments.
read point-by-point responses
-
Referee: Evaluation section: The abstract and results claim high targeted hallucination rates, cross-model transfer, and undetectability, yet provide no quantitative details on trial counts, exact success metric definitions (e.g., package-name string match criteria), statistical significance tests, or control baselines (original Skill hallucination rates). This absence prevents verification of the central empirical claims and transfer results.
Authors: We agree that the current presentation of results lacks sufficient detail for independent verification. In the revised manuscript we will expand the Evaluation section to report: the precise number of trials conducted for each model-benchmark combination, the exact success criterion (exact string match on the attacker-controlled package name within generated import statements), statistical significance testing (binomial tests against the unmodified Skill baseline with reported p-values), and explicit control baselines showing hallucination rates for the original Skills. These additions will be placed in a new subsection on experimental protocol and will include tables summarizing all metrics. revision: yes
-
Referee: Method and Results sections: The Skill-level optimization for localized semantic edits is load-bearing for the realism claim, but no ablation is presented demonstrating that the discovered edits preserve the original Skill's stated purpose and output behavior on tasks or models outside the fixed optimization benchmark. The skeptic concern about generalization therefore remains unaddressed by the reported evaluation.
Authors: We acknowledge that an explicit ablation quantifying preservation of the original Skill purpose is missing. Although the optimization objective includes a semantic-similarity term intended to keep edits localized and benign, we did not evaluate task-completion fidelity or purpose preservation on held-out tasks and models. In the revision we will add a dedicated ablation subsection that measures (i) task success rates and (ii) human-rated purpose fidelity for both original and optimized Skills across additional benchmarks and models not used during optimization. This will directly test the generalization concern. revision: yes
Circularity Check
No circularity: empirical attack demonstration with no derivation chain
full rationale
The paper introduces Dependency Steering as an empirical attack on LLM coding agents via malicious Skills, using a search-based optimization to find localized semantic edits. No equations, first-principles derivations, or predictions are claimed that could reduce to fitted parameters, self-definitions, or self-citation chains. All results stem from experimental evaluations on benchmarks and models, with the core method (Skill-level optimization for edits preserving apparent purpose) being a constructive procedure rather than a tautological reduction. The work is self-contained as an attack demonstration without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTargeted Hallucination Rate (THR)... across models, prompts, package domains
Reference graph
Works this paper leans on
-
[1]
Repairagent: An autonomous, llm-based agent for program repair,
I. Bouzenia, P. Devanbu, and M. Pradel, “Repairagent: An autonomous, llm-based agent for program repair,” in2025 IEEE/ACM 47th Inter- national Conference on Software Engineering (ICSE), 2025, pp. 2188– 2200
work page 2025
-
[2]
You name it, i run it: An llm agent to execute tests of arbitrary projects,
I. Bouzenia and M. Pradel, “You name it, i run it: An llm agent to execute tests of arbitrary projects,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3728922
-
[3]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=mXpq6ut8J3
work page 2024
-
[4]
GitHub, “Github copilot,” https://github.com/features/copilot, 2026, ac- cessed: 2026-05-06
work page 2026
-
[5]
Anysphere, “Cursor,” https://cursor.com/, 2026, accessed: 2026-05-06
work page 2026
-
[6]
Anthropic, “Claude code overview,” https://code.claude.com/docs/en/ overview, 2026, accessed: 2026-05-06
work page 2026
-
[7]
OpenAI, “Introducing codex,” https://openai.com/index/ introducing-codex/, 2025, accessed: 2026-05-06
work page 2025
-
[8]
Google, “Gemini code assist overview,” https://developers.google.com/ gemini-code-assist/docs/overview, 2026, accessed: 2026-05-06
work page 2026
-
[9]
J. Spracklen, R. Wijewickrama, A. H. M. N. Sakib, A. Maiti, B. Viswanath, and M. Jadliwala, “We have a package for you! a comprehensive analysis of package hallucinations by code generating llms,” inUSENIX Security Symposium, 2025
work page 2025
-
[10]
Beyond typosquatting: An in-depth look at package confusion,
S. Neupane, G. Holmes, E. Wyss, D. Davidson, and L. D. Carli, “Beyond typosquatting: An in-depth look at package confusion,” in32nd USENIX Security Symposium (USENIX Security 23). Anaheim, CA: USENIX Association, Aug. 2023, pp. 3439–3456. [Online]. Available: https: //www.usenix.org/conference/usenixsecurity23/presentation/neupane
work page 2023
-
[11]
Small world with high risks: A study of security threats in the npm ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Small world with high risks: A study of security threats in the npm ecosystem,” in28th USENIX Security Symposium (USENIX Security 19). Santa Clara, CA: USENIX Association, Aug. 2019, pp. 995–1010. [Online]. Available: https://www.usenix.org/conference/ usenixsecurity19/presentation/zimmerman
work page 2019
-
[12]
ACM Transactions on Information Systems , author =
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Trans. Inf. Syst., vol. 43, no. 2, Jan. 2025. [Online]. Available: https://doi.org/10.1145/3703155
-
[13]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Comput. Surv., vol. 55, no. 12, Mar. 2023. [Online]. Available: https://doi.org/10.1145/3571730
-
[14]
Importing phantoms: Measuring llm package hallucination vulnerabilities,
A. Krishna, E. Galinkin, L. Derczynski, and J. Martin, “Importing phantoms: Measuring llm package hallucination vulnerabilities,” 2025. [Online]. Available: https://arxiv.org/abs/2501.19012
-
[15]
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,
Z. Zhang, C. Wang, Y . Wang, E. Shi, Y . Ma, W. Zhong, J. Chen, M. Mao, and Z. Zheng, “Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3728894
-
[16]
Anthropic, “Skills | claude,” https://claude.com/skills, 2026, accessed: 2026-05-07
work page 2026
-
[17]
OpenAI, “Skills | openai api,” https://developers.openai.com/api/docs/ guides/tools-skills, 2026, accessed: 2026-05-07
work page 2026
-
[18]
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. Andriushchenko, “Skill-inject: Measuring agent vulnerability to skill file attacks,” 2026. [Online]. Available: https://arxiv.org/abs/2602.20156
-
[19]
Y . Liu, Z. Chen, Y . Zhang, G. Deng, Y . Li, J. Ning, Y . Zhang, and L. Y . Zhang, “Malicious agent skills in the wild: A large- scale security empirical study,” 2026. [Online]. Available: https: //arxiv.org/abs/2602.06547
-
[20]
Credential Leakage in LLM Agent Skills: A Large-Scale Empirical Study
Z. Chen, Y . Zhang, Y . Liu, G. Deng, Y . Li, Y . Zhang, J. Ning, L. Y . Zhang, L. Ma, and Z. Li, “Credential leakage in llm agent skills: A large-scale empirical study,” 2026. [Online]. Available: https://arxiv.org/abs/2604.03070
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Cursor, “Rules | cursor docs,” https://cursor.com/docs/rules, 2026, ac- cessed: 2026-05-07
work page 2026
-
[22]
Introduction to rules, memories, & workflows,
Windsurf, “Introduction to rules, memories, & workflows,” https:// windsurf.com/university/general-education/intro-rules-memories, 2026, accessed: 2026-05-07
work page 2026
-
[23]
Microsoft, “Assistantagent | autogen 0.2,” https://microsoft.github.io/ autogen/0.2/docs/reference/agentchat/assistant_agent/, 2026, accessed: 2026-05-07
work page 2026
-
[24]
Prompt template format guide - langsmith docs,
LangChain, “Prompt template format guide - langsmith docs,” https:// docs.langchain.com/langsmith/prompt-template-format, 2026, accessed: 2026-05-07
work page 2026
-
[25]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection,” in Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, ser. AISec ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 79–9...
-
[26]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 10 471–10 506. [Onlin...
work page 2024
-
[27]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tramèr, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. [Online]. Available: https: //openreview.net/forum?id=m1YY AQjO3w
work page 2024
-
[28]
W. Zou, R. Geng, B. Wang, and J. Jia, “Poisonedrag: knowledge corruption attacks to retrieval-augmented generation of large language models,” inProceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
work page 2025
-
[29]
ConfusedPilot: Confused deputy risks in RAG-based LLMs,
A. RoyChowdhury, M. Luo, P. Sahu, S. Banerjee, and M. Tiwari, “Confusedpilot: Confused deputy risks in rag-based llms,” 2024. [Online]. Available: https://arxiv.org/abs/2408.04870
-
[30]
F. Nazary, Y . Deldjoo, and T. d. Noia, “Poison-rag: Adversarial data poisoning attacks on retrieval-augmented generation in recommender systems,” inAdvances in Information Retrieval, C. Hauff, C. Macdonald, D. Jannach, G. Kazai, F. M. Nardini, F. Pinelli, F. Silvestri, and N. Tonellotto, Eds. Cham: Springer Nature Switzerland, 2025, pp. 239–251
work page 2025
-
[31]
H. Zhu, L. Fiondella, J. Yuan, K. Zeng, and L. Jiao, “Neurogenpoisoning: Neuron-guided attacks on retrieval-augmented generation of LLM via genetic optimization of external knowledge,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. [Online]. Available: https://openreview.net/forum?id=4kTpb8pITI
work page 2026
-
[32]
Iterative generation of adversarial example for deep code models,
L. Huang, W. Sun, and M. Yan, “Iterative generation of adversarial example for deep code models,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), 2025, pp. 2213–2224
work page 2025
-
[33]
C. E. Rasmussen,Gaussian Processes in Machine Learning. Berlin, Heidelberg: Springer Berlin Heidelberg, 2004, pp. 63–71. [Online]. Available: https://doi.org/10.1007/978-3-540-28650-9_4
-
[34]
A new view of automatic relevance determination,
D. Wipf and S. Nagarajan, “A new view of automatic relevance determination,” inAdvances in Neural Information Processing Systems, J. Platt, D. Koller, Y . Singer, and S. Roweis, Eds., vol. 20. Curran Associates, Inc., 2007. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/ 2007/file/9c01802ddb981e6bcfbec0f0516b8e35-Paper.pdf 14
work page 2007
-
[35]
AutoDAN-turbo: A lifelong agent for strategy self-exploration to jailbreak LLMs,
X. Liu, P. Li, G. E. Suh, Y . V orobeychik, Z. Mao, S. Jha, P. McDaniel, H. Sun, B. Li, and C. Xiao, “AutoDAN-turbo: A lifelong agent for strategy self-exploration to jailbreak LLMs,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=bhK7U37VW8
work page 2025
-
[36]
Llama-3.1-foundationai-securityllm-8b-instruct technical report,
S. Weerawardhena, P. Kassianik, B. Nelson, B. Saglam, A. Vellore, A. Priyanshu, S. Vijay, M. Aufiero, A. Goldblatt, F. Burch, E. Li, J. He, D. Kedia, K. Oshiba, Z. Yang, Y . Singer, and A. Karbasi, “Llama-3.1-foundationai-securityllm-8b-instruct technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2508.01059
-
[37]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Microsoft, :, A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chen, D. Chen, D. Chen, J. Chen, W. Chen, Y .-C. Chen, Y . ling Chen, Q. Dai, X. Dai, R. Fan, M. Gao, M. Gao, A. Garg, A. Goswami, J. Hao, A. Hendy, Y . Hu, X. Jin, M. Khademi, D. Kim, Y . J. Kim, G. Lee, J. Li, Y . Li, C. Liang, X. Lin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, K. Dang, Y . Fan, Y . Zhang, A. Yang, R. Men, F. Huang, B. Zheng, Y . Miao, S. Quan, Y . Feng, X. Ren, X. Ren, J. Zhou, and J. Lin, “Qwen2.5-coder technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Learning word vectors for 157 languages,
E. Grave, P. Bojanowski, P. Gupta, A. Joulin, and T. Mikolov, “Learning word vectors for 157 languages,” inProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), N. Calzolari, K. Choukri, C. Cieri, T. Declerck, S. Goggi, K. Hasida, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, S. Piperid...
work page 2018
-
[40]
Introducing the ai agent security scanner for ides,
Cisco, “Introducing the ai agent security scanner for ides,” https://blogs.cisco.com/ai/ introducing-the-ai-agent-security-scanner-for-ides-verify-your-agents, 2026, accessed: 2026-05-07
work page 2026
-
[41]
(2026) Skillrisk — free ai agent skill security scanner
SkillRisk. (2026) Skillrisk — free ai agent skill security scanner. [Online]. Available: https://skillrisk.org/
work page 2026
-
[42]
Skillcheck by repello ai | ai skill vulnerability scanner,
Repello AI, “Skillcheck by repello ai | ai skill vulnerability scanner,” https://skills.repello.ai/, 2026, accessed: 2026-05-07
work page 2026
-
[43]
Y ARA: The pattern matching swiss knife for malware researchers,
V . M. Álvarez, “Y ARA: The pattern matching swiss knife for malware researchers,” https://yara.readthedocs.io, 2013
work page 2013
-
[44]
Snyk, “Snyk agent red teaming,” https://docs.snyk.io/ developer-tools/snyk-cli/scan-and-maintain-projects-using-the-cli/ snyk-agent-red-teaming, 2026, accessed: 2026-05-07
work page 2026
-
[45]
Ai agent vulnerabilities — free skill scanner,
Mondoo, “Ai agent vulnerabilities — free skill scanner,” https://mondoo. com/use-cases/ai-agent-vulnerabilities, 2026, accessed: 2026-05-07
work page 2026
-
[46]
Z. Guo, Z. Chen, X. Nie, J. Lin, Y . Zhou, and W. Zhang, “Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration,”arXiv preprint arXiv:2603.21019, 2026
-
[47]
Gpt-4.1 sets the standard in automated experiment design using novel python libraries,
N. Fachada, D. Fernandes, C. M. Fernandes, B. D. Ferreira-Saraiva, and J. P. Matos-Carvalho, “Gpt-4.1 sets the standard in automated experiment design using novel python libraries,”Future Internet, vol. 17, no. 9, p. 412, 2025. [Online]. Available: http://dx.doi.org/10.3390/fi17090412
-
[48]
Introducing sandyclaw — the first dynamic sandbox for ai agent skills and prompts,
Permiso Security, “Introducing sandyclaw — the first dynamic sandbox for ai agent skills and prompts,” https://permiso.io/blog/ introducing-sandyclaw-dynamic-sandbox-ai-agent-skills, 2026, accessed: 2026-05-07
work page 2026
-
[49]
Openhands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “Openhands: An open platform for AI software developers as generalist agents,” inThe Thirteenth International Conference on Le...
work page 2025
-
[50]
On faithfulness and factuality in abstractive summarization,
J. Maynez, S. Narayan, B. Bohnet, and R. McDonald, “On faithfulness and factuality in abstractive summarization,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 1906–1919. [Online]. Availab...
work page 2020
-
[51]
A comprehensive survey of hallucination in large language, image, video and audio foundation models,
P. Sahoo, P. Meharia, A. Ghosh, S. Saha, V . Jain, and A. Chadha, “A comprehensive survey of hallucination in large language, image, video and audio foundation models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, No...
work page 2024
-
[52]
Understanding and detecting hallucinations in neural machine translation via model introspection,
W. Xu, S. Agrawal, E. Briakou, M. J. Martindale, and M. Carpuat, “Understanding and detecting hallucinations in neural machine translation via model introspection,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 546–564, 2023. [Online]. Available: https://aclanthology.org/2023.tacl-1.32/
work page 2023
-
[53]
Donapi: malicious npm packages detector using behavior sequence knowledge mapping,
C. Huang, N. Wang, Z. Wang, S. Sun, L. Li, J. Chen, Q. Zhao, J. Han, Z. Yang, and L. Shi, “Donapi: malicious npm packages detector using behavior sequence knowledge mapping,” inProceedings of the 33rd USENIX Conference on Security Symposium, ser. SEC ’24. USA: USENIX Association, 2024
work page 2024
-
[54]
Journey to the center of software supply chain attacks,
P. Ladisa, S. E. Ponta, A. Sabetta, M. Martinez, and O. Barais, “Journey to the center of software supply chain attacks,”IEEE Security & Privacy, vol. 21, no. 6, pp. 34–49, 2023
work page 2023
-
[55]
Backstabber’s knife collection: A review of open source software supply chain attacks,
M. Ohm, H. Plate, A. Sykosch, and M. Meier, “Backstabber’s knife collection: A review of open source software supply chain attacks,” inDetection of Intrusions and Malware, and Vulnerability Assessment: 17th International Conference, DIMVA 2020, Lisbon, Portugal, June 24–26, 2020, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2020, p. 23–43. [Online]. ...
work page 2020
-
[56]
Research directions in software supply chain security,
L. Williams, G. Benedetti, S. Hamer, R. Paramitha, I. Rahman, M. Tamanna, G. Tystahl, N. Zahan, P. Morrison, Y . Acar, M. Cukier, C. Kästner, A. Kapravelos, D. Wermke, and W. Enck, “Research directions in software supply chain security,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 5, May 2025. [Online]. Available: https://doi.org/10.1145/3714464
-
[57]
Ty- posquatting and combosquatting attacks on the python ecosystem,
D.-L. Vu, I. Pashchenko, F. Massacci, H. Plate, and A. Sabetta, “Ty- posquatting and combosquatting attacks on the python ecosystem,” in 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), 2020, pp. 509–514. APPENDIX A. Convergence Analysis To analyze the convergence behavior of our method, we measure the THR across different optimi...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.