Recognition: 2 theorem links
· Lean TheoremReflection Anchors for Propagation-Aware Visual Retention in Long-Chain Multimodal Reasoning
Pith reviewed 2026-05-12 02:19 UTC · model grok-4.3
The pith
Deriving a lower bound on visual gain from interventions allows RAPO to select reflection anchors that enhance visual retention during long-chain multimodal reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We study this problem from an information-theoretic standpoint and derive a lower bound on the downstream visual gain of a one-step intervention, which suggests two factors: local branching room (token entropy) and downstream visual propagation potential (suffix divergence from a vision-marginalized reference). Guided by this analysis, we propose reflection-anchor policy optimization (RAPO), a GRPO-based policy optimization method that selects high-entropy reflection anchors and optimizes a chain-masked finite-window KL surrogate for downstream visual dependence.
What carries the argument
Reflection anchors chosen at high-entropy tokens combined with GRPO optimization of a chain-masked finite-window KL surrogate to increase downstream visual dependence.
If this is right
- RAPO achieves substantial performance gains over strong baselines on reasoning-intensive and general-domain benchmarks.
- The improvements apply across multiple LVLM backbones.
- Selected reflection anchors concentrate on visually sensitive decision points.
- RAPO strengthens contrastive visual-dependence signals throughout the generated reasoning trajectories.
Where Pith is reading between the lines
- Similar propagation-aware selection could extend to other policy optimization methods or even inference-time interventions.
- Future work might derive tighter bounds or extend the finite-window surrogate to full trajectories if computation allows.
- This framework could inform the design of new loss functions that explicitly reward visual propagation in autoregressive models.
Load-bearing premise
That optimizing the chain-masked finite-window KL surrogate reliably increases the actual downstream visual dependence predicted by the lower bound instead of a mismatched proxy.
What would settle it
Running the optimization and then measuring that visual dependence or suffix divergence shows no increase relative to baselines would indicate the surrogate does not achieve the intended effect.
Figures





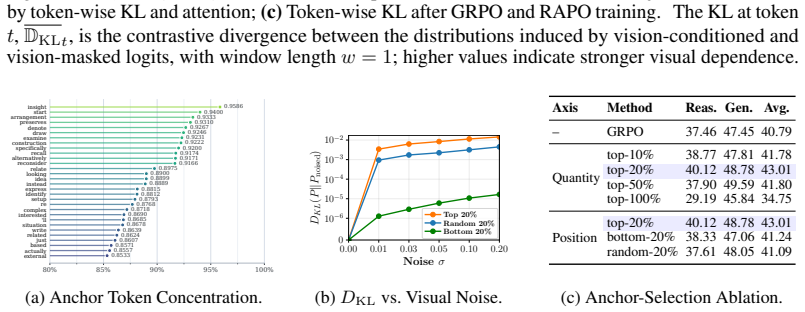





read the original abstract
Long chain-of-thought (CoT) reasoning improves large vision--language models, but visual information often fades during generation, limiting long-horizon multimodal reasoning. Existing methods either re-inject vision at inference or train policies for stronger grounding, but where to intervene relies on perception heuristics rather than principled gain analysis, and how local visual influence propagates remains implicit. We study this problem from an information-theoretic standpoint and derive a lower bound on the downstream visual gain of a one-step intervention, which suggests two factors: local branching room (token entropy) and downstream visual propagation potential (suffix divergence from a vision-marginalized reference). Guided by this analysis, we propose reflection-anchor policy optimization (RAPO), a GRPO-based policy optimization method that selects high-entropy reflection anchors and optimizes a chain-masked finite-window KL surrogate for downstream visual dependence. Experiments on reasoning-intensive and general-domain benchmarks show that RAPO delivers substantial gains over strong baselines across multiple LVLM backbones. Mechanism analyses further indicate that reflection anchors are enriched for visually sensitive decision points and that RAPO increases contrastive visual-dependence signals along generated trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives an information-theoretic lower bound on downstream visual gain from one-step interventions in long CoT trajectories for LVLMs, depending on local token entropy and suffix divergence from a vision-marginalized reference. Guided by this, it introduces reflection-anchor policy optimization (RAPO), a GRPO method that selects high-entropy anchors and optimizes a chain-masked finite-window KL surrogate to promote visual dependence. Experiments report substantial gains over baselines across reasoning and general benchmarks on multiple LVLM backbones, with mechanism analyses indicating that anchors are enriched for visually sensitive points and that RAPO increases contrastive visual-dependence signals.
Significance. If the central claim holds, the work supplies a principled, propagation-aware framework for visual retention in extended multimodal reasoning, shifting from heuristic re-injection or grounding policies to an entropy-plus-divergence analysis. The explicit lower-bound derivation and the accompanying mechanism analyses constitute clear strengths, offering both theoretical motivation and post-hoc interpretability that could inform future intervention strategies.
major comments (2)
- [§3 and §4.1] §3 (lower-bound derivation) and §4.1 (GRPO objective): The lower bound is stated in terms of full-suffix divergence from the vision-marginalized reference, yet the optimized surrogate is a chain-masked finite-window KL. No theorem, lemma, or ablation demonstrates that reductions in this local surrogate necessarily enlarge the suffix-divergence term once masking severs long-range dependencies and the window is finite; if the surrogate can be minimized while the actual propagation potential remains flat, the information-theoretic justification for RAPO is undermined.
- [§5] §5 (experimental results): The reported gains are described as “substantial” but the text provides neither quantitative effect sizes, baseline hyper-parameter details, statistical significance tests, nor direct verification that the lower-bound quantities (entropy and suffix divergence) increase along the optimized trajectories. Without these, it is impossible to confirm that the observed improvements are attributable to the derived mechanism rather than to generic policy optimization or post-hoc anchor selection.
minor comments (2)
- [§4.2] The finite-window size and entropy threshold are treated as free parameters; a sensitivity analysis or default-value justification would improve reproducibility.
- [§4.1] Notation for the chain-masked KL surrogate and the vision-marginalized reference distribution should be introduced with explicit equations rather than descriptive prose.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address the major concerns point by point below, providing clarifications on the theoretical surrogate and committing to enhanced experimental reporting in the revision.
read point-by-point responses
-
Referee: [§3 and §4.1] §3 (lower-bound derivation) and §4.1 (GRPO objective): The lower bound is stated in terms of full-suffix divergence from the vision-marginalized reference, yet the optimized surrogate is a chain-masked finite-window KL. No theorem, lemma, or ablation demonstrates that reductions in this local surrogate necessarily enlarge the suffix-divergence term once masking severs long-range dependencies and the window is finite; if the surrogate can be minimized while the actual propagation potential remains flat, the information-theoretic justification for RAPO is undermined.
Authors: The chain-masked finite-window KL surrogate is introduced as a computationally tractable proxy that targets the local propagation of visual information within the reasoning chain, with masking ensuring that the optimization focuses on causal dependencies up to the current point rather than future tokens. While we recognize that a direct theorem linking surrogate minimization to full suffix-divergence enlargement under finite windows is not provided in the current manuscript, the design is grounded in the lower-bound factors of entropy and divergence. To address this, we will add a supporting lemma in the revision that bounds the approximation error under mild assumptions on the model’s attention decay, and include an ablation that tracks how surrogate values correlate with measured suffix divergence on sample trajectories. This will strengthen the connection between the optimization objective and the theoretical motivation. revision: yes
-
Referee: [§5] §5 (experimental results): The reported gains are described as “substantial” but the text provides neither quantitative effect sizes, baseline hyper-parameter details, statistical significance tests, nor direct verification that the lower-bound quantities (entropy and suffix divergence) increase along the optimized trajectories. Without these, it is impossible to confirm that the observed improvements are attributable to the derived mechanism rather than to generic policy optimization or post-hoc anchor selection.
Authors: We agree that more rigorous reporting is necessary to substantiate the claims. In the revised version, we will expand §5 to include: (i) quantitative effect sizes with means and standard deviations across multiple runs, (ii) complete hyper-parameter settings for RAPO and all baselines, (iii) statistical significance tests (e.g., t-tests with p-values) comparing RAPO to baselines, and (iv) explicit measurements of the key quantities from the lower bound—average anchor entropy and suffix divergence—before and after optimization, demonstrating increases consistent with the mechanism. These additions will help isolate the contribution of the information-theoretic guidance from generic optimization effects. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from first principles
full rationale
The paper derives a lower bound on downstream visual gain from information-theoretic first principles (local token entropy and suffix divergence from a vision-marginalized reference). This bound is used only to motivate anchor selection and the choice of a finite-window KL surrogate inside GRPO; the surrogate is explicitly an approximation, not a direct re-expression or fit of the bound itself. No equations reduce the claimed result to its inputs by construction, no self-citations are load-bearing for the central premise, and no renaming of known results occurs. The method remains an independent optimization choice guided by (but not equivalent to) the derived bound.
Axiom & Free-Parameter Ledger
free parameters (2)
- finite window size for KL surrogate
- entropy threshold for anchor selection
axioms (2)
- domain assumption The derived lower bound on downstream visual gain is a useful predictor of actual intervention benefit in generated trajectories.
- ad hoc to paper The chain-masked finite-window KL surrogate is a faithful proxy for the full suffix visual dependence.
invented entities (1)
-
reflection anchors
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearderive a lower bound on the downstream visual gain ... local branching room (token entropy) and downstream visual propagation potential (suffix divergence ...)
Reference graph
Works this paper leans on
-
[1]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URLhttps://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Large language models are zero-shot reasoners, 2023
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners, 2023. URL https://arxiv.org/abs/2205. 11916
work page 2023
-
[3]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[4]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Haotian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, Huabi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, and Wenqi Shao. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning, 2025. URL https://arxiv.org/abs/ 2503.07365
work page Pith review arXiv 2025
-
[10]
Wenyan Li, Raphael Tang, Chengzu Li, Caiqi Zhang, Ivan Vulic, and Anders Søgaard. Lost in embeddings: Information loss in vision-language models.arXiv preprint arXiv:2509.11986, 2, 2025
-
[11]
Hai-Long Sun, Zhun Sun, Houwen Peng, and Han-Jia Ye. Mitigating visual forgetting via take- along visual conditioning for multi-modal long cot reasoning.arXiv preprint arXiv:2503.13360, 2025. 11
-
[12]
Ahmed Masry, Juan A. Rodriguez, Tianyu Zhang, Suyuchen Wang, Chao Wang, Aarash Feizi, Akshay Kalkunte Suresh, Abhay Puri, Xiangru Jian, Pierre-André Noël, Sathwik Tejaswi Madhusudhan, Marco Pedersoli, Bang Liu, Nicolas Chapados, Yoshua Bengio, Enamul Hoque, Christopher Pal, Issam H. Laradji, David Vazquez, Perouz Taslakian, Spandana Gella, and Sai Rajeswa...
-
[13]
Look again, think slowly: Enhancing visual reflection in vision-language models
Pu Jian, Junhong Wu, Wei Sun, Chen Wang, Shuo Ren, and Jiajun Zhang. Look again, think slowly: Enhancing visual reflection in vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9262–9281, 2025
work page 2025
-
[14]
arXiv preprint arXiv:2505.23558 , year=
Xu Chu, Xinrong Chen, Guanyu Wang, Zhijie Tan, Kui Huang, Wenyu Lv, Tong Mo, and Weiping Li. Qwen look again: Guiding vision-language reasoning models to re-attention visual information.arXiv preprint arXiv:2505.23558, 2025
-
[15]
MINT-cot: Enabling interleaved visual tokens in mathematical chain-of-thought reasoning
Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, and Hongsheng Li. MINT-cot: Enabling interleaved visual tokens in mathematical chain-of-thought reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[16]
URLhttps://openreview.net/forum?id=vMpvtSmtXY
-
[17]
Interleaved-modal chain-of-thought
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19520–19529, 2025
work page 2025
-
[18]
v1: Learning to Point Visual Tokens for Multimodal Grounded Reasoning
Jiwan Chung, Junhyeok Kim, Siyeol Kim, Jaeyoung Lee, Min Soo Kim, and Youngjae Yu. v1: Learning to point visual tokens for multimodal grounded reasoning, 2025. URL https: //arxiv.org/abs/2505.18842
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Yiming Qin, Bomin Wei, Jiaxin Ge, Konstantinos Kallidromitis, Stephanie Fu, Trevor Darrell, and XuDong Wang. Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens.arXiv preprint arXiv:2511.19418, 2025
-
[20]
Visual thoughts: A unified per- spective of understanding multimodal chain-of-thought
Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi WANG, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, and Libo Qin. Visual thoughts: A unified per- spective of understanding multimodal chain-of-thought. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum? id=xPcKmKSEis
work page 2026
-
[21]
Latent chain-of-thought for visual reasoning, 2025
Guohao Sun, Hang Hua, Jian Wang, Jiebo Luo, Sohail Dianat, Majid Rabbani, Raghuveer Rao, and Zhiqiang Tao. Latent chain-of-thought for visual reasoning, 2025. URL https: //arxiv.org/abs/2510.23925
-
[22]
Perception-Aware Policy Optimization for Multimodal Reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, and Heng Ji. Perception-aware policy optimization for multimodal reasoning, 2025. URL https://arxiv.org/abs/2507.06448
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Spotlight on token perception for multimodal reinforcement learning, 2025
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning, 2025. URL https://arxiv.org/ abs/2510.09285
-
[24]
Rethinking token-level policy optimization for multimodal chain-of-thought,
Yunheng Li, Hangyi Kuang, Hengrui Zhang, Jiangxia Cao, Zhaojie Liu, Qibin Hou, and Ming- Ming Cheng. Rethinking token-level policy optimization for multimodal chain-of-thought,
- [25]
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page 2025
-
[28]
Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning,
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning,
- [29]
-
[30]
Zhongwei Wan, Zhihao Dou, Che Liu, Yu Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Yi Xin, Yifan Jiang, et al. Srpo: Enhancing multimodal llm reasoning via reflection- aware reinforcement learning.arXiv preprint arXiv:2506.01713, 2025
-
[31]
Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, et al. Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search.arXiv preprint arXiv:2412.18319, 2024
-
[32]
Yizhen Zhang, Yang Ding, Shuoshuo Zhang, Xinchen Zhang, Haoling Li, Zhong-zhi Li, Peijie Wang, Jie Wu, Lei Ji, Yelong Shen, et al. Perl: Permutation-enhanced reinforcement learning for interleaved vision-language reasoning.arXiv preprint arXiv:2506.14907, 2025
-
[33]
More thought, less accuracy? on the dual nature of rea- soning in vision-language models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Mengqi He, Fabian Waschkowski, Lukas Wesemann, Peter Henry Tu, and Jing Zhang. More thought, less accuracy? on the dual nature of rea- soning in vision-language models. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=XpL5eqjCjF
work page 2026
-
[34]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024. URLhttps://arxiv.org/ abs/2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[36]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2505.16673 (2025)
Huanjin Yao, Qixiang Yin, Jingyi Zhang, Min Yang, Yibo Wang, Wenhao Wu, Fei Su, Li Shen, Minghui Qiu, Dacheng Tao, and Jiaxing Huang. R1-sharevl: Incentivizing reasoning capability of multimodal large language models via share-grpo, 2025. URL https://arxiv.org/abs/ 2505.16673
-
[38]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[39]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
-
[40]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, and Hongsheng Li. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?, 2024. URL https://arxiv.org/abs/ 2403.14624
-
[41]
Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark
Yunzhuo Hao, Jiawei Gu, Huichen Will Wang, Linjie Li, Zhengyuan Yang, Lijuan Wang, and Yu Cheng. Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark, 2025. URLhttps://arxiv.org/abs/2501.05444
-
[42]
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts, 2024. URL https://arxiv.org/abs/2407.04973. 13
-
[43]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark, 2025. URL https: //arxiv.org/abs/2409.02813
work page internal anchor Pith review arXiv 2025
-
[44]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.