Recognition: no theorem link
Any2Any 3D Diffusion Models with Knowledge Transfer: A Radiotherapy Planning Study
Pith reviewed 2026-05-12 04:47 UTC · model grok-4.3
The pith
Transferring priors from video diffusion models via modality-aware conditioning and reinforcement learning improves 3D dose prediction accuracy for radiotherapy planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiffKT3D is a unified Any2Any 3D diffusion model that transfers generative priors from video diffusion models through modality-specific embeddings for conditioning on CT, structures, body, and beam data, followed by reinforcement learning post-training aligned to a clinical Scorecard; this combination reduces voxel-level mean absolute error from 2.07 to 1.93 while producing dose maps that better match institutional preferences and visual quality standards.
What carries the argument
DiffKT3D framework, which performs knowledge transfer from pretrained video diffusion models using modality-aware embeddings for flexible Any2Any conditioning and applies reinforcement learning guided by a clinically-informed Scorecard to refine outputs.
If this is right
- Voxel-wise dose prediction error drops from 2.07 to 1.93 mean absolute error on the evaluated benchmark.
- Generated dose maps show higher image quality and closer alignment with institutional treatment preferences.
- The same model handles conditioning on any combination of CT, anatomical structures, body outlines, and beam settings without cross-attention overhead.
- Clinically aligned RL post-training produces outputs that generalize across diverse radiotherapy scenarios rather than overfitting to one site.
- The approach supplies a single trainable pipeline that replaces multiple task-specific models for different clinical modalities.
Where Pith is reading between the lines
- Hospitals could retrain only the RL stage on their own Scorecard to adapt the model without repeating the full diffusion pretraining.
- The same transfer pattern might extend to other 3D medical generation tasks such as synthetic CT or organ segmentation where large natural-data priors exist.
- Integration into commercial treatment planning software could shorten planning time by providing higher-quality starting dose maps for physician review.
- If the domain gap proves larger than expected, targeted medical pretraining on CT volumes before the RL stage could be tested as a lightweight fix.
Load-bearing premise
The assumption that statistical patterns learned from natural video scenes can transfer to three-dimensional medical dose distributions without large domain gaps that would require heavy retraining.
What would settle it
Running the model on a new multi-center test set where the voxel MAE remains above 2.0 or where blinded clinical reviewers consistently prefer the GDP-HMM winner over DiffKT3D outputs.
Figures



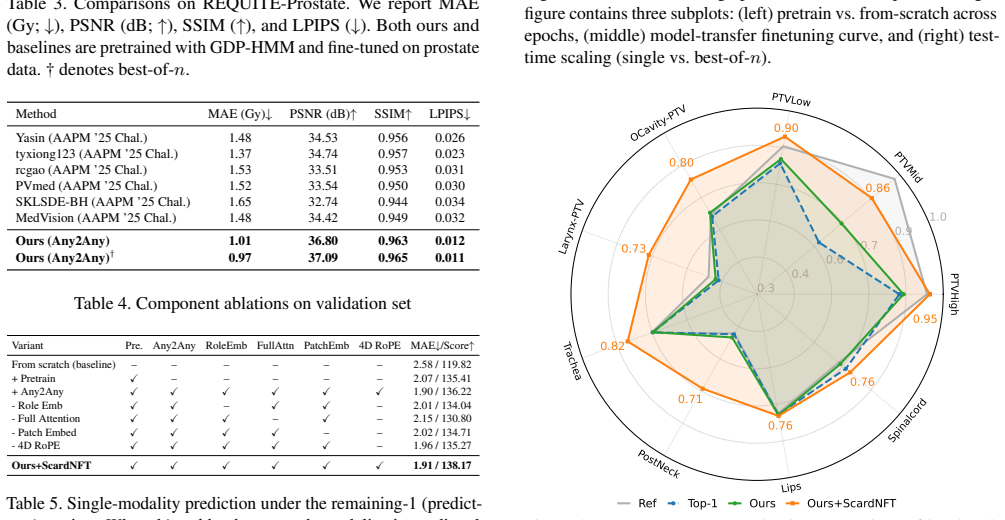



read the original abstract
Voxel-wise dose prediction is a critical yet challenging task in practical radiotherapy (RT) planning, as bespoke models trained from scratch often struggle to generalize across diverse clinical settings. Meanwhile, generative models trained on billion-scale datasets from vision domains have achieved impressive performance. Herein, we propose DiffKT3D, a unified Any2Any 3D diffusion framework that leverages prior knowledge from pretrained video diffusion models for efficient and clinically meaningful dose prediction. To enable flexible conditioning across multiple clinical modalities (CT, anatomical structures, body, beam settings, etc.), we introduce an Any2Any conditional paradigm utilizing modality-specific embeddings without cross-attention overhead. Further, we design a novel reinforcement learning (RL) post-training mechanism guided by a clinically-informed Scorecard explicitly tailored to institutional treatment preferences. Compared with winner of GDP-HMM challenge, DiffKT3D sets a new state-of-the-art in dose prediction by reducing voxel-level MAE from 2.07 to 1.93. In addition, DiffKT3D achieves superior image quality and preference match. These results demonstrate that transferring diffusion priors via modality-aware conditioning and clinically aligned RL post-training can provide a robust and generalizable solution for RT planning across various clinical scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiffKT3D, a unified Any2Any 3D diffusion framework for voxel-wise dose prediction in radiotherapy planning. It transfers priors from pretrained video diffusion models via modality-specific embeddings for flexible conditioning on inputs such as CT, anatomical structures, body, and beam settings, without cross-attention overhead. A reinforcement learning post-training step is guided by a clinically-informed Scorecard tailored to institutional preferences. The central empirical claim is that this yields a new state-of-the-art, reducing voxel-level MAE from 2.07 to 1.93 versus the GDP-HMM challenge winner, while also improving image quality and preference match.
Significance. If the claims hold after addressing the gaps below, the work would demonstrate a viable path for leveraging billion-scale vision priors in constrained 3D medical tasks, potentially improving generalization across clinical scenarios where bespoke models fail. The Any2Any conditioning and RL alignment with clinical scorecards are conceptually interesting extensions. However, the current manuscript provides no evidence isolating the contribution of the video priors, no error bars or statistical tests on the MAE gain, and insufficient experimental details, so the significance cannot yet be assessed.
major comments (3)
- [Abstract] Abstract: The claim that the 2.07→1.93 MAE reduction results from transferring diffusion priors via the Any2Any paradigm is unsupported. No ablation is reported that compares the full DiffKT3D against an otherwise identical 3D diffusion architecture trained from scratch (or randomly initialized) on the same radiotherapy data with the same conditioning scheme. Without this, the gain could equally be attributed to the new conditioning or the RL step alone.
- [Abstract] Abstract and Methods (RL post-training): The RL post-training uses a Scorecard explicitly tailored to institutional treatment preferences. This introduces a circularity risk: if the scorecard weights or metrics were selected or tuned with knowledge of the model's outputs, the reported 'preference match' and any associated MAE improvement become partly tautological rather than an independent clinical validation.
- [Abstract] Abstract: The SOTA claim is presented without error bars, cross-validation details, data-split descriptions, or baseline re-implementation specifics. Post-hoc comparison to a single challenge winner risks selection bias and prevents assessment of whether the 0.14 MAE drop is statistically meaningful or reproducible.
minor comments (1)
- [Abstract] Abstract: The statements 'superior image quality and preference match' are not accompanied by the specific quantitative metrics (e.g., SSIM, PSNR, or clinical scoring protocol) used to establish superiority.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging where revisions are needed to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the 2.07→1.93 MAE reduction results from transferring diffusion priors via the Any2Any paradigm is unsupported. No ablation is reported that compares the full DiffKT3D against an otherwise identical 3D diffusion architecture trained from scratch (or randomly initialized) on the same radiotherapy data with the same conditioning scheme. Without this, the gain could equally be attributed to the new conditioning or the RL step alone.
Authors: We agree that an ablation isolating the contribution of the transferred video priors is required to substantiate the central claim. The current manuscript does not contain this comparison. In the revised version we will add an experiment training an otherwise identical 3D diffusion model from random initialization on the same radiotherapy data using the identical Any2Any conditioning scheme and RL post-training, and report the resulting MAE to quantify the benefit attributable to the video priors. revision: yes
-
Referee: [Abstract] Abstract and Methods (RL post-training): The RL post-training uses a Scorecard explicitly tailored to institutional treatment preferences. This introduces a circularity risk: if the scorecard weights or metrics were selected or tuned with knowledge of the model's outputs, the reported 'preference match' and any associated MAE improvement become partly tautological rather than an independent clinical validation.
Authors: The Scorecard is derived from established institutional clinical guidelines and standard radiotherapy metrics that were defined prior to model development. To mitigate the circularity concern we will expand the Methods section with a precise description of the metrics, fixed weights, and the independent process used to construct the Scorecard. This will demonstrate that the RL objective targets pre-specified clinical criteria rather than being tuned to the reported model outputs. revision: partial
-
Referee: [Abstract] Abstract: The SOTA claim is presented without error bars, cross-validation details, data-split descriptions, or baseline re-implementation specifics. Post-hoc comparison to a single challenge winner risks selection bias and prevents assessment of whether the 0.14 MAE drop is statistically meaningful or reproducible.
Authors: We acknowledge that the SOTA claim requires stronger statistical support and transparency. In the revision we will report error bars from repeated runs or cross-validation, provide full details of the data splits, include statistical tests (e.g., paired t-test) for the MAE difference, and clarify the exact procedure used for the GDP-HMM baseline comparison, including whether reported values or re-implementations were employed. revision: yes
Circularity Check
No significant circularity; claims rest on empirical comparisons without self-referential reduction
full rationale
The paper describes DiffKT3D as combining pretrained video diffusion priors, Any2Any modality-specific embeddings, and RL post-training guided by an institutional Scorecard. Performance is reported via direct comparison to the GDP-HMM challenge winner (MAE 2.07 to 1.93) plus qualitative image quality and preference match. No equations, self-citations, or ansatzes are present in the provided text that would make any claimed prediction equivalent to its inputs by construction. The RL Scorecard is described as clinically-informed and tailored to preferences rather than fitted to the model's outputs; without a quoted reduction showing the evaluation metric is identical to the training reward in a tautological way, the strict criteria for circularity are not met. The derivation chain is therefore self-contained as an empirical engineering contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- Scorecard weights or metrics
axioms (1)
- domain assumption Pretrained video diffusion models contain priors that transfer usefully to 3D medical dose prediction tasks.
Reference graph
Works this paper leans on
-
[1]
https://www.aapm.org/GrandChallenge/ GDP-HMM/, 2025
Generalizable dose prediction for heterogeneous multi-cohort and multi-site radiotherapy planning (gdp-hmm) grand chal- lenge. https://www.aapm.org/GrandChallenge/ GDP-HMM/, 2025. Accessed: 2025-10-24. 1, 6
work page 2025
-
[2]
Bobby Azad, Reza Azad, Sania Eskandari, Afshin Bozorg- pour, Amirhossein Kazerouni, Islem Rekik, and Dorit Merhof. Foundational models in medical imaging: A comprehensive survey and future vision.arXiv preprint arXiv:2310.18689,
-
[3]
McNiven, Adam Diamant, and Timothy C
Aaron Babier, Rafid Mahmood, Andrea L. McNiven, Adam Diamant, and Timothy C. Y . Chan. Knowledge-based auto- mated planning with three-dimensional generative adversarial networks.Medical Physics, 47(2):297–306, 2020. 2
work page 2020
-
[4]
Aaron Babier, Binghao Zhang, Rafid Mahmood, Kevin L. Moore, Thomas G. Purdie, Andrea L. McNiven, and Timothy C. Y . Chan. Openkbp: The open-access knowledge-based planning grand challenge.arXiv preprint arXiv:2011.14076,
-
[5]
Aaron Babier et al. Openkbp-opt: An international and open- source framework for plan optimization in knowledge-based planning.arXiv preprint arXiv:2202.08303, 2022. 1
-
[6]
Fan Bao et al. One transformer fits all distributions in multi- modal diffusion at scale.arXiv preprint arXiv:2303.06555,
-
[7]
Multidiffusion: Fusing diffusion paths for controlled image generation,
Omer Bar-Tal et al. Multidiffusion: Fusing diffusion paths for controlled image generation.arXiv preprint arXiv:2302.08113, 2023. 2
-
[8]
Ana Mar ´ıa Barrag´an-Montero, Dan Nguyen, Weiguo Lu, Mu Han Lin, Roya Norouzi-Kandalan, Xavier Geets, Edmond Sterpin, and Steve Jiang. Three-dimensional dose predic- tion for lung imrt patients with deep neural networks: robust learning from heterogeneous beam configurations.Medical Physics, 2019. 2
work page 2019
-
[9]
Søren M. Bentzen, Louis S. Constine, Joseph O. Deasy, Avra- ham Eisbruch, Andrew Jackson, Lawrence B. Marks, Ran- dall K. Ten Haken, and Ellen D. Yorke. Quantitative analyses of normal tissue effects in the clinic (QUANTEC): an in- troduction to the scientific issues.International Journal of Radiation Oncology Biology Physics, 2010. 2
work page 2010
-
[10]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Diakogiannis, Franc ¸ois Waldner, Peter Caccetta, and Chen Wu
Foivos I. Diakogiannis, Franc ¸ois Waldner, Peter Caccetta, and Chen Wu. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data.ISPRS Journal of Photogrammetry and Remote Sensing, 162:94–114, 2020. 2
work page 2020
-
[12]
Gary A. Ezzell, Jay W. Burmeister, Nesrin Dogan, Thomas J. LoSasso, John G. Mechalakos, Dimitris Mihailidis, Aimee Molineu, Jatinder R. Palta, Chester R. Ramsey, Brian J. Salter, Jianguo Shi, Ping Xia, Cedric X. Yu, and Ying Xiao. IMRT commissioning: multiple institution planning and dosimetry comparisons, a report from AAPM task group 119.Medical Physics...
work page 2009
-
[13]
Diffdp: Radiotherapy dose prediction via a diffusion model.arXiv preprint arXiv:2307.09794, 2023
Zhenghao Feng et al. Diffdp: Radiotherapy dose prediction via a diffusion model.arXiv preprint arXiv:2307.09794, 2023. 1, 2, 19
-
[14]
Flexible-cm gan: Towards precise 3d dose predic- tion in radiotherapy
Riqiang Gao, Bin Lou, Zhoubing Xu, Dorin Comaniciu, and Ali Kamen. Flexible-cm gan: Towards precise 3d dose predic- tion in radiotherapy. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 715–725, 2023. 1, 2, 6, 8
work page 2023
-
[15]
Riqiang Gao, Florin-Cristian Ghesu, Simon Arberet, Shahab Basiri, Esa Kuusela, Martin Kraus, Dorin Comaniciu, and Ali Kamen. Multi-agent reinforcement learning meets leaf sequencing in radiotherapy.arXiv preprint arXiv:2406.01853,
-
[16]
Riqiang Gao, Mamadou Diallo, Han Liu, Anthony Magliari, Jonathan Sackett, Wilko Verbakel, Sandra Meyers, Rafe Mc- beth, Masoud Zarepisheh, Simon Arberet, et al. Automating rt planning at scale: High quality data for ai training.arXiv preprint arXiv:2501.11803, 2025. 1, 2, 6, 8, 15, 17
-
[17]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems, pages 2672–2680,
-
[18]
Mary P Gronberg, Beth M Beadle, Adam S Garden, Heath Skinner, Skylar Gay, Tucker Netherton, Wenhua Cao, Car- los E Cardenas, Christine Chung, David T Fuentes, et al. Deep learning–based dose prediction for automated, individualized quality assurance of head and neck radiation therapy plans. Practical radiation oncology, 13(3):e282–e291, 2023. 1
work page 2023
-
[19]
Pengfei Guo, Can Zhao, Dong Yang, Yufan He, Vishwesh Nath, Ziyue Xu, Pedro RAS Bassi, Zongwei Zhou, Ben- jamin D Simon, Stephanie Anne Harmon, et al. Text2ct: Towards 3d ct volume generation from free-text descriptions using diffusion model.arXiv preprint arXiv:2505.04522,
-
[20]
Maisi: Medical ai for synthetic imaging
Pengfei Guo, Can Zhao, Dong Yang, Ziyue Xu, Vish- wesh Nath, Yucheng Tang, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, et al. Maisi: Medical ai for synthetic imaging. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 4430–4441. IEEE, 2025. 15, 21
work page 2025
-
[21]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InAdvances in Neural Information Processing Systems, pages 6840–6851, 2020. 2, 20 9
work page 2020
-
[22]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations (ICLR),
-
[23]
Adapting visual-language mod- els for generalizable anomaly detection in medical images
Chengwei Huang, Yicheng Zhang, Chen Chen, Meng Wang, Bing Li, and Xiangming He. Adapting visual-language mod- els for generalizable anomaly detection in medical images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3312–3322,
-
[24]
Fabian Isensee, Paul F. Jaeger, Simon A. A. Kohl, Jens Pe- tersen, and Klaus H. Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmenta- tion.Nature Methods, 18(2):203–211, 2021. 15
work page 2021
-
[25]
Domain knowledge driven 3d dose prediction using moment-based loss function
Gourav Jhanwar, Navdeep Dahiya, Parmida Ghahremani, Ma- soud Zarepisheh, and Saad Nadeem. Domain knowledge driven 3d dose prediction using moment-based loss function. Physics in Medicine & Biology, 67(18):185017, 2022. 2, 8
work page 2022
-
[26]
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met- zger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos- ing diffusion-based image generators for monocular depth estimation.arXiv preprint arXiv:2312.02145, 2023. 2
-
[27]
Vasant Kearney, Jason W Chan, Samuel Haaf, Martina De- scovich, and Timothy D Solberg. Dosenet: a volumetric dose prediction algorithm using 3d fully-convolutional neural net- works.Physics in Medicine & Biology, 63(23):235022, 2018. 2
work page 2018
-
[28]
Chan, Tianqi Wang, Alan Perry, Martina Descovich, Olivier Morin, Sue S
Vasant Kearney, Jason W. Chan, Tianqi Wang, Alan Perry, Martina Descovich, Olivier Morin, Sue S. Yom, and Timo- thy D. Solberg. DoseGAN: a generative adversarial network for synthetic dose prediction using attention-gated discrimi- nation and generation.Scientific Reports, 2020. 1, 2
work page 2020
-
[29]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2014. 14
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
Pick-a-pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain et al. Pick-a-pic: An open dataset of user preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, 2023. 2, 3
work page 2023
-
[31]
A review of dose prediction methods for tumor radiation therapy
Xiaoyan Kui, Fang Liu, Min Yang, Hao Wang, Canwei Liu, Dan Huang, Qinsong Li, Liming Chen, and Beiji Zou. A review of dose prediction methods for tumor radiation therapy. Meta-Radiology, 2(1):100057, 2024. 1
work page 2024
-
[32]
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Zichun Liao, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Om- niflow: Any-to-any generation with multi-modal rectified flows.arXiv preprint arXiv:2412.01169, 2024. 2
-
[33]
Xiaomeng Li, Hao Chen, Xiaojuan Qi, Qi Dou, Chi-Wing Fu, and Pheng-Ann Heng. H-DenseUNet: hybrid densely connected UNet for liver and tumor segmentation from CT volumes.IEEE Transactions on Medical Imaging, 2018. 2
work page 2018
-
[34]
Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. PMC-CLIP: Con- trastive language-image pre-training using biomedical docu- ments.arXiv preprint arXiv:2303.07240, 2023. 1
-
[35]
Weifeng Lin, Xinyu Wei, Renrui Zhang, Le Zhuo, Shitian Zhao, Siyuan Huang, Huan Teng, Junlin Xie, Yu Qiao, Peng Gao, et al. Pixwizard: Versatile image-to-image visual assistant with open-language instructions.arXiv preprint arXiv:2409.15278, 2024. 2
-
[36]
Yaron Lipman, Ricky T. Q. Chen, and Heli Ben-Hamu. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 16
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Shuolin Liu, Jingjing Zhang, Teng Li, Hui Yan, and Jianfei Liu. Technical note: A cascade 3d u-net for dose prediction in radiotherapy.Medical Physics, 48(11):7132–7141, 2021. 2
work page 2021
-
[38]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems, 2022. 16
work page 2022
-
[39]
Anthony Magliari, Ryan Clark, Lesley Rosa, and Sushil Beri- wal. Hn-sib-bpi: A single click, sub-site specific, dosimetric scorecard tuned rapidplan model created from a foundation model for treating head and neck with bilateral neck.Medical Dosimetry, 50(1):63–69, 2025. 3
work page 2025
-
[40]
Chong Mou et al. T2I-Adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453, 2023. 2
-
[41]
Dan Nguyen, Xun Jia, David Sher, Mu-Han Lin, Zohaib Iqbal, Hui Liu, and Steve Jiang. 3d radiotherapy dose predic- tion on head and neck cancer patients with a hierarchically densely connected u-net deep learning architecture.Physics in Medicine & Biology, 2019. 2
work page 2019
-
[42]
Dan Nguyen, Rafe McBeth, Azar Sadeghnejad Barkousaraie, Gyanendra Bohara, Chenyang Shen, Xun Jia, and Steve Jiang. Incorporating human and learned domain knowledge into training deep neural networks: A differentiable dose-volume histogram and adversarial inspired framework for generating pareto optimal dose distributions in radiation therapy.Medical Physi...
work page 2020
-
[43]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Piotr Bojanowski, Gautier Izacard, et al. DINOv2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agar- wal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 14, 15, 21
work page 2023
-
[46]
FiLM: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence, 2018. 14
work page 2018
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 1 10
work page 2021
-
[48]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 15
work page 2022
-
[50]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer Assisted Inter- vention (MICCAI). Springer, 2015. 2
work page 2015
-
[51]
Saikat Roy, Gregor Koehler, Constantin Ulrich, Michael Baumgartner, Jens Petersen, Fabian Isensee, Paul F. Jaeger, and Klaus H. Maier-Hein. Mednext: Transformer-driven scal- ing of convnets for medical image segmentation. InMedical Image Computing and Computer Assisted Intervention (MIC- CAI), 2023. 2, 15
work page 2023
-
[52]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Confer- ence on Learning Representations (ICLR), 2022. 20
work page 2022
-
[53]
Petra Seibold, Adam Webb, Miguel E. Aguado-Barrera, David Azria, Celine Bourgier, Muriel Brengues, Erik Briers, Renee Bultijnck, Patricia Calvo-Crespo, Ana Carballo, et al. Requite: a prospective multicentre cohort study of patients undergoing radiotherapy for breast, lung or prostate cancer. Radiotherapy and Oncology, 138:212–224, 2019. 2, 6, 15
work page 2019
-
[54]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. Di- nov3.arXiv preprint arXiv:2508.10104, 2025. 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Xinrui Song, Xuanang Xu, and Pingkun Yan. Dino-reg: Gen- eral purpose image encoder for training-free multi-modal deformable medical image registration. InInternational Con- ference on Medical Image Computing and Computer-Assisted Intervention, pages 608–617. Springer, 2024. 1
work page 2024
- [56]
-
[57]
Any-to-any generation via composable diffusion.arXiv preprint arXiv:2305.11846, 2023
Zineng Tang et al. Any-to-any generation via composable diffusion.arXiv preprint arXiv:2305.11846, 2023. 2
-
[58]
Bilateral head&neck 70/63/56gy (hn-sib-bpi) [rapidplan]
Varian Medical Affairs. Bilateral head&neck 70/63/56gy (hn-sib-bpi) [rapidplan]. https://medicalaffairs. varian . com / hn - sib - bpi - rapidplan - vmat2,
-
[59]
Accessed: 2024-10-19. 3, 5, 6
work page 2024
-
[60]
Lung – conventional 60gy (nrg lu- 004 / atkins km 2021)
Varian Medical Affairs. Lung – conventional 60gy (nrg lu- 004 / atkins km 2021). https://medicalaffairs. varian . com / lung - conventional - vmat2, 2024. Accessed: 2024-10-19. 3, 5, 6
work page 2021
-
[61]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017. 14
work page 2017
-
[62]
Diffusion model align- ment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model align- ment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8228–8238, 2024. 2
work page 2024
-
[63]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gener- ative models.arXiv preprint arXiv:2503.20314, 2025. 2, 14, 15, 21
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Bin Wang, Lin Teng, Lanzhuju Mei, Zhiming Cui, Xuanang Xu, Qianjin Feng, and Dinggang Shen. Deep learning-based head and neck radiotherapy planning dose prediction via beam-wise dose decomposition. InInternational Confer- ence on Medical Image Computing and Computer-Assisted Intervention, pages 575–584. Springer, 2022. 2
work page 2022
-
[65]
Wentao Wang, Yang Sheng, Chunhao Wang, Jiahan Zhang, Xinyi Li, Manisha Palta, Brian Czito, Christopher G Willett, Qiuwen Wu, Yaorong Ge, et al. Fluence map prediction using deep learning models–direct plan generation for pancreas stereotactic body radiation therapy.Frontiers in artificial intelligence, 3:68, 2020. 1
work page 2020
-
[66]
Junde Wu, Wei Ji, Yuanpei Liu, Huazhu Fu, Min Xu, Yanwu Xu, and Yueming Jin. Medical SAM adapter: Adapting seg- ment anything model for medical image segmentation.arXiv preprint arXiv:2304.12620, 2023. 1
-
[67]
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hong- sheng Li. Human preference score: Better aligning text- to-image models with human preference.arXiv preprint arXiv:2303.14420, 2023. 3
-
[68]
Omnigen: Unified image generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Zhenbang Yang, Chao Shen, Wenrui Dai, Jiarui Gan, Yu Liu, Ke Shang, Zhifeng Chen, and Qingshan Liu. Omnigen: Unified image generation. arXiv preprint arXiv:2409.11340, 2024. 2
-
[69]
Learning and evaluating human preferences for text-to-image generation
Jun Xu, Siyao Ren, Zeqiang Lin, Jiaming Zhu, Zhi Zhang, Yixiao Jiang, Wenwang Ye, Jianzhuang Wang, Tong Lu, Ji- Rong Gu, Xiaoyang Wang, and Shuai Yang. Learning and evaluating human preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, 2023. 2, 3
work page 2023
-
[70]
Xingqian Xu et al. Versatile diffusion: Text, images and variations all in one diffusion model.arXiv preprint arXiv:2211.08332, 2022. 2
-
[71]
Yifeng Xu, Zhenliang He, Meina Kan, Shiguang Shan, and Xilin Chen. Jodi: Unification of visual generation and under- standing via joint modeling.arXiv preprint arXiv:2505.19084,
-
[72]
Using human feedback to fine-tune diffusion models without any reward model
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Qimai Li, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
work page 2024
-
[73]
Jingjing Zhang, Shuolin Liu, Hui Yan, Teng Li, Ronghu Mao, and Jianfei Liu. Predicting voxel-level dose distributions for esophageal radiotherapy using densely connected network with dilated convolutions.Physics in Medicine & Biology, 65 (20):205013, 2020. 2 11
work page 2020
-
[74]
Adding conditional control to text-to-image diffusion models,
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models.arXiv preprint arXiv:2302.05543, 2023. 2, 19
-
[75]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedi- cal foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[76]
Learning multi- dimensional human preference for text-to-image generation
Sixian Zhang, Bohan Wang, Junqiang Wu, Yan Li, Tingt- ing Gao, Di Zhang, and Zhongyuan Wang. Learning multi- dimensional human preference for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8018–8027,
-
[77]
Yiwen Zhang et al. Dosediff: Distance-aware diffusion model for dose prediction in radiotherapy.arXiv preprint arXiv:2306.16324, 2023. 1, 2
-
[78]
Can Zhao, Pengfei Guo, Dong Yang, Yucheng Tang, Yu- fan He, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, and Daguang Xu. MAISI-v2: Accelerated 3d high-resolution medical image synthesis with rectified flow and region-specific contrastive loss.arXiv preprint arXiv:2508.05772, 2025. 2
-
[79]
Diffusionnft: Online diffusion rein- forcement with forward process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion rein- forcement with forward process. InInternational Conference on Learning Representations (ICLR), 2026. 2, 5, 16 12 Supplementary Contents A. Detailed Model Structures 14 B. Training Details 15...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.