Recognition: no theorem link
DegBins: Degradation-Driven Binning for Depth Super-Resolution
Pith reviewed 2026-05-12 04:41 UTC · model grok-4.3
The pith
Depth super-resolution is reframed as hybrid classification-regression where residuals become probability-weighted discrete bins whose ranges adapt to local degradations in feature space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
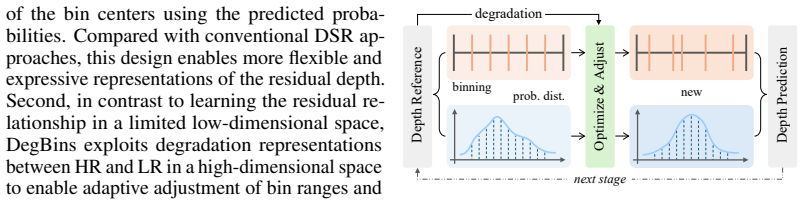
DegBins reformulates the regression-based DSR as a hybrid classification-regression problem, where the residual depth is represented as a linear combination of discrete depth bins weighted by their learned probability distribution, yielding more flexible and expressive representations. It models the degradation relationship between HR and LR in a high-dimensional feature space, enabling adaptive bin range adjustment and probability optimization conditioned on local degradation characteristics. A multi-stage refinement scheme performs progressively finer-grained bin partitioning and probability updating based on the previous estimate.
What carries the argument
Degradation-driven binning: discrete depth bins whose ranges and probability weights are learned and adapted inside high-dimensional feature space according to local degradation patterns.
If this is right
- Finer depth recovery in areas with severe degradations or complex structures.
- Greater robustness when degradation patterns differ across the image or across datasets.
- Progressive improvement through successive stages of finer binning and updated probabilities.
- More generalizable performance on unseen depth super-resolution scenarios.
Where Pith is reading between the lines
- The same hybrid binning idea could be tested on other regression problems in vision that suffer from non-stationary degradations, such as image deblurring or denoising.
- Real-world depth sensors with unknown or mixed degradations would be a direct test bed for whether the feature-space adaptation generalizes beyond the training distribution.
- If the probability-weighted bins prove effective, similar discrete representations might replace pure regression heads in related tasks like surface normal estimation or optical flow.
Load-bearing premise
That representing residuals as adaptive probability-weighted discrete bins in high-dimensional feature space will capture spatially varying degradations more effectively than direct additive residual prediction.
What would settle it
A head-to-head test on the same five benchmarks in which a conventional additive residual network matches or exceeds DegBins accuracy, especially in regions of severe or varying degradation, would show the binning reformulation adds no advantage.
Figures





read the original abstract
Depth super-resolution (DSR) aims to recover a high-resolution (HR) depth map from its low-resolution (LR) counterpart. With color image guidance, this task is typically formulated as learning the residual between HR and LR in a low-dimensional feature space. However, this additive formulation is insufficient to accurately capture the complex relationship between HR and LR, especially under spatially varying degradations. In this paper, we introduce DegBins, a novel DSR framework that leverages degradation-driven binning to adaptively enhance residual modeling. Specifically, DegBins reformulates the regression-based DSR as a hybrid classification-regression problem, where the residual depth is represented as a linear combination of discrete depth bins weighted by their learned probability distribution, yielding more flexible and expressive representations. Furthermore, DegBins models the degradation relationship between HR and LR in a high-dimensional feature space, enabling adaptive bin range adjustment and probability optimization conditioned on local degradation characteristics. To progressively improve reconstruction quality, DegBins adopts a multi-stage refinement scheme, where each stage performs finer-grained bin partitioning and probability updating based on the former estimation. This coarse-to-fine design facilitates more accurate depth recovery, particularly in regions with severe degradations or complex structural variations. Extensive experiments across five benchmarks demonstrate that DegBins consistently outperforms existing state-of-the-art methods in terms of accuracy, robustness, and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DegBins, a novel framework for depth super-resolution that reformulates residual learning as a hybrid classification-regression task. Residual depth is modeled as a linear combination of discrete depth bins weighted by learned probabilities, with bin ranges adaptively adjusted in high-dimensional feature space conditioned on local degradation characteristics, followed by a multi-stage coarse-to-fine refinement process. The central claim is that this degradation-driven binning yields more flexible and expressive representations than standard additive residuals, leading to consistent outperformance over state-of-the-art methods across five benchmarks in accuracy, robustness, and generalization.
Significance. If the empirical results hold, the hybrid binning approach could advance depth super-resolution by offering a more adaptive mechanism for handling spatially varying degradations, moving beyond additive residual formulations and potentially improving reconstruction quality in challenging real-world conditions.
major comments (2)
- Abstract: The central claim of consistent outperformance on five benchmarks is asserted without any quantitative results, baselines, metrics, ablation studies, or error analysis. This absence is load-bearing for the empirical contribution and prevents evaluation of whether the hybrid binning formulation delivers meaningful gains over additive residuals.
- Method description (as summarized in abstract): The assumption that representing residuals as probability-weighted bin combinations with degradation-conditioned range adaptation in feature space will capture complex spatially varying degradations better than standard additive residual learning lacks supporting derivation or comparison; without concrete equations or analysis showing how this reduces to a superior quantity, the improvement remains unverified.
minor comments (1)
- Abstract: The multi-stage refinement scheme is described at a high level; specifying how bin partitioning becomes finer-grained and how probability updates are performed at each stage would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address each major comment below with clarifications from the full manuscript and note revisions where they strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: The central claim of consistent outperformance on five benchmarks is asserted without any quantitative results, baselines, metrics, ablation studies, or error analysis. This absence is load-bearing for the empirical contribution and prevents evaluation of whether the hybrid binning formulation delivers meaningful gains over additive residuals.
Authors: We agree that the abstract summarizes the contribution at a high level without specific numbers due to length constraints. The full manuscript provides the requested details in Section 4 (Experiments), including quantitative tables comparing DegBins against multiple baselines on five benchmarks using RMSE, MAE, and other metrics, plus ablation studies and error analysis demonstrating gains from the hybrid formulation. To better support the claim in the abstract, we will revise it to include a concise mention of key average improvements. revision: yes
-
Referee: Method description (as summarized in abstract): The assumption that representing residuals as probability-weighted bin combinations with degradation-conditioned range adaptation in feature space will capture complex spatially varying degradations better than standard additive residual learning lacks supporting derivation or comparison; without concrete equations or analysis showing how this reduces to a superior quantity, the improvement remains unverified.
Authors: Section 3 of the manuscript provides the concrete formulation and derivation. The residual is expressed as a linear combination r = sum p_k * b_k, where p_k are learned probabilities and b_k are adaptively adjusted bin values conditioned on degradation features extracted in high-dimensional space. This reduces to a more expressive mapping than fixed additive residuals because the effective residual can vary non-linearly with local degradation characteristics. The paper includes analysis of this advantage and verifies it via direct comparisons and ablations in the experiments. We will expand the derivation paragraph in Section 3 if needed for clarity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents DegBins as a new framework that reformulates depth super-resolution as a hybrid classification-regression task using degradation-conditioned binning in feature space and multi-stage refinement. No load-bearing equations, predictions, or claims reduce by construction to fitted parameters from the same work or to self-citations whose validity depends on the current paper. The central modeling choice (probability-weighted bin combinations for residuals) is introduced as an explicit alternative to additive residuals and is evaluated empirically on external benchmarks, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adabins: Depth estimation using adaptive bins
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. InCVPR, pages 4009–4018, 2021
work page 2021
-
[2]
Localbins: Improving depth estimation by learning local distributions
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Localbins: Improving depth estimation by learning local distributions. InECCV, pages 480–496. Springer, 2022
work page 2022
-
[3]
Learning graph regularisation for guided super-resolution
Riccardo De Lutio, Alexander Becker, Stefano D’Aronco, Stefania Russo, Jan D Wegner, and Konrad Schindler. Learning graph regularisation for guided super-resolution. InCVPR, pages 1979–1988, 2022
work page 1979
-
[4]
Xin Deng and Pier Luigi Dragotti. Deep convolutional neural network for multi-modal image restoration and fusion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43 (10):3333–3348, 2020
work page 2020
-
[5]
Depth map prediction from a single image using a multi-scale deep network.NeurIPS, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.NeurIPS, 27, 2014
work page 2014
-
[6]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InCVPR, pages 605–613, 2017
work page 2017
-
[7]
Image guided depth upsampling using anisotropic total generalized variation
David Ferstl, Christian Reinbacher, Rene Ranftl, Matthias Rüther, and Horst Bischof. Image guided depth upsampling using anisotropic total generalized variation. InICCV, pages 993– 1000, 2013
work page 2013
-
[8]
Deep ordinal regression network for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Batmanghelich, and Dacheng Tao. Deep ordinal regression network for monocular depth estimation. InCVPR, pages 2002–2011, 2018
work page 2002
-
[9]
Towards fast and accurate real-world depth super-resolution: Benchmark dataset and baseline
Lingzhi He, Hongguang Zhu, Feng Li, Huihui Bai, Runmin Cong, Chunjie Zhang, Chunyu Lin, Meiqin Liu, and Yao Zhao. Towards fast and accurate real-world depth super-resolution: Benchmark dataset and baseline. InCVPR, pages 9229–9238, 2021
work page 2021
-
[10]
Evaluation of cost functions for stereo matching
Heiko Hirschmuller and Daniel Scharstein. Evaluation of cost functions for stereo matching. In CVPR, pages 1–8, 2007
work page 2007
-
[11]
Uncertainty quantification in depth estimation via constrained ordinal regression
Dongting Hu, Liuhua Peng, Tingjin Chu, Xiaoxing Zhang, Yinian Mao, Howard Bondell, and Mingming Gong. Uncertainty quantification in depth estimation via constrained ordinal regression. InECCV, pages 237–256. Springer, 2022
work page 2022
-
[12]
C2pd: Continuity-constrained pixelwise deformation for guided depth super-resolution
Jiahui Kang, Qing Cai, Runqing Tan, Yimei Liu, and Zhi Liu. C2pd: Continuity-constrained pixelwise deformation for guided depth super-resolution. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4212–4220, 2025
work page 2025
-
[13]
Beomjun Kim, Jean Ponce, and Bumsub Ham. Deformable kernel networks for joint image filtering.International Journal of Computer Vision, 129(2):579–600, 2021
work page 2021
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
All-in-one image restoration for unknown corruption
Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv, and Xi Peng. All-in-one image restoration for unknown corruption. InCVPR, pages 17452–17462, 2022
work page 2022
-
[16]
Yijun Li, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang. Deep joint image filtering. InECCV, pages 154–169, 2016
work page 2016
-
[17]
Yijun Li, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang. Joint image filtering with deep convolutional networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(8):1909–1923, 2019
work page 1909
-
[18]
Zhenyu Li, Xuyang Wang, Xianming Liu, and Junjun Jiang. Binsformer: Revisiting adaptive bins for monocular depth estimation.IEEE Transactions on Image Processing, 33:3964–3976, 2024. 10
work page 2024
-
[19]
Efficient and degradation-adaptive network for real-world image super-resolution
Jie Liang, Hui Zeng, and Lei Zhang. Efficient and degradation-adaptive network for real-world image super-resolution. InECCV, pages 574–591, 2022
work page 2022
-
[20]
Kai-Han Lo, Yu-Chiang Frank Wang, and Kai-Lung Hua. Edge-preserving depth map upsam- pling by joint trilateral filter.IEEE transactions on cybernetics, 48(1):371–384, 2017
work page 2017
-
[21]
Depth enhancement via low-rank matrix completion
Si Lu, Xiaofeng Ren, and Feng Liu. Depth enhancement via low-rank matrix completion. In CVPR, pages 3390–3397, 2014
work page 2014
-
[22]
Guided depth super-resolution by deep anisotropic diffusion
Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Guided depth super-resolution by deep anisotropic diffusion. InCVPR, pages 18237–18246, 2023
work page 2023
-
[23]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, pages 10912–10922, 2021
work page 2021
-
[24]
Learning conditional random fields for stereo
Daniel Scharstein and Chris Pal. Learning conditional random fields for stereo. InCVPR, pages 1–8, 2007
work page 2007
-
[25]
Nddepth: Normal- distance assisted monocular depth estimation
Shuwei Shao, Zhongcai Pei, Weihai Chen, Xingming Wu, and Zhengguo Li. Nddepth: Normal- distance assisted monocular depth estimation. InICCV, pages 7931–7940, 2023
work page 2023
-
[26]
Iebins: Iterative elastic bins for monocular depth estimation.NeurIPS, 36:53025–53037, 2023
Shuwei Shao, Zhongcai Pei, Xingming Wu, Zhong Liu, Weihai Chen, and Zhengguo Li. Iebins: Iterative elastic bins for monocular depth estimation.NeurIPS, 36:53025–53037, 2023
work page 2023
-
[27]
Symmetric uncertainty-aware feature transmission for depth super-resolution
Wuxuan Shi, Mang Ye, and Bo Du. Symmetric uncertainty-aware feature transmission for depth super-resolution. InACM MM, pages 3867–3876, 2022
work page 2022
-
[28]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InECCV, pages 746–760, 2012
work page 2012
-
[29]
Pixel-adaptive convolutional neural networks
Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, Erik Learned-Miller, and Jan Kautz. Pixel-adaptive convolutional neural networks. InCVPR, pages 11166–11175, 2019
work page 2019
-
[30]
Baoli Sun, Xinchen Ye, Baopu Li, Haojie Li, Zhihui Wang, and Rui Xu. Learning scene structure guidance via cross-task knowledge transfer for single depth super-resolution. InCVPR, pages 7792–7801, 2021
work page 2021
-
[31]
Bridgenet: A joint learning network of depth map super-resolution and monocular depth estimation
Qi Tang, Runmin Cong, Ronghui Sheng, Lingzhi He, Dan Zhang, Yao Zhao, and Sam Kwong. Bridgenet: A joint learning network of depth map super-resolution and monocular depth estimation. InACM MM, pages 2148–2157, 2021
work page 2021
-
[32]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InECCV, pages 402–419. Springer, 2020
work page 2020
-
[33]
Haotian Wang, Meng Yang, and Nanning Zheng. G2-monodepth: A general framework of generalized depth inference from monocular rgb+ x data.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3753–3771, 2023
work page 2023
-
[34]
Kun Wang, Zhiqiang Yan, Junkai Fan, Wanlu Zhu, Xiang Li, Jun Li, and Jian Yang. Dcdepth: Progressive monocular depth estimation in discrete cosine domain.NeurIPS, 37:64629–64648, 2024
work page 2024
-
[35]
Unsupervised degradation representation learning for blind super-resolution
Longguang Wang, Yingqian Wang, Xiaoyu Dong, Qingyu Xu, Jungang Yang, Wei An, and Yulan Guo. Unsupervised degradation representation learning for blind super-resolution. In CVPR, pages 10581–10590, 2021
work page 2021
-
[36]
Sgnet: Structure guided network via gradient- frequency awareness for depth map super-resolution
Zhengxue Wang, Zhiqiang Yan, and Jian Yang. Sgnet: Structure guided network via gradient- frequency awareness for depth map super-resolution. InAAAI, pages 5823–5831, 2024
work page 2024
-
[37]
Scene prior filtering for depth map super-resolution.arXiv preprint arXiv:2402.13876, 2024
Zhengxue Wang, Zhiqiang Yan, Ming-Hsuan Yang, Jinshan Pan, Jian Yang, Ying Tai, and Guang- wei Gao. Scene prior filtering for depth map super-resolution.arXiv preprint arXiv:2402.13876, 2024. 11
-
[38]
Dornet: A degradation oriented and regularized network for blind depth super-resolution
Zhengxue Wang, Zhiqiang Yan, Jinshan Pan, Guangwei Gao, Kai Zhang, and Jian Yang. Dornet: A degradation oriented and regularized network for blind depth super-resolution. InCVPR, pages 15813–15822, 2025
work page 2025
-
[39]
Spatiotemporal difference network for video depth super-resolution
Zhengxue Wang, Yuan Wu, Xiang Li, Zhiqiang Yan, and Jian Yang. Spatiotemporal difference network for video depth super-resolution. InAAAI, pages 10403–10411, 2026
work page 2026
-
[40]
Zhiqiang Yan, Kun Wang, Xiang Li, Zhenyu Zhang, Guangyu Li, Jun Li, and Jian Yang. Learning complementary correlations for depth super-resolution with incomplete data in real world.IEEE Transactions on Neural Networks and Learning Systems, 35(4):5616–5626, 2022
work page 2022
-
[41]
Distortion and uncertainty aware loss for panoramic depth completion
Zhiqiang Yan, Xiang Li, Kun Wang, Shuo Chen, Jun Li, and Jian Yang. Distortion and uncertainty aware loss for panoramic depth completion. InICML, pages 39099–39109, 2023
work page 2023
-
[42]
Tri-perspective view decomposition for geometry-aware depth completion
Zhiqiang Yan, Yuankai Lin, Kun Wang, Yupeng Zheng, Yufei Wang, Zhenyu Zhang, Jun Li, and Jian Yang. Tri-perspective view decomposition for geometry-aware depth completion. In CVPR, pages 4874–4884, 2024
work page 2024
-
[43]
Zhiqiang Yan, Zhengxue Wang, Kun Wang, Jun Li, and Jian Yang. Completion as enhancement: A degradation-aware selective image guided network for depth completion.arXiv preprint arXiv:2412.19225, 2024
-
[44]
Zhiqiang Yan, Kun Wang, Xiang Li, Guangwei Gao, Jun Li, and Jian Yang. Tri-perspective view decomposition for geometry aware depth completion and super-resolution.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[45]
Ducos: Duality constrained depth super-resolution via foundation model
Zhiqiang Yan, Zhengxue Wang, Haoye Dong, Jun Li, Jian Yang, and Gim Hee Lee. Ducos: Duality constrained depth super-resolution via foundation model. InICCV, pages 8361–8371, 2025
work page 2025
-
[46]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.arXiv preprint arXiv:2406.09414, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
Mingde Yao, Ruikang Xu, Yuanshen Guan, Jie Huang, and Zhiwei Xiong. Neural degradation representation learning for all-in-one image restoration.IEEE Transactions on Image Processing, 2024
work page 2024
-
[48]
Guanghao Yin, Wei Wang, Zehuan Yuan, Wei Ji, Dongdong Yu, Shouqian Sun, Tat-Seng Chua, and Changhu Wang. Conditional hyper-network for blind super-resolution with multiple degradations.IEEE Transactions on Image Processing, 31:3949–3960, 2022
work page 2022
-
[49]
Structure flow-guided network for real depth super-resolution
Jiayi Yuan, Haobo Jiang, Xiang Li, Jianjun Qian, Jun Li, and Jian Yang. Structure flow-guided network for real depth super-resolution. InAAAI, pages 3340–3348, 2023
work page 2023
-
[50]
All-in-one multi- degradation image restoration network via hierarchical degradation representation
Cheng Zhang, Yu Zhu, Qingsen Yan, Jinqiu Sun, and Yanning Zhang. All-in-one multi- degradation image restoration network via hierarchical degradation representation. InACM MM, pages 2285–2293, 2023
work page 2023
-
[51]
Ingredient-oriented multi-degradation learning for image restoration
Jinghao Zhang, Jie Huang, Mingde Yao, Zizheng Yang, Hu Yu, Man Zhou, and Feng Zhao. Ingredient-oriented multi-degradation learning for image restoration. InCVPR, pages 5825– 5835, 2023
work page 2023
-
[52]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. Designing a practical degradation model for deep blind image super-resolution. InICCV, pages 4791–4800, 2021
work page 2021
-
[53]
Image super- resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super- resolution using very deep residual channel attention networks. InECCV, pages 286–301, 2018
work page 2018
-
[54]
Discrete cosine transform network for guided depth map super-resolution
Zixiang Zhao, Jiangshe Zhang, Shuang Xu, Zudi Lin, and Hanspeter Pfister. Discrete cosine transform network for guided depth map super-resolution. InCVPR, pages 5697–5707, 2022
work page 2022
-
[55]
Spherical space feature decomposition for guided depth map super-resolution
Zixiang Zhao, Jiangshe Zhang, Xiang Gu, Chengli Tan, Shuang Xu, Yulun Zhang, Radu Timofte, and Luc Van Gool. Spherical space feature decomposition for guided depth map super-resolution. InICCV, pages 12547–12558, 2023. 12
work page 2023
-
[56]
Decoupling fine detail and global geometry for compressed depth map super-resolution
Huan Zheng, Wencheng Han, and Jianbing Shen. Decoupling fine detail and global geometry for compressed depth map super-resolution. InCVPR, pages 951–960, 2025
work page 2025
-
[57]
Zhiwei Zhong, Xianming Liu, Junjun Jiang, Debin Zhao, Zhiwen Chen, and Xiangyang Ji. High-resolution depth maps imaging via attention-based hierarchical multi-modal fusion.IEEE Transactions on Image Processing, 31:648–663, 2021
work page 2021
-
[58]
Zhiwei Zhong, Xianming Liu, Junjun Jiang, Debin Zhao, and Xiangyang Ji. Deep attentional guided image filtering.IEEE Transactions on Neural Networks and Learning Systems, 2023
work page 2023
-
[59]
Guided depth map super-resolution: A survey.ACM Computing Surveys, 55(14s):1–36, 2023
Zhiwei Zhong, Xianming Liu, Junjun Jiang, Debin Zhao, and Xiangyang Ji. Guided depth map super-resolution: A survey.ACM Computing Surveys, 55(14s):1–36, 2023
work page 2023
-
[60]
Zhiwei Zhong, Xianming Liu, Junjun Jiang, Debin Zhao, and Shiqi Wang. Dual-level cross- modality neural architecture search for guided image super-resolution.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[61]
Hongyang Zhou, Xiaobin Zhu, Jianqing Zhu, Zheng Han, Shi-Xue Zhang, Jingyan Qin, and Xu-Cheng Yin. Learning correction filter via degradation-adaptive regression for blind single image super-resolution. InICCV, pages 12365–12375, 2023
work page 2023
-
[62]
Deformable convnets v2: More deformable, better results
Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. InCVPR, pages 9308–9316, 2019. 13 A Technical Appendices for DegBins A.1 Metrics Given the predicted depth map X and the corresponding GT Z containing m valid pixels, we evaluate performance using RMSE (cm), MAE (cm), and the accuracy metricδ 1, defin...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.