Recognition: no theorem link
Overcoming Catastrophic Forgetting in Visual Continual Learning with Reinforcement Fine-Tuning
Pith reviewed 2026-05-12 04:36 UTC · model grok-4.3
The pith
RaPO reduces catastrophic forgetting in visual continual learning by rewarding reinforcement learning rollouts that stay close to previous task policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
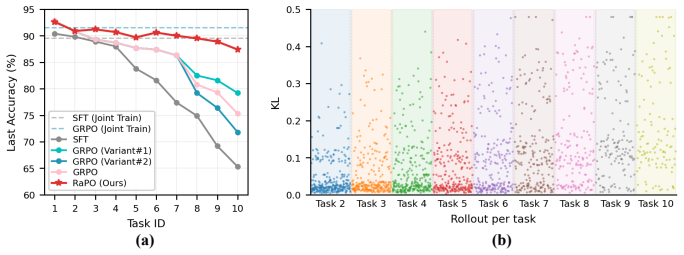
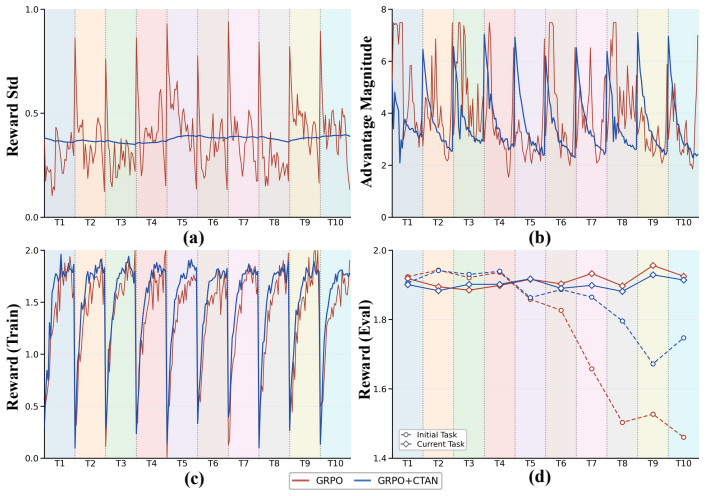
Pilot experiments reveal that trajectory-level distribution drift agnosticism is the key bottleneck: among rollouts achieving the same task reward, the KL divergence from the preceding-task policy varies substantially and correlates with forgetting. RaPO mitigates this through a retention reward that converts the trajectory-level KL divergence into a continuous additive signal, preferentially reinforcing knowledge-preserving rollouts within each group, together with cross-task advantage normalization that maintains a persistent exponential moving average of reward statistics across task boundaries to stabilize optimization.
What carries the argument
Retention Reward that turns trajectory-level KL divergence from the preceding policy into a continuous reward signal to prefer preserving rollouts, paired with Cross-Task Advantage Normalization (CTAN) that uses an exponential moving average of reward statistics to stabilize training across sequential tasks.
If this is right
- RaPO delivers leading performance by substantially reducing catastrophic forgetting while preserving strong plasticity across class-incremental, domain-incremental, and three other visual continual learning settings.
- The method leverages the free-form textual generalization of multimodal large language models to evaluate retention of prior visual knowledge during sequential learning.
- Cross-task advantage normalization prevents optimization instability that would otherwise arise when reward statistics change at task boundaries.
- Explicit mitigation of trajectory-level drift makes reinforcement fine-tuning more viable for lifelong visual task sequences than standard approaches.
Where Pith is reading between the lines
- Similar drift-aware reward shaping could be tested in non-visual continual learning domains such as language or control tasks where policy stability across sequences is also valuable.
- The trajectory-level insight suggests that monitoring KL divergence during training might serve as a practical diagnostic for impending forgetting even in non-reinforcement continual learning setups.
- Combining the retention reward with existing regularization techniques could be explored to further strengthen preservation without additional hyperparameter tuning.
- If the method scales, it could support longer task sequences in real-world visual applications such as robotics or medical imaging where forgetting old categories is costly.
Load-bearing premise
Trajectory-level distribution drift is the main cause of forgetting, and converting it into an additive reward will reliably protect prior knowledge without reducing plasticity or causing optimization instability.
What would settle it
An ablation that removes the retention reward component on the same five visual continual learning benchmarks and measures no increase in forgetting rates, or a drop in new-task accuracy when the full method is used, would falsify the central claim.
Figures




read the original abstract
Recent studies suggest that Reinforcement Fine-Tuning (RFT) is inherently more resilient to catastrophic forgetting than Supervised Fine-Tuning (SFT). However, whether RFT (e.g., GRPO) can effectively overcome forgetting in challenging visual continual learning settings, such as class-incremental learning (CIL) and domain-incremental learning (DIL), remains an open problem. Through a pilot study, we confirm that while RFT consistently outperforms SFT, it still suffers from non-negligible forgetting. We empirically trace this bottleneck to Trajectory-level Drift Agnosticism: among candidate rollouts achieving identical task rewards, the KL divergence from the preceding-task policy varies substantially, which strongly correlates with catastrophic forgetting across sequential tasks. Motivated by this insight, we propose Retention-aware Policy Optimization (RaPO), a simple yet effective RFT method that explicitly mitigates forgetting through trajectory-level reward shaping. Specifically, RaPO comprises two core components: (1) Retention Reward that converts trajectory-level distribution drift into a continuous reward signal, preferentially reinforcing knowledge-preserving rollouts within each group; (2) Cross-Task Advantage Normalization (CTAN), which maintains a persistent exponential moving average of reward statistics across task boundaries to stabilize the optimization progress during continual learning. Leveraging the free-form textual generalization of MLLMs, we comprehensively evaluate RaPO across five visual continual learning settings. Extensive experiments demonstrate that RaPO achieves leading performance, substantially reducing catastrophic forgetting while preserving strong plasticity. To the best of our knowledge, this work represents the first systematic exploration of RFT in visual continual learning, offering insights that we hope will inspire future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reinforcement fine-tuning (RFT) outperforms supervised fine-tuning (SFT) in visual continual learning but still exhibits non-negligible catastrophic forgetting. Through a pilot study, it attributes this to Trajectory-level Drift Agnosticism, where KL divergence from the prior policy varies among high-reward rollouts and correlates with forgetting. It proposes Retention-aware Policy Optimization (RaPO) consisting of a Retention Reward that shapes rewards to favor low-drift trajectories and Cross-Task Advantage Normalization (CTAN) using persistent EMA of reward statistics. Evaluated across five visual CL settings (CIL, DIL, etc.) with MLLMs, RaPO is reported to achieve leading performance by substantially reducing forgetting while preserving plasticity.
Significance. If the empirical results and ablations hold, the work would be moderately significant as the first systematic study applying RFT to visual continual learning. The reward-shaping approach based on policy drift offers a concrete mechanism that could generalize beyond the tested settings and inspire further integration of RL techniques with incremental learning for large multimodal models.
major comments (3)
- Abstract and §4 (Experiments): the central claim that RaPO 'achieves leading performance' and 'substantially reduc[es] catastrophic forgetting' is asserted without any quantitative numbers, baseline comparisons, statistical significance tests, or ablation results, which are load-bearing for validating the method's effectiveness over prior RFT and SFT approaches.
- §3.1 (Pilot Study): the asserted strong correlation between trajectory-level KL divergence and forgetting lacks reported controls, error bars, or statistical analysis, leaving open whether the correlation is causal or whether other interference mechanisms dominate.
- §3.2 (RaPO Method): the Retention Reward and CTAN are introduced as additive signals and EMA normalization, but no analysis or equations demonstrate that they preserve new-task plasticity (e.g., forward transfer) or avoid optimization instability when reward scales differ across tasks, which is required for the claim that the method mitigates forgetting without side effects.
minor comments (2)
- The term 'Trajectory-level Drift Agnosticism' is used repeatedly but never given a formal definition or equation, which reduces clarity in the motivation section.
- Notation for the Retention Reward and CTAN (e.g., how the EMA is exactly computed and applied to advantages) could be made more precise with explicit formulas to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We have addressed each major comment in detail below and revised the manuscript to incorporate the feedback, strengthening the presentation of our results and analysis.
read point-by-point responses
-
Referee: Abstract and §4 (Experiments): the central claim that RaPO 'achieves leading performance' and 'substantially reduc[es] catastrophic forgetting' is asserted without any quantitative numbers, baseline comparisons, statistical significance tests, or ablation results, which are load-bearing for validating the method's effectiveness over prior RFT and SFT approaches.
Authors: We agree that providing quantitative support in the abstract and ensuring comprehensive reporting in the experiments section is important. Although Section 4 of the original manuscript includes tables with performance metrics comparing RaPO to SFT, GRPO, and other baselines across the five visual CL settings, we acknowledge the need for more explicit quantification and statistical validation. In the revised version, we have updated the abstract to include specific numbers highlighting the leading performance and forgetting reduction. We have also added statistical significance tests (e.g., t-tests) and expanded the ablation studies with additional results in §4 to better validate the claims. revision: yes
-
Referee: §3.1 (Pilot Study): the asserted strong correlation between trajectory-level KL divergence and forgetting lacks reported controls, error bars, or statistical analysis, leaving open whether the correlation is causal or whether other interference mechanisms dominate.
Authors: Thank you for this observation. The pilot study demonstrates the correlation via empirical observations and plots. To strengthen this, we have revised §3.1 to include error bars on the relevant figures, additional control experiments to isolate the effect of KL divergence, and statistical analysis such as correlation coefficients and p-values. We also discuss the potential causality and acknowledge other possible mechanisms in the text. revision: yes
-
Referee: §3.2 (RaPO Method): the Retention Reward and CTAN are introduced as additive signals and EMA normalization, but no analysis or equations demonstrate that they preserve new-task plasticity (e.g., forward transfer) or avoid optimization instability when reward scales differ across tasks, which is required for the claim that the method mitigates forgetting without side effects.
Authors: We appreciate the referee's point on the need for supporting analysis. In the revised §3.2, we have incorporated additional equations and analysis showing that the Retention Reward is designed as a bounded additive term that does not override the task-specific reward, thereby preserving plasticity and forward transfer. For CTAN, we provide a derivation illustrating its stability properties across varying reward scales. Furthermore, we have included new experimental results measuring forward transfer and optimization metrics like variance in advantages to demonstrate the absence of negative side effects. revision: yes
Circularity Check
No significant circularity; empirical motivation and independent evaluation
full rationale
The paper's central chain begins with a pilot empirical observation that KL divergence varies among equal-reward rollouts and correlates with forgetting. It then defines an explicit Retention Reward to convert that KL into an additive signal and adds CTAN for cross-task normalization. These are not self-definitional or fitted-input predictions: the forgetting metric remains an independent downstream measurement, and final claims rest on benchmark results across five settings rather than reducing by construction to the pilot correlation or any self-citation. No uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results appear. The procedure is a testable hypothesis with separate validation, qualifying as self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Policy optimization under task rewards improves performance on the current task while the added retention term preserves prior behavior.
- domain assumption Exponential moving average of reward statistics remains stable and useful across task boundaries.
invented entities (2)
-
Retention Reward
no independent evidence
-
Cross-Task Advantage Normalization (CTAN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1.5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen Team. Qwen3.5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827, 2025
-
[6]
Leveraging verifier-based reinforcement learning in image editing
Hanzhong Guo, Jie Wu, Jie Liu, Yu Gao, Zilyu Ye, Linxiao Yuan, Xionghui Wang, Yizhou Yu, and Weilin Huang. Leveraging verifier-based reinforcement learning in image editing. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025
work page 2025
-
[9]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Visual-rft: Visual reinforcement fine-tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2034–2044, 2025
work page 2034
-
[11]
To think or not to think: A study of thinking in rule-based visual reinforcement fine-tuning
Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Haoquan Zhang, Wang Bill Zhu, and Kaipeng Zhang. To think or not to think: A study of thinking in rule-based visual reinforcement fine-tuning. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[12]
Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Xiansheng Chen, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[13]
Hulingxiao He, Zijun Geng, and Yuxin Peng. Fine-r1: Make multi-modal llms excel in fine-grained visual recognition by chain-of-thought reasoning. InInternational Conference on Learning Representations, 2026
work page 2026
-
[14]
A survey on ensemble learning for data stream classification.ACM Computing Surveys, 50(2):1–36, 2017
Heitor Murilo Gomes, Jean Paul Barddal, Fabrício Enembreck, and Albert Bifet. A survey on ensemble learning for data stream classification.ACM Computing Surveys, 50(2):1–36, 2017
work page 2017
-
[15]
Towards lifelong learning of large language models: A survey.ACM Computing Surveys, 57(8):1–35, 2025
Junhao Zheng, Shengjie Qiu, Chengming Shi, and Qianli Ma. Towards lifelong learning of large language models: A survey.ACM Computing Surveys, 57(8):1–35, 2025
work page 2025
-
[16]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
work page 2025
-
[17]
Yutao Yang, Jie Zhou, Xuanwen Ding, Tianyu Huai, Shunyu Liu, Qin Chen, Yuan Xie, and Liang He. Recent advances of foundation language models-based continual learning: A survey.ACM Computing Surveys, 57(5):1–38, 2025. 20
work page 2025
-
[18]
Continual instruction tuning for large multimodal models.IEEE Transactions on Image Processing, 2026
Jinghan He, Haiyun Guo, Kuan Zhu, Ming Tang, and Jinqiao Wang. Continual instruction tuning for large multimodal models.IEEE Transactions on Image Processing, 2026
work page 2026
-
[19]
Reinforcement fine-tuning naturally mitigates forgetting in continual post-training, 2025
Song Lai, Haohan Zhao, Rong Feng, Changyi Ma, Wenzhuo Liu, Hongbo Zhao, Xi Lin, Dong Yi, Qingfu Zhang, Hongbin Liu, et al. Reinforcement fine-tuning naturally mitigates forgetting in continual post-training.arXiv preprint arXiv:2507.05386, 2025
-
[20]
RL’s razor: Why online reinforcement learning forgets less
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. RL’s razor: Why online reinforcement learning forgets less. InInternational Conference on Learning Representations, 2026
work page 2026
-
[21]
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Class-incremental learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9851–9873, 2024
work page 2024
-
[22]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
work page 2024
-
[23]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8349, 2021
work page 2021
-
[24]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Hel- yar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[28]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[29]
Safe rlhf: Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback. InInternational Conference on Learning Representations, 2024
work page 2024
-
[30]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling, 2025
work page 2025
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Onethinker: All-in-one reasoning model for image and video
Kaituo Feng, Manyuan Zhang, Hongyu Li, Kaixuan Fan, Shuang Chen, Yilei Jiang, Dian Zheng, Peiwen Sun, Yiyuan Zhang, Haoze Sun, et al. Onethinker: All-in-one reasoning model for image and video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
-
[34]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 139–149, 2022
work page 2022
-
[35]
Da-Wei Zhou, Zi-Wen Cai, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 133(3):1012–1032, 2025. 21
work page 2025
-
[36]
Yabin Wang, Zhiwu Huang, and Xiaopeng Hong. S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning.Advances in Neural Information Processing Systems, 35:5682–5695, 2022
work page 2022
-
[37]
Non-exemplar domain incremental learning via cross-domain concept integration
Qiang Wang, Yuhang He, Songlin Dong, Xinyuan Gao, Shaokun Wang, and Yihong Gong. Non-exemplar domain incremental learning via cross-domain concept integration. InEuropean Conference on Computer Vision, pages 144–162. Springer, 2024
work page 2024
-
[38]
Continual learning with pre-trained models: a survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, and De-Chuan Zhan. Continual learning with pre-trained models: a survey. InInternational Joint Conference on Artificial Intelligence, pages 8363–8371, 2024
work page 2024
-
[39]
Scaling continual learning to 300+ tasks with bi-level routing mixture-of-experts
Meng Lou, Yunxiang Fu, and Yizhou Yu. Scaling continual learning to 300+ tasks with bi-level routing mixture-of-experts. InInternational Conference on Machine Learning, 2026
work page 2026
-
[40]
Inflora: Interference-free low-rank adaptation for continual learning
Yan-Shuo Liang and Wu-Jun Li. Inflora: Interference-free low-rank adaptation for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23638– 23647, 2024
work page 2024
-
[41]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23219–23230, 2024
work page 2024
-
[42]
Yan Wang, Da-Wei Zhou, and Han-Jia Ye. Integrating task-specific and universal adapters for pre-trained model-based class-incremental learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 806–816, 2025
work page 2025
-
[43]
Mos: Model surgery for pre-trained model-based class-incremental learning
Hai-Long Sun, Da-Wei Zhou, Hanbin Zhao, Le Gan, De-Chuan Zhan, and Han-Jia Ye. Mos: Model surgery for pre-trained model-based class-incremental learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20699–20707, 2025
work page 2025
-
[44]
Dual consolidation for pre- trained model-based domain-incremental learning
Da-Wei Zhou, Zi-Wen Cai, Han-Jia Ye, Lijun Zhang, and De-Chuan Zhan. Dual consolidation for pre- trained model-based domain-incremental learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20547–20557, 2025
work page 2025
-
[45]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
work page 2021
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[47]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representations, 2024
work page 2024
-
[48]
arXiv preprint arXiv:2602.12125 , year=
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
-
[49]
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15262–15271, 2021
work page 2021
-
[50]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Yann Le, Xuan Yang, et al. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
work page 2015
-
[51]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
work page 2011
-
[52]
Jinghua Zhang, Li Liu, Olli Silvén, Matti Pietikäinen, and Dewen Hu. Few-shot class-incremental learning for classification and object detection: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4):2924–2945, 2025
work page 2025
-
[53]
Riemannian walk for incremental learning: Understanding forgetting and intransigence
Arslan Chaudhry, Puneet K Dokania, Thalaiyasingam Ajanthan, and Philip HS Torr. Riemannian walk for incremental learning: Understanding forgetting and intransigence. InProceedings of the European Conference on Computer Vision, pages 532–547, 2018. 22
work page 2018
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
work page 2017
-
[56]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2017
work page 2017
-
[57]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean Conference on Computer Vision, pages 740–755. Springer, 2014
work page 2014
-
[58]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017
work page 2017
-
[59]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[60]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification
Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. InProceedings of the European conference on computer vision (ECCV), pages 305–321, 2018
work page 2018
-
[62]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
work page 2019
-
[63]
Deep hashing network for unsupervised domain adaptation
Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5018–5027, 2017
work page 2017
-
[64]
Cross-domain weakly- supervised object detection through progressive domain adaptation
Naoto Inoue, Ryosuke Furuta, Toshihiko Yamasaki, and Kiyoharu Aizawa. Cross-domain weakly- supervised object detection through progressive domain adaptation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 2018
work page 2018
-
[65]
Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective.International Journal of Computer Vision, 111(1):98–136, 2015
work page 2015
-
[66]
Three types of incremental learning.Nature Machine Intelligence, 4(12):1185–1197, 2022
Gido M Van de Ven, Tinne Tuytelaars, and Andreas S Tolias. Three types of incremental learning.Nature Machine Intelligence, 4(12):1185–1197, 2022
work page 2022
-
[67]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision, pages 213–229, 2020
work page 2020
-
[68]
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347, 2025. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.