Recognition: 3 theorem links
· Lean TheoremASACK : Adaptive Safe Active Continual Koopman Learning for Uncertain Systems with Contractive Guarantees
Pith reviewed 2026-05-12 03:40 UTC · model grok-4.3
The pith
An autoencoder-based Koopman model can be continually refined online using a contractive adaptation law that ensures convergence and safety for uncertain systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating a contractive adaptation law with active learning and robust MPC in a nonconvex optimization allows safe and efficient online refinement of Koopman models under uncertainty, unifying learning, data collection, and control with theoretical convergence guarantees and error bounds that preserve real-time feasibility.
What carries the argument
The contractive adaptation law for the autoencoder-based Koopman model, which provides convergence guarantees and is combined with active learning to collect informative data and robust MPC for safety.
If this is right
- Robots can adapt their dynamics models online while completing tasks and maintaining safety guarantees.
- Model approximation errors are bounded and used to ensure robust safety in the controller.
- The active learning strategy improves data efficiency for faster adaptation under shifts.
- The framework maintains real-time feasibility for deployment on physical robotic systems.
- Convergence is guaranteed theoretically even with distributional shifts and model uncertainty.
Where Pith is reading between the lines
- Similar contractive laws might be developed for other lifted linear models beyond Koopman operators.
- The approach could be tested in scenarios with sudden environmental changes like terrain shifts for mobile robots.
- Integrating this with multi-agent systems might allow cooperative model learning across robots.
- Future work could explore reducing the computational cost of the nonconvex solver for even tighter real-time constraints.
Load-bearing premise
That a contractive adaptation law can be designed to guarantee convergence of the autoencoder-based Koopman model under arbitrary distributional shifts and model uncertainty while remaining compatible with real-time non-convex optimization and safety constraints.
What would settle it
Observing divergence of the model parameters, violation of safety constraints, or failure to meet real-time computation limits during an experiment with a significant distributional shift.
Figures



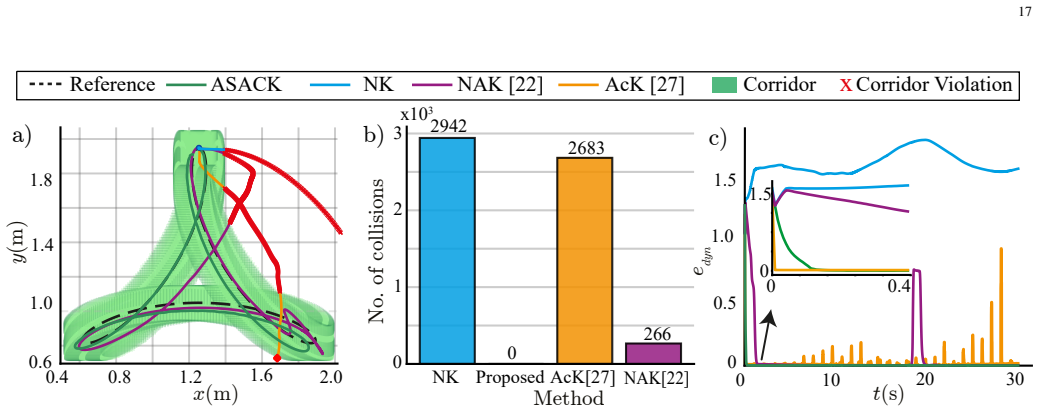

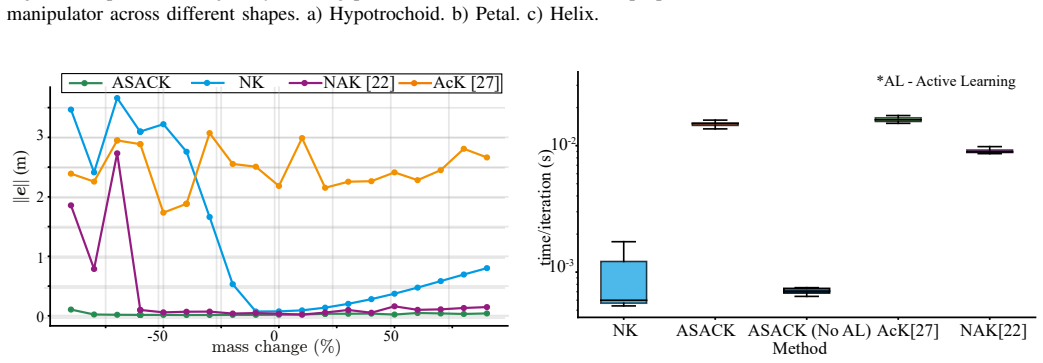




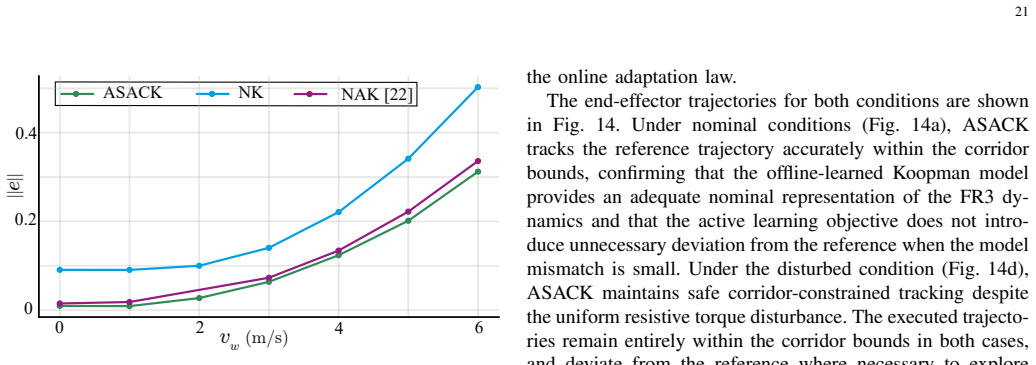




read the original abstract
Koopman operator theory provides a powerful framework for representing nonlinear dynamics through a linear operator acting on lifted observables, enabling the use of linear control techniques for nonlinear systems. However, Koopman models are typically learned from data and often degrade in performance under model uncertainty and distributional shifts between training and deployment. Although several works have explored online adaptation to address this issue, many rely on neural network-based updates that introduce significant computational overhead and lack formal safety guarantees, limiting their suitability for real-time and safety-critical robotic applications. In this work, we propose a unified framework for continual adaptive Koopman learning that enables safe and efficient online refinement of learned models during task execution. An autoencoder-based Koopman model is first learned offline and subsequently refined online through a contractive adaptation law, which provides theoretical convergence guarantees under distributional shifts and model uncertainty. To improve data efficiency and accelerate model refinement, the adaptation mechanism is integrated with an active learning strategy that drives the system to collect informative data while accomplishing task objectives. The resulting control problem is formulated as a nonconvex optimization problem incorporating both active learning objectives and safety constraints. We further derive theoretical bounds on model approximation error and show how these bounds can be incorporated within a robust Model Predictive Control (MPC) framework to provide formal safety guarantees. The proposed approach unifies learning, excitation, and safety within a single control framework without sacrificing real-time feasibility. Extensive simulation and experimental studies demonstrate superior performance compared to state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ASACK, a unified framework for continual adaptive Koopman learning in uncertain robotic systems. An autoencoder-based Koopman model is learned offline and refined online via a contractive adaptation law claimed to guarantee convergence under distributional shifts and model uncertainty. This is combined with an active learning strategy to collect informative data, formulated as a non-convex MPC problem that jointly optimizes task performance, excitation, and safety constraints. Theoretical bounds on model approximation error are derived and incorporated into a robust MPC scheme for formal safety guarantees. The approach is asserted to maintain real-time feasibility, with simulation and experimental results showing superior performance over baselines.
Significance. If the central theoretical claims hold, particularly the contractive guarantees persisting under closed-loop active learning and the error bounds enabling robust safety, the work would advance safe deployment of learned Koopman models for nonlinear systems with uncertainty. The unification of adaptation, active excitation, and robust MPC is a notable strength, as is the emphasis on real-time feasibility for robotic applications. Credit is due for attempting to provide explicit convergence analysis and error bounds rather than relying solely on empirical adaptation.
major comments (2)
- [§3.2 and §4] §3.2 (Contractive Adaptation Law) and §4 (Active Learning MPC formulation): The convergence of the adaptation law is presented as providing theoretical guarantees under distributional shifts. However, the proof appears to rely on persistence-of-excitation conditions that may not hold when the excitation signal is generated endogenously by the non-convex MPC optimizer (which also enforces safety constraints and task objectives). The closed-loop coupling, particularly when robust tube tightening becomes active, risks violating the conditions needed for contraction; a dedicated re-derivation or Lyapunov analysis for the coupled system is required to support the abstract's claims.
- [§5] §5 (Robust MPC with error bounds): The derivation of model approximation error bounds and their incorporation into the robust MPC is load-bearing for the safety guarantees. Please clarify the specific theorem or equation where the bounds are obtained (e.g., via the autoencoder reconstruction or Koopman residual) and exactly how they translate into constraint tightening or tube radii in the MPC optimization; without this explicit link, the formal safety claims remain incompletely substantiated.
minor comments (2)
- [Abstract] Abstract: The claim of 'superior performance' would benefit from a brief quantitative summary (e.g., average tracking error reduction or success rate) rather than a qualitative statement.
- [Notation and §3] Notation: Ensure the lifted state dimension and the specific form of the contractive update (e.g., the gain or projection operator) are defined consistently when first introduced and reused in the MPC section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the theoretical foundations of our work. We address each major comment below and have revised the manuscript to provide additional analysis and clarifications as needed.
read point-by-point responses
-
Referee: [§3.2 and §4] §3.2 (Contractive Adaptation Law) and §4 (Active Learning MPC formulation): The convergence of the adaptation law is presented as providing theoretical guarantees under distributional shifts. However, the proof appears to rely on persistence-of-excitation conditions that may not hold when the excitation signal is generated endogenously by the non-convex MPC optimizer (which also enforces safety constraints and task objectives). The closed-loop coupling, particularly when robust tube tightening becomes active, risks violating the conditions needed for contraction; a dedicated re-derivation or Lyapunov analysis for the coupled system is required to support the abstract's claims.
Authors: We agree that the original proof in §3.2 establishes contraction under persistence-of-excitation (PE) assumptions that are standard for open-loop adaptation but require careful verification in the closed-loop setting. The active learning MPC in §4 is designed to generate endogenous excitation while respecting safety, which could interact with tube tightening. In the revised manuscript, we have added a new Lyapunov analysis subsection following §4 that explicitly considers the coupled system. We show that the active excitation term maintains a minimum level of PE even under worst-case robust tightening, and the contractive adaptation law remains valid with a modified contraction rate that accounts for the bounded disturbance from the MPC. This re-derivation supports the abstract claims without altering the core algorithm. revision: yes
-
Referee: [§5] §5 (Robust MPC with error bounds): The derivation of model approximation error bounds and their incorporation into the robust MPC is load-bearing for the safety guarantees. Please clarify the specific theorem or equation where the bounds are obtained (e.g., via the autoencoder reconstruction or Koopman residual) and exactly how they translate into constraint tightening or tube radii in the MPC optimization; without this explicit link, the formal safety claims remain incompletely substantiated.
Authors: The error bounds are obtained in Theorem 3 of §5, which combines the autoencoder reconstruction error with the Koopman residual under the assumed Lipschitz continuity of the underlying dynamics. These bounds directly determine the tube radii via Equation (12), where the tightening parameter is set to the supremum of the error bound over the prediction horizon to ensure robust constraint satisfaction. We have expanded the text in the revised §5 with an explicit step-by-step mapping from Theorem 3 to the MPC tightening radii, including a numerical example illustrating the translation. This makes the link between the approximation error and the safety guarantees fully transparent. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe an offline-learned autoencoder Koopman model refined via a contractive adaptation law, integrated with active learning in a nonconvex MPC, and with derived error bounds for robust control. No equations, self-citations, or explicit reductions are visible that would make any claimed prediction or guarantee equivalent to its inputs by construction. The adaptation law and bounds are presented as independently derived theoretical results rather than fits renamed as predictions or ansatzes smuggled via self-reference. The derivation chain appears self-contained against external benchmarks, with no load-bearing steps reducing to tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Nonlinear system dynamics admit a finite-dimensional Koopman approximation via an autoencoder that can be refined online.
- ad hoc to paper A contractive adaptation law exists that guarantees convergence of the model error under model uncertainty and distributional shifts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; Jcost_pos_of_ne_one echoesEk+1 = Ek(I−ηGk) + Δk … ∥Ek+1∥F ≤ ρ∥Ek∥F + ν … lim sup ∥Ek∥F ≤ ν/(1−ρ) (Theorem 1)
-
IndisputableMonolith/Foundation/BranchSelection.leanRCLCombiner_isCoupling_iff; branch_selection unclearJinfo := log det(Ĝk + εI) … D-optimal active learning objective
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff; alpha_pin_under_high_calibration unclearδ+k := vmax Ēk (1 + η vmax √w) … CBF constraint h(xnomk+1) ≥ (1−α)h(xk) + Lh δk
Reference graph
Works this paper leans on
-
[1]
Foundations of chemical reaction network theory,
M. Feinberg, “Foundations of chemical reaction network theory,” 2019
work page 2019
-
[2]
P. Mendes and D. Kell, “Non-linear optimization of biochemical path- ways: applications to metabolic engineering and parameter estimation.,” Bioinformatics (Oxford, England), vol. 14, no. 10, pp. 869–883, 1998
work page 1998
-
[3]
Inference for nonlin- ear epidemiological models using genealogies and time series,
D. A. Rasmussen, O. Ratmann, and K. Koelle, “Inference for nonlin- ear epidemiological models using genealogies and time series,”PLoS computational biology, vol. 7, no. 8, p. e1002136, 2011
work page 2011
-
[4]
Filtering for nonlinear genetic regulatory networks with stochastic disturbances,
Z. Wang, J. Lam, G. Wei, K. Fraser, and X. Liu, “Filtering for nonlinear genetic regulatory networks with stochastic disturbances,” IEEE Transactions on Automatic Control, vol. 53, no. 10, pp. 2448– 2457, 2008
work page 2008
-
[5]
S. H. Strogatz,Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering. CRC press, 2018
work page 2018
-
[6]
Ogataet al.,Modern control engineering, vol
K. Ogataet al.,Modern control engineering, vol. 5. Prentice hall Upper Saddle River, NJ, 2010
work page 2010
-
[7]
Hamiltonian systems and transformation in hilbert space,
B. O. Koopman, “Hamiltonian systems and transformation in hilbert space,”Proceedings of the National Academy of Sciences, vol. 17, no. 5, pp. 315–318, 1931
work page 1931
-
[8]
M. Korda and I. Mezi ´c, “Linear predictors for nonlinear dynamical sys- tems: Koopman operator meets model predictive control,”Automatica, vol. 93, pp. 149–160, 2018
work page 2018
-
[9]
Data-driven discovery of coordinates and governing equations,
K. Champion, B. Lusch, J. N. Kutz, and S. L. Brunton, “Data-driven discovery of coordinates and governing equations,”Proceedings of the National Academy of Sciences, vol. 116, no. 45, pp. 22445–22451, 2019
work page 2019
-
[10]
Q. Li, F. Dietrich, E. M. Bollt, and I. G. Kevrekidis, “Extended dynamic mode decomposition with dictionary learning: A data-driven adaptive spectral decomposition of the koopman operator,”Chaos: An Interdisci- plinary Journal of Nonlinear Science, vol. 27, no. 10, p. 103111, 2017
work page 2017
-
[11]
Deep learning for universal linear embeddings of nonlinear dynamics,
B. Lusch, J. N. Kutz, and S. L. Brunton, “Deep learning for universal linear embeddings of nonlinear dynamics,”Nature communications, vol. 9, no. 1, p. 4950, 2018
work page 2018
-
[12]
Modern Koop- man Theory for Dynamical Systems,
S. L. Brunton, M. Budi ˇsi´c, E. Kaiser, and J. N. Kutz, “Modern koopman theory for dynamical systems,”arXiv preprint arXiv:2102.12086, 2021
-
[13]
C. K. Sah, R. Singh, and J. Keshavan, “Real-time constrained tracking control of redundant manipulators using a koopman-zeroing neural network framework,”IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 1732–1739, 2024
work page 2024
-
[14]
General- ized momenta-based koopman formalism for robust control of euler- lagrangian systems,
R. Singh, A. Singh, C. S. Kashyap, and J. Keshavan, “General- ized momenta-based koopman formalism for robust control of euler- lagrangian systems,”arXiv preprint arXiv:2509.17010, 2025
-
[15]
Data-driven control of soft robots using koopman operator theory,
D. Bruder, X. Fu, R. B. Gillespie, C. D. Remy, and R. Vasudevan, “Data-driven control of soft robots using koopman operator theory,” IEEE transactions on robotics, vol. 37, no. 3, pp. 948–961, 2020
work page 2020
-
[16]
A koopman-based residual modeling approach for the control of a soft robot arm,
D. Bruder, D. Bombara, and R. J. Wood, “A koopman-based residual modeling approach for the control of a soft robot arm,”The International journal of robotics research, vol. 44, no. 3, pp. 388–406, 2025
work page 2025
-
[17]
Koopman operator based modeling for quadrotor control on se (3),
V . Zinage and E. Bakolas, “Koopman operator based modeling for quadrotor control on se (3),”IEEE Control Systems Letters, vol. 6, pp. 752–757, 2021
work page 2021
-
[18]
C. Folkestad, S. X. Wei, and J. W. Burdick, “Koopnet: Joint learning of koopman bilinear models and function dictionaries with application to quadrotor trajectory tracking,” in2022 International Conference on Robotics and Automation (ICRA), pp. 1344–1350, IEEE, 2022
work page 2022
-
[19]
Koopman-lqr controller for quadrotor uavs from data,
Z. M. Manaa, A. M. Abdallah, M. A. Abido, and S. S. A. Ali, “Koopman-lqr controller for quadrotor uavs from data,” in2024 IEEE International Conference on Smart Mobility (SM), pp. 153–158, IEEE, 2024
work page 2024
-
[20]
Modeling quadruped leg dynamics on deformable terrains using data-driven koopman operators,
A. Krolicki, D. Rufino, A. Zheng, S. S. Narayanan, J. Erb, and U. Vaidya, “Modeling quadruped leg dynamics on deformable terrains using data-driven koopman operators,”IFAC-PapersOnLine, vol. 55, no. 37, pp. 420–425, 2022
work page 2022
-
[21]
Koopman operator based linear model predictive control for quadruped trotting,
C.-M. Yang and P. A. Bhounsule, “Koopman operator based linear model predictive control for quadruped trotting,” in2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 12359–12364, IEEE, 2025
work page 2025
-
[22]
Adaptive koopman embedding for robust control of nonlinear dynamical systems,
R. Singh, C. K. Sah, and J. Keshavan, “Adaptive koopman embedding for robust control of nonlinear dynamical systems,”The International Journal of Robotics Research, vol. 44, no. 13, pp. 2235–2261, 2025
work page 2025
-
[23]
Model predictive control of nonlinear dynamics using online adaptive koopman operators,
D. Uchida and K. Duraisamy, “Model predictive control of nonlinear dynamics using online adaptive koopman operators,”arXiv preprint arXiv:2412.02972, 2024
-
[24]
Continual learning and lifting of koopman dynamics for linear control of legged robots,
F. Li, A. Abuduweili, Y . Sun, R. Chen, W. Zhao, and C. Liu, “Continual learning and lifting of koopman dynamics for linear control of legged robots,”arXiv preprint arXiv:2411.14321, 2024
-
[25]
M. Selim, S. Bhat, and K. H. Johansson, “Metakoopman: Bayesian meta- learning of koopman operators for modeling structured dynamics under distribution shifts,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[26]
Event-based adaptive koopman framework for optic flow-guided landing on moving platforms,
B. Banday, C. K. Sah, and J. Keshavan, “Event-based adaptive koopman framework for optic flow-guided landing on moving platforms,”arXiv preprint arXiv:2501.16868, 2025
-
[27]
Active learning of dynamics for data-driven control using koopman operators,
I. Abraham and T. D. Murphey, “Active learning of dynamics for data-driven control using koopman operators,”IEEE Transactions on Robotics, vol. 35, no. 5, pp. 1071–1083, 2019
work page 2019
- [28]
-
[29]
Gcontrol-aware learning of koopman embedding models a koopman spectral approach,
D. Goswami and D. A. Paley, “Gcontrol-aware learning of koopman embedding models a koopman spectral approach,” in2017 IEEE 56th Annual Conference on Decision and Control (CDC), pp. 6107–6112, IEEE, 2017
work page 2017
- [30]
-
[31]
acados – a modular open-source framework for fast embedded optimal control,
R. Verschueren, G. Frison, D. Kouzoupis, J. Frey, N. van Duijkeren, A. Zanelli, B. Novoselnik, T. Albin, R. Quirynen, and M. Diehl, “acados – a modular open-source framework for fast embedded optimal control,” Mathematical Programming Computation, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.