Recognition: 2 theorem links
· Lean TheoremDeepTumorVQA: A Hierarchical 3D CT Benchmark for Stage-Wise Evaluation of Medical VLMs and Tool-Augmented Agents
Pith reviewed 2026-05-12 03:58 UTC · model grok-4.3
The pith
A hierarchical benchmark reveals that accurate measurement is the main barrier for medical vision-language models analyzing 3D CT tumor scans, with tool augmentation providing substantial relief.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
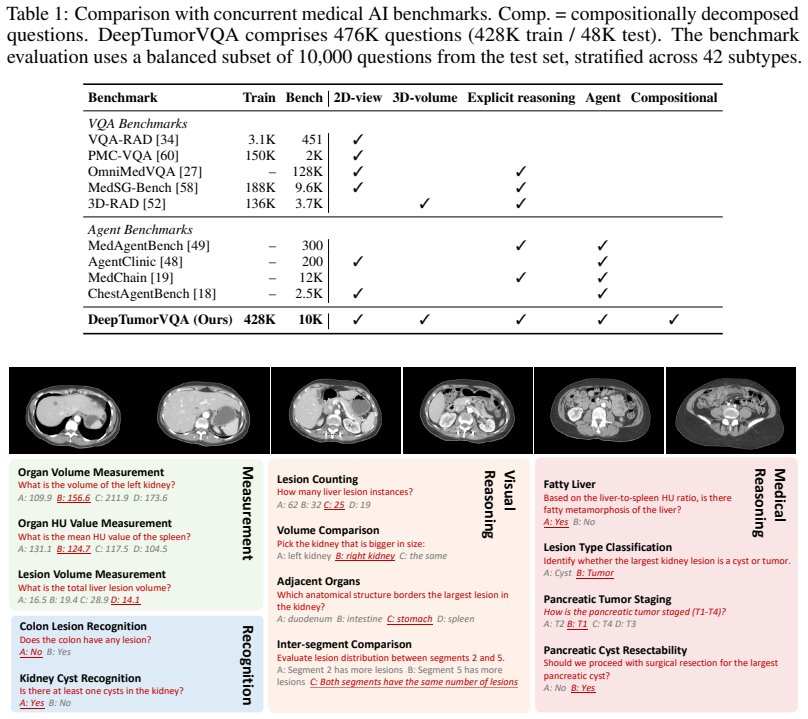
DeepTumorVQA decomposes 3D CT tumor diagnosis into four stages—recognition, measurement, visual reasoning, and medical reasoning—with 476,000 questions across 42 subtypes on over 9,000 volumes. Ground-truth evidence chains link the stages so higher questions can be scored independently. Experiments across more than 30 model configurations demonstrate that quantitative measurement forms the primary bottleneck for VLMs in direct reasoning mode. Tool-augmented agents that call segmentation models, measurement programs, and knowledge modules achieve better results, and supervised tool-use traces further reduce errors.
What carries the argument
The hierarchical four-stage evidence chain for tumor diagnosis, supported by tool-interaction environments that let agents call external segmentation, measurement, and knowledge tools.
Load-bearing premise
The four stages accurately capture independent steps in real clinical tumor diagnosis workflows, and the automatically generated questions and annotations do not contain systematic biases that would skew the results.
What would settle it
Running the same models on a version of the benchmark where measurement ground truth is provided directly as input, and finding no improvement in later-stage reasoning accuracy, would show that measurement is not the primary bottleneck.
Figures





read the original abstract
Medical vision-language models (VLMs) and AI agents have made significant progress in learning to analyze and reason about clinical images. However, existing medical visual question answering (VQA) benchmarks collapse model capabilities into a single accuracy score, obscuring where and why models fail. We propose DeepTumorVQA, a hierarchical benchmark that follows the multi-stage evidence chain in tumor diagnosis and decomposes 3D CT reasoning into four stages: recognition, measurement, visual reasoning, and medical reasoning. Higher-level questions remain independently scorable, while their ground-truth evidence chains are defined over lower-level primitives. The benchmark contains 476K questions across 42 clinical subtypes on 9,262 3D CT volumes. In addition to a direct reasoning mode for VLMs, DeepTumorVQA provides tool-interaction environments for agent evaluation, where a model can call external tools, including segmentation models, measurement programs, and medical knowledge modules, before answering the question. Evaluating over 30 model configurations, we find that reliable quantitative measurement is the primary bottleneck, making later-stage visual and medical reasoning harder for VLMs, while tool augmentation substantially mitigates this issue. When tools are available, leveraging medical knowledge and tools to reason about medical images becomes a new challenge. We further show that ground-truth step-by-step tool-use traces from DeepTumorVQA can supervise agents and reduce tool-use and reasoning failures. This stage-wise progression from recognition to measurement to visual and medical reasoning provides a concrete roadmap for future medical VLM and AI agent studies. All data and code are released at https://github.com/Schuture/DeepTumorVQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeepTumorVQA, a hierarchical 3D CT VQA benchmark that decomposes tumor diagnosis into four stages (recognition, measurement, visual reasoning, medical reasoning) with independently scorable higher-level questions whose ground-truth evidence chains build on lower-level primitives. It generates 476K questions across 42 subtypes from 9,262 volumes, supports both direct VLM evaluation and tool-augmented agent environments (with segmentation, measurement, and knowledge tools), and evaluates over 30 model configurations to conclude that quantitative measurement is the primary bottleneck while tool augmentation substantially mitigates it; ground-truth tool-use traces are also released for agent supervision.
Significance. If the four-stage decomposition is a faithful model of clinical workflows, the benchmark provides a valuable, actionable roadmap for medical VLM and agent development by isolating specific failure points rather than collapsing performance into a single score. Strengths include the large scale, release of code and data for reproducibility, extensive empirical testing across model configurations, and the provision of tool-interaction environments that enable falsifiable comparisons of direct vs. augmented reasoning.
major comments (1)
- [Benchmark construction] Benchmark construction (implied in §3 and abstract): limited detail is provided on the question generation pipeline, annotation validation procedures (e.g., inter-annotator agreement or expert review), and potential selection effects or biases across the 42 subtypes. Because the central claim—that measurement is the primary bottleneck and tools mitigate later-stage failures—rests on the stages forming a valid, unbiased evidence chain matching real clinical tumor diagnosis, explicit validation metrics or sensitivity analyses for these aspects are needed to confirm the reported accuracy patterns are not artifacts of question design.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. We appreciate the focus on benchmark construction and will revise the manuscript to provide greater transparency on the question generation process, validation steps, and potential biases.
read point-by-point responses
-
Referee: Benchmark construction (implied in §3 and abstract): limited detail is provided on the question generation pipeline, annotation validation procedures (e.g., inter-annotator agreement or expert review), and potential selection effects or biases across the 42 subtypes. Because the central claim—that measurement is the primary bottleneck and tools mitigate later-stage failures—rests on the stages forming a valid, unbiased evidence chain matching real clinical tumor diagnosis, explicit validation metrics or sensitivity analyses for these aspects are needed to confirm the reported accuracy patterns are not artifacts of question design.
Authors: We agree that expanding the description of benchmark construction will strengthen the paper. In the revised §3 we will add a detailed account of the question generation pipeline: questions are programmatically derived from expert-annotated 3D CT volumes and tumor masks in the source public datasets (with the four-stage hierarchy explicitly encoded so that higher-level questions reference lower-level primitives). Because generation is deterministic and rule-based from these existing annotations, traditional inter-annotator agreement on the VQA pairs themselves is not applicable; we will clarify this and note that the underlying CT annotations follow standard radiological protocols. To address potential selection effects, we will include (i) the exact subtype distribution across the 9,262 volumes, (ii) a sensitivity analysis showing that the measurement-bottleneck pattern holds when subsets of subtypes are held out, and (iii) a brief discussion of how the 42 subtypes were chosen to reflect clinical prevalence. These additions will make the evidence chain and its robustness explicit without altering the reported empirical findings. revision: yes
Circularity Check
No significant circularity
full rationale
The paper constructs a new hierarchical benchmark (DeepTumorVQA) with 476K questions across four explicitly defined stages and reports empirical performance of external VLMs and agents on those questions. The central claim—that quantitative measurement is the primary bottleneck and tool augmentation mitigates it—follows directly from observed accuracy patterns and deltas on independently scored questions, with no internal parameters fitted to the target results, no self-referential definitions, and no load-bearing self-citations that reduce the findings to prior author work by construction. The stage decomposition is a design choice whose validity is an external assumption, not a circular derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tumor diagnosis in 3D CT follows a multi-stage evidence chain from recognition through measurement to visual and medical reasoning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decomposes 3D CT reasoning into four stages: recognition, measurement, visual reasoning, and medical reasoning
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reliable quantitative measurement is the primary bottleneck
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
3dland: 3d lesion abdominal anomaly localization dataset.arXiv preprint arXiv:2602.12820, 2026
Mehran Advand, Zahra Dehghanian, Navid Faraji, Reza Barati, Seyed Amir Ahmad Safavi- Naini, and Hamid R Rabiee. 3dland: 3d lesion abdominal anomaly localization dataset.arXiv preprint arXiv:2602.12820, 2026
-
[2]
Nnenaya Agochukwu, Steffen Huber, Michael Spektor, Alexander Goehler, and Gary M Israel. Differentiating renal neoplasms from simple cysts on contrast-enhanced ct on the basis of attenuation and homogeneity.American Journal of Roentgenology, 208(4):801–804, 2017
work page 2017
-
[3]
Cystic lesions of the pancreas.Annals of Surgery, 254:680–686, 2011
Peter J Allen, Michael D’Angelica, Mithat Gonen, David P Jaques, Daniel G Coit, William R Jarnagin, Ronald DeMatteo, Yuman Fong, Leslie H Blumgart, and Murray F Brennan. Cystic lesions of the pancreas.Annals of Surgery, 254:680–686, 2011
work page 2011
-
[4]
Medagentsim: Self-evolving multi-agent simulations for realistic clinical interactions
Mohammad Almansoori, Komal Kumar, and Hisham Cholakkal. Medagentsim: Self-evolving multi-agent simulations for realistic clinical interactions. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 362–372. Springer, 2025
work page 2025
-
[5]
Ajcc cancer staging manual, 2017
American Joint Committee on Cancer. Ajcc cancer staging manual, 2017
work page 2017
-
[6]
The medical segmentation decathlon.arXiv preprint arXiv:2106.05735, 2021
Michela Antonelli, Annika Reinke, Spyridon Bakas, Keyvan Farahani, Bennett A Landman, Geert Litjens, Bjoern Menze, Olaf Ronneberger, Ronald M Summers, Bram van Ginneken, et al. The medical segmentation decathlon.arXiv preprint arXiv:2106.05735, 2021
-
[7]
M3d:Ad- vancing 3d medical image analysis with multi-modal large language models
Fan Bai, Yuxin Du, Tiejun Huang, Max Q-H Meng, and Bo Zhao. M3d: Advancing 3d medical image analysis with multi-modal large language models.arXiv preprint arXiv:2404.00578, 2024
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Radgpt: Constructing 3d image-text tumor datasets.arXiv preprint arXiv:2501.04678, 2025
Pedro RAS Bassi, Mehmet Can Yavuz, Kang Wang, Xiaoxi Chen, Wenxuan Li, Sergio Decher- chi, Andrea Cavalli, Yang Yang, Alan Yuille, and Zongwei Zhou. Radgpt: Constructing 3d image-text tumor datasets.arXiv preprint arXiv:2501.04678, 2025
-
[10]
Arlindo Sprenger Bezerra, Giuseppe D’Ippolito, Luzia Akiko Frias, Mauro Ozaki, Jacob Szejnfeld, and Marcelo Fuchs. Determination of splenomegaly by ct: is there a place for a single measurement?American Journal of Roentgenology, 184(5):1510–1513, 2005
work page 2005
-
[11]
The liver tumor segmentation benchmark (lits).arXiv preprint arXiv:1901.04056, 2019
Patrick Bilic, Patrick Ferdinand Christ, Eugene V orontsov, Grzegorz Chlebus, Hao Chen, Qi Dou, Chi-Wing Fu, Xiao Han, Pheng-Ann Heng, Jürgen Hesser, et al. The liver tumor segmentation benchmark (lits).arXiv preprint arXiv:1901.04056, 2019
-
[12]
Merlin: A vision language foundation model for 3d computed tomography
Louis Blankemeier, Joseph Paul Cohen, Ashwin Kumar, Dave Van Veen, Syed Jamal Safdar Gardezi, Magdalini Paschali, Zhihong Chen, Jean-Benoit Delbrouck, Eduardo Reis, Cesar Truyts, et al. Merlin: A vision language foundation model for 3d computed tomography. Research Square, pages rs–3, 2024
work page 2024
-
[13]
Junying Chen, Ruyi Gui, Anningzhe Chi, Anqi Peng, Zhongzhi Zhang, Xiang Wan, et al. Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale. arXiv preprint arXiv:2406.19280, 2024
- [14]
-
[15]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[16]
Rsna 2023 abdominal trauma detection, 2023
Errol Colak, Hui-Ming Lin, Robyn Ball, Melissa Davis, Adam Flanders, Sabeena Jalal, Kirti Magudia, Brett Marinelli, Savvas Nicolaou, Luciano Prevedello, Jeff Rudie, George Shih, Maryam Vazirabad, and John Mongan. Rsna 2023 abdominal trauma detection, 2023. URL https://kaggle.com/competitions/rsna-2023-abdominal-trauma-detection
work page 2023
-
[17]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Medrax: Medical reasoning agent for chest x-ray
Adibvafa Eltawil, Fares Cheema, Yong Suk Paul Shin, Jonathan Rubin, Sheyang Chen, et al. Medrax: Medical reasoning agent for chest x-ray. InProceedings of the International Conference on Machine Learning, 2025
work page 2025
-
[19]
Jie Gao, Yuanyuan Chen, Guozheng Wang, Hongyi Li, Jianye Yang, et al. Medchain: Bridging the gap between llm agents and clinical practice through interactive sequential benchmarking. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[20]
Google DeepMind. Gemini 3 pro model card. Google DeepMind Model Card,
-
[21]
URL https://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-Pro-Model-Card.pdf
-
[22]
Medgemma: Our most capable open models for health ai de- velopment
Google Research. Medgemma: Our most capable open models for health ai de- velopment. Google Research Blog, 2025. URL https://research.google/blog/ medgemma-our-most-capable-open-models-for-health-ai-development/
work page 2025
-
[23]
Serkan Guneyli, Hakan Dogan, Omer Tarik Esengur, and Hur Hassoy. Computed tomography evaluation of pancreatic steatosis: correlation with covid-19 prognosis.Future Virology, 17(4): 231–237, 2022
work page 2022
-
[24]
Ibrahim Ethem Hamamci, Sezgin Er, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Dogan, Muhammed Furkan Dasdelen, Omer Faruk Durugol, Bastian Wittmann, Tamaz Amiranashvili, et al. Developing generalist foundation models from a multimodal dataset for 3d computed tomography.arXiv preprint arXiv:2403.17834, 2024
-
[25]
William P Harbin, Nicholas J Robert, and Joseph T Ferrucci Jr. Diagnosis of cirrhosis based on regional changes in hepatic morphology: a radiological and pathological analysis.Radiology, 135(2):273–283, 1980
work page 1980
-
[26]
Nicholas Heller, Sean McSweeney, Matthew Thomas Peterson, Sarah Peterson, Jack Rickman, Bethany Stai, Resha Tejpaul, Makinna Oestreich, Paul Blake, Joel Rosenberg, et al. An international challenge to use artificial intelligence to define the state-of-the-art in kidney and kidney tumor segmentation in ct imaging., 2020
work page 2020
-
[27]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[28]
Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170–22183, 2024
work page 2024
-
[29]
Yuanfeng Ji, Haotian Bai, Chongjian Ge, Jie Yang, Ye Zhu, Ruimao Zhang, Zhen Li, Lingyan Zhang, Wanling Ma, Xiang Wan, et al. Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation.Advances in Neural Information Processing Systems, 35:36722–36732, 2022
work page 2022
-
[30]
Yankai Jiang, Yujie Zhang, Peng Zhang, Yichen Li, Jintai Chen, Xiaoming Shi, and Shihui Zhen. Incentivizing tool-augmented thinking with images for medical image analysis.arXiv preprint arXiv:2512.14157, 2025. 11
-
[31]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
work page 2017
-
[32]
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeon- hoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
work page 2024
-
[33]
Yuji Kodama, Connie S Ng, Tsung-Teh Wu, Gregory D Ayers, Steven A Curley, Eddie K Abdalla, Jean-Nicolas Vauthey, and Chusilp Charnsangavej. Comparison of ct methods for determining the fat content of the liver.American Journal of Roentgenology, 188(5):1307–1312, 2007
work page 2007
-
[34]
Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge
Bennett Landman, Zhoubing Xu, J Igelsias, Martin Styner, T Langerak, and Arno Klein. Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge. InProc. MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge, volume 5, page 12, 2015
work page 2015
-
[35]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1): 1–10, 2018
work page 2018
-
[36]
Mmedagent: Learning to use medical tools with multi-modal agent
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, et al. Mmedagent: Learning to use medical tools with multi-modal agent. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760, 2024
work page 2024
-
[37]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36: 28541–28564, 2023
work page 2023
-
[39]
Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning
Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan L Yuille. Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14963–14973, 2023
work page 2023
-
[40]
Clevr-ref+: Diagnosing visual reasoning with referring expressions
Runtao Liu, Chenxi Liu, Yutong Bai, and Alan L Yuille. Clevr-ref+: Diagnosing visual reasoning with referring expressions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4185–4194, 2019
work page 2019
-
[41]
Word: Revisiting organs segmentation in the whole abdominal region
Xiangde Luo, Wenjun Liao, Jianghong Xiao, Tao Song, Xiaofan Zhang, Kang Li, Guotai Wang, and Shaoting Zhang. Word: Revisiting organs segmentation in the whole abdominal region. arXiv preprint arXiv:2111.02403, 2021
-
[42]
Jun Ma, Yao Zhang, Song Gu, Cheng Zhu, Cheng Ge, Yichi Zhang, Xingle An, Congcong Wang, Qiyuan Wang, Xin Liu, et al. Abdomenct-1k: Is abdominal organ segmentation a solved problem.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
work page 2021
-
[43]
Jun Ma, Yao Zhang, Song Gu, Xingle An, Zhihe Wang, Cheng Ge, Congcong Wang, Fan Zhang, Yu Wang, Yinan Xu, et al. Fast and low-gpu-memory abdomen ct organ segmentation: the flare challenge.Medical Image Analysis, 82:102616, 2022
work page 2022
-
[44]
Ct-agent: A multimodal-LLM agent for 3d CT radiology question answering, 2025
Yuren Mao, Wenyi Xu, Yuyang Qin, and Yunjun Gao. Ct-agent: a multimodal-llm agent for 3d ct radiology question answering.arXiv preprint arXiv:2505.16229, 2025
-
[45]
Nccn clinical practice guidelines in oncol- ogy: Pancreatic adenocarcinoma, 2024
National Comprehensive Cancer Network. Nccn clinical practice guidelines in oncol- ogy: Pancreatic adenocarcinoma, 2024. URL https://www.nccn.org/guidelines/ guidelines-detail?category=1&id=1455. 12
work page 2024
-
[46]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Blaine Rister, Darvin Yi, Kaushik Shivakumar, Tomomi Nobashi, and Daniel L Rubin. Ct-org, a new dataset for multiple organ segmentation in computed tomography.Scientific Data, 7(1): 1–9, 2020
work page 2020
-
[48]
Deeporgan: Multi-level deep convolutional networks for automated pancreas segmentation
Holger R Roth, Le Lu, Amal Farag, Hoo-Chang Shin, Jiamin Liu, Evrim B Turkbey, and Ronald M Summers. Deeporgan: Multi-level deep convolutional networks for automated pancreas segmentation. InInternational conference on medical image computing and computer- assisted intervention, pages 556–564. Springer, 2015
work page 2015
-
[49]
arXiv preprint arXiv:2405.07960 , year =
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Pontes Reis, Sheshank Yarlagadda, et al. Agentclinic: A multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
-
[50]
Jiang, Alex Grabowski, Aarav Chauhan, et al
Samuel Schmidgall, Baekjin Kim, Hyunjin Goh, Albert Q. Jiang, Alex Grabowski, Aarav Chauhan, et al. Medagentbench: Dataset for benchmarking llms as agents in medical applica- tions.NEJM AI, 2025
work page 2025
-
[51]
Bosniak classification of cystic renal masses, version 2019: an update proposal and needs assessment
Stuart G Silverman, Ivan Pedrosa, James H Ellis, Nicole M Hindman, Nicola Schieda, Andrew D Smith, Erick M Remer, Atul B Shinagare, Natalie E Curci, Lucia Manganaro, et al. Bosniak classification of cystic renal masses, version 2019: an update proposal and needs assessment. Radiology, 292(2):475–488, 2019
work page 2019
-
[52]
Revisions of international consensus fukuoka guidelines for the management of ipmn of the pancreas
Masao Tanaka, Carlos Fernández-del Castillo, V olkan Adsay, Suresh Chari, Massimo Falconi, Jin-Young Jang, Wataru Kimura, Philip Levy, Martha B Pitman, C Max Schmidt, et al. Revisions of international consensus fukuoka guidelines for the management of ipmn of the pancreas. Pancreatology, 12(3):183–197, 2012
work page 2012
-
[53]
3d-rad: A large-scale 3d radiology med-vqa dataset
Xiaoxiao Tang et al. 3d-rad: A large-scale 3d radiology med-vqa dataset. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[54]
Multi-modal learning from unpaired images: Application to multi-organ segmentation in ct and mri
Vanya V Valindria, Nick Pawlowski, Martin Rajchl, Ioannis Lavdas, Eric O Aboagye, Andrea G Rockall, Daniel Rueckert, and Ben Glocker. Multi-modal learning from unpaired images: Application to multi-organ segmentation in ct and mri. In2018 IEEE winter conference on applications of computer vision (WACV), pages 547–556. IEEE, 2018
work page 2018
-
[55]
Jakob Wasserthal, Hanns-Christian Breit, Manfred T Meyer, Maurice Pradella, Daniel Hinck, Alexander W Saez, Tobias Semler, Florian Stritzel, Martin Segeroth, and Joshy Josi. Totalseg- mentator: Robust segmentation of 104 anatomic structures in ct images.Radiology: Artificial Intelligence, 5(5):e230024, 2023
work page 2023
-
[56]
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data.arXiv preprint arXiv:2308.02463, 2023
-
[57]
Advancing multimodal medical capabilities of gemini.arXiv preprint arXiv:2405.03162, 2024
Lin Yang, Shawn Xu, Andrew Sellergren, Timo Kohlberger, Yuchen Zhou, Ira Ktena, Atilla Kiraly, Faruk Ahmed, Farhad Hormozdiari, Tiam Jaroensri, et al. Advancing multimodal medical capabilities of gemini.arXiv preprint arXiv:2405.03162, 2024
-
[58]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[59]
Jingkun Yu, Yixiao Ge, Rui Wang, Shan Ying, et al. Medsg-bench: Benchmarking medical image sequences grounding capability of multimodal large language models. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[60]
Irfan Zeb, Dong Li, Khurram Nasir, Ronit Katz, Vahid N Larijani, and Matthew J Budoff. Computed tomography scans in the evaluation of fatty liver disease in a population based study: the multi-ethnic study of atherosclerosis.Academic radiology, 19(7):811–818, 2012. 13
work page 2012
-
[61]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415, 2023
-
[62]
Qingqing Zhu, Qiao Jin, Tejas S Mathai, Yin Fang, Zhizheng Wang, Yifan Yang, Maame Sarfo-Gyamfi, Benjamin Hou, Ran Gu, Praveen TS Balamuralikrishna, et al. Ct-bench: A benchmark for multimodal lesion understanding in computed tomography.arXiv preprint arXiv:2602.14879, 2026. 14 a Data Sources Table 6: Overview of public abdominal CT datasets collected in ...
-
[63]
Pancreas-CT [2015] [link] 42 1
CHAOS [2018] [link] 20 1 2. Pancreas-CT [2015] [link] 42 1
work page 2018
- [64]
- [65]
-
[66]
AMOS22 [2022] [link] 200 2 8. KiTS [2020] [link] 489 1 9–14. MSD CT Tasks [2021] [link] 945 1 15. AbdomenCT-1K [2021] [link] 1,050 12
work page 2022
-
[67]
FLARE’23 [2022] [link] 4,100 30 17. Trauma Detect. [2023] [link] 4,711 23 All 17 source datasets are publicly available under their respective licenses (links in Table 6); users are responsible for complying with each source dataset’s terms of use. The DeepTumorVQAannotations, structured metadata, and benchmark questionscontributed by this work are releas...
work page 2022
-
[68]
Reasoning liver lesion cluster
Q: Is pancreas enlarged? A: No Vis. Reasoning liver lesion cluster. Top-1 seg. ≥50% (highly); top- 2 segs. ≥75% (somewhat); else widely – Q: Liver lesions clustered? A: Yes Vis. Reasoning bilateral kidney asym. Largest-lesion-location vote; tie bro- ken by vol. ratio>1.3× – Q: Which kidney has more le- sions? A: Right Vis. Reasoning multi-organ burden Cro...
-
[69]
Reasoning hepatic steatosis gr
Q: Fatty liver grade? A: Light Med. Reasoning hepatic steatosis gr. 4-grade: HU 58/51/39 thresholds [32] Q: Steatosis grade? A: Moder- ate Med. Reasoning pancreatic steatosis P/S HU ratio<0.7 [22] Q: Pancreatic steatosis? A: No Med. Reasoning splenomegaly grading 4-grade: 314.5/500/800 cm 3 [10] Q: Splenomegaly grade? A: Mild Med. Reasoning PDAC vs PNET c...
-
[70]
Q: PDAC or PNET? A: PDAC Med. Reasoning portal hypertension Splenic vol + liver HU composite [24] Q: Portal hypertension? A: Yes Med. Reasoning renal mass charact. Simplified Bosniak: HU≤20 simple cyst; ≥70 hyperattenuating; else in- determinate/solid
-
[71]
Q: Mass classification? A: Sim- ple cyst Med. Reasoning lesion type class. Largest-volume kidney lesion: cyst vs. tumor label from radiologist an- notation
-
[72]
Q: Cyst or tumor? A: Tumor 20 (continued from previous page) Task Type Subtype Generation Logic Reference Example QA Med. Reasoning pseudocyst determ. HU>14.5 threshold [3] Q: Is it a pseudocyst? A: Yes Med. Reasoning pancreatic T staging T1–T4 from annotations [5] Q: Tumor T-stage? A: T2 Med. Reasoning cyst resectability Cyst vol>3.0 cm 3 [51] Q: Cyst re...
-
[73]
Q: Lesion resectable? A: No d Compositional Design vs. Template Matching Our use of deterministic generation programs invites comparison to CLEVR [ 30], but DeepTu- morVQA differs in three fundamental ways. First, our visual inputs arereal CT scans with real pathology, not synthetic scenes; the visual grounding challenge is genuine and domain-specific. Se...
-
[74]
We preprocess each NIfTI volume by: (1) clipping HU values to [−1024,1024] ; (2) resizing the volume to [64,256,256] using trilinear interpolation (scipy.ndimage.zoom); (3) normalizing to [0,1] by (x+ 1024)/2048 . The 3D ViT encoder processes this volume as a sequence of 2×16×16 patches, yielding 256 visual tokens. Resizing from native resolution (typical...
work page 2048
-
[75]
measure(target, type) Returns a ground-truth quantitative measurement for a specified target and measurement type. • Input: target (string), the anatomical target; type (string), one of volume, mean_HU, diameter,count. •Output:JSON with fields:value(float),unit(string). • Supported types: volume (cm3), mean_HU (Hounsfield units), diameter (cm, largest les...
-
[76]
lookup_medical_knowledge(query) Retrieves clinical criteria from a curated 27-entry knowledge base covering diagnostic thresholds, grading systems, and classification criteria. • Input: query (string): clinical topic (e.g., “fatty liver”,“splenomegaly grading”). • Output:JSON with fields: entries (list of dicts withcriterion,threshold,source). • Query mat...
work page 2012
-
[77]
crop_region(organ) Returns organ-focused multi-slice crops for visual inspection (vision mode only). •Input:organ(string): target organ (e.g.,“liver”,“kidney”,“pancreas”). • Output:JSON with field: image_base64 (string), a base64-encoded PNG of 5 representa- tive axial slices tiled in a single image with abdominal windowing. • Crop details:The bounding bo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.