Recognition: no theorem link
Do multimodal models imagine electric sheep?
Pith reviewed 2026-05-12 03:19 UTC · model grok-4.3
The pith
Large multimodal models form mental imagery of intermediate puzzle states as a byproduct of learning to predict action sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By supervising the model to predict the open-loop sequence of actions to solve a puzzle from an initial state, we show that the model's activations after each action encode meaningful visual information about the intermediate state. This finding suggests that an imperfect visual world model begins to form as a byproduct of learning to select correct actions, in the absence of any explicit visual supervision.
What carries the argument
Activations that appear after each predicted action and encode visual details of the resulting puzzle state.
If this is right
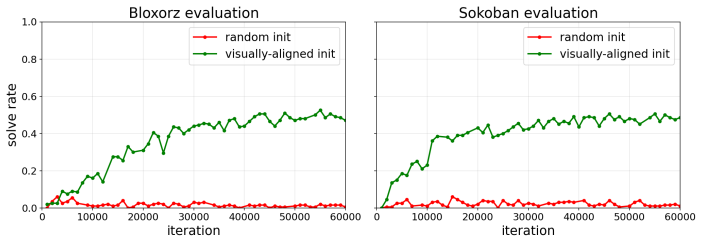
- Adding as few as sixteen visual tokens per step into the chain of thought raises average solve rate from 83% to 89%.
- Gains are largest on reasoning-heavy tasks such as jigsaw puzzles and 3D mental rotation.
- An imperfect visual world model emerges from action-sequence supervision alone across tangram, sokoban, rush hour and similar domains.
- The same activation-based imagery can be read out and reused without additional visual training data.
Where Pith is reading between the lines
- Planning or action prediction may be a more efficient route to building internal world models than pure next-token visual prediction.
- The same mechanism could be tested in embodied agents where actions have real physical consequences.
- Explicitly routing these visual tokens into longer reasoning chains might further close the gap between model performance and human spatial reasoning.
Load-bearing premise
The information in the activations is specifically visual content about the puzzle layout rather than abstract or action-related features.
What would settle it
Decoding or intervening on the activations after an action yields no recognizable reconstruction of the intermediate puzzle state, or performance gains vanish when the extracted tokens are replaced by random vectors of the same size.
Figures







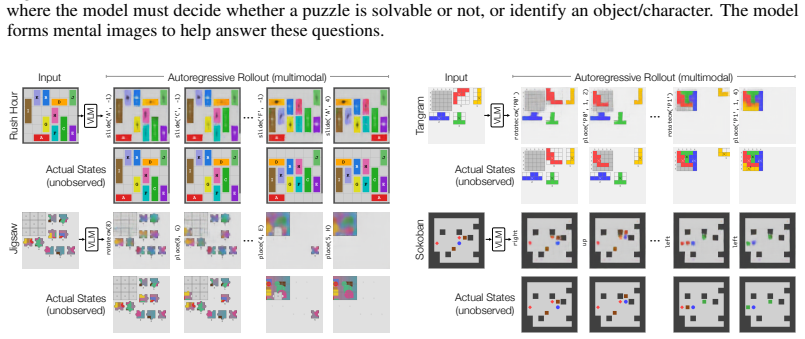






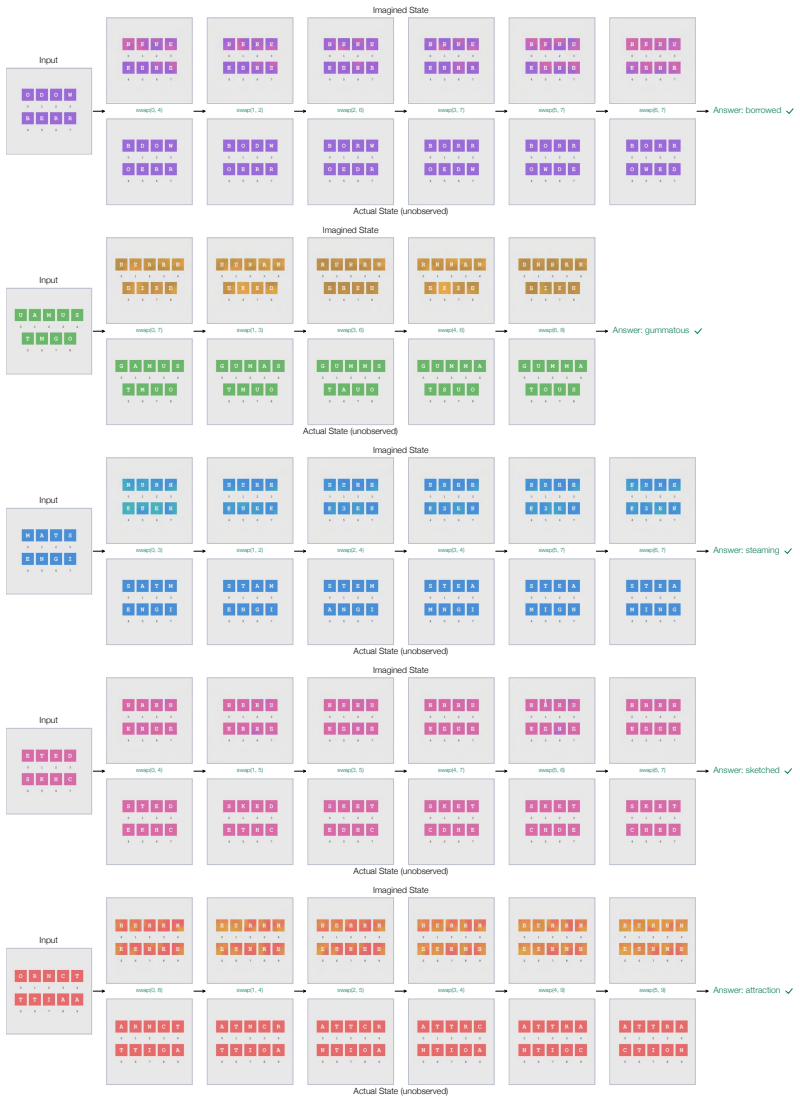





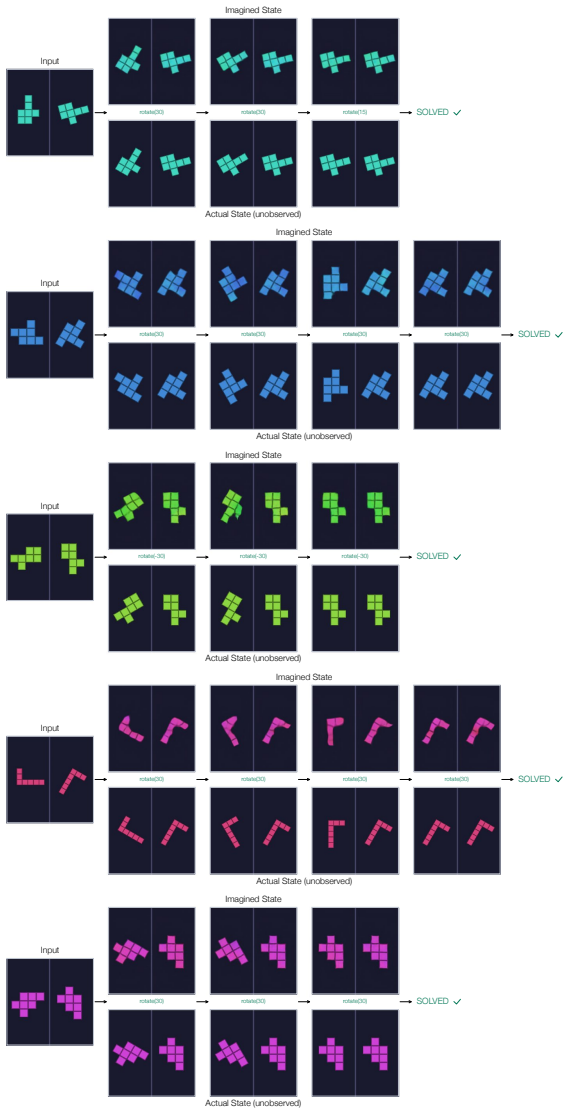


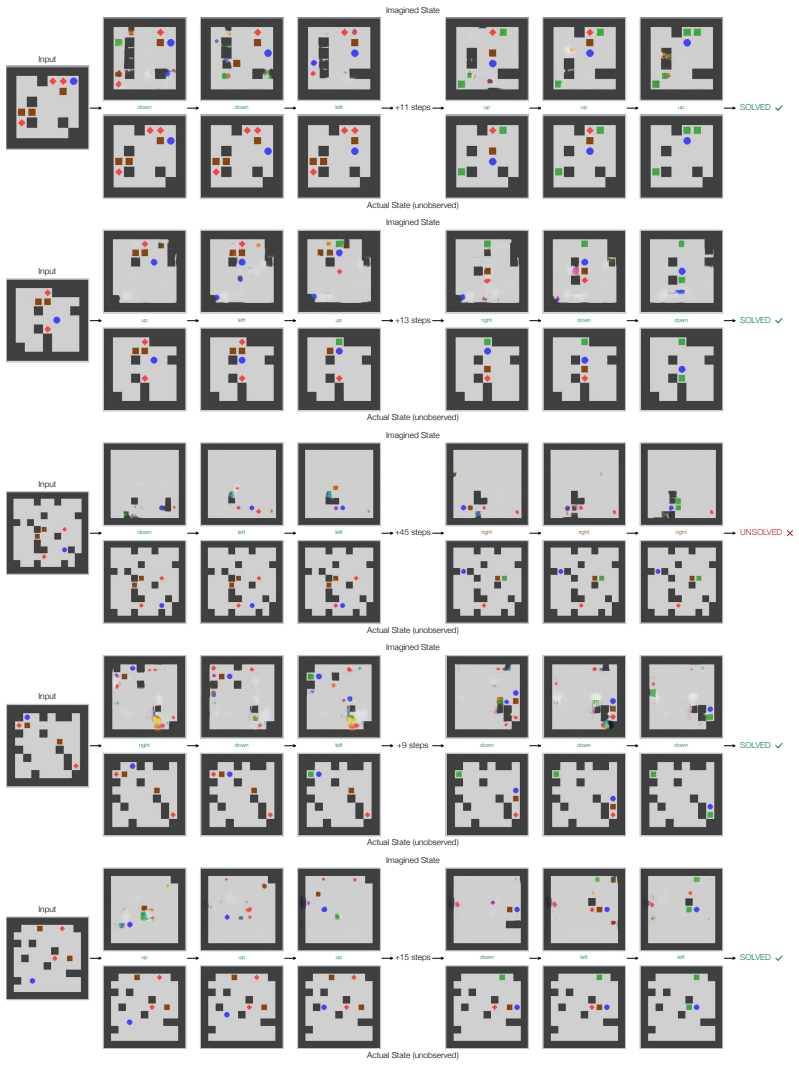

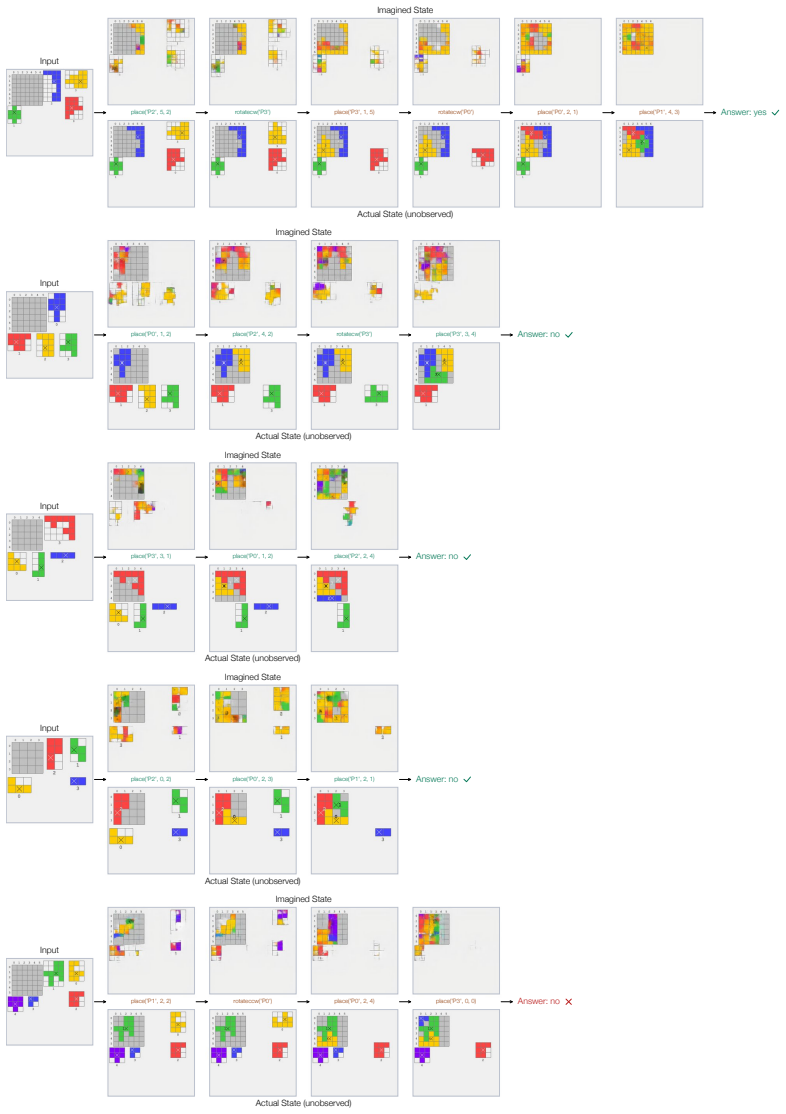











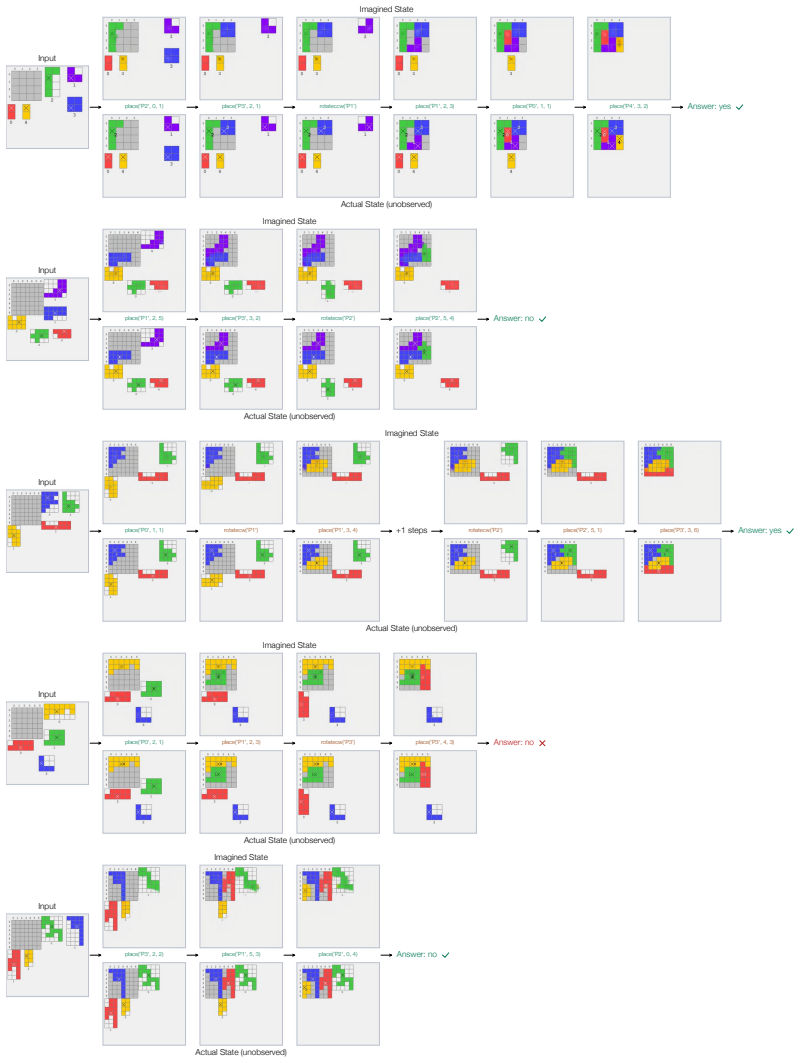












read the original abstract
Yes. We find that large multimodal models develop mental imagery when solving spatial puzzles, and they do imagine sheep when solving sheep puzzles. We fine-tune a Qwen3.5 VLM to solve twelve diverse visual reasoning tasks -- including tangram, jigsaw, sokoban, 3D mental rotation, and rush hour -- that require understanding geometry, spatial relationships, and the consequences of actions. By supervising the model to predict the open-loop sequence of actions to solve a puzzle from an initial state, we show that the model's activations after each action encode meaningful visual information about the intermediate state. This finding suggests that an imperfect visual world model begins to form as a byproduct of learning to select correct actions, in the absence of any explicit visual supervision. Building on this observation, we propose two ways to sharpen and use the mental images formed by the model. We find that integrating as few as sixteen visual tokens per step into the chain of thought improves the average solve rate from 83% to 89%, with particularly strong gains on reasoning-heavy tasks such as jigsaw and 3D mental rotation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large multimodal models develop mental imagery when solving spatial puzzles. By fine-tuning Qwen3.5 VLM on twelve tasks (tangram, jigsaw, sokoban, 3D mental rotation, rush hour, etc.) and supervising open-loop action sequences from initial states, the authors show that post-action activations encode meaningful visual information about intermediate states. They further propose integrating as few as sixteen visual tokens per step into the chain of thought, raising average solve rates from 83% to 89% with larger gains on reasoning-heavy tasks.
Significance. If substantiated, the work provides evidence that implicit visual world models can emerge in VLMs purely as a byproduct of action-prediction objectives without explicit visual supervision or reconstruction losses. The multi-task controlled setup and the token-integration intervention offer both mechanistic insight into emergent capabilities and a practical method for boosting spatial reasoning. The diversity of tasks and the focus on open-loop supervision are clear strengths.
major comments (3)
- [§4.2] §4.2 (activation probing): The central claim that activations encode specifically visual information (rather than abstract state or action history) is load-bearing but not isolated. No text-only state-description baseline, no ablation that removes visual input during fine-tuning while retaining action supervision, and no quantification of variance explained by visual features versus action tokens are reported. Without these controls the 'mental imagery' interpretation and the subsequent token-integration gains remain plausible but not fully verified.
- [Table 1] Table 1 (solve-rate results): The reported lift from 83% to 89% is promising, yet the table lacks error bars, the number of evaluation runs, or statistical significance tests. This makes it difficult to assess whether the 6% average gain (and the stronger effects on jigsaw and 3D rotation) is robust or could be explained by other side-effects of fine-tuning.
- [§3] §3 (fine-tuning procedure): It is unclear whether the visual encoder is frozen or updated during supervision on action sequences. This detail is necessary to support the interpretation that an 'imperfect visual world model begins to form' rather than merely being accessed from pre-existing representations.
minor comments (2)
- [Abstract] The abstract and §2 list the twelve tasks only in summary form; an enumerated table with one-sentence descriptions of each puzzle would aid reproducibility and reader understanding.
- [§4.3] The procedure for extracting and integrating the sixteen visual tokens is described in prose but would benefit from a short equation or pseudocode block to make the exact token-selection and insertion mechanism unambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying our methodology and strengthening the evidence where needed through revisions to the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (activation probing): The central claim that activations encode specifically visual information (rather than abstract state or action history) is load-bearing but not isolated. No text-only state-description baseline, no ablation that removes visual input during fine-tuning while retaining action supervision, and no quantification of variance explained by visual features versus action tokens are reported. Without these controls the 'mental imagery' interpretation and the subsequent token-integration gains remain plausible but not fully verified.
Authors: We agree that additional controls are necessary to more rigorously isolate the visual component of the learned representations. In the revised manuscript, we have added a text-only state-description baseline in which the model receives textual summaries of puzzle states (instead of images) during both fine-tuning and probing; this baseline shows substantially weaker encoding of intermediate states. We also include an ablation in which the visual encoder remains frozen during action-sequence supervision, demonstrating that the post-action activations lose their ability to predict visual features when visual parameters are not updated. Finally, we report a linear regression analysis quantifying the fraction of activation variance explained by visual features (extracted via a separate visual probe) versus action-history tokens, showing that visual information accounts for the majority of the predictive power on held-out states. revision: yes
-
Referee: [Table 1] Table 1 (solve-rate results): The reported lift from 83% to 89% is promising, yet the table lacks error bars, the number of evaluation runs, or statistical significance tests. This makes it difficult to assess whether the 6% average gain (and the stronger effects on jigsaw and 3D rotation) is robust or could be explained by other side-effects of fine-tuning.
Authors: We have updated Table 1 to report results averaged over five independent fine-tuning and evaluation runs with different random seeds. Error bars now show standard deviation across runs. We also added paired t-tests comparing the baseline (no visual tokens) against the 16-token integration condition; the average 6% gain is statistically significant (p < 0.01), with even stronger significance on jigsaw (p < 0.001) and 3D mental rotation (p < 0.001). These additions confirm that the reported improvements are robust to run-to-run variation. revision: yes
-
Referee: [§3] §3 (fine-tuning procedure): It is unclear whether the visual encoder is frozen or updated during supervision on action sequences. This detail is necessary to support the interpretation that an 'imperfect visual world model begins to form' rather than merely being accessed from pre-existing representations.
Authors: We have expanded §3 to explicitly state that the visual encoder is not frozen. The full VLM (including the vision tower) is fine-tuned end-to-end on the open-loop action prediction loss using LoRA adapters applied to both language and vision modules. This detail is now accompanied by a short ablation confirming that freezing the vision tower during training eliminates the emergence of useful visual encodings in the probed activations, supporting the claim that the world model forms through adaptation of visual representations rather than passive access to pre-trained features. revision: yes
Circularity Check
No significant circularity; empirical chain is self-contained
full rationale
The paper's derivation proceeds from action-sequence supervision during fine-tuning, through activation probing to detect state information, to an optional token-integration intervention whose performance lift is measured directly. None of these steps reduces by construction to a prior fitted parameter, self-referential definition, or load-bearing self-citation. The claim that activations encode visual (rather than abstract) content is presented as an empirical observation verified by probing and downstream gains, not as a definitional identity. No equations or uniqueness theorems are invoked that collapse the result to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of visual tokens per step
axioms (1)
- domain assumption Activations in a transformer can be linearly decoded into visual state information
Reference graph
Works this paper leans on
-
[1]
Mental rotation of three-dimensional objects.Science, 171(3972):701–703, 1971
Roger N Shepard and Jacqueline Metzler. Mental rotation of three-dimensional objects.Science, 171(3972):701–703, 1971
work page 1971
-
[2]
Cambridge University Press, 2005
Priti Shah and Akira Miyake.The Cambridge Handbook of Visuospatial Thinking. Cambridge University Press, 2005
work page 2005
-
[3]
Mast and Lutz Jäncke.Spatial Processing in Navigation, Imagery and Perception
Fred W. Mast and Lutz Jäncke.Spatial Processing in Navigation, Imagery and Perception. Springer, 2007
work page 2007
-
[4]
Valérie Gyselinck and Francesca Pazzaglia.From Mental Imagery to Spatial Cognition and Language. Psychology Press, 2012
work page 2012
-
[5]
Bence Nanay.Mental Imagery: Philosophy, Psychology, Neuroscience. Oxford University Press, 2023
work page 2023
-
[6]
Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Kraehenbuehl, and Vladlen Koltun. Does spatial cognition emerge in frontier models? InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[7]
Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, XinQiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models. InThe Fourteenth International Conference on Learning Representations,
-
[8]
URLhttps://openreview.net/forum?id=6nZKT2rL0H
-
[9]
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard
Liang Chen, Weichu Xie, Yiyan Liang, Hongfeng He, Hans Zhao, Zhibo Yang, Zhiqi Huang, Haoning Wu, Haoyu Lu, Y . Charles, et al. BabyVision: Visual reasoning beyond language. arXiv preprint arXiv:2601.06521, 2026. URLhttps://arxiv.org/abs/2601.06521
-
[10]
11plus-bench: Demystifying multimodal llm spatial reasoning with cognitive-inspired analysis
Chengzu Li, Wenshan Wu, Huanyu Zhang, Qingtao Li, Zeyu Gao, Yan Xia, José Hernández- Orallo, Ivan Vuli ´c, and Furu Wei. 11Plus-Bench: Demystifying multimodal LLM spatial reasoning with cognitive-inspired analysis.arXiv preprint arXiv:2508.20068, 2025. URL https://arxiv.org/abs/2508.20068
-
[11]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[12]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[13]
Actually, othello-gpt has a linear emergent world model, Mar 2023
Neel Nanda. Actually, othello-gpt has a linear emergent world model, Mar 2023. URL https://neelnanda.io/mechanistic-interpretability/othello
work page 2023
-
[14]
Emergent representations of program semantics in language models trained on programs
Charles Jin and Martin Rinard. Emergent representations of program semantics in language models trained on programs. InInternational Conference on Machine Learning, 2024. URL https://arxiv.org/abs/2305.11169
-
[15]
arXiv preprint arXiv:2210.13382 , year=
Kenneth Li, Aspen K Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Emergent world representations: Exploring a sequence model trained on a synthetic task.arXiv preprint arXiv:2210.13382, 2022
-
[16]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[17]
Spatialviz-bench: A cognitively-grounded benchmark for diagnosing spatial visualization in MLLMs
Siting Wang, Minnan Pei, Luoyang Sun, Cheng Deng, Yuchen Li, Kun Shao, Zheng Tian, Haifeng Zhang, and Jun Wang. Spatialviz-bench: A cognitively-grounded benchmark for diagnosing spatial visualization in MLLMs. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=OqZ7bm28Xx. 10
work page 2026
- [18]
-
[19]
Unfolding spatial cognition: Evaluating multimodal models on visual simulations
Linjie Li, Mahtab Bigverdi, Jiawei Gu, Zixian Ma, Yinuo Yang, Ziang Li, Yejin Choi, and Ranjay Krishna. Unfolding spatial cognition: Evaluating multimodal models on visual simulations. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=fbGmSV6tUw
work page 2026
-
[20]
When visualizing is the first step to reasoning: MIRA, a benchmark for visual chain-of-thought
Yiyang Zhou, Haoqin Tu, Zijun Wang, Zeyu Wang, Niklas Muennighoff, Fan Nie, Yejin Choi, James Zou, Chaorui Deng, Shen Yan, Haoqi Fan, Cihang Xie, Huaxiu Yao, and Qinghao Ye. When visualizing is the first step to reasoning: MIRA, a benchmark for visual chain-of-thought. arXiv preprint arXiv:2511.02779, 2025. URLhttps://arxiv.org/abs/2511.02779
-
[21]
Tyler Bonnen, Stephanie Fu, Yutong Bai, Thomas O’Connell, Yoni Friedman, Nancy Kanwisher, Joshua B. Tenenbaum, and Alexei A. Efros. Evaluating multiview object consistency in humans and image models.arXiv preprint arXiv:2409.05862, 2024. URL https://arxiv.org/abs/ 2409.05862
-
[22]
Nicholas Budny, Kia Ghods, Declan Campbell, Raja Marjieh, Amogh Joshi, Sreejan Kumar, Jonathan D. Cohen, Taylor W. Webb, and Thomas L. Griffiths. Visual serial processing deficits explain divergences in human and VLM reasoning.arXiv preprint arXiv:2509.25142, 2025. URLhttps://arxiv.org/abs/2509.25142
-
[23]
Can vision-language models solve the shell game?arXiv preprint arXiv:2603.08436, 2026
Tiedong Liu and Wee Sun Lee. Can vision-language models solve the shell game?arXiv preprint arXiv:2603.08436, 2026. URLhttps://arxiv.org/abs/2603.08436
-
[24]
Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008,
Stephanie Fu, Tyler Bonnen, Devin Guillory, and Trevor Darrell. Hidden in plain sight: VLMs overlook their visual representations.arXiv preprint arXiv:2506.08008, 2025. URL https://arxiv.org/abs/2506.08008
-
[25]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
Mohammad Asadi, Jack W. O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Rajabalifardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. MIRAGE: The illusion of visual understanding. arXiv preprint arXiv:2603.21687, 2026. URLhttps://arxiv.org/abs/2603.21687
-
[26]
Chain-of-sketch: Enabling global visual reasoning.arXiv preprint arXiv:2410.08165, 2024
Aryo Lotfi, Enrico Fini, Samy Bengio, Moin Nabi, and Emmanuel Abbe. Chain-of-sketch: Enabling global visual reasoning.arXiv preprint arXiv:2410.08165, 2024. URL https: //arxiv.org/abs/2410.08165
-
[27]
Whiteboard-of-thought: Thinking step-by- step across modalities
Sachit Menon, Richard Zemel, and Carl V ondrick. Whiteboard-of-thought: Thinking step-by- step across modalities. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20016–20031, 2024
work page 2024
-
[28]
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G. Shapiro, and Ranjay Krishna. Perception tokens enhance visual reasoning in multimodal language models. arXiv preprint arXiv:2412.03548, 2024. URLhttps://arxiv.org/abs/2412.03548
-
[29]
Mull-Tokens: Modality-Agnostic Latent Thinking
Arijit Ray, Ahmed Abdelkader, Chengzhi Mao, Bryan A. Plummer, Kate Saenko, Ranjay Krishna, Leonidas Guibas, and Wen-Sheng Chu. Mull-tokens: Modality-agnostic latent thinking. arXiv preprint arXiv:2512.10941, 2025. URLhttps://arxiv.org/abs/2512.10941
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang, Gordon Wetzstein, and Tsung-Yi Lin. CoT-VLA: Visual chain-of-thought reasoning for vision-language- action models.arXiv preprint arXiv:2503.22020, 2025. URL https://arxiv.org/abs/ 2503.22020
-
[31]
Jana Zeller, Thaddäus Wiedemer, Fanfei Li, Thomas Klein, Prasanna Mayilvahanan, Matthias Bethge, Felix Wichmann, Ryan Cotterell, and Wieland Brendel. MentisOculi: Revealing the limits of reasoning with mental imagery.arXiv preprint arXiv:2602.02465, 2026. URL https://arxiv.org/abs/2602.02465. 11
-
[32]
Mind’s eye of LLMs: Visualization-of-thought elicits spatial reasoning in large language models
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, and Furu Wei. Mind’s eye of LLMs: Visualization-of-thought elicits spatial reasoning in large language models. InConference on Neural Information Processing Systems, 2024. URL https://openreview. net/forum?id=CEJ1mYPgWw
work page 2024
-
[33]
Imagine while reasoning in space: Multimodal visualization-of-thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli´c, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought. InForty- second International Conference on Machine Learning, 2025. URL https://openreview. net/forum?id=6vk6Xg24ZC
work page 2025
-
[34]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=jE8xbmvFin
work page 2024
-
[35]
Visual representations inside the language model.arXiv preprint arXiv:2510.04819,
Benlin Liu, Amita Kamath, Madeleine Grunde-McLaughlin, Winson Han, and Ranjay Krishna. Visual representations inside the language model.arXiv preprint arXiv:2510.04819, 2025. URL https://arxiv.org/abs/2510.04819
-
[36]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. In NeurIPS, 2018
work page 2018
-
[37]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorld- Model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026. URLhttps://arxiv.org/abs/2603.19312
-
[39]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328, 2025. URLhttps://arxiv.org/abs/2509.20328
work page internal anchor Pith review arXiv 2025
-
[40]
Demystifing video reasoning.arXiv preprint arXiv:2603.16870, 2026
Ruisi Wang, Zhongang Cai, Fanyi Pu, Junxiang Xu, Wanqi Yin, Maijunxian Wang, Ran Ji, Chenyang Gu, Bo Li, Ziqi Huang, Hokin Deng, Dahua Lin, Ziwei Liu, and Lei Yang. Demystifing video reasoning.arXiv preprint arXiv:2603.16870, 2026. URL https://arxiv. org/abs/2603.16870
-
[41]
Xianjin Wu, Dingkang Liang, Tianrui Feng, Kui Xia, Yumeng Zhang, Xiaofan Li, Xiao Tan, and Xiang Bai. Generation models know space: Unleashing implicit 3D priors for scene understanding.arXiv preprint arXiv:2603.19235, 2026. URL https://arxiv.org/abs/ 2603.19235
-
[42]
NitroGen: An open foundation model for generalist gaming agents, 2026
Loïc Magne, Anas Awadalla, Guanzhi Wang, Yinzhen Xu, Joshua Belofsky, Fengyuan Hu, Joohwan Kim, Ludwig Schmidt, Georgia Gkioxari, Jan Kautz, Yisong Yue, Yejin Choi, Yuke Zhu, and Linxi Fan. NitroGen: An open foundation model for generalist gaming agents.arXiv preprint arXiv:2601.02427, 2026. URLhttps://arxiv.org/abs/2601.02427
-
[43]
MMGR: Multi-modal generative reasoning.arXiv preprint arXiv:2512.14691, 2025
Zefan Cai, Haoyi Qiu, Tianyi Ma, Haozhe Zhao, Gengze Zhou, Kung-Hsiang Huang, Parisa Kordjamshidi, Minjia Zhang, Wen Xiao, Jiuxiang Gu, Nanyun Peng, and Junjie Hu. MMGR: Multi-modal generative reasoning.arXiv preprint arXiv:2512.14691, 2025. URL https: //arxiv.org/abs/2512.14691
- [45]
-
[46]
A very big video reasoning suite
Maijunxian Wang, Ruisi Wang, Juyi Lin, Ran Ji, Thaddäus Wiedemer, Qingying Gao, Dezhi Luo, Yaoyao Qian, Lianyu Huang, Zelong Hong, et al. A very big video reasoning suite.arXiv preprint arXiv:2602.20159, 2026. URLhttps://arxiv.org/abs/2602.20159
-
[47]
arXiv preprint arXiv:2602.17270 (2026)
Jonathan Heek, Emiel Hoogeboom, Thomas Mensink, and Tim Salimans. Unified latents (UL): How to train your latents.arXiv preprint arXiv:2602.17270, 2026. URL https://arxiv. org/abs/2602.17270. 12
-
[48]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. URL https: //arxiv.org/abs/2505.14683
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Compositional chain of thought prompting for large multimodal models
Chancharik Mitra, Brandon Huang, Trevor Darrell, and Roei Herzig. Compositional chain of thought prompting for large multimodal models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024
work page 2024
-
[50]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics, volume 15, pages 627–635, 11–13 Apr 2011
work page 2011
-
[51]
Jigsaw-puzzles: From seeing to understanding to reasoning in vision-language models
Zesen Lyu, Dandan Zhang, Wei Ye, Fangdi Li, Zhihang Jiang, and Yao Yang. Jigsaw-puzzles: From seeing to understanding to reasoning in vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26003–26014, 2025
work page 2025
-
[52]
Yikun Zong and Cheston Tan. Tangramsr: Can vision-language models reason in continuous geometric space?arXiv preprint arXiv:2602.05570, 2026
-
[53]
Pspace-completeness of bloxorz and of games with 2-buttons
Tom C Van Der Zanden and Hans L Bodlaender. Pspace-completeness of bloxorz and of games with 2-buttons. InInternational Conference on Algorithms and Complexity, pages 403–415. Springer, 2015
work page 2015
-
[54]
Ami Hauptman, Achiya Elyasaf, Moshe Sipper, and Assaf Karmon. Gp-rush: using genetic pro- gramming to evolve solvers for the rush hour puzzle.Proceedings of the 11th Annual conference on Genetic and evolutionary computation, 2009. URL https://api.semanticscholar. org/CorpusID:14553191
work page 2009
-
[55]
Transfer learning and curriculum learning in sokoban
Zhao Yang, Mike Preuss, and Aske Plaat. Transfer learning and curriculum learning in sokoban. InBenelux Conference on Artificial Intelligence, pages 187–200. Springer, 2021
work page 2021
-
[56]
Jingmiao Zhao and Carolyn Jane Anderson. Solving and generating npr sunday puzzles with large language models.arXiv preprint arXiv:2306.12255, 2023
-
[57]
Andrew Shin and Kunitake Kaneko. Large language models lack understanding of character composition of words.arXiv preprint arXiv:2405.11357, 2024
-
[58]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[59]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InConference on Neural Information Processing Systems, page 6309–6318, 2017
work page 2017
-
[60]
Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
-
[61]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Spinbench: Perspective and rotation as a lens on spatial reasoning in vlms
Yuyou Zhang, Radu Corcodel, Chiori Hori, Anoop Cherian, and Ding Zhao. Spinbench: Perspective and rotation as a lens on spatial reasoning in vlms. InThe Fourteenth International Conference on Learning Representations, volume abs/2509.25390, 2026. URL https://api. semanticscholar.org/CorpusID:281681204
-
[63]
Seq2seq models reconstruct visual jigsaw puzzles without seeing them
Gur Elkin, Ofir Itzhak Shahar, and Ohad Ben-Shahar. Seq2seq models reconstruct visual jigsaw puzzles without seeing them.arXiv preprint arXiv:2511.06315, 2025
-
[64]
Solving sokoban with forward-backward reinforcement learning
Yaron Shoham and Gal Elidan. Solving sokoban with forward-backward reinforcement learning. InProceedings of the International Symposium on Combinatorial Search, volume 12, pages 191–193, 2021. 13
work page 2021
-
[65]
Planning in a recurrent neural network that plays sokoban
Mohammad Taufeeque, Philip Quirke, Maximilian Li, Chris Cundy, Aaron David Tucker, Adam Gleave, and Adrià Garriga-Alonso. Planning in a recurrent neural network that plays sokoban. InICLR, 2025. URLhttps://openreview.net/forum?id=ORxjH9kTp8
work page 2025
-
[66]
Jialong Wu, Xiaoying Zhang, Hongyi Yuan, Xiangcheng Zhang, Tianhao Huang, Changjing He, Chaoyi Deng, Renrui Zhang, Youbin Wu, and Mingsheng Long. Visual generation unlocks human-like reasoning through multimodal world models.arXiv preprint arXiv:2601.19834, 2026
-
[67]
Tahani Q. Alhassan, Shefaa S. Omar, and Lamiaa A. Elrefaei. Game of bloxorz solving agent using informed and uninformed search strategies.Procedia Computer Science, 2019. URL https://api.semanticscholar.org/CorpusID:213051605
work page 2019
-
[68]
Modeling and solving the rush hour puzzle
Lorenzo Cian, Talissa Dreossi, and Agostino Dovier. Modeling and solving the rush hour puzzle. InItalian Conference on Computational Logic, 2022. URL https://api.semanticscholar. org/CorpusID:252599882
work page 2022
-
[69]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023. URL https://dl.acm.org/doi/abs/10.1145/3600006. 3613165
-
[70]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 14 A Implementation Details Visual tokens.We use discrete visual tokens to represent images in all of our methods. We experiment with two encodings. Firstly, we use an FSQ autoencoder with D= 6 dimensions with L= 5 levels each, yielding a codeboo...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.