Recognition: 2 theorem links
· Lean TheoremCalibrate, Don't Curate: Label-Efficient Estimation from Noisy LLM Judges
Pith reviewed 2026-05-12 03:21 UTC · model grok-4.3
The pith
Calibrating the full panel of noisy LLM judges on labeled data outperforms selecting only the most accurate ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
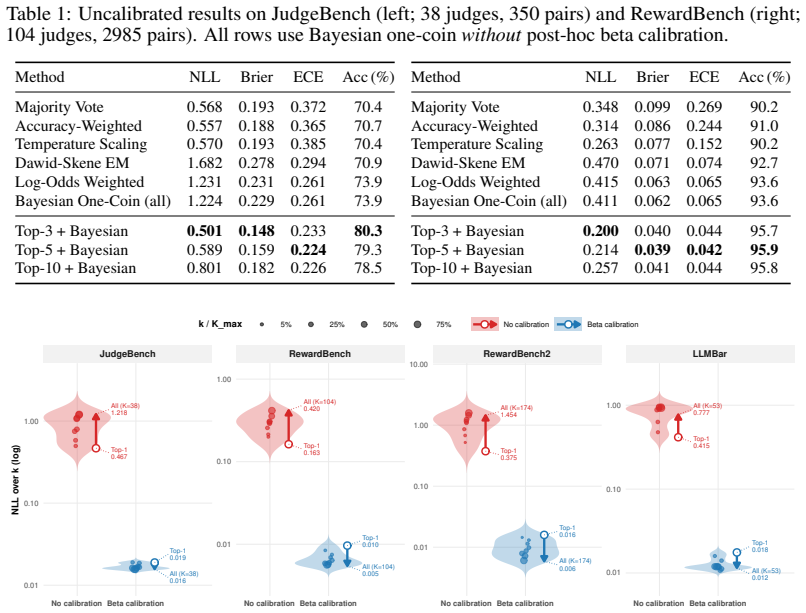
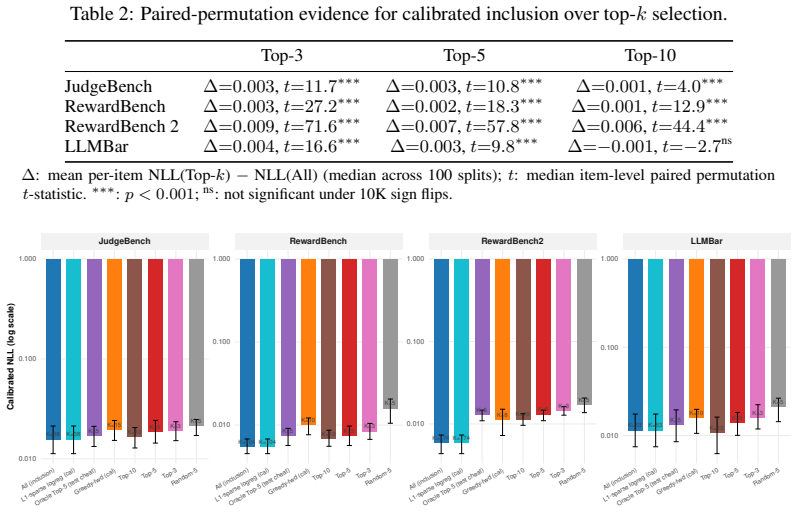
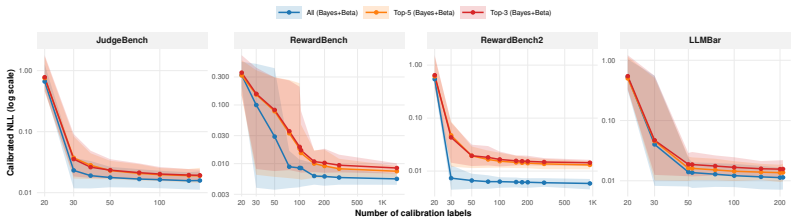
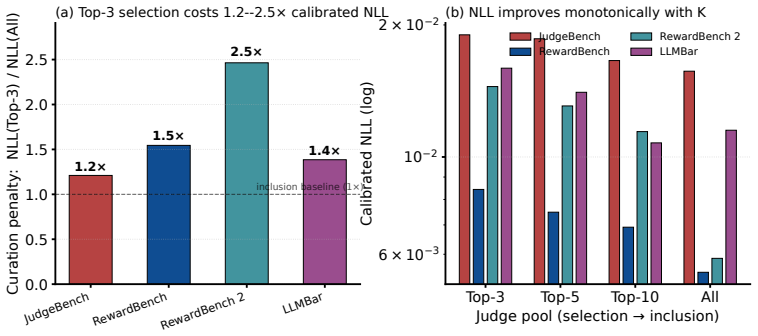
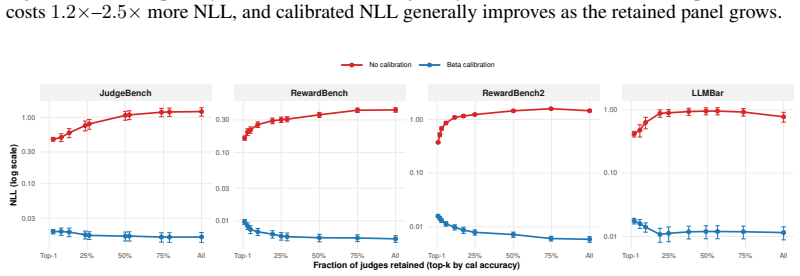
Holding aggregation and calibration fixed, the calibrated full judge panel consistently yields lower negative log-likelihood than accuracy-ranked top-k subsets across four labeled benchmarks. On RewardBench2 this produces NLL of 0.006 versus 0.013 for the top-5 selection. Oracle analysis shows that the minimal calibrated risk under proper scoring rules is non-increasing in the number of available signals, so even below-chance judges improve performance when their systematic biases are estimable from the calibration set and their outputs supply non-redundant information.
What carries the argument
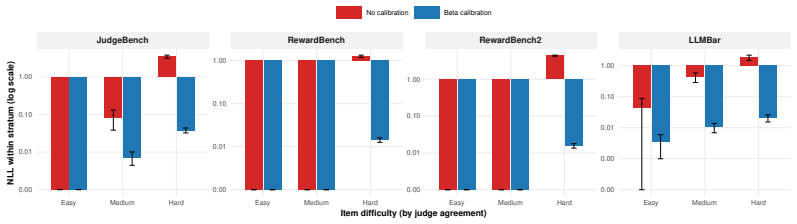
Calibration of individual judge probabilities on a labeled set under proper scoring rules, which learns biases and combines non-redundant signals while guaranteeing that optimal calibrated risk does not increase.
If this is right
- Full panels after calibration halve calibration error on RewardBench2 relative to top-5 selection.
- Below-chance judges contribute once their biases are learned from calibration data.
- Accuracy-based curation is dominated whenever labeled calibration examples exist.
- The advantage survives judge-family deduplication and stronger same-pipeline subset search.
- The operating rule applies equally to LLM-as-judge and reward-model pairwise evaluation.
Where Pith is reading between the lines
- Collecting a broader, more diverse set of judges may be preferable to aggressive filtering when even modest calibration data can be obtained.
- The same logic could extend to online or streaming settings where calibration updates occur incrementally as new labeled pairs arrive.
- Ensemble methods that treat weak but diverse predictors as additive rather than competitive may gain wider use in label-efficient evaluation pipelines.
Load-bearing premise
That the systematic biases of each judge, including those below chance level, can be reliably estimated from the calibration set and that the resulting signals stay non-redundant after correction.
What would settle it
A calibration dataset in which, after learning biases, the full judge panel produces strictly higher negative log-likelihood than its accuracy-ranked top-k subset under the same aggregation rule.
Figures

read the original abstract
Multi-judge evaluation is increasingly used to assess LLMs and reward models, and the prevailing heuristic is to curate: keep the most accurate judges and discard weaker ones. We show that this heuristic can reverse when the target is not point accuracy, but calibrated probabilistic evaluation from a labeled calibration set. Holding the aggregation and calibration procedures fixed, we compare accuracy-ranked top-$k$ judge selection with using the full judge panel. Across four labeled pairwise-evaluation benchmarks spanning LLM-as-judge and reward-model settings, the calibrated full panel consistently outperforms accuracy-based selection. On RewardBench2, retaining all judges achieves negative log-likelihood (NLL) of $0.006$ versus $0.013$ under top-5 selection, halving the calibration error. This advantage persists after judge-family deduplication and against stronger same-pipeline subset search. We explain this reversal with oracle analyses showing that the optimal calibrated risk under proper scoring rules cannot increase when additional judge signals are made available, and that even below-chance judges can be useful when their biases are learnable and their signals are non-redundant. The resulting operating principle is simple: in multi-judge evaluation with labeled calibration data, do not discard weak judges by accuracy alone; keep them when they are parseable, non-redundant, and calibratable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in multi-judge LLM evaluation with a labeled calibration set, calibrating and retaining the full panel of judges (including below-chance ones) consistently outperforms accuracy-based top-k selection for probabilistic evaluation, as measured by negative log-likelihood on held-out data. This is demonstrated empirically across four pairwise-evaluation benchmarks, with the full panel halving NLL (0.006 vs. 0.013) on RewardBench2, and supported by oracle analyses under proper scoring rules showing that optimal calibrated risk is non-increasing in the number of signals when biases are learnable and signals remain non-redundant after calibration.
Significance. If the empirical results and modeling assumptions hold, the work has clear significance for LLM-as-judge and reward-model evaluation by reversing the prevailing 'curate' heuristic in favor of a simpler calibration-based approach that leverages all available signals. The consistent outperformance across benchmarks, persistence after deduplication, and grounding in decision-theoretic oracle results are notable strengths that could influence label-efficient practices in the field.
major comments (2)
- [Abstract] Abstract and methods description: The central empirical claim (e.g., NLL of 0.006 vs. 0.013 on RewardBench2) and the explanation for why below-chance judges contribute rest on the assumption that per-judge biases are learnable from the calibration set and that signals remain non-redundant post-calibration. However, the manuscript provides no specification of the calibration model form, feature dimensionality, calibration-set size, or train/test split details, making it impossible to audit whether this assumption holds or to reproduce the results.
- [Theoretical Analysis] Theoretical section (oracle analysis): While the result that optimal risk under proper scoring rules cannot increase with additional signals is standard, the extension to include below-chance judges requires the non-redundancy assumption. No empirical diagnostic is reported (e.g., correlation matrix or effective rank of the calibrated judge outputs) to confirm that additional judges contribute independent information after calibration, which is load-bearing for the reversal claim.
minor comments (1)
- [Abstract] The operating principle at the end of the abstract introduces the terms 'parseable, non-redundant, and calibratable' without prior formal definitions or operational criteria in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key gaps in methodological detail and empirical support. We agree with both points and will revise the manuscript accordingly to enhance reproducibility and strengthen the claims. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: The central empirical claim (e.g., NLL of 0.006 vs. 0.013 on RewardBench2) and the explanation for why below-chance judges contribute rest on the assumption that per-judge biases are learnable from the calibration set and that signals remain non-redundant post-calibration. However, the manuscript provides no specification of the calibration model form, feature dimensionality, calibration-set size, or train/test split details, making it impossible to audit whether this assumption holds or to reproduce the results.
Authors: We agree that the manuscript currently omits these critical implementation details, which limits auditability and reproducibility. In the revised version we will add a dedicated Methods subsection that fully specifies the calibration model form, feature dimensionality, calibration-set sizes, and train/test split procedures used for each benchmark. These additions will make explicit how per-judge biases are learned from the labeled data and will allow readers to verify the non-redundancy assumption post-calibration, directly supporting the reported NLL improvements. revision: yes
-
Referee: [Theoretical Analysis] Theoretical section (oracle analysis): While the result that optimal risk under proper scoring rules cannot increase with additional signals is standard, the extension to include below-chance judges requires the non-redundancy assumption. No empirical diagnostic is reported (e.g., correlation matrix or effective rank of the calibrated judge outputs) to confirm that additional judges contribute independent information after calibration, which is load-bearing for the reversal claim.
Authors: We acknowledge that the non-redundancy assumption is load-bearing for extending the oracle result to below-chance judges and that an empirical diagnostic is currently absent. In the revision we will add a new analysis (in the Experiments or Appendix) reporting the correlation matrix and effective rank of the calibrated judge output matrix on the calibration sets. This diagnostic will confirm that the additional signals remain informative after calibration, thereby grounding the theoretical extension and the observed reversal of the curation heuristic. revision: yes
Circularity Check
No circularity: empirical benchmarks and general decision-theoretic oracle are independent of fitted inputs
full rationale
The paper's central results consist of direct empirical comparisons of NLL on held-out labeled benchmarks (e.g., RewardBench2) under fixed aggregation/calibration procedures, plus a general oracle statement that optimal risk under proper scoring rules is non-increasing in the number of signals. Neither reduces by construction to any fitted parameter, self-definition, or self-citation chain. The learnability/non-redundancy assumption is an empirical modeling claim, not a definitional equivalence. No load-bearing step quotes or equations exhibit the forbidden patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibration model parameters
axioms (1)
- domain assumption Judges' biases are learnable from the calibration set and their signals are non-redundant
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearProposition 1 (Monotonicity of oracle-calibrated risk) and Theorem 1 (Calibrated Jury Theorem) using log-odds weights α_k = log(p_k/(1-p_k)) and proper scoring rules NLL/Brier.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearBeta calibration map and nested model classes M_ω ⊂ M_ω,δ ⊂ M_ω,δ,G with excess-risk bound (Theorem 2).
Reference graph
Works this paper leans on
-
[1]
Efficient Bayesian inference from noisy pairwise comparisons.arXiv preprint arXiv:2510.09333,
Balázs Aczel, Dirk Oliver Theis, and Roger Wattenhofer. Efficient Bayesian inference from noisy pairwise comparisons.arXiv preprint arXiv:2510.09333,
work page internal anchor Pith review arXiv
-
[2]
CLEAR: Calibrated learning for epistemic and aleatoric risk.arXiv preprint arXiv:2507.08150,
Ilia Azizi, Juraj Bodik, Jakob Heiss, and Bin Yu. CLEAR: Calibrated learning for epistemic and aleatoric risk.arXiv preprint arXiv:2507.08150,
-
[3]
Hamid Dadkhahi, Firas Trabelsi, Parker Riley, Juraj Juraska, and Mehdi Mirzazadeh. Distribution- calibrated inference time compute for thinking LLM-as-a-judge.arXiv preprint arXiv:2512.03019,
-
[4]
On Cost-Effective LLM-as-a-Judge Improvement Techniques
Ryan Lail. An empirical investigation of practical LLM-as-a-judge improvement techniques on RewardBench 2.arXiv preprint arXiv:2604.13717,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yuran Li, Jama Hussein Mohamud, Chongren Sun, Di Wu, and Benoit Boulet. Leveraging LLMs as meta-judges: A multi-agent framework for evaluating LLM judgments.arXiv preprint arXiv:2504.17087,
-
[6]
RewardBench 2: Advancing Reward Model Evaluation
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A. Smith, Hannaneh Ha- jishirzi, and Nathan Lambert. RewardBench 2: Advancing reward model evaluation.arXiv preprint arXiv:2506.01937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
QA-calibration of language model confidence scores.arXiv preprint arXiv:2410.06615,
Putra Manggala, Atalanti Mastakouri, Elke Kirschbaum, Shiva Prasad Kasiviswanathan, and Aaditya Ramdas. QA-calibration of language model confidence scores.arXiv preprint arXiv:2410.06615,
- [8]
-
[9]
Bhaktipriya Radharapu, Eshika Saxena, Kenneth Li, Chenxi Whitehouse, Adina Williams, and Nicola Cancedda. Calibrating LLM judges: Linear probes for fast and reliable uncertainty estimation. arXiv preprint arXiv:2512.22245,
-
[10]
Quantitative LLM judges.arXiv preprint arXiv:2506.02945,
Aishwarya Sahoo, Jeevana Kruthi Karnuthala, Tushar Parmanand Budhwani, Pranchal Agarwal, Sankaran Vaidyanathan, Alexa Siu, Franck Dernoncourt, Jennifer Healey, Nedim Lipka, Ryan Rossi, Uttaran Bhattacharya, and Branislav Kveton. Quantitative LLM judges.arXiv preprint arXiv:2506.02945,
-
[11]
Zailong Tian, Zhuoheng Han, Yanzhe Chen, Haozhe Xu, Xi Yang, Richeng Xuan, Houfeng Wang, and Lizi Liao. Overconfidence in LLM-as-a-judge: Diagnosis and confidence-driven solution. arXiv preprint arXiv:2508.06225,
-
[12]
Measuring all the noises of LLM evals.arXiv preprint arXiv:2512.21326,
Sida Wang. Measuring all the noises of LLM evals.arXiv preprint arXiv:2512.21326,
-
[13]
11 Mingyuan Xu, Xinzi Tan, Jiawei Wu, and Doudou Zhou. A judge-aware ranking framework for evaluating large language models without ground truth.arXiv preprint arXiv:2601.21817,
-
[14]
Joint inference (Appendix G) T={τ 1, . . . , τm}Grid of label budgets tested simultaneously Tb(τ), ¯T(τ)Per-split NLL difference at budgetτin splitb; mean across splits [CorrEmpirical correlation of centeredT b across budgets Mobs,c 1−α Observed test statistic; bootstrap critical value at level1−α B Additional Related Literature Classical crowdsourcing an...
work page 1979
-
[15]
use Bayesian Bradley–Terry modeling with rater-quality priors, while Bradley–Terry-σ (BT- σ) [Qian et al., 2026] shows how ignoring heterogeneity can make confidence intervals too narrow around biased estimates. These methods are closest to our aggregation layer, but our main empirical 15 comparison asks whether reliability-aware aggregation should be app...
work page 2026
-
[16]
derive black-box confidence from token-level entropy. These works calibrate an individual judge or a fixed judge-output representation, whereas our setting must also decide how many heterogeneous judges to retain before calibration. Calibration and conformal extensions.Our probability maps use standard post-hoc tools: Platt scaling [Platt, 1999], beta cal...
work page 1999
-
[17]
study conformal prediction under label contamination, while van der Laan and Alaa [2024, 2025] combine Venn–Abers or Venn-style calibration with conformal guarantees. These extensions are useful for downstream coverage, but the main contribution here is upstream: calibrated probability estimation from a multi-judge panel. Broader evaluation and uncertaint...
work page 2024
-
[18]
C.7 Finite-Sample Hoeffding Bound for Weighted Voting Theorem 3(Finite-sample improvement of weighted over majority voting).Consider K independent binary judges with accuracies ak = 1/2 +δ k and votes encoded as 2yk −1∈ {−1,+1} . Let Sw = P k wk(2yk −1) and let Smv be the unweighted sum. Hoeffding’s inequality gives error exponents Ew = (P k(2ak −1)w k)2 ...
work page 2013
-
[19]
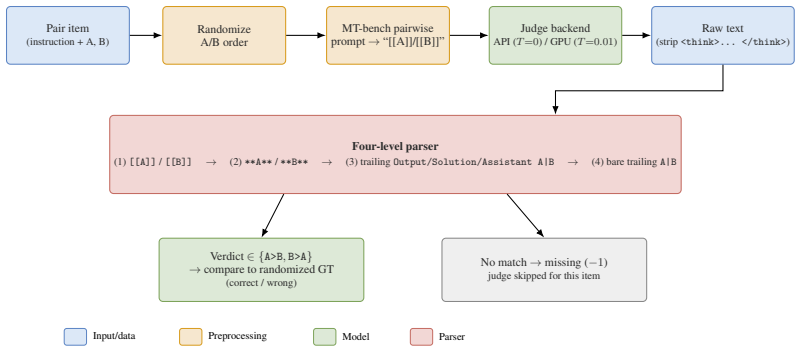
Because RewardBench on its own already has a wide, redundancy-free panel, we did not augment it. All added judges share an identical MT-bench-style pairwise prompt [Zheng et al., 2023]: the judge is told it is an “impartial judge,” given the user instruction and the two candidate responses (as “Assistant A” and “Assistant B”), and asked to produce a short...
-
[20]
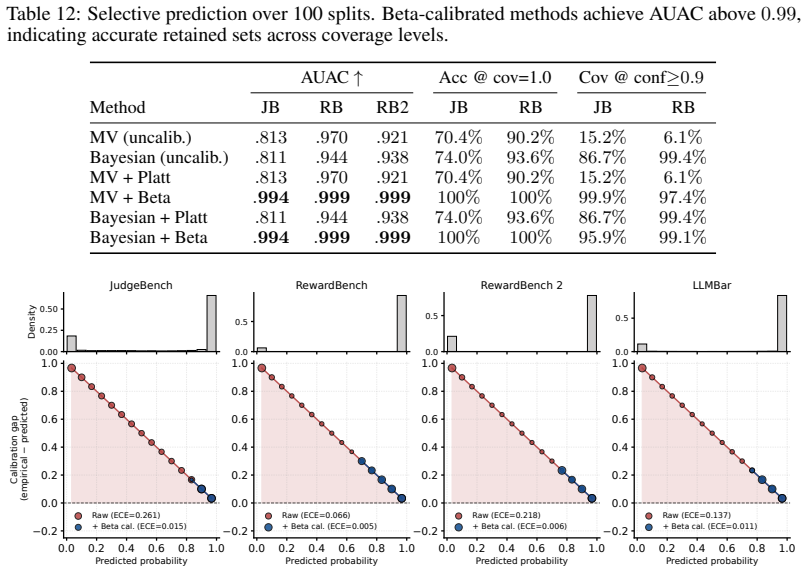
reduces NLL from 1.22 to 0.084 on JudgeBench (93% reduction) and from 0.41 to 0.046 on RewardBench (89% reduction). Steps 1–2 provide the Bayesian posterior probabilities that serve as input for beta calibration; Step 4 adds distribution-free coverage guarantees. H.11 Sanity Checks Replacing ground-truth labels with random labels yields NLL ≈0.70 –0.75 (≈...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.