Recognition: no theorem link
MOTOR-Bench: A Real-world Dataset and Multi-agent Framework for Zero-shot Human Mental State Understanding
Pith reviewed 2026-05-12 02:45 UTC · model grok-4.3
The pith
A multi-agent framework coordinates specialized agents to infer behaviors, cognitions, and emotions from real-world video clips in zero-shot settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MOTOR-MAS coordinates multiple agents through a structured agent coordination mechanism to infer explicit behaviors, internal cognitions, and psychological emotions from multimodal video clips, achieving a 15.93-point Macro-F1 improvement over the best single-model benchmark for the three labels and a 10.2-point gain over general multi-agent systems specifically in internal cognition prediction.
What carries the argument
The structured agent coordination mechanism that assigns separate agents to observe explicit behaviors, infer internal cognitions, and recognize psychological emotions before combining their structured outputs for final prediction.
If this is right
- The framework supports more reliable zero-shot mental-state monitoring in educational settings without requiring task-specific training data.
- Performance on internal cognition improves when reasoning is decomposed across agents rather than attempted in a single forward pass.
- Real-world challenges such as class imbalance and visual noise are handled better by the multi-agent structure than by monolithic models.
- The MOTOR-Bench dataset provides a standardized testbed for measuring progress in structured, multimodal mental-state inference.
Where Pith is reading between the lines
- If the coordination mechanism is the main source of gains, similar layered agent designs could transfer to other inference problems that require bridging observable signals to unobservable internal states.
- Adding iterative feedback between the behavior, cognition, and emotion agents might reduce inconsistencies that arise from one-way information flow.
- Testing the same framework on video from non-classroom domains, such as team meetings or clinical interactions, would reveal whether the approach depends on the specific self-regulated learning labels.
Load-bearing premise
Expert annotations based on self-regulated learning theory accurately reflect the true internal mental states that are only indirectly visible in the video behavior.
What would settle it
A new evaluation on videos where participants later provide independent self-reports of their own mental states during the recorded interaction, showing that MOTOR-MAS predictions match the self-reports no better than single-model baselines, would indicate the reported gains do not stem from improved reasoning about hidden states.
Figures




read the original abstract
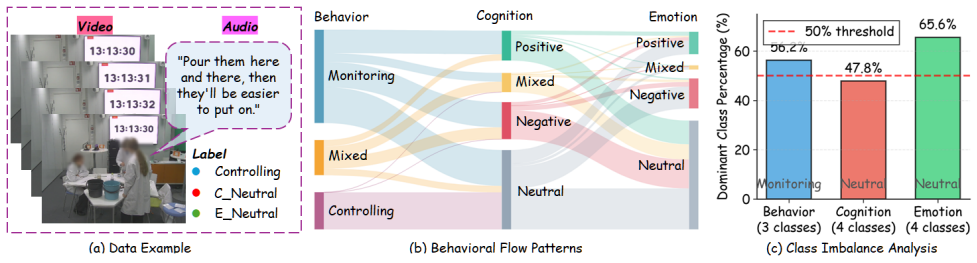
Understanding human mental states from natural behavior is crucial for intelligent systems in the real world. However, most current research focuses on predicting isolated mental state labels, lacking structured annotations of complex interpersonal interactions. To support structured analysis, we introduce MOTOR-Bench, a carefully-designed benchmark with a real-world dataset MOTOR-dataset, containing 1,440 multimodal video clips in collaborative learning scenarios, reflecting key real-world data challenges including natural class imbalance, visual noise, and domain-specific language. Each sample is labeled by educational experts based on self-regulated learning theory. We further evaluate several state-of-the-art multimodal large language models and multi-agent systems in a zero-shot setting on our MOTOR-Bench. However, their performance on this task remains limited, suggesting that existing methods still struggle with structured reasoning from observable behavior to deeper mental states. To address this challenge, we propose a reasoning multi-agent framework, named MOTOR-MAS. It coordinates multiple agents through a structured agent coordination mechanism to infer explicit behaviors, internal cognitions, and psychological emotions. Experimental results show that our MOTOR-MAS outperforms the best single-model benchmark by 15.93 points in Macro-F1 scores for the three labels of behavior, cognition, and emotion, and outperforms the general multi-agent benchmark by 10.2 points in internal cognition prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MOTOR-Bench, a dataset of 1,440 real-world multimodal video clips from collaborative learning scenarios, each annotated by educational experts using self-regulated learning theory for three structured labels (behavior, cognition, emotion). It benchmarks zero-shot performance of state-of-the-art multimodal LLMs and general multi-agent systems on this data, reports their limitations, and proposes MOTOR-MAS, a coordinated multi-agent reasoning framework that achieves a 15.93-point Macro-F1 improvement over the best single-model baseline and a 10.2-point gain in internal cognition prediction over general multi-agent systems.
Significance. If the expert-derived labels prove reliable, the work would offer a valuable, challenging benchmark that incorporates natural class imbalance, visual noise, and domain-specific language, advancing research on structured mental-state inference from observable behavior. The MOTOR-MAS results would provide concrete evidence that explicit multi-agent coordination can improve zero-shot reasoning over single models in this setting.
major comments (3)
- [Dataset construction] Dataset construction section: no inter-annotator agreement statistics (e.g., Cohen’s kappa or Fleiss’ kappa) are reported for the expert annotations of cognition and emotion, which are inferred from video behavior via self-regulated learning theory. Without these metrics or validation against self-reports/physiological signals, the reliability of the ground-truth labels remains unestablished, directly undermining interpretation of the reported Macro-F1 gains.
- [Experimental results] Experimental results section: the headline improvements (15.93 Macro-F1 over best single-model, 10.2 over general multi-agent) are stated without specifying the exact baseline models and implementations, statistical significance tests, error bars, or the precise data splits used. This absence prevents verification that the gains are robust rather than artifacts of unstated choices.
- [Evaluation protocol] Evaluation protocol: the zero-shot setting is described, yet no analysis is provided of how visual noise, class imbalance, or domain-specific language in the 1,440 clips affects model performance or label consistency. This is load-bearing for the claim that existing methods “still struggle with structured reasoning.”
minor comments (2)
- [MOTOR-MAS framework] The description of the agent coordination mechanism in MOTOR-MAS would benefit from an explicit pseudocode or step-by-step algorithm to clarify how the structured coordination differs from the general multi-agent baseline.
- [Results tables] Table captions and axis labels in the results tables should explicitly state the evaluation metric (Macro-F1) and the three label categories to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment point-by-point below. Revisions have been made to incorporate additional details, metrics, and analyses as described.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: no inter-annotator agreement statistics (e.g., Cohen’s kappa or Fleiss’ kappa) are reported for the expert annotations of cognition and emotion, which are inferred from video behavior via self-regulated learning theory. Without these metrics or validation against self-reports/physiological signals, the reliability of the ground-truth labels remains unestablished, directly undermining interpretation of the reported Macro-F1 gains.
Authors: We agree that inter-annotator agreement (IAA) metrics are essential for establishing label reliability. Three educational experts independently annotated each of the 1,440 clips following self-regulated learning theory protocols. We have now computed Fleiss’ kappa scores across the three annotators for behavior (0.82), cognition (0.71), and emotion (0.68) labels; these values and a brief discussion of agreement levels will be added to the Dataset Construction section. Regarding validation against self-reports or physiological signals, such data were not collected because the dataset derives from naturalistic, real-world collaborative learning videos where intrusive measurements were infeasible; we will explicitly note this limitation and the reliance on expert theory-driven inference. revision: yes
-
Referee: [Experimental results] Experimental results section: the headline improvements (15.93 Macro-F1 over best single-model, 10.2 over general multi-agent) are stated without specifying the exact baseline models and implementations, statistical significance tests, error bars, or the precise data splits used. This absence prevents verification that the gains are robust rather than artifacts of unstated choices.
Authors: We acknowledge that additional implementation details are required for reproducibility and to substantiate the reported gains. In the revised Experimental Results section we will: (1) explicitly enumerate all baseline models and their versions/implementations (including the specific multimodal LLMs and general multi-agent systems tested); (2) describe the evaluation protocol on the full set of 1,440 clips under the zero-shot setting (no train/test split was used); (3) report statistical significance via paired t-tests or McNemar’s test where applicable; and (4) include error bars derived from multiple inference runs with different random seeds. These clarifications will be added without altering the headline numbers. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol: the zero-shot setting is described, yet no analysis is provided of how visual noise, class imbalance, or domain-specific language in the 1,440 clips affects model performance or label consistency. This is load-bearing for the claim that existing methods “still struggle with structured reasoning.”
Authors: We agree that a targeted analysis of these real-world factors strengthens the central claim. We have added a new subsection under Evaluation Protocol that provides: (a) per-class performance breakdowns to illustrate the effects of natural class imbalance; (b) qualitative case studies highlighting failures attributable to visual noise (e.g., occlusion, poor lighting) and domain-specific educational terminology; and (c) a consistency analysis comparing model predictions against expert label distributions. This analysis directly supports that the observed performance gaps reflect challenges in structured reasoning rather than isolated artifacts. revision: yes
Circularity Check
No circularity: empirical dataset and framework with no derivation chain or self-referential reductions
full rationale
The paper introduces MOTOR-Bench as a real-world video dataset annotated by experts using external self-regulated learning theory, then reports zero-shot empirical evaluations of existing models and a proposed multi-agent framework MOTOR-MAS. Performance numbers (e.g., Macro-F1 gains) are direct comparisons on the new data against baselines; no equations, fitted parameters, predictions derived from the same data, or load-bearing self-citations appear in the abstract or described structure. All load-bearing steps are external (theory, annotations, model evaluations) rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Anticipation?
Yueyi Yang, Haotian Liu, Fang Kang, Mengqi Zhang, Zheng Lian, Hao Tang, and Haoyu Chen. Saynext-bench: Why do llms struggle with next-utterance prediction?arXiv preprint arXiv:2602.00327, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Zheng Lian, Licai Sun, Lan Chen, Haoyu Chen, Zebang Cheng, Fan Zhang, Ziyu Jia, Ziyang Ma, Fei Ma, Xiaojiang Peng, et al. Emoprefer: Can large language models under- stand human emotion preferences?International Conference on Learning Representations, 2025
work page 2025
-
[3]
Zheng Lian, Haiyang Sun, Licai Sun, Haoyu Chen, Lan Chen, Hao Gu, Zhuofan Wen, Shun Chen, Siyuan Zhang, Hailiang Yao, et al. Ov-mer: Towards open-vocabulary mul- timodal emotion recognition.International Conference on Machine Learning, 2024
work page 2024
-
[4]
Guoying Zhao, Yante Li, and Qianru Xu. From emotion ai to cognitive ai.International Journal of Network Dynamics and Intelligence, 1(1), 2022
work page 2022
-
[5]
Stefanos Zafeiriou, Athanasios Papaioannou, Irene Kotsia, Mihalis Nicolaou, and Guoying Zhao. Facial affect “in-the- wild”: A survey and a new database. In2016 IEEE Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW). Institute of Electrical and Electronics En- gineers, 2016
work page 2016
-
[6]
Multimodal emotion prediction in interper- sonal videos integrating facial and speech cues
Hajer Guerdelli, Claudio Ferrari, Stefano Berretti, and Al- berto Del Bimbo. Multimodal emotion prediction in interper- sonal videos integrating facial and speech cues. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 5681–5690, 2025
work page 2025
-
[7]
Haoyu Chen, Henglin Shi, Xin Liu, Xiaobai Li, and Guoy- ing Zhao. Smg: A micro-gesture dataset towards sponta- neous body gestures for emotional stress state analysis.In- ternational Journal of Computer Vision, 131(6):1346–1366, 2023
work page 2023
-
[8]
imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis
Xin Liu, Henglin Shi, Haoyu Chen, Zitong Yu, Xiaobai Li, and Guoying Zhao. imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 10631–10642, 2021
work page 2021
-
[9]
Haoyu Chen, Xin Liu, Xiaobai Li, Henglin Shi, and Guoy- ing Zhao. Analyze spontaneous gestures for emotional stress state recognition: A micro-gesture dataset and analysis with deep learning. In2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), pages 1–8. IEEE, 2019
work page 2019
-
[10]
Emoticon: Context-aware multimodal emotion recognition using frege’s principle
Trisha Mittal, Pooja Guhan, Uttaran Bhattacharya, Rohan Chandra, Aniket Bera, and Dinesh Manocha. Emoticon: Context-aware multimodal emotion recognition using frege’s principle. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14234– 14243, 2020
work page 2020
-
[11]
How you feelin’? learning emotions and mental states in movie scenes
Dhruv Srivastava, Aditya Kumar Singh, and Makarand Tapaswi. How you feelin’? learning emotions and mental states in movie scenes. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2517–2528, 2023
work page 2023
-
[12]
H. J ¨arvenoja, T. T¨orm¨anen, A. Nakata, and L. Morska. Mo- tivational triggers for regulation in collaborative learning. Manuscript submitted for publication, 2026
work page 2026
-
[13]
H. J ¨arvenoja, T. T ¨orm¨anen, M. Turunen, and E. Lehtoaho. We will succeed: How varying success expectancies and so- cially shared regulation shape students’ collaborative learn- ing.Journal of Computer Assisted Learning, 41(3):e70024, 2025
work page 2025
-
[14]
Miika Sobocinski, Sanna J ¨arvel¨a, Jonna Malmberg, et al. How does monitoring set the stage for adaptive regulation or maladaptive behavior in collaborative learning?Metacogni- tion and Learning, 15(2):99–127, 2020
work page 2020
-
[15]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[17]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Zheng Lian, Haoyu Chen, Lan Chen, Haiyang Sun, Licai Sun, Yong Ren, Zebang Cheng, Bin Liu, Rui Liu, Xiaojiang Peng, et al. Affectgpt: A new dataset, model, and benchmark for emotion understanding with multimodal large language models.arXiv preprint arXiv:2501.16566, 2025
-
[19]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society.Ad- vances in neural information processing systems, 36:51991– 52008, 2023
work page 2023
-
[20]
Macro f1 and macro f1.arXiv preprint arXiv:1911.03347, 2019
Juri Opitz and Sebastian Burst. Macro f1 and macro f1.arXiv preprint arXiv:1911.03347, 2019
- [21]
-
[22]
Soujanya Poria, Erik Cambria, Rajiv Bajpai, and Amir Hus- sain. A review of affective computing: From unimodal anal- ysis to multimodal fusion.Information fusion, 37:98–125, 2017
work page 2017
-
[23]
AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Multimodal lan- guage analysis in the wild: Cmu-mosei dataset and inter- pretable dynamic fusion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 2236–2246, 2018
work page 2018
-
[24]
Meld: A multimodal multi-party dataset for emotion recognition in conversations
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recognition in conversations. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 527– 536, 2019
work page 2019
-
[25]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Zhang, Ceyao Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta pro- gramming for multi-agent collaborative framework.arXiv preprint arXiv:2308.00352, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Scaling large-language-model-based multi-agent collaboration
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, et al. Scaling large language model-based multi-agent collaboration.arXiv preprint arXiv:2406.07155, 2024
-
[27]
Yingxuan Yang, Chengrui Qu, Muning Wen, Laixi Shi, Ying Wen, Weinan Zhang, Adam Wierman, and Shangding Gu. Understanding agent scaling in llm-based multi-agent sys- tems via diversity.arXiv preprint arXiv:2602.03794, 2026
-
[28]
Becoming a self-regulated learner: An overview.Theory into practice, 41(2):64–70, 2002
Barry J Zimmerman. Becoming a self-regulated learner: An overview.Theory into practice, 41(2):64–70, 2002
work page 2002
-
[29]
Roger Azevedo, Jennifer G Cromley, and Diane Seibert. Does adaptive scaffolding facilitate students’ ability to regu- late their learning with hypermedia?Contemporary educa- tional psychology, 29(3):344–370, 2004
work page 2004
-
[30]
H. J ¨arvenoja, T. T¨orm¨anen, M. Turunen, E. Lehtoaho, and J. Suoraniemi. MotoR multimodal process data of secondary school students’ collaborative learning (version 1), 2024
work page 2024
-
[31]
whisper-large-finnish-v3 (revision ee1a8bf), 2023
Finnish-NLP. whisper-large-finnish-v3 (revision ee1a8bf), 2023
work page 2023
-
[32]
Kyubyong Park and Thomas Mulc. Css10: A collection of single speaker speech datasets for 10 languages.arXiv preprint arXiv:1903.11269, 2019
-
[33]
Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux. V oxpopuli: A large-scale multilingual speech corpus for representation learning, semi- supervised learning and interpretation. InProceedings of the 59th Annual Meeting of the Association for Computa- tional Linguistics and...
work page 2021
-
[34]
FlashAttention-2: Faster attention with better par- allelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better par- allelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.