Recognition: 2 theorem links
· Lean TheoremMetal-Sci: A Scientific Compute Benchmark for Evolutionary LLM Kernel Search on Apple Silicon
Pith reviewed 2026-05-12 04:05 UTC · model grok-4.3
The pith
A held-out scoring function catches generalization failures missed by in-distribution metrics in LLM kernel search on Apple Silicon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
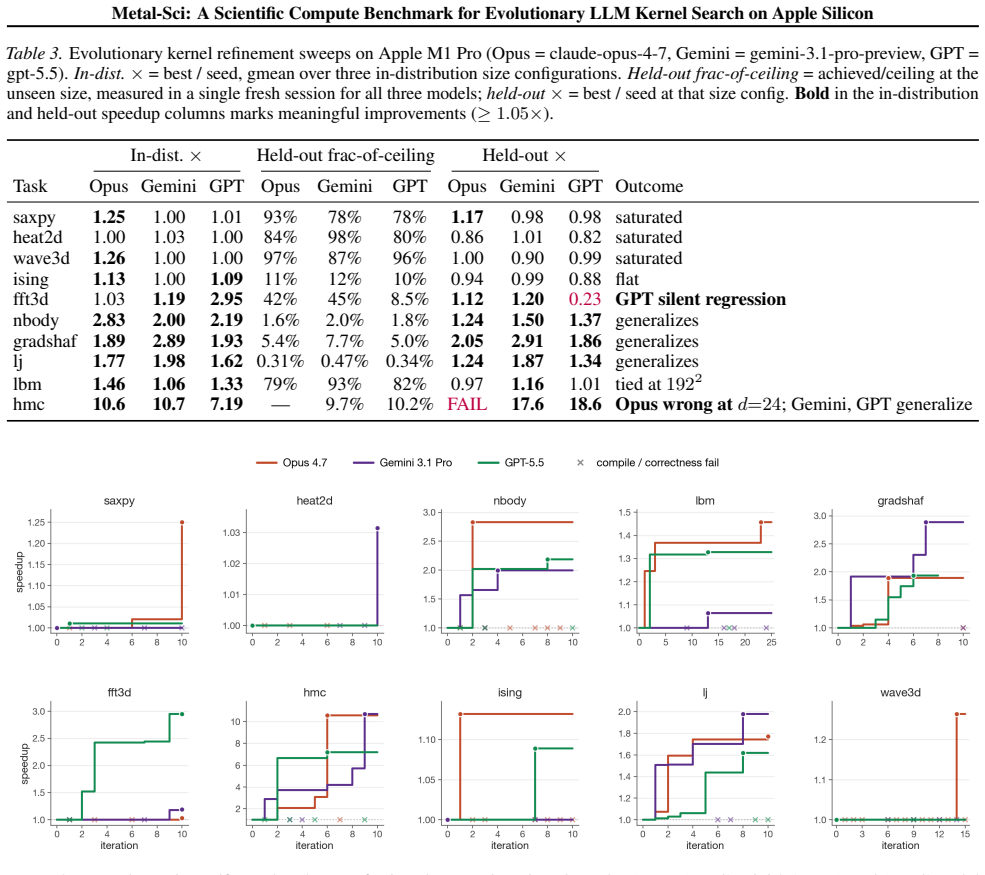
The central claim is that the held-out gate scoring function Φ_T functions as a cheap mechanical oversight primitive on this automatic search loop. It is evaluated once at end-of-run on a configuration the agent never sees during search. This catches examples such as an Opus template for HMC that returns wrong samples at unseen dimensions and a GPT FFT3D best that achieves 2.95× speedup in-distribution but collapses to 0.23× on a 256^3 held-out cube, issues that in-distribution scores alone cannot reveal.
What carries the argument
The held-out gate scoring function Φ_T, which evaluates each final candidate kernel on an unseen problem size after search completes to identify non-generalizing or incorrect solutions.
If this is right
- In-distribution speedups alone are insufficient to validate LLM-optimized kernels.
- Post-search evaluation on held-out sizes can identify incorrect or non-generalizing implementations.
- The benchmark enables systematic comparison of different LLMs on kernel search tasks.
- Roofline-anchored fitness provides a hardware-grounded way to score optimizations across diverse tasks.
- Automatic evolutionary search loops require explicit generalization gates to avoid accepting brittle kernels.
Where Pith is reading between the lines
- Similar held-out evaluation could be added to other LLM-driven code optimization pipelines for different languages or hardware.
- The approach highlights a general need for post-search validation steps when using evolutionary methods with LLMs.
- Benchmarks of this type could be extended with more varied held-out cases to better simulate deployment conditions.
- The oversight primitive suggests a template for monitoring search processes that rely on learned models rather than fixed rules.
Load-bearing premise
The selected held-out sizes differ sufficiently from in-distribution sizes to expose real generalization failures, and roofline-anchored fitness scores predict useful performance outside the benchmark.
What would settle it
An optimized kernel that passes both in-distribution scoring and the held-out gate yet produces incorrect results or poor performance on a further unseen size or real scientific workload.
Figures






read the original abstract
We present Metal-Sci, a 10-task benchmark of scientific Apple Silicon Metal compute kernels spanning six optimization regimes (stencils, all-pairs in $n$-body problems, multi-field Boltzmann, neighbor-list molecular dynamics, multi-kernel PDE, FFT). Each task ships a CPU reference, a roofline-anchored fitness function, and a held-out generalization size. We pair the benchmark with a lightweight harness for automatic kernel search that runtime-compiles each candidate, scores it against the roofline across multiple sizes, and feeds structured compile and per-size correctness diagnostics back to a frozen LLM driving a $(1{+}1)$ evolutionary loop. We report matched single-model sweeps of Claude Opus 4.7, Gemini 3.1 Pro, and GPT 5.5 on M1 Pro: in-distribution self-speedups span $1.00\times$ to $10.7\times$. Beyond raw speedup, our central methodological claim is structural: the held-out gate scoring function $\Phi_\mathcal{T}$ (evaluated once at end-of-run on a configuration the agent never sees during search) functions as a cheap mechanical oversight primitive on this automatic search loop, catching e.g. an Opus template <uint D> HMC win that returns wrong samples at unseen dimensions, and a GPT FFT3D best that wins in-distribution at $2.95\times$ speedup but collapses to $0.23\times$ on a $256^3$ held-out cube, a silent regression that the in-distribution score alone cannot see. Code at https://github.com/vicgalle/metal-sci-kernels
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Metal-Sci, a 10-task benchmark for scientific Metal compute kernels on Apple Silicon covering regimes like stencils, n-body, Boltzmann, MD, PDE, and FFT. Each task includes a CPU reference, roofline-anchored fitness, and held-out size. It describes an LLM-driven (1+1) evolutionary search harness that compiles and scores candidates, reporting in-distribution speedups up to 10.7× for models including Claude Opus 4.7, Gemini 3.1 Pro, and GPT 5.5. The key claim is that the held-out gate Φ_T acts as an oversight primitive, detecting issues like incorrect HMC samples at unseen dimensions and performance drops (e.g., 2.95× to 0.23× on 256^3 FFT3D) missed by in-distribution scoring.
Significance. Should the empirical results hold and the held-out tests demonstrate reliable detection of generalization failures, the work offers a valuable benchmark and methodology for overseeing LLM-based automatic kernel optimization in scientific computing. The open code repository strengthens the contribution by supporting reproducibility. This could have implications for developing more robust automated systems for hardware-specific optimizations.
major comments (2)
- Abstract: The central claim that Φ_T functions as a cheap mechanical oversight primitive catching silent regressions requires that the held-out sizes are in a meaningfully different regime from those used in the roofline-anchored fitness during the evolutionary search. The abstract provides one concrete example (256^3 for the GPT FFT3D case) but does not include or reference a table quantifying the in-distribution sizes for all 10 tasks or the ratios to held-out sizes. Without this, it is unclear whether the performance collapse represents a search-specific failure uniquely detected by Φ_T or an effect of unmodeled factors at larger scales, as noted in the roofline model validation.
- §3 (Benchmark and Harness): The methods description of the (1+1) evolutionary loop and fitness scoring must explicitly list the sizes used for in-distribution roofline evaluation per task versus the single held-out size for Φ_T. This information is load-bearing for verifying that the observed regressions (e.g., the Opus HMC and GPT FFT3D cases) are not artifacts of bandwidth saturation or precision effects already present on the same roofline segment.
minor comments (2)
- The abstract states 'six optimization regimes' but then lists seven items (stencils, all-pairs, multi-field Boltzmann, neighbor-list MD, multi-kernel PDE, FFT); clarify the exact grouping and mapping to tasks in the introduction or §2.
- Model names (Claude Opus 4.7, Gemini 3.1 Pro, GPT 5.5) should be accompanied by exact version strings or dates in the experimental setup to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each point below and will revise the manuscript to improve clarity and verifiability of the size regimes.
read point-by-point responses
-
Referee: Abstract: The central claim that Φ_T functions as a cheap mechanical oversight primitive catching silent regressions requires that the held-out sizes are in a meaningfully different regime from those used in the roofline-anchored fitness during the evolutionary search. The abstract provides one concrete example (256^3 for the GPT FFT3D case) but does not include or reference a table quantifying the in-distribution sizes for all 10 tasks or the ratios to held-out sizes. Without this, it is unclear whether the performance collapse represents a search-specific failure uniquely detected by Φ_T or an effect of unmodeled factors at larger scales, as noted in the roofline model validation.
Authors: We agree that the abstract would benefit from an explicit reference to the size regimes. The manuscript includes Table 1, which quantifies the in-distribution sizes used for roofline-anchored fitness evaluation across all 10 tasks together with the single held-out size for Φ_T. The held-out sizes are selected to probe meaningfully different regimes, consistent with the roofline model validation. We will revise the abstract to reference Table 1 and add a brief statement summarizing the size ratios, thereby clarifying that the reported regressions (including the GPT FFT3D case) represent search-specific generalization failures detected by Φ_T rather than unmodeled scale effects. revision: yes
-
Referee: §3 (Benchmark and Harness): The methods description of the (1+1) evolutionary loop and fitness scoring must explicitly list the sizes used for in-distribution roofline evaluation per task versus the single held-out size for Φ_T. This information is load-bearing for verifying that the observed regressions (e.g., the Opus HMC and GPT FFT3D cases) are not artifacts of bandwidth saturation or precision effects already present on the same roofline segment.
Authors: We agree that §3 should make this information explicit for transparency. We will revise the methods section to include a clear enumeration (or excerpt from Table 1) contrasting the in-distribution sizes used for fitness scoring during evolutionary search with the held-out size for Φ_T on each task. This addition will enable readers to confirm that the observed regressions in the HMC and FFT3D examples lie outside the in-distribution regimes and are not attributable to bandwidth saturation or precision effects already present on the same roofline segment. revision: yes
Circularity Check
No circularity; empirical claim stands on reported observations
full rationale
The paper's central methodological claim—that the held-out gate Φ_T catches silent regressions missed by in-distribution roofline scores—is presented as an empirical observation from concrete runs (Opus HMC template returning wrong samples at unseen dimensions; GPT FFT3D collapsing from 2.95× to 0.23× on 256³). No derivation chain reduces this to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation. The benchmark tasks, roofline fitness, (1+1) evolutionary loop, and held-out evaluation are described as independent components; speedups and failure cases are reported outcomes rather than quantities forced by the paper's own equations or prior author work. The setup is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the held-out gate scoring function ΦT ... functions as a cheap mechanical oversight primitive on this automatic search loop
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
six optimization regimes (stencils, all-pairs, multi-field Boltzmann, neighbor-list MD, multi-kernel PDE, FFT)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pawan and Dupont, Emilien and Ruiz, Francisco J
Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Balog, Matej and Kumar, M. Pawan and Dupont, Emilien and Ruiz, Francisco J. R. and Ellenberg, Jordan and Wang, Pengming and Fawzi, Omar and Kohli, Pushmeet and Fawzi, Alhussein , journal =. Mathematical discoveries from program search with large language models , year =
-
[2]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alphaevolve: A coding agent for scientific and algorithmic discovery , author=. arXiv preprint arXiv:2506.13131 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Twelfth International Conference on Learning Representations , year =
Ma, Yecheng Jason and Liang, William and Wang, Guanzhi and Huang, De-An and Bastani, Osbert and Jayaraman, Dinesh and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , title =. The Twelfth International Conference on Learning Representations , year =
-
[4]
Advances in Neural Information Processing Systems , year =
Ye, Haoran and Wang, Jiarui and Cao, Zhiguang and Berto, Federico and Hua, Chuanbo and Kim, Haeyeon and Park, Jinkyoo and Song, Guojie , title =. Advances in Neural Information Processing Systems , year =
-
[5]
and Zhou, Denny and Chen, Xinyun , title =
Yang, Chengrun and Wang, Xuezhi and Lu, Yifeng and Liu, Hanxiao and Le, Quoc V. and Zhou, Denny and Chen, Xinyun , title =. The Twelfth International Conference on Learning Representations , year =
-
[6]
Transactions on Machine Learning Research , year =
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , title =. Transactions on Machine Learning Research , year =
-
[7]
Advances in Neural Information Processing Systems , year =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , title =. Advances in Neural Information Processing Systems , year =
-
[8]
Cooperation and Exploitation in
Gallego, V. Cooperation and Exploitation in. arXiv preprint arXiv:2603.19453 , year =
- [9]
-
[10]
Beyer, Hans-Georg and Schwefel, Hans-Paul , title =. Natural Computing , volume =
-
[11]
Anne Ouyang and Simon Guo and Simran Arora and Alex L Zhang and William Hu and Christopher Re and Azalia Mirhoseini , booktitle=. KernelBench: Can. 2025 , url=
work page 2025
-
[12]
Fast n-body simulation with CUDA. GPU Gems 3 , author=. 2007 , publisher=
work page 2007
- [13]
-
[14]
Computers & Mathematics with Applications , volume=
Multi-thread implementations of the lattice Boltzmann method on non-uniform grids for CPUs and GPUs , author=. Computers & Mathematics with Applications , volume=. 2011 , publisher=
work page 2011
-
[15]
Journal of computational physics , volume=
General purpose molecular dynamics simulations fully implemented on graphics processing units , author=. Journal of computational physics , volume=. 2008 , publisher=
work page 2008
-
[16]
arXiv preprint arXiv:2510.03760 , year=
Evoengineer: Mastering automated cuda kernel code evolution with large language models , author=. arXiv preprint arXiv:2510.03760 , year=
-
[17]
Kalade, Sarunas and Schelle, Graham , journal=
-
[18]
Towards robust agentic cuda kernel benchmarking, verification, and optimization , author=. arXiv preprint arXiv:2509.14279 , year=
-
[19]
arXiv preprint arXiv:2603.08721 , year=
KernelCraft: Benchmarking for Agentic Close-to-Metal Kernel Generation on Emerging Hardware , author=. arXiv preprint arXiv:2603.08721 , year=
-
[20]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Tritonbench: Benchmarking large language model capabilities for generating triton operators , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[21]
Multikernelbench: A multi-platform benchmark for kernel generation , author=. arXiv e-prints, pp. arXiv--2507 , year=
-
[22]
Mark Saroufim and Jiannan Wang and Bert Maher and Sahan Paliskara and Laura Wang and Shahin Sefati and Manuel Candales , title =. 2025 , url =
work page 2025
-
[23]
Communications of the ACM , volume=
Roofline: an insightful visual performance model for multicore architectures , author=. Communications of the ACM , volume=. 2009 , publisher=
work page 2009
-
[24]
Proceedings of the 2008 ACM/IEEE Conference on Supercomputing , articleno =
Datta, Kaushik and Murphy, Mark and Volkov, Vasily and Williams, Samuel and Carter, Jonathan and Oliker, Leonid and Patterson, David and Shalf, John and Yelick, Katherine , title =. Proceedings of the 2008 ACM/IEEE Conference on Supercomputing , articleno =. 2008 , isbn =
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.