Recognition: no theorem link
Security Risks in Tool-Enabled AI Agents: A Systematic Analysis of Privileged Execution Environments
Pith reviewed 2026-05-12 02:40 UTC · model grok-4.3
The pith
Tool-enabled AI agents in cloud environments face security risks mainly from over-privileged tools, capability-intent mismatches, and ambient authority leakage rather than novel vulnerabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A structured analysis of cloud-hosted tool-enabled AI agents reveals a taxonomy of security risks that arise primarily from over-privileged tools, capability-intent mismatches, and ambient authority leakage within execution environments; these patterns are illustrated through three representative scenarios and a small controlled experiment that also shows the effect of basic mitigations, from which the authors derive practical guidelines for more secure cloud deployments.
What carries the argument
A taxonomy of risk categories for tool-enabled agents operating in privileged execution environments, used to classify and illustrate how over-privileged tools, intent mismatches, and authority leaks produce side-effecting security issues.
If this is right
- Over-privileged tools enable agents to execute unintended side-effecting operations beyond their intended scope.
- Capability-intent mismatches allow agents to access permissions that do not align with their stated goals.
- Ambient authority leakage occurs when execution environments expose credentials or rights unnecessarily to the agent.
- Lightweight mitigations can reduce risk manifestation in controlled settings, though they involve tradeoffs with agent functionality.
- Practical design guidelines can guide more secure cloud deployment of such agents without relying on discovery of new vulnerabilities.
Where Pith is reading between the lines
- Standard access-control practices from non-AI systems may transfer directly to agent environments rather than requiring entirely new mechanisms.
- Cloud providers could offer restricted sandboxes specifically tuned for AI agents to limit ambient authority by default.
- Intent-verification layers added to agent tool-calling interfaces could reduce mismatch risks before deployment.
- Larger empirical studies across varied production workloads would be needed to confirm whether the identified patterns remain dominant at scale.
Load-bearing premise
The three representative agent scenarios and small controlled experiment are assumed to capture the main risk patterns that would appear in production cloud deployments of tool-enabled agents.
What would settle it
A production-scale study of deployed cloud AI agents that finds novel vulnerabilities to be the dominant cause of security incidents rather than over-privilege, mismatches, or ambient leaks.
Figures
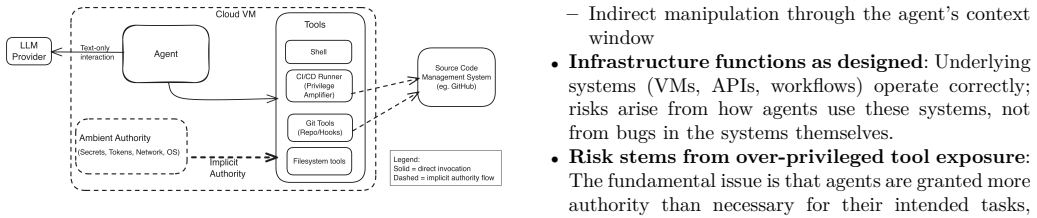
read the original abstract
Tool-enabled AI agents are increasingly deployed in cloud-hosted environments and offered as services, where they perform side-effecting operations through privileged tools within execution environments. While such agents enable powerful automation, the security implications of hosting autonomous agents in privileged execution environments are not yet fully explored. This paper presents a structured analysis of security risks associated with cloud-hosted AI agents. We introduce a taxonomy of risk categories, illustrate these risks through three representative agent scenarios, and discuss mitigation strategies along with their tradeoffs. A small controlled experiment empirically illustrates risk manifestation and the effect of lightweight mitigations in this setup. Our analysis suggests that many risks in autonomous cloud agents arise not from novel vulnerabilities, but from over-privileged tools, capability-intent mismatches, and ambient authority leakage in execution environments. Based on these findings, we derive practical design guidelines for deploying AI agents in the cloud more securely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that security risks in cloud-hosted tool-enabled AI agents primarily arise from over-privileged tools, capability-intent mismatches, and ambient authority leakage in execution environments rather than novel vulnerabilities. It introduces a taxonomy of risk categories, illustrates the risks via three representative agent scenarios, discusses mitigation strategies and tradeoffs, and presents a small controlled experiment to demonstrate risk manifestation and the impact of lightweight mitigations. From this, the authors derive practical design guidelines for more secure deployment of such agents.
Significance. If the analysis and experiment hold, the work provides a useful shift in perspective for the field by emphasizing configuration and privilege issues over zero-day vulnerabilities, which could inform more effective security practices for autonomous agents in cloud settings. The taxonomy and guidelines offer concrete starting points for practitioners, though their broader applicability remains to be validated.
major comments (2)
- The central claim (that risks stem mainly from over-privileged tools, mismatches, and leakage rather than novel vulnerabilities) rests on the three representative scenarios plus the small controlled experiment being representative of production cloud deployments. The experiment description provides no details on controls, statistical power, sampling of tool sets, execution environments, or autonomy levels, leaving open the possibility that other patterns (e.g., supply-chain issues or scale-dependent behaviors) dominate in practice.
- The taxonomy is presented as derived from the analysis of the scenarios and experiment, but the manuscript does not include an explicit validation step against a broader or more diverse dataset of real-world tool-enabled agents, which weakens the systematic nature of the contribution.
minor comments (2)
- Clarify the exact scope and limitations of the 'small controlled experiment' in the methods or results section to allow readers to assess its illustrative value.
- Ensure all mitigation tradeoffs are explicitly linked back to the taxonomy categories for easier reference.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We respond point-by-point to the major comments below, indicating revisions where we agree changes are warranted.
read point-by-point responses
-
Referee: The central claim (that risks stem mainly from over-privileged tools, mismatches, and leakage rather than novel vulnerabilities) rests on the three representative scenarios plus the small controlled experiment being representative of production cloud deployments. The experiment description provides no details on controls, statistical power, sampling of tool sets, execution environments, or autonomy levels, leaving open the possibility that other patterns (e.g., supply-chain issues or scale-dependent behaviors) dominate in practice.
Authors: We agree that the experiment section requires additional detail and explicit scoping. The experiment functions as a controlled illustration of risk manifestation and mitigation effects in a defined setup, not as a comprehensive or statistically powered evaluation of production systems. We will revise the manuscript to: (1) describe the controls (fixed set of 10 representative tools, isolated containerized execution environment with explicit privilege boundaries, and bounded autonomy levels), (2) state the absence of statistical power or broad sampling, and (3) clarify that the central claim is grounded in the logical analysis of the three scenarios, which reflect documented patterns from existing agent frameworks. We will also note that while supply-chain or scale-dependent issues may exist, they fall outside the paper's focus on inherent privilege and authority leakage in tool-enabled cloud agents. This revision will prevent overgeneralization. revision: yes
-
Referee: The taxonomy is presented as derived from the analysis of the scenarios and experiment, but the manuscript does not include an explicit validation step against a broader or more diverse dataset of real-world tool-enabled agents, which weakens the systematic nature of the contribution.
Authors: The taxonomy was derived deductively by extracting recurring risk patterns from the three scenarios, which were chosen to span varying privilege levels, capability-intent alignments, and execution contexts drawn from current cloud agent literature and deployments. No separate large-scale validation dataset was used. We will revise the manuscript to: (1) detail the derivation process from the scenarios, (2) justify scenario selection by reference to common frameworks, and (3) add an explicit limitations paragraph stating that broader empirical validation against diverse real-world agent corpora is left to future work. This maintains the contribution as a structured analytical framework while addressing the concern about scope. revision: yes
Circularity Check
No significant circularity in analysis or taxonomy
full rationale
The paper is a qualitative security analysis that introduces a risk taxonomy, illustrates it via three scenarios and a small controlled experiment, and derives guidelines from established concepts in privileged execution and ambient authority. No equations, fitted parameters, predictions, or self-referential definitions appear; claims rest on external security principles rather than reducing to the paper's own inputs by construction. The derivation chain is therefore self-contained and independent of any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GitHub, “About coding agent.” [Online]. Available: https: //docs.github.com/en/enterprise-cloud@latest/copilot/concept s/agents/coding-agent/about-coding-agent
-
[2]
Codex web: Delegate to codex in the cloud
OpenAI, “Codex web: Delegate to codex in the cloud.” [Online]. Available: https://developers.openai.com/codex/cloud/
-
[3]
Bridging knowledge gaps in llms via function calls,
K. Basu, “Bridging knowledge gaps in llms via function calls,” inProceedings of the 33rd ACM International Conference on Information and Knowledge Management, ser. CIKM ’24. New York, NY, USA: Association for Computing Machinery, 2024, pp. 5556–5557. [Online]. Available: https: //doi.org/10.1145/3627673.3679070
-
[4]
The lethal trifecta for ai agents: private data, untrusted content, and external communication
S. Willison, “The lethal trifecta for ai agents: private data, untrusted content, and external communication.” [Online]. Available: https://simonwillison.net/2025/Jun/16/the-lethal- trifecta/
work page 2025
-
[5]
The ROME incident: When the AI agent becomes the insider threat,
SC Media, “The ROME incident: When the AI agent becomes the insider threat,” SC Media, 2025, online article
work page 2025
-
[6]
Agentic ai – threats and mitigations
OWASP GenAI Security Project, “Agentic ai – threats and mitigations.” [Online]. Available: https://genai.owasp.org/reso urce/agentic-ai-threats-and-mitigations/
-
[7]
The emerged security and privacy of llm agent: A survey with case studies,
F. He, T. Zhu, D. Ye, B. Liu, W. Zhou, and P. S. Yu, “The emerged security and privacy of llm agent: A survey with case studies,”ACM Computing Surveys, vol. 58, no. 6, pp. 1–36, dec
-
[8]
Available: http://dx.doi.org/10.1145/3773080
[Online]. Available: http://dx.doi.org/10.1145/3773080
-
[9]
V. S. Narajala and O. Narayan, “Securing agentic ai: A comprehensive threat model and mitigation framework for generative ai agents,” 2025. [Online]. Available: https: //arxiv.org/abs/2504.19956
-
[10]
Ai agents under threat: A survey of key security challenges and future pathways,
Z. Deng, Y. Guo, C. Han, W. Ma, J. Xiong, S. Wen, and Y. Xiang, “Ai agents under threat: A survey of key security challenges and future pathways,”ACM Computing Surveys, vol. 57, no. 7, pp. 1–36, feb 2025, article 182. [Online]. Available: https://doi.org/10.1145/3716628
-
[11]
Ai agents vs. agentic ai: A conceptual taxonomy, applications and challenges,
R. Sapkota, K. I. Roumeliotis, and M. Karkee, “Ai agents vs. agentic ai: A conceptual taxonomy, applications and challenges,”Information Fusion, vol. 126, p. 103599, feb 2026. [Online]. Available: http://dx.doi.org/10.1016/j.inffus.2025.103 599
-
[12]
Anthropic, “Building effective agents.” [Online]. Available: https://www.anthropic.com/engineering/building-effective- agents
-
[13]
Securing the model context protocol (mcp): Risks, controls, and governance,
H. Errico, J. Ngiam, and S. Sojan, “Securing the model context protocol (mcp): Risks, controls, and governance,” 2025. [Online]. Available: https://arxiv.org/abs/2511.20920
-
[14]
Secalign: Defending against prompt injection with preference optimization,
S. Chen, A. Zharmagambetov, S. Mahloujifar, K. Chaudhuri, D. Wagner, and C. Guo, “Secalign: Defending against prompt injection with preference optimization,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communi- cations Security, 2025, pp. 2833–2847
work page 2025
-
[15]
Agentrim: Tool risk mitigation for agentic ai,
R. Betser, S. Bose, A. Giloni, C. Picardi, S. Padakandla, and R. Vainshtein, “Agentrim: Tool risk mitigation for agentic ai,”
-
[16]
Available: https://arxiv.org/abs/2601.12449
[Online]. Available: https://arxiv.org/abs/2601.12449
-
[17]
Benchmarking and defending against indirect prompt injection attacks on large language models,
J. Yi, Y. Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu, “Benchmarking and defending against indirect prompt injection attacks on large language models,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, 2025, pp. 1809–1820
work page 2025
-
[18]
From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,
M. A. Ferrag, N. Tihanyi, D. Hamouda, L. Maglaras, A. Lakas, and M. Debbah, “From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,”ICT Express,
-
[19]
Available: https://www.sciencedirect.com/scie nce/article/pii/S2405959525001997
[Online]. Available: https://www.sciencedirect.com/scie nce/article/pii/S2405959525001997
-
[20]
Principles and implementation techniques of software- based fault isolation,
G. Tan, “Principles and implementation techniques of software- based fault isolation,”Foundations and Trends in Privacy and Security, vol. 1, no. 3, pp. 171–269, 2017
work page 2017
-
[21]
Haicosystem: An ecosystem for sandboxing safety risks in human-ai interactions,
X. Zhou, H. Kim, F. Brahman, L. Jiang, H. Zhu, X. Lu, F. Xu, B. Y. Lin, Y. Choi, N. Mireshghallah, R. Le Bras, and M. Sap, “Haicosystem: An ecosystem for sandboxing safety risks in human-ai interactions,” inProceedings of the Workshop on Towards Safe & Trustworthy Agents, NeurIPS 2024, 2024, arXiv:2409.16427. [Online]. Available: https://arxiv.org/abs/2409.16427
-
[22]
cellmate: Sandboxing browser ai agents.arXiv preprint arXiv:2512.12594, 2025
L. Meng, H. Feng, I. Shumailov, and E. Fernandes, “cellmate: Sandboxing browser ai agents,” 2025. [Online]. Available: https://arxiv.org/abs/2512.12594
-
[23]
Ambush from all sides: Understanding security threats in open-source software ci/cd pipelines,
Z. Pan, W. Shen, X. Wang, Y. Yang, R. Chang, Y. Liu, C. Liu, Y. Liu, and K. Ren, “Ambush from all sides: Understanding security threats in open-source software ci/cd pipelines,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 1, pp. 403–418, 2023
work page 2023
-
[24]
S. M. Saleh, N. Madhavji, and J. Steinbacher, “A system- atic literature review on continuous integration and deploy- ment (ci/cd) for secure cloud computing,”arXiv preprint arXiv:2506.08055, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.