Recognition: 2 theorem links
· Lean TheoremLEVI: Stronger Search Architectures Can Substitute for Larger LLMs in Evolutionary Search
Pith reviewed 2026-05-12 02:55 UTC · model grok-4.3
The pith
LEVI demonstrates that stronger evolutionary search architectures can substitute for larger LLMs, achieving better results at far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
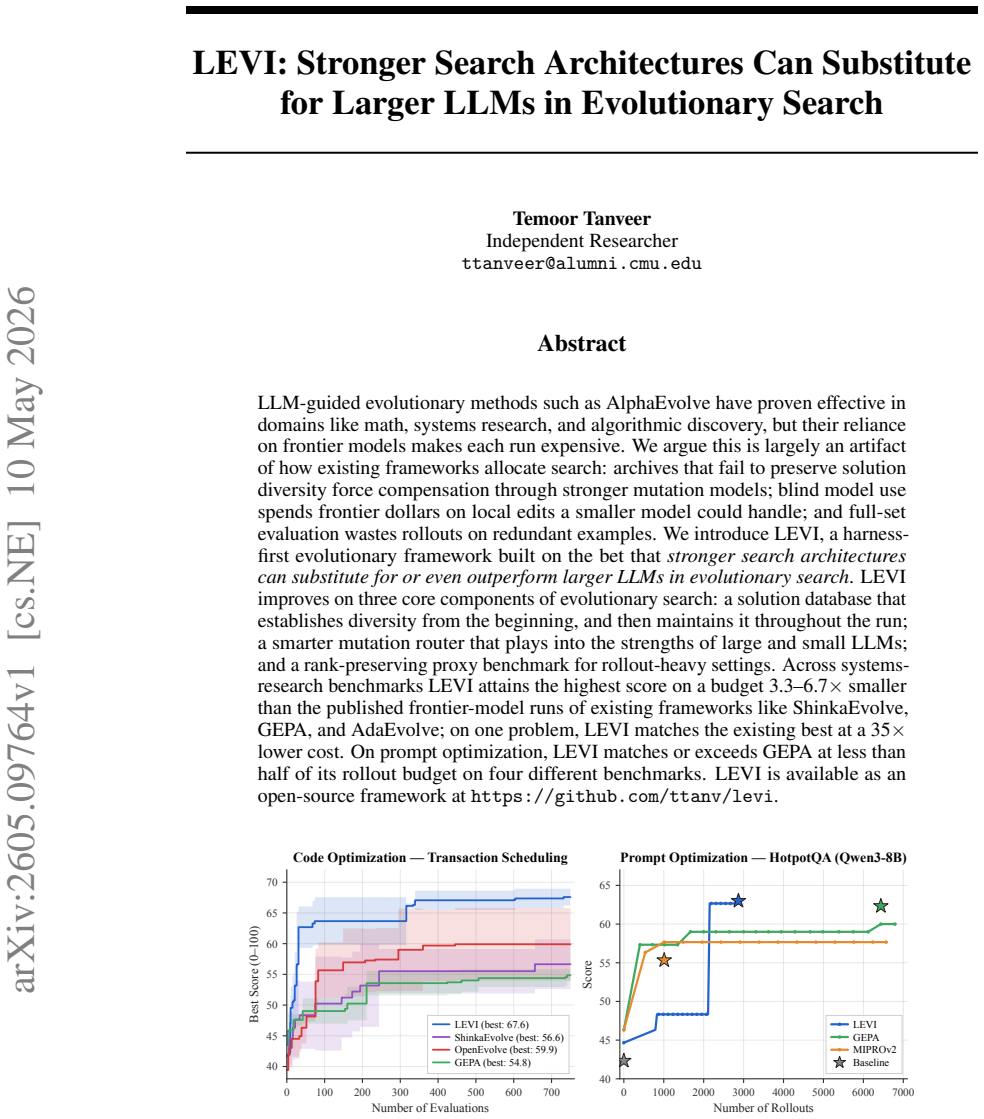
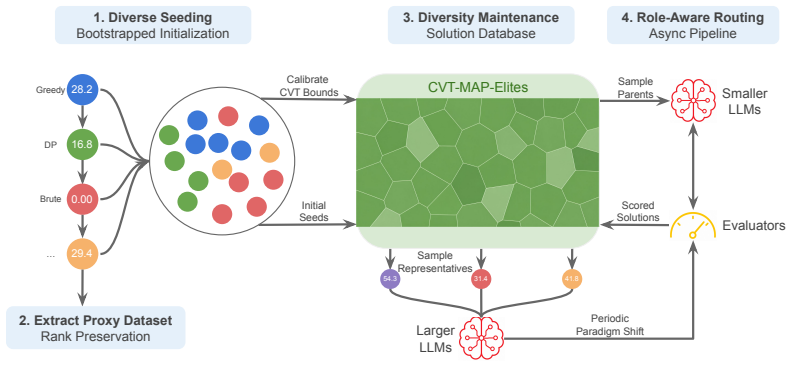
LEVI is an evolutionary framework built on the idea that architectural strength can replace model size. Its key features include a solution database that preserves diversity from the start and throughout, a mutation router that assigns tasks to large or small LLMs based on their strengths, and a rank-preserving proxy for efficient benchmarking in rollout-heavy scenarios. Experiments show it reaches the highest scores on systems benchmarks with 3.3-6.7 times smaller budgets than prior methods, matching the best result in one case at 35 times lower cost, and performs comparably or better on prompt optimization with half the budget.
What carries the argument
The combination of a diversity-establishing and maintaining solution database, a strength-aware mutation router for large and small LLMs, and a rank-preserving proxy benchmark.
Load-bearing premise
The reported improvements stem directly from the three architectural innovations rather than variations in baseline implementations, problem sets, or experimental conditions.
What would settle it
Reproducing the baseline methods with identical problem selections, evaluation protocols, and model versions would eliminate the performance and cost advantages claimed for LEVI.
Figures






read the original abstract
LLM-guided evolutionary methods such as AlphaEvolve have proven effective in domains like math, systems research, and algorithmic discovery, but their reliance on frontier models makes each run expensive. We argue this is largely an artifact of how existing frameworks allocate search: archives that fail to preserve solution diversity force compensation through stronger mutation models; blind model use spends frontier dollars on local edits a smaller model could handle; and full-set evaluation wastes rollouts on redundant examples. We introduce LEVI, a harness-first evolutionary framework built on the bet that stronger search architectures can substitute for or even outperform larger LLMs in evolutionary search. LEVI improves on three core components of evolutionary search: a solution database that establishes diversity from the beginning, and then maintains it throughout the run; a smarter mutation router that plays into the strengths of large and small LLMs; and a rank-preserving proxy benchmark for rollout-heavy settings. Across systems-research benchmarks LEVI attains the highest score on a budget 3.3-6.7x smaller than the published frontier-model runs of existing frameworks like ShinkaEvolve, GEPA, and AdaEvolve; on one problem, LEVI matches the existing best at a 35x lower cost. On prompt optimization, LEVI matches or exceeds GEPA at less than half of its rollout budget on four different benchmarks. LEVI is available as an open-source framework at https://github.com/ttanv/levi.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LEVI, a harness-first evolutionary framework for LLM-guided search that augments three components: a solution database that enforces diversity from initialization onward, a mutation router that routes edits to large or small LLMs based on task demands, and a rank-preserving proxy benchmark that reduces rollout costs while preserving relative ordering. The central empirical claim is that these changes allow LEVI to reach the highest scores on systems-research benchmarks at 3.3-6.7x lower budget than published frontier-model runs of ShinkaEvolve, GEPA, and AdaEvolve (with one problem matched at 35x lower cost) and to match or exceed GEPA on four prompt-optimization benchmarks at less than half the rollout budget. The framework is released open-source.
Significance. If the performance advantages survive controlled re-evaluation, the result would be significant for evolutionary computation and LLM-augmented discovery: it supplies concrete evidence that search-architecture refinements can substitute for model scale, lowering the cost barrier for math, systems, and algorithmic tasks. The open-source release and the explicit framing against published baselines are strengths that would aid adoption and follow-on work.
major comments (2)
- [Experimental Results] Experimental Results section: all quantitative claims (3.3-6.7x budget reduction, 35x on one problem, half rollout budget on prompt optimization) rest on comparisons to previously published numbers from ShinkaEvolve, GEPA, and AdaEvolve rather than re-executions of those baselines on the identical benchmark instances, evaluation protocols, rollout counts, and LLM checkpoints used by LEVI. This is load-bearing for the central attribution that the three architectural changes (diversity database, mutation router, rank-preserving proxy) are responsible for the gains; uncontrolled differences in problem difficulty or metric definitions could produce the same cost reductions.
- [Method and Evaluation] Method and Evaluation sections: no ablation tables or controlled variants are presented that isolate the contribution of each of the three proposed changes while holding the LLM size, total rollout budget, and problem set fixed. Without such isolations, the claim that stronger search architecture substitutes for larger LLMs remains correlational.
minor comments (3)
- [Abstract] Abstract: the phrases 'highest score' and 'matches the existing best' would be clearer if the exact metric (e.g., pass@1, success rate) and the number of independent runs were stated.
- [Figures and Tables] Figure captions and tables: several budget-vs-performance plots lack error bars or run-to-run variance, making it hard to judge whether the reported margins exceed noise.
- [Related Work] Related Work: the positioning against AlphaEvolve and other LLM-evolution frameworks could include a short table summarizing their archive, mutation, and evaluation strategies for direct comparison with LEVI's three changes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments correctly identify areas where stronger controls would improve the attribution of our results. We address each point below and have prepared revisions to the manuscript that incorporate additional discussion and new experiments where feasible.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: all quantitative claims (3.3-6.7x budget reduction, 35x on one problem, half rollout budget on prompt optimization) rest on comparisons to previously published numbers from ShinkaEvolve, GEPA, and AdaEvolve rather than re-executions of those baselines on the identical benchmark instances, evaluation protocols, rollout counts, and LLM checkpoints used by LEVI. This is load-bearing for the central attribution that the three architectural changes (diversity database, mutation router, rank-preserving proxy) are responsible for the gains; uncontrolled differences in problem difficulty or metric definitions could produce the same cost reductions.
Authors: We agree that re-executing the baselines under identical conditions would provide the most direct evidence. However, the published numbers come from the original authors' implementations and hardware setups, and repeating those runs at frontier scale would require resources beyond the scope of this work. In the revised manuscript we have added a dedicated subsection that enumerates known differences in problem instances, evaluation protocols, and model checkpoints, together with an explicit discussion of how these factors could affect the reported speed-ups. We also emphasize that the open-source release of LEVI enables independent re-evaluation by the community. revision: partial
-
Referee: [Method and Evaluation] Method and Evaluation sections: no ablation tables or controlled variants are presented that isolate the contribution of each of the three proposed changes while holding the LLM size, total rollout budget, and problem set fixed. Without such isolations, the claim that stronger search architecture substitutes for larger LLMs remains correlational.
Authors: We concur that isolating each component is necessary to move beyond correlational claims. The original submission reported only the full-system results. For the revision we have added a new ablation study section that holds LLM size, total rollout budget, and benchmark instances fixed while individually enabling or disabling the diversity database, the mutation router, and the rank-preserving proxy. The resulting tables quantify the marginal contribution of each change and directly support the architectural-substitution thesis. revision: yes
Circularity Check
No significant circularity; empirical claims rest on benchmark comparisons
full rationale
The paper introduces LEVI as an empirical evolutionary search framework with three described architectural components (diversity database, mutation router, rank-preserving proxy) and reports performance gains via direct comparisons to published baseline runs on systems-research and prompt-optimization benchmarks. No equations, derivations, fitted parameters, or self-referential definitions appear in the abstract or described content. The central claims are experimental outcomes rather than reductions of predictions to inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The derivation chain is therefore self-contained against external benchmarks, consistent with the default expectation for non-circular empirical systems papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-guided mutation and selection can discover high-quality solutions when diversity is maintained.
- domain assumption A rank-preserving proxy benchmark can substitute for full evaluation without changing relative ordering.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesLEVI improves on three core components of evolutionary search: a solution database that establishes diversity from the beginning... a smarter mutation router... and a rank-preserving proxy benchmark
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoesa CVT-MAP-Elites archive preserves diversity by construction
Reference graph
Works this paper leans on
-
[1]
PE” = punctuated equilibrium; “cascade
Spot Multi uses five custom AST extractors capturing state-machine structure rather than the generic AST features. Benchmark Budget Mutation models AST descriptors Score-key descrip- tors Cloudcast $3.00 Qwen3-30B loops, branches, math ops 5 per-cloud cost columns EPLB $4.50 MiMo-v2 + Qwen3-30B loop nesting, cyclomatic, math ops exec. time + 3 work- loads...
-
[2]
Your code must be COMPLETE and RUNNABLE as a standalone file
-
[3]
Include ALL necessary imports at the top of your code
-
[4]
The function signature must match exactly what is specified
-
[5]
‘‘‘ DO NOT include any explanation or text outside the code block
Ensure there are no syntax errors (matching parentheses, quotes, indentation) Your response must follow this structure: ‘‘‘python # all necessary imports here def function_name(...): # your complete implementation return ... ‘‘‘ DO NOT include any explanation or text outside the code block. DO NOT assume any imports are already available - include every i...
-
[6]
The resulting code must be COMPLETE and RUNNABLE
-
[7]
Do NOT remove import statements unless replacing with different imports
-
[8]
Ensure your replacements maintain valid Python syntax 17
-
[9]
If adding new functionality that needs imports, add them with a separate SEARCH/REPLACE block RULES:
-
[10]
Make SURGICAL changes - small, focused edits (5-20 lines max per block)
-
[11]
Copy the SEARCH section EXACTLY from the original (including whitespace/indentation)
-
[12]
Use multiple small SEARCH/REPLACE blocks instead of one large block
-
[13]
Start your response immediately with <<<<<<< SEARCH
-
[14]
Do NOT include any explanation or text outside the blocks
-
[15]
Do NOT use ‘‘‘python code blocks E.4 Paradigm shift (PE trigger) Sent to the paradigm-shift (heavy) model whenever PE fires (Appendix F). The representative_solutions field is filled with the highest-scoring elite from each k-means cluster of the occupied archive cells. # Algorithmic Paradigm Shift Challenge ## Problem {problem_description} ## Function Si...
-
[16]
**Identify current paradigms**: What algorithmic strategies do the existing solutions use? (e.g., greedy, graph-based, dynamic programming, heuristic search, brute-force with pruning, etc.)
-
[17]
**Find the gap**: What paradigms are NOT represented in the current solutions?
-
[18]
**Design a novel approach**: Synthesize a solution using a completely different conceptual framework and data structure strategy than those found in the examples ### Instructions:
-
[19]
Study the function signature carefully - match it EXACTLY
-
[20]
Actively avoid the core logic, heuristics, and search patterns used in the existing solutions
-
[21]
No explanations before or after
Design a solution using a COMPLETELY DIFFERENT strategy ### Critical Requirements: - Your function signature MUST match exactly: ‘{function_signature}‘ - Use only standard Python libraries (numpy, collections, itertools, math, heapq, functools, etc.) and torch if needed - The code must be syntactically valid and complete - Include ALL necessary imports at...
-
[22]
Keeping the core algorithmic approach intact
-
[23]
Making targeted modifications to: - Constants and thresholds - Secondary heuristics - Edge case handling - Implementation details The variant should explore nearby regions of the solution space while preserving the novel approach. ## Output Output ONLY the complete Python code in a ‘‘‘python block. E.6 Prompt-optimization mutation (single-prompt artifact)...
-
[24]
Cluster occupied cells.Run k-means in descriptor space over the behavior vectors of the currently occupied centroids, withk=n_clusters(default 3)
-
[25]
The result is a small set of mutually-distant, individually-strong solutions
Select representatives.From each cluster, take the highest-scoring elite. The result is a small set of mutually-distant, individually-strong solutions
-
[26]
Paradigm-shift call.Build the paradigm-shift prompt (Section E.4) with the represen- tatives as context. Route to the paradigm-shift model (default: Gemini Flash 3) with max_tokens=4096,timeout=300s, at the configuredpe.temperature
-
[27]
Insert into the archive if it dominates its target cell
Evaluate paradigm.Score the resulting candidate against the full evaluator. Insert into the archive if it dominates its target cell. 5.Variant burst.Generaten variants (default 3) variants of the accepted paradigm shift using the variant-generation prompt (Section E.5), routed to the smaller mutation model. Each variant is independently evaluated and inse...
-
[28]
These logs are what the figures in Figure 5 are derived from
Logging.Record paradigm_generated, paradigm_accepted, variants_generated, variants_accepted, and total_cost for the trigger event. These logs are what the figures in Figure 5 are derived from. The trigger interval is the only PE knob that varies across our experiments: the per-benchmark and ablation runs override interval between 5 and 18 depending on bud...
-
[29]
-> tuple[torch.Tensor, torch.Tensor, torch.Tensor]: 10’’’ 11Paradigm: Spectral-Inspired Balanced Partitioning (SIBP). 12 20 13Instead of greedy allocation or simple interleaving, this approach treats the 14load balancing problem as a ’Bin Packing with Variable Item Sizes’ combined 15with a ’Static Circular Buffer’ layout. 16
-
[30]
Approximation: We use a Logarithmic Binning strategy to allocate expert counts, 18representing a shift from linear proportionality to entropy-minimizing distribution
-
[31]
Placement: We utilize a ’Circular Zig-Zag’ mapping to assign experts to physical 20slots, ensuring that the highest-load experts are geographically distributed 21using a relative-prime offset and localized mirroring. 22’’’ 23num_layers, num_logical_experts = weight.shape 24device = weight.device 25 26# 1. Expert Count Determination: Entropy-based Logarith...
-
[32]
Initial Greedy Packing using a Pressure-Aware First-Fit
-
[33]
Simulated Annealing / Local Search to refine the bottleneck (max pressure). 22""" 23 24def calculate_kvpr(gpu_models): 25if not gpu_models: 26return 0.0 27total_weight = sum(m.req_rate / m.slo for m in gpu_models) 28used_mem = sum(m.model_size for m in gpu_models) 29remaining_mem = GPU_MEM_SIZE - used_mem 30# Respect hard constraint; return inf if exceede...
-
[34]
-> pd.DataFrame: 18""" 19Optimized Column and Row Reordering for Maximum Prefix Hit Rate. 20 21Strategy:
-
[35]
Apply column merging with robust error handling
-
[36]
Use a hybrid column ordering approach: 24- For small column sets (<= col_stop), use brute-force with early pruning. 25- For larger sets, use greedy selection based on compression-like utility (sum of squares of frequencies)
-
[37]
Row reordering via sequential stable frequency ranking (high-frequency values grouped together)
-
[38]
Leverage vectorized operations and sampling to ensure runtime < 10s
-
[39]
Avoid common pitfalls: nested multiprocessing, apply(), missing columns, and row truncation. 29 30Key improvements over v1/v2: 31- Avoids ‘df.apply(lambda)‘ entirely; uses vectorized string operations. 32- Prevents daemonic process errors by using ThreadPoolExecutor instead of ProcessPoolExecutor. 33- Handles edge cases: empty DataFrame, missing columns, ...
-
[40]
deadline-aware restart-overhead cautious
-> float: 171""" 172Vectorized prefix hit rate calculation using string concatenation. 173Avoids loops and apply; uses pandas vectorized operations. 174 175Args: 176col_order: List of column names in order 177sample_str: DataFrame of string values (already converted) 178 179Returns: 180Average prefix hit rate (fraction of rows where current row starts wit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.