Recognition: no theorem link
Evaluating Tool Cloning in Agentic-AI Ecosystems
Pith reviewed 2026-05-12 01:57 UTC · model grok-4.3
The pith
Tool cloning creates widespread hidden duplication across public agent-tool repositories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The study performs the first large-scale audit of tool repositories in agentic AI ecosystems by computing pairwise lexical and fuzzy-structural similarity across all MCP-to-MCP, Skills-to-Skills, and cross-ecosystem pairs. High-similarity regions appear consistently, and manual verification of sampled pairs shows that 60 percent of high-Jaccard candidates and 85 percent of high-ssdeep candidates in the MCP ecosystem are true clones. These results demonstrate that cloning is a pervasive source of duplication that overstates ecosystem diversity and contaminates benchmark construction.
What carries the argument
A repository-level auditing pipeline that computes complementary lexical similarity and fuzzy-structural similarity metrics on all repository pairs, then calibrates true cloning rates through manual verification of 100 sampled pairs per ecosystem in each similarity bucket.
If this is right
- Raw tool counts in marketplaces substantially overstate actual diversity.
- Benchmark splits risk including near-duplicate tools, biasing generalization measurements.
- Vulnerable code from source repositories can propagate widely through clones.
- Provenance tracking, attribution, and intellectual-property questions become harder to resolve.
- Datasets and benchmarks must incorporate repository provenance and similarity checks to remain valid.
Where Pith is reading between the lines
- Agent platforms could add automated deduplication steps before listing new tools.
- Security audits might focus first on frequently cloned repositories to catch widespread issues.
- Benchmark creators could adopt similarity-aware train-test splits as standard practice.
Load-bearing premise
That lexical and fuzzy-structural similarity scores, after calibration on manually reviewed samples, reliably separate true cloning from independent but coincidentally similar code.
What would settle it
A full manual audit of every high-similarity pair that finds most of them are independently written implementations rather than clones.
Figures

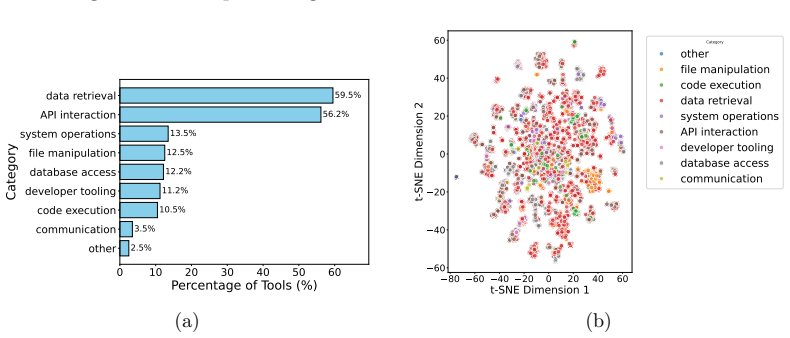


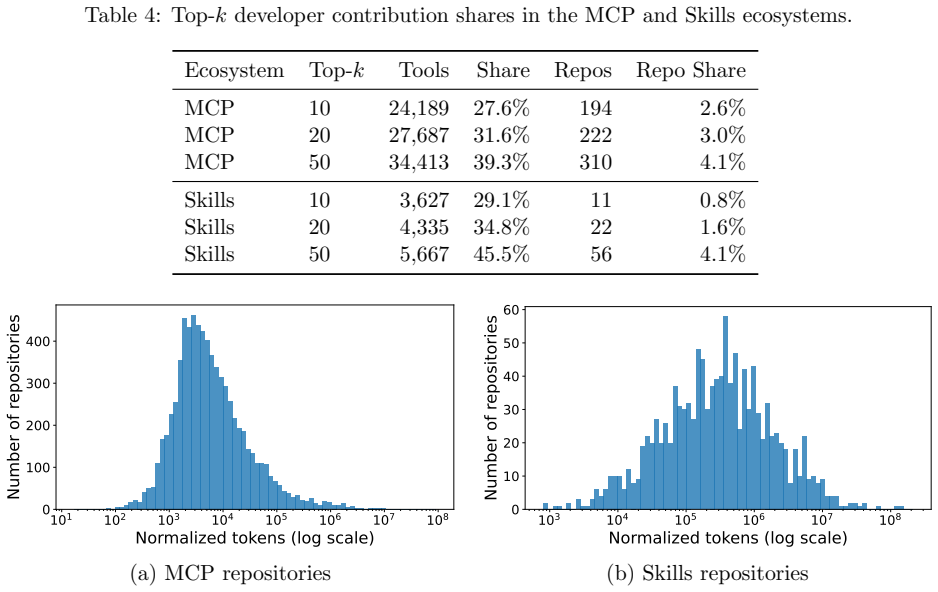





read the original abstract
Agent tools are becoming a core interface through which LLM agents access external data, services, and execution environments. As these tools are distributed through public marketplaces, raw tool counts may substantially overstate ecosystem diversity if many repositories are cloned, lightly modified, or derived from shared templates. Such hidden duplication can contaminate benchmark splits, propagate vulnerable implementations, bias measurements of tool-use generalization, and raise provenance, attribution, and intellectual-property concerns. We present, to our knowledge, the first large-scale measurement study of tool cloning in agentic AI ecosystems. We curate a unified dataset from multiple public platforms, covering 7,508 Model Context Protocol (MCP) repositories with 87,564 extracted tools and 1,353 Skills repositories with 12,447 tools, for a total of 8,861 repositories and 100,011 tool entries. To measure implementation-level duplication, we build a repository-level auditing pipeline using complementary lexical and fuzzy-structural similarity metrics, and compute pairwise similarity across MCP-to-MCP, Skills-to-Skills, and MCP-to-Skills repository pairs. We further manually verify 100 sampled pairs per MCP and Skills ecosystem across similarity-score buckets to calibrate how often high similarity reflects true code cloning. Our analysis shows that cloning is not an isolated artifact: high-similarity regions appear across comparison settings, and 60\% of high-Jaccard candidates and 85\% of high-ssdeep candidates in the MCP ecosystem are manually verified as clones. These results indicate that tool cloning is a pervasive and severe source of hidden duplication in agent-tool ecosystems. They further suggest that agent-tool datasets and benchmarks should account for repository provenance and implementation similarity when measuring tool diversity or constructing evaluation splits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first large-scale empirical study of tool cloning in agentic AI ecosystems. It curates a dataset of 7,508 MCP repositories (87,564 tools) and 1,353 Skills repositories (12,447 tools), applies Jaccard and ssdeep similarity metrics to all pairwise repository comparisons, and manually verifies 100 sampled pairs per ecosystem across similarity-score buckets. The analysis finds high similarity regions and verifies 60% of high-Jaccard and 85% of high-ssdeep MCP candidates as clones, concluding that tool cloning is pervasive and recommending that benchmarks account for repository provenance and implementation similarity.
Significance. If the manual verification reliably distinguishes cloning from coincidental similarity, this study would be significant for the field by quantifying hidden duplication in tool ecosystems at scale. The dataset size (over 100k tools) and complementary lexical/fuzzy metrics provide a solid foundation for the measurement. The findings could influence how tool diversity is measured and how evaluation splits are constructed in agent benchmarks, addressing issues like contamination and bias. The purely empirical approach with no fitted parameters or circular derivations is a strength.
major comments (1)
- [Manual verification procedure (Results section)] The pervasiveness claim (60% of high-Jaccard and 85% of high-ssdeep candidates verified as clones) depends on manual verification of only 100 pairs per ecosystem. With ~28M possible MCP repository pairs, this sample size is too small to reliably calibrate false-positive rates in the high-similarity tail. The manuscript provides no details on sampling stratification across score buckets, inter-rater agreement, or explicit decision criteria for classifying pairs as clones versus coincidental similarity (e.g., shared boilerplate or common libraries). This under-calibration directly undermines the reliability of interpreting high similarity scores as evidence of pervasive cloning.
minor comments (1)
- [Abstract and §4 (Methodology)] The abstract states verification occurs 'across similarity-score buckets' but the main text should explicitly define the bucket boundaries, the total number of high-similarity candidates, and the precise sampling method to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the single major comment below regarding the manual verification procedure, providing clarification on our approach while agreeing to enhance the manuscript with additional methodological details.
read point-by-point responses
-
Referee: The pervasiveness claim (60% of high-Jaccard and 85% of high-ssdeep candidates verified as clones) depends on manual verification of only 100 pairs per ecosystem. With ~28M possible MCP repository pairs, this sample size is too small to reliably calibrate false-positive rates in the high-similarity tail. The manuscript provides no details on sampling stratification across score buckets, inter-rater agreement, or explicit decision criteria for classifying pairs as clones versus coincidental similarity (e.g., shared boilerplate or common libraries). This under-calibration directly undermines the reliability of interpreting high similarity scores as evidence of pervasive cloning.
Authors: We appreciate the referee's emphasis on methodological transparency for the manual verification. Our sampling of 100 pairs per ecosystem was stratified across similarity-score buckets to concentrate on the high-similarity tail, where the distinction between cloning and coincidental similarity is most critical for our pervasiveness conclusions. This targeted calibration is appropriate for interpreting the metrics in the regions of interest, rather than requiring exhaustive sampling from the full ~28 million pairs. However, we agree that the manuscript would benefit from greater detail on the exact bucket-wise sampling proportions, the explicit decision criteria (including how boilerplate, shared libraries, and common dependencies were handled), and any inter-rater agreement measures. In the revised manuscript, we will expand the relevant sections to include a full description of the verification protocol, the classification rubric, and clarification on the verification process. These additions will strengthen the presentation without changing the reported verification rates or core findings. revision: yes
Circularity Check
No significant circularity in empirical measurement study
full rationale
The paper conducts a purely empirical measurement study: it curates a dataset of repositories and tools, applies lexical and fuzzy similarity metrics to compute pairwise scores, and manually verifies a sample of high-similarity pairs. No derivations, equations, fitted parameters presented as predictions, or self-referential steps exist that would reduce the central claims about cloning prevalence to inputs by construction. The findings rest directly on the collected data and verification process, with no load-bearing self-citations or ansatzes that create circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High lexical and fuzzy-structural similarity between repositories indicates code cloning rather than independent development
Reference graph
Works this paper leans on
-
[1]
Clone detection using abstract syntax trees , author=. Proceedings. International Conference on Software Maintenance , year=
-
[2]
Queen’s School of computing TR , year=
A survey on software clone detection research , author=. Queen’s School of computing TR , year=
-
[3]
Science of computer programming , year=
Comparison and evaluation of code clone detection techniques and tools: A qualitative approach , author=. Science of computer programming , year=
- [4]
-
[5]
IEEE Transactions on software engineering , year=
Comparison and evaluation of clone detection tools , author=. IEEE Transactions on software engineering , year=
-
[6]
2009 IEEE 31st International Conference on Software Engineering , pages=
Do code clones matter? , author=. 2009 IEEE 31st International Conference on Software Engineering , pages=. 2009 , organization=
work page 2009
- [7]
-
[8]
The distribution of the flora in the alpine zone. 1 , author=. New phytologist , volume=. 1912 , publisher=
work page 1912
-
[9]
Digital investigation , volume=
Identifying almost identical files using context triggered piecewise hashing , author=. Digital investigation , volume=. 2006 , publisher=
work page 2006
- [10]
-
[11]
Finding near-duplicate web pages: a large-scale evaluation of algorithms , author=. Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
- [12]
-
[13]
Empirical Software Engineering , volume=
Empirical study of android repackaged applications , author=. Empirical Software Engineering , volume=. 2019 , publisher=
work page 2019
-
[14]
The 2014 ACM international conference on Measurement and modeling of computer systems , pages=
A measurement study of google play , author=. The 2014 ACM international conference on Measurement and modeling of computer systems , pages=
work page 2014
-
[15]
arXiv preprint arXiv:2009.08366 , year=
Graphcodebert: Pre-training code representations with data flow , author=. arXiv preprint arXiv:2009.08366 , year=
-
[16]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Codebert: A pre-trained model for programming and natural languages , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
work page 2020
-
[17]
Introducing the Model Context Protocol , author =. 2024 , howpublished =
work page 2024
-
[18]
Equipping Agents for the Real World with Agent Skills , author =. 2025 , howpublished =
work page 2025
-
[20]
The twelfth international conference on learning representations , year=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. The twelfth international conference on learning representations , year=
-
[21]
International Conference on Learning Representations (ICLR) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[25]
2012 IEEE symposium on security and privacy , pages=
Dissecting android malware: Characterization and evolution , author=. 2012 IEEE symposium on security and privacy , pages=. 2012 , organization=
work page 2012
-
[26]
Llama 4: Open Foundation Models for Multimodal and Efficient AI , author =. 2025 , howpublished =
work page 2025
-
[27]
Advances in Neural Information Processing Systems , year=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , year=
-
[28]
The Twelfth International Conference on Learning Representations , year=
AgentBench: Evaluating LLMs as Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
The twelfth international conference on learning representations , year=
Swe-bench: Can language models resolve real-world github issues? , author=. The twelfth international conference on learning representations , year=
-
[30]
Advances in Neural Information Processing Systems , year=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , year=
-
[31]
IEEE transactions on software engineering , year=
CCFinder: A multilinguistic token-based code clone detection system for large scale source code , author=. IEEE transactions on software engineering , year=
-
[32]
29th International Conference on Software Engineering (ICSE'07) , year=
Deckard: Scalable and accurate tree-based detection of code clones , author=. 29th International Conference on Software Engineering (ICSE'07) , year=
-
[33]
Proceedings of the 38th international conference on software engineering , year=
Sourcerercc: Scaling code clone detection to big-code , author=. Proceedings of the 38th international conference on software engineering , year=
-
[34]
IEEE Transactions on software Engineering , year=
CP-Miner: Finding copy-paste and related bugs in large-scale software code , author=. IEEE Transactions on software Engineering , year=
-
[35]
Proceedings of the second ACM conference on Data and Application Security and Privacy , year=
Detecting repackaged smartphone applications in third-party android marketplaces , author=. Proceedings of the second ACM conference on Data and Application Security and Privacy , year=
-
[36]
European Symposium on Research in Computer Security , year=
Attack of the clones: Detecting cloned applications on android markets , author=. European Symposium on Research in Computer Security , year=
-
[37]
European Symposium on Research in Computer Security , year=
Andarwin: Scalable detection of semantically similar android applications , author=. European Symposium on Research in Computer Security , year=
-
[38]
MCP.so , year = 2025, howpublished =
work page 2025
-
[39]
MCPServers.org , year = 2025, howpublished =
work page 2025
-
[40]
MCP Market , title =
-
[41]
Introducing the model context protocol
Anthropic . Introducing the model context protocol. https://www.anthropic.com/news/model-context-protocol, 2024
work page 2024
-
[42]
Equipping agents for the real world with agent skills
Anthropic . Equipping agents for the real world with agent skills. https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills, 2025
work page 2025
-
[43]
Clone detection using abstract syntax trees
Ira D Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant'Anna, and Lorraine Bier. Clone detection using abstract syntax trees. In Proceedings. International Conference on Software Maintenance, 1998
work page 1998
-
[44]
Comparison and evaluation of clone detection tools
Stefan Bellon, Rainer Koschke, Giulio Antoniol, Jens Krinke, and Ettore Merlo. Comparison and evaluation of clone detection tools. IEEE Transactions on software engineering, 2007
work page 2007
-
[45]
Attack of the clones: Detecting cloned applications on android markets
Jonathan Crussell, Clint Gibler, and Hao Chen. Attack of the clones: Detecting cloned applications on android markets. In European Symposium on Research in Computer Security, 2012
work page 2012
-
[46]
Andarwin: Scalable detection of semantically similar android applications
Jonathan Crussell, Clint Gibler, and Hao Chen. Andarwin: Scalable detection of semantically similar android applications. In European Symposium on Research in Computer Security, 2013
work page 2013
-
[47]
Deckard: Scalable and accurate tree-based detection of code clones
Lingxiao Jiang, Ghassan Misherghi, Zhendong Su, and Stephane Glondu. Deckard: Scalable and accurate tree-based detection of code clones. In 29th International Conference on Software Engineering (ICSE'07), 2007
work page 2007
-
[48]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The twelfth international conference on learning representations, 2023
work page 2023
-
[49]
Elmar Juergens, Florian Deissenboeck, Benjamin Hummel, and Stefan Wagner. Do code clones matter? In 2009 IEEE 31st International Conference on Software Engineering, pages 485--495. IEEE, 2009
work page 2009
-
[50]
Ccfinder: A multilinguistic token-based code clone detection system for large scale source code
Toshihiro Kamiya, Shinji Kusumoto, and Katsuro Inoue. Ccfinder: A multilinguistic token-based code clone detection system for large scale source code. IEEE transactions on software engineering, 2002
work page 2002
-
[51]
Identifying almost identical files using context triggered piecewise hashing
Jesse Kornblum. Identifying almost identical files using context triggered piecewise hashing. Digital investigation, 3: 0 91--97, 2006
work page 2006
-
[52]
Survey of research on software clones
Rainer Koschke. Survey of research on software clones. 2007
work page 2007
-
[53]
Cp-miner: Finding copy-paste and related bugs in large-scale software code
Zhenmin Li, Shan Lu, Suvda Myagmar, and Yuanyuan Zhou. Cp-miner: Finding copy-paste and related bugs in large-scale software code. IEEE Transactions on software Engineering, 2006
work page 2006
-
[54]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
- [55]
-
[56]
Llama 4: Open foundation models for multimodal and efficient ai
Meta AI . Llama 4: Open foundation models for multimodal and efficient ai. https://ai.meta.com/llama/, 2025. Accessed: 2026-05-06
work page 2025
-
[57]
Gorilla: Large language model connected with massive apis
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[58]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. In The twelfth international conference on learning representations, 2023
work page 2023
-
[59]
Comparison and evaluation of code clone detection techniques and tools: A qualitative approach
Chanchal K Roy, James R Cordy, and Rainer Koschke. Comparison and evaluation of code clone detection techniques and tools: A qualitative approach. Science of computer programming, 2009
work page 2009
-
[60]
A survey on software clone detection research
Chanchal Kumar Roy and James R Cordy. A survey on software clone detection research. Queen’s School of computing TR, 2007
work page 2007
-
[61]
Sourcerercc: Scaling code clone detection to big-code
Hitesh Sajnani, Vaibhav Saini, Jeffrey Svajlenko, Chanchal K Roy, and Cristina V Lopes. Sourcerercc: Scaling code clone detection to big-code. In Proceedings of the 38th international conference on software engineering, 2016
work page 2016
-
[62]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36: 0 68539--68551, 2023
work page 2023
-
[63]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36: 0 38154--38180, 2023
work page 2023
-
[64]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36: 0 8634--8652, 2023
work page 2023
- [65]
-
[66]
arXiv preprint arXiv:2306.05301 , year =
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301, 2023
- [67]
-
[68]
MCP.so. Mcp.so. https://mcp.so/, 2025
work page 2025
-
[69]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[70]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[71]
Detecting repackaged smartphone applications in third-party android marketplaces
Wu Zhou, Yajin Zhou, Xuxian Jiang, and Peng Ning. Detecting repackaged smartphone applications in third-party android marketplaces. In Proceedings of the second ACM conference on Data and Application Security and Privacy, 2012
work page 2012
-
[72]
Dissecting android malware: Characterization and evolution
Yajin Zhou and Xuxian Jiang. Dissecting android malware: Characterization and evolution. In 2012 IEEE symposium on security and privacy, pages 95--109. IEEE, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.