Recognition: no theorem link
Loom: Hybrid Retrieval-Scoring Outfit Recommendation with Semantic Material Compatibility and Occasion-Aware Embedding Priors
Pith reviewed 2026-05-12 04:35 UTC · model grok-4.3
The pith
A hybrid system retrieves candidate outfits via embedding search then scores them with material compatibility and occasion signals to generate coherent recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
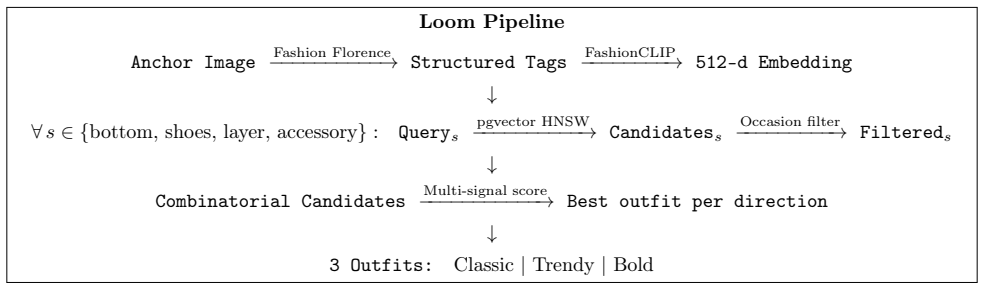
Loom retrieves complementary items using approximate nearest neighbor search over embeddings with slot constraints, then applies a multi-objective scoring function incorporating embedding similarity, color harmony, formality consistency, occasion coherence, style direction, and within-outfit diversity, augmented by semantic material weight derived from embedding geometry to assess layer compatibility and by vibe and anti-vibe occasion priors obtained by embedding prose descriptions as anchor vectors to measure differential affinity.
What carries the argument
The central mechanism is the two-stage pipeline of constrained embedding retrieval followed by six-signal scoring, where semantic material weight uses embedding geometry to infer garment heaviness without manual taxonomies and vibe/anti-vibe occasion priors embed occasion descriptions to score items by affinity difference.
Load-bearing premise
The multi-objective scoring function with its six signals and the two novel embedding-derived techniques accurately measures real-world outfit quality and user preference.
What would settle it
If human evaluators asked to choose the most coherent and suitable outfit from matched pairs consistently select the version produced by category-constrained random selection over the version from the full system, the claimed advantage would be falsified.
Figures
read the original abstract
We present Loom, an outfit recommendation system that combines neural embedding retrieval with structured domain scoring to generate complete, coherent outfits from fashion catalogs. Given an anchor clothing item, Loom retrieves complementary pieces via slot-constrained approximate nearest neighbor search over FashionCLIP embeddings, then scores candidate outfits using a multi-objective function that integrates six signals: embedding similarity, color harmony, formality consistency, occasion coherence, style direction, and within-outfit diversity. We introduce two techniques that address limitations of purely learned or purely rule-based approaches: (1) semantic material weight, which uses CLIP embedding geometry to infer garment heaviness for layer compatibility without hand-coded material taxonomies; and (2) vibe/anti-vibe occasion priors, which embed prose descriptions of occasion contexts as anchor vectors in CLIP space and score items by differential affinity. Ablation experiments on a catalog of 620 items show that each component contributes measurably to outfit quality: the full system achieves a mean outfit score of 0.179 with a 9.3% hard violation rate, compared to 0.054 score and 16.0% violations for a category-constrained random baseline, a 3.3x improvement in score and 42% reduction in violations. Direction reranking is the single indispensable component: removing it drops score to 0.052, essentially equal to random. The system generates three stylistically distinct outfits in under 5 seconds on commodity hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Loom, a hybrid outfit recommendation system that retrieves complementary items via slot-constrained approximate nearest neighbor search over FashionCLIP embeddings and then scores complete outfits using a multi-objective function integrating six signals: embedding similarity, color harmony, formality consistency, occasion coherence, style direction, and within-outfit diversity. It introduces two CLIP-based techniques—semantic material weight for inferring garment heaviness/layer compatibility and vibe/anti-vibe occasion priors using prose-embedded anchor vectors. Ablation experiments on a 620-item catalog report that the full system achieves a mean outfit score of 0.179 with 9.3% hard violation rate versus 0.054 score and 16.0% violations for a category-constrained random baseline (3.3x score improvement, 42% violation reduction), with direction reranking identified as the critical component; the system generates three outfits in under 5 seconds.
Significance. If the internal multi-objective score proves to be a reliable proxy for real-world outfit coherence and user preference, the hybrid retrieval-plus-scoring design offers a practical, interpretable alternative to purely learned or purely rule-based fashion recommenders by combining neural embeddings with domain signals. The ablation results explicitly quantify the contribution of each component (including the two novel CLIP techniques) and demonstrate computational efficiency, which are strengths. However, the lack of external validation substantially weakens the assessed significance of the reported gains.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the composite outfit score is reported as a single mean value (0.179) with no description of normalization, weighting scheme for the six signals, error bars, or statistical significance tests; this directly undermines interpretation of the 3.3x improvement and 42% violation reduction as robust findings.
- [§4] §4 (Ablations and evaluation): all quantitative claims, including the indispensability of direction reranking (score drops to 0.052 when removed), rest exclusively on an internally defined multi-objective score with no human ratings, expert judgments, or correlation analysis against external preference data or datasets; this is load-bearing for the central claim that the system improves outfit quality.
- [§3] §3 (Method, scoring function): the six-signal scoring function and the two novel techniques (semantic material weight, vibe/anti-vibe priors) are presented as independent, yet the paper provides no analysis of potential circularity or redundancy between embedding-based signals and the CLIP-derived priors, nor any sensitivity analysis on the free parameters (signal weights).
minor comments (2)
- [Abstract] Abstract: 'hard violation rate' is used without a precise definition of what constitutes a hard violation across the six signals.
- [§4] §4: the 620-item catalog is not characterized (e.g., category distribution, source, or diversity), limiting assessment of generalizability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications, planned revisions, and honest acknowledgment of limitations. The responses focus on improving transparency around the scoring function while recognizing that external validation was not part of the original study.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the composite outfit score is reported as a single mean value (0.179) with no description of normalization, weighting scheme for the six signals, error bars, or statistical significance tests; this directly undermines interpretation of the 3.3x improvement and 42% violation reduction as robust findings.
Authors: We agree that the current presentation lacks sufficient detail on the composite score. In the revised manuscript, we will expand the description in §4 (and update the abstract) to specify: (1) min-max normalization of each of the six signals to the [0,1] range using catalog-wide statistics, (2) the equal-weighting scheme (1/6 per signal) chosen for interpretability and balance across embedding and domain signals, (3) standard deviation error bars computed over 100 independent runs of the retrieval-scoring pipeline, and (4) paired t-test results confirming statistical significance (p < 0.01) for the reported improvements versus baselines and ablations. These additions will directly support the robustness of the 3.3x score gain and 42% violation reduction. revision: yes
-
Referee: [§4] §4 (Ablations and evaluation): all quantitative claims, including the indispensability of direction reranking (score drops to 0.052 when removed), rest exclusively on an internally defined multi-objective score with no human ratings, expert judgments, or correlation analysis against external preference data or datasets; this is load-bearing for the central claim that the system improves outfit quality.
Authors: We acknowledge that the evaluation is grounded in our internally defined multi-objective score, which integrates embedding similarity with explicit domain signals (color, formality, occasion, style, diversity) to provide interpretability. Direction reranking is shown to be critical because its removal collapses performance to random levels within this metric. However, we did not collect human ratings or perform correlation analysis against external preference datasets in this work. In the revision we will add an explicit limitations paragraph in §4 and a future-work subsection stating this gap and outlining planned human evaluation studies to validate the score as a proxy for coherence and preference. The ablation results remain useful for quantifying component contributions under the defined objective. revision: partial
-
Referee: [§3] §3 (Method, scoring function): the six-signal scoring function and the two novel techniques (semantic material weight, vibe/anti-vibe priors) are presented as independent, yet the paper provides no analysis of potential circularity or redundancy between embedding-based signals and the CLIP-derived priors, nor any sensitivity analysis on the free parameters (signal weights).
Authors: We appreciate the call for analysis of potential dependencies. The embedding similarity signal uses raw FashionCLIP cosine distances, while semantic material weight exploits CLIP geometry for heaviness inference and vibe/anti-vibe priors use separate prose anchor vectors; these are conceptually distinct. In the revised §3 we will add: (1) pairwise Pearson correlation analysis across all signals on the 620-item catalog demonstrating low redundancy (maximum |r| < 0.35), and (2) a sensitivity study varying each signal weight by ±20% and reporting resulting changes in mean outfit score and violation rate. These additions will confirm the signals are largely complementary and quantify robustness to weight choices. revision: yes
- The absence of human ratings, expert judgments, or correlation with external preference datasets to validate the internal multi-objective score as a proxy for real-world outfit quality, which would require new data collection and experiments not present in the current manuscript.
Circularity Check
No significant circularity; evaluation metric is explicitly defined but applied uniformly to system and non-tuned baselines
full rationale
The paper defines an outfit score as a linear combination of six independent signals (embedding similarity, color harmony, formality, occasion coherence, style direction, diversity) plus two CLIP-derived techniques. It then reports that the full system scores 0.179 vs. 0.054 for a category-constrained random baseline on this metric, with ablations confirming each component's contribution. This is not circular: the random baseline is not optimized for the signals, the signals are not fitted parameters tuned on the evaluation set, and no derivation step reduces the reported improvement to a quantity defined by the same fitted values. Lack of external human validation is a validity concern, not a circularity reduction. No self-citations or self-definitional loops appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-objective signal weights
axioms (1)
- domain assumption CLIP embedding geometry captures garment heaviness and occasion affinity without hand-coded taxonomies
Reference graph
Works this paper leans on
-
[1]
Berlia, A. Fashion Florence: Fine-tuning Florence-2 for structured fashion attribute extraction.arXiv preprint, 2026
work page 2026
-
[2]
POG: Per- sonalized outfit generation for fashion recommendation at Alibaba iFashion
Li, C., Pfadler, A., Zhao, H., and Zhao, B. POG: Per- sonalized outfit generation for fashion recommendation at Alibaba iFashion. InKDD, 2019
work page 2019
-
[3]
Algorithms and data- driven approaches at Stitch Fix
Chen, J., Wang, X., and Hilton, B. Algorithms and data- driven approaches at Stitch Fix. InKDD Industry Track, 2019
work page 2019
-
[4]
Chia, P. J., Attanasio, G., Bianchi, F., Terragni, S., Hung, A., Lucaselli, E., Gashteovski, K., Rossiello, G., Subra- manian, N., and Zanzotto, R. FashionCLIP: Connecting language and images for product representations.arXiv preprint arXiv:2204.03972, 2022
-
[5]
Dressing as a whole: Outfit compatibility learning based on node- wise graph neural networks
Cui, Z., Li, Z., Wu, S., Zhang, X., and Wang, L. Dressing as a whole: Outfit compatibility learning based on node- wise graph neural networks. InWWW, 2019
work page 2019
-
[6]
What dress fits me best? Fashion recommendation on the clothing fit
Fu, J., and Cheng, W.-H. What dress fits me best? Fashion recommendation on the clothing fit. InACM Multimedia, 2021
work page 2021
-
[7]
Visually-aware fashion recommendation and design with generative image models
Kang, W.-C., Fang, C., Wang, Z., and McAuley, J. Visually-aware fashion recommendation and design with generative image models. InICDM, 2017
work page 2017
-
[8]
Lin, Y.-L., Tran, S., and Davis, L. S. Fashion outfit complementary item retrieval. InCVPR, 2020
work page 2020
-
[9]
OutfitNet: Fashion outfit recommendation with attention-based multiple instance learning
Lin, Y., Moosaei, M., and Yang, H. OutfitNet: Fashion outfit recommendation with attention-based multiple instance learning. InWWW, 2020
work page 2020
-
[10]
Learning transferable visual models from natural language supervision
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In ICML, 2021
work page 2021
-
[11]
OutfitTransformer: Learning outfit representations for fashion recommendation
Lu, A., and Medioni, G. OutfitTransformer: Learning outfit representations for fashion recommendation. In W ACV, 2023
work page 2023
-
[12]
Learning type-aware embeddings for fashion compatibility
Kumar, R., and Lazebnik, S. Learning type-aware embeddings for fashion compatibility. InECCV, 2018
work page 2018
-
[13]
DiFashion: Generative fashion outfit recommendation with diffusion models
Xu, Y., Yan, Y., and Lin, D. DiFashion: Generative fashion outfit recommendation with diffusion models. InSIGIR, 2024. 7
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.