Recognition: 1 theorem link
· Lean TheoremProbing Routing-Conditional Calibration in Attention-Residual Transformers
Pith reviewed 2026-05-12 05:01 UTC · model grok-4.3
The pith
Scalar routing summaries in Attention-Residual transformers do not yield stable evidence of conditional miscalibration after proper controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In completed runs of Attention-Residual transformers, scalar routing summaries produce weighted calibration gaps that remain small or sensitive to random seed, with only one of thirty within-bin permutation tests rejecting the null of no routing-conditional miscalibration at the 0.05 level and that rejection not repeating across seeds. A minimal two-dimensional Nadaraya-Watson estimator using confidence and routing-depth variance performs no better than confidence-only baselines on worst-routing-tertile expected calibration error. Even a full-vector multilayer perceptron over the entire routing profile appears superior to a linear confidence baseline, yet this advantage vanishes when a same-
What carries the argument
Matched-confidence stratification combined with within-bin routing-permutation nulls and capacity-matched control probes. These tools isolate any routing-specific contribution to calibration by holding confidence fixed and testing against randomized or capacity-equivalent alternatives.
If this is right
- Calibration gaps tied to routing summaries stay small or fluctuate with the choice of random seed.
- Within-bin permutation tests rarely reject the no-difference null, and rejections are not reproducible across seeds.
- Probes that incorporate routing information achieve no reliable improvement in worst-tertile ECE once bandwidth and capacity are accounted for.
- Apparent gains from vector-valued routing features disappear under capacity-matched confidence-only models and under shuffling of the routing profiles.
Where Pith is reading between the lines
- The same control framework could be used to test whether other internal states such as attention patterns carry hidden calibration information.
- If routing does not improve calibration, then uncertainty estimates in these architectures may need to rely on external methods like temperature scaling or ensembles rather than internal traces.
- Apparent benefits from auxiliary features in calibration models often trace to increased expressive capacity rather than the semantic content of the feature.
- This diagnostic approach highlights the need for permutation and capacity controls in any study claiming that model internals improve uncertainty quantification.
Load-bearing premise
The matched-confidence stratification, within-bin permutation nulls, and capacity-matched MLP controls are sufficient to detect a genuine routing-conditional calibration signal if one is present in the architecture.
What would settle it
Consistent rejection of the conditional null hypothesis across multiple independent seeds in the within-bin permutation tests, or demonstration that a routing-aware probe reliably outperforms capacity-matched confidence-only models on held-out worst-routing-tertile expected calibration error.
Figures


















read the original abstract
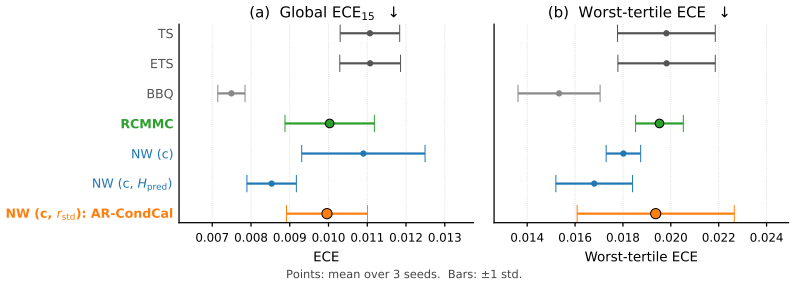
Post-hoc calibration is usually evaluated as a function of logits or softmax confidence alone, even as routing-augmented architectures increasingly accompany predictions with sample-specific internal routing traces and pair them with claims of calibration-relevant uncertainty. We ask a basic question: do these traces provide stable routing-specific evidence for post-hoc calibration beyond confidence? We study this in Attention-Residual transformers (Kimi Team, 2026) through a matched-confidence diagnostic suite that stratifies examples by routing-derived state, compares subgroup gaps against within-bin routing-permutation nulls, and evaluates matched post-hoc probes differing only in their auxiliary feature. Across our completed AR runs, scalar routing summaries do not provide stable evidence of routing-conditional miscalibration: weighted gaps remain small or seed-sensitive, and only $1$ of $30$ within-bin permutation tests rejects the conditional-null at $\alpha=0.05$ (only on one seed; not stable across seeds in that cell). AR-CondCal, a minimal $2$-D Nadaraya--Watson probe on confidence and routing-depth variance, lies within the seed-variance band of matched confidence-only and predictive-entropy controls and does not reliably improve worst-routing-tertile ECE; bandwidth-sensitivity checks (Scott multiples, CV-NLL, global-ECE oracle) do not change this. A full-vector MLP over $(c, H_1, \ldots, H_L)$ can appear to improve over a linear confidence baseline, but the apparent gain disappears once a capacity-matched confidence-only MLP is included as a control, and shuffled routing profiles achieve comparable performance. Apparent routing-aware calibration gains in this AR setting should not be read as internal-state calibration until matched-confidence, bandwidth, capacity, and permutation controls rule out common confounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically probes whether scalar routing summaries (e.g., routing-depth variance) in Attention-Residual transformers supply stable evidence of routing-conditional miscalibration beyond softmax confidence. Using matched-confidence stratification, within-bin routing-permutation nulls, capacity-matched MLP baselines, and bandwidth-sensitivity checks on completed AR runs, it reports small or seed-sensitive weighted gaps, only 1/30 unstable rejections of the conditional null at α=0.05, and no reliable ECE improvement from a 2-D Nadaraya-Watson probe (AR-CondCal) or full-vector MLP once controls are applied; shuffled routing profiles perform comparably.
Significance. If the negative result holds, the work is significant for calibration research in routing-augmented architectures: it demonstrates that common confounds (confidence correlation, capacity, spurious signals) can produce apparent routing-aware gains and supplies a concrete diagnostic suite (permutation nulls + matched baselines) to rule them out. The explicit controls and seed-sensitivity reporting are strengths that increase the reliability of the conditional-null conclusion.
major comments (1)
- [Methods (permutation null construction)] The central claim rests on the within-bin permutation tests and the 1/30 rejection rate; the manuscript should specify in the methods how bins are constructed (e.g., quantiles of confidence) and whether permutations are performed independently per bin and per routing summary, as any dependence would affect the validity of the non-rejection conclusion.
minor comments (2)
- [Results] The bandwidth-sensitivity checks (Scott multiples, CV-NLL, global-ECE oracle) are mentioned only in the abstract; a short table or paragraph in the results section listing the exact bandwidth values tested and the resulting ECE changes would improve reproducibility.
- [Preliminaries] Notation for the routing summaries (H_1, …, H_L) and the AR-CondCal probe is introduced without an explicit equation; adding a short definition subsection would aid readers unfamiliar with the Kimi Team 2026 AR architecture.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the work's significance and for the careful methodological comment. We address the point below and will incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Methods (permutation null construction)] The central claim rests on the within-bin permutation tests and the 1/30 rejection rate; the manuscript should specify in the methods how bins are constructed (e.g., quantiles of confidence) and whether permutations are performed independently per bin and per routing summary, as any dependence would affect the validity of the non-rejection conclusion.
Authors: We agree that explicit specification of bin construction and the permutation procedure is required to substantiate the validity of the within-bin nulls and the reported 1/30 rejection rate. The original manuscript did not provide these details. In the revised Methods section we will add a precise description stating that examples are stratified into bins using quantiles of softmax confidence and that routing-summary permutations are generated independently within each bin and separately for each routing feature. This independent-per-bin construction was the procedure used in the experiments; the added text will include a brief justification that it preserves the marginal confidence distribution while testing for conditional routing effects. The revision will not alter any numerical results. revision: yes
Circularity Check
No circularity: empirical negative result with explicit controls
full rationale
The manuscript is an empirical study that applies matched-confidence stratification, within-bin permutation nulls, capacity-matched MLP controls, and bandwidth checks to test for routing-conditional calibration signals. All reported outcomes (small/seed-sensitive gaps, 1/30 unstable rejections, no reliable ECE improvement) are direct statistical observations from the runs rather than quantities derived from equations that reduce to the inputs by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the central claims; the controls are independent of the target result and falsify the alternative hypotheses on the observed data.
Axiom & Free-Parameter Ledger
free parameters (1)
- Nadaraya-Watson bandwidth
axioms (1)
- domain assumption Within-bin routing-permutation nulls correctly model the conditional independence of routing state and calibration error given confidence.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
scalar routing summaries do not provide stable evidence of routing-conditional miscalibration: weighted gaps remain small or seed-sensitive, and only 1 of 30 within-bin permutation tests rejects the conditional-null
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
ISSN 1532-4435. Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677,
work page internal anchor Pith review arXiv
-
[3]
Multicalibration: Calibration for the (computationally-identifiable) masses
Ursula Hébert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. Multicalibration: Calibration for the (computationally-identifiable) masses. InInternational Conference on Machine Learning, pages 1939–1948. PMLR,
work page 1939
-
[4]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.arXiv preprint arXiv:1903.12261,
work page internal anchor Pith review arXiv 1903
-
[5]
SGDR: Stochastic Gradient Descent with Warm Restarts
Yahui Liu, Enver Sangineto, Wei Bi, Nicu Sebe, Bruno Lepri, and Marco Nadai. Efficient training of visual transformers with small datasets.Advances in Neural Information Processing Systems, 34:23818–23830, 2021a. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer us...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training.arXiv preprint arXiv:1710.03740,
work page internal anchor Pith review arXiv
-
[7]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
URL https://arxiv.org/abs/1701.06538. Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al. Attention residuals.arXiv preprint arXiv:2603.15031,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Xin Wang, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E. Gonzalez. Skipnet: Learning dynamic routing in convolutional networks. InComputer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XIII, pages 420–436, Berlin, Heidelberg,
work page 2018
-
[9]
Springer-Verlag. ISBN 978-3-030-01260-1. doi: 10.1007/978-3-030-01261-8_25. URL https://doi.org/10.1007/978- 3-030-01261-8_25. Geoffrey S Watson. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, pages 359–372,
-
[10]
Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers
Bianca Zadrozny and Charles Elkan. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. InIcml, volume 1, page 2001,
work page 2001
-
[11]
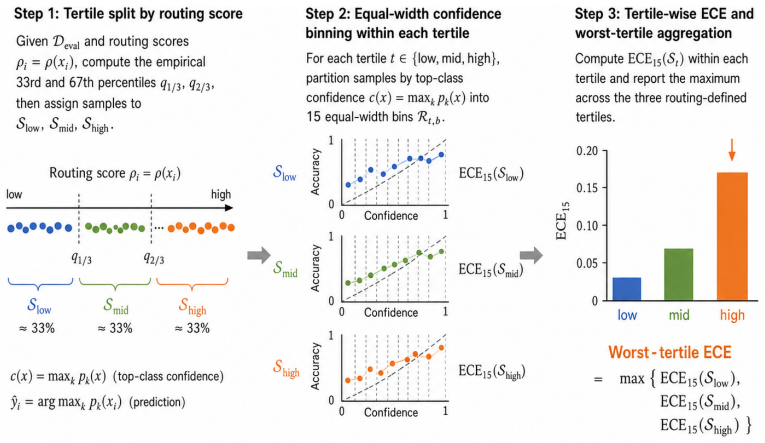
12 A Worst-tertile ECE: bin-level construction Worst-tertile ECE is the diagnostic metric introduced in §2.1 and used as the routing-conditional headline score throughout the paper. The body definition (Eqs. (1) and (2) in §2.1) reports the final aggregation; this appendix unpacks the within-tertile ECE15(St) operator into its bin-level components, in the...
work page 2017
-
[12]
Table 3 reports the three diagnostic metrics we chose not to place in the main comparison: MCE (worst-bin |acc−conf| over 15 equal-width bins), classwise ECE [Kull et al., 2019] (mean of per-class ECE over the 10 CIFAR-10 classes), and SmoothECE [Blasiok and Nakkiran, 2023]. We include SmoothECE in particular as a binning-robust cross-check: the equal-wid...
work page 2019
-
[13]
Classwise ECE is the mean of per-class ECE over the 10 CIFAR-10 classes
MCE is the worst-bin |acc−conf| among 15 equal-width confidence bins (bins with <5 samples ignored);MCE is included only as a stress-test metric — the worst-bin statistic is highly sensitive to tail-bin support and its cross-seed std (e.g., ±0.37 for AR-CondCal) reflects this instability rather than a per-method calibration property. Classwise ECE is the ...
-
[14]
cannot, by construction, see the routing signal
therefore reflects non-linear modelling of confidence and the wider input vector, not routing-specific information. Caveat.The audit does not preclude routing-specific gains under richer probes or different objectives; under the probes and controls evaluated here, the full-profile gain is not routing-specific. O Supporting propositions This appendix conta...
work page 1964
-
[15]
move the empirical ordering, and our main results in Tab. 2 reflect that); (iii) imply improvement on classification accuracy, adversarial robustness, out-of-distribution detection, or safety, which are outside this paper’s scope. The role of these propositions in the paper is interpretive: they explain why a softmax-only calibrator cannot resolve the hyp...
work page 2022
-
[16]
substrate-specific empirical finding
This appendix collects the cross-architecture pilot (ViT-B/16 Block-AR CIFAR-10) and additional cross-substrate / cross-dataset arms that constrain the scope statement of the main paper. ViT-B/16 CIFAR-10 cross-architecture pilot (Block-AR and Full-AR, single seed).Both AR variants of the intended cross-architecture replication are complete on our pipelin...
work page 2020
-
[17]
that no1-D projection of routing uncertainty definitively recovers the routing-conditional calibration signal. Feature c10-Full c100-Full tin-Block tin-Full Raw (no calibration)0.1422 0.1313 0.0907 0.1207 Confidence only0.00410.0126 0.0167 0.0261 Predictive entropy0.0081 0.0131 0.01830.0226 Aggregate routing entropyr agg 0.0055 0.01220.01600.0250 Routing ...
-
[18]
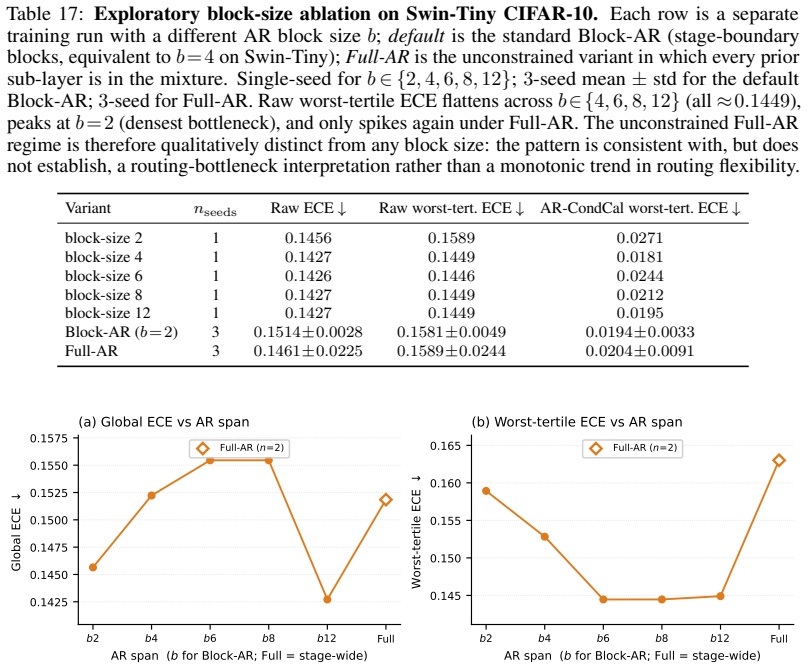
Substrate VariantnMax gap Wt. gap Permutation (mean±std) (mean±std) (p, rej/n) Sw-T / C-10 Block-AR‡ 3 0.193±0.1070.015±0.0030.042,1/3 Full-AR3 0.134±0.0420.020±0.0100.547,0/3 DeiT-S / C-10 Block-AR3 0.122±0.0280.020±0.0090.265,0/3 Full-AR3 0.115±0.0150.019±0.0050.496,0/3 DeiT-S / C-100 Block-AR3 0.094±0.0210.027±0.0020.467,0/3 Full-AR3 0.091±0.0290.026±0...
work page 1920
-
[19]
The two key qualitative signatures replicate verbatim
We re-ran the same temporal pilot (stride- 4 ckpt sampling over 300 epochs; K= 5 ensemble of the last 5 sampled epochs) on the corresponding Swin-Tiny + Block-AR CIFAR-100 cell (seed-1). The two key qualitative signatures replicate verbatim. A consistent direction of effect on both datasets is used here, together with Fig. 4 and App. R, to characterise th...
-
[20]
None of these is protocol- matched main-paper evidence; each is reported only to bound the scope of external-cell interpretations a reviewer might attach. Check Headline finding Cross-regime sanity (ViT-B/16 FT,9cells) Accuracy / ECE / NLL / Brier vary by dataset; no consistent variant ordering survives across cells. Cross-substrate sanity (custom small-V...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.