Recognition: no theorem link
ConsistNav: Closing the Action Consistency Gap in Zero-Shot Object Navigation with Semantic Executive Control
Pith reviewed 2026-05-12 05:09 UTC · model grok-4.3
The pith
A semantic executive with persistent memory and guarded phases closes the action consistency gap in zero-shot object navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
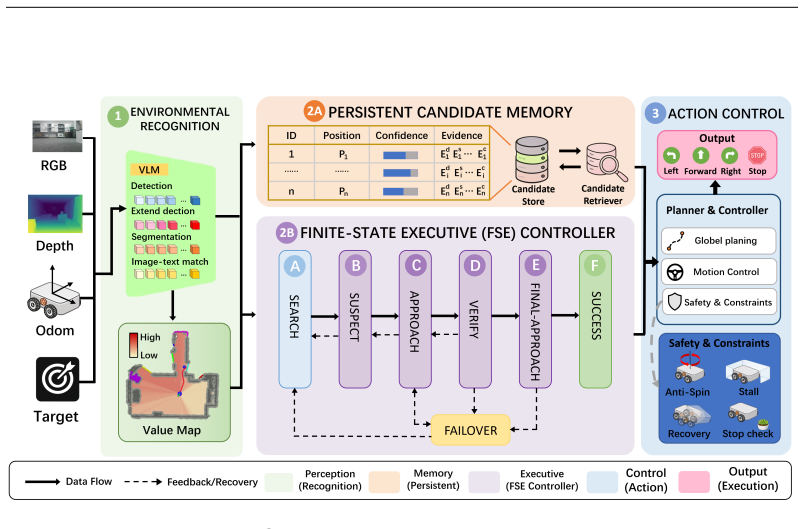
ConsistNav builds a semantic executive around three coordinated modules: a Finite-State Executive Controller that advances target pursuit through guarded semantic phases, a Persistent Candidate Memory that aggregates cross-frame evidence into stable object hypotheses, and Stability-Aware Action Control that suppresses rotational stagnation, ineffective pursuit, and unverified stopping. The design leaves the detector and low-level planner unchanged and instead decides when semantic evidence is allowed to influence navigation. Experiments on HM3D and MP3D show state-of-the-art results among compared zero-shot ObjectNav methods.
What carries the argument
The semantic executive, a training-free controller with three modules (Finite-State Executive Controller, Persistent Candidate Memory, and Stability-Aware Action Control) that manages when and how semantic evidence drives navigation decisions across an episode.
If this is right
- Agents maintain persistent target hypotheses instead of oscillating between exploration and pursuit.
- Success rate rises 11.4 percent and SPL rises 7.9 percent over the controlled baseline on MP3D.
- The framework works with any open-vocabulary detector and low-level planner without modification.
- Phase transitions and stability controls reduce premature abandonment near the target.
- Real-world robot experiments confirm robustness of the executive mechanism.
Where Pith is reading between the lines
- The same executive structure could be applied to other embodied tasks that require consistent commitment over long horizons.
- Stronger detectors would likely amplify gains, but the consistency layer itself addresses a separate failure mode.
- Control logic layered above perception may prove more scalable than retraining perception models for every new task variant.
- Testing the approach in environments with moving objects would reveal whether memory persistence still holds when evidence changes.
Load-bearing premise
Semantic evidence from open-vocabulary detectors remains reliable enough across frames for the memory module to form stable hypotheses and for the controller to make correct phase transitions without being misled by systematic false positives.
What would settle it
Deploying ConsistNav in an environment where detector false positives create persistent wrong hypotheses that the stability module cannot override, resulting in lower success rates than the baseline.
Figures




read the original abstract
Zero-shot object navigation has advanced rapidly with open-vocabulary detectors, image--text models, and language-guided exploration. However, even after current methods detect a plausible target hypothesis, the agent may still oscillate between exploration and pursuit, or abandon the object near success. We identify this failure mode as an action consistency gap: semantic evidence is repeatedly reinterpreted at each step without persistent commitment across the episode. We introduce ConsistNav, a training-free zero-shot ObjectNav framework built around a semantic executive composed of three coordinated modules: Finite-State Executive Controller stages target pursuit through guarded semantic phases; Persistent Candidate Memory accumulates cross-frame target evidence into stable object hypotheses; and Stability-Aware Action Control suppresses rotational stagnation, ineffective pursuit, and unverified stopping. This design changes neither the detector nor the low-level planner; instead, it controls when semantic evidence should influence navigation and when it should be suppressed or revisited. We conduct extensive experiments on HM3D and MP3D, where ConsistNav achieves state-of-the-art results among compared zero-shot ObjectNav methods and improves SR by 11.4% and SPL by 7.9% over the controlled baseline on MP3D. Ablation studies and real-world deployment experiments further demonstrate the effectiveness and robustness of the proposed executive mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ConsistNav, a training-free zero-shot ObjectNav framework that addresses the action consistency gap via a semantic executive composed of a Finite-State Executive Controller for guarded phase transitions, Persistent Candidate Memory for accumulating cross-frame target evidence, and Stability-Aware Action Control for suppressing stagnation and unverified stopping. It reports state-of-the-art results among compared zero-shot methods on HM3D and MP3D, including an 11.4% Success Rate and 7.9% SPL improvement over the controlled baseline, along with ablations and real-world deployment.
Significance. If the empirical results hold under detailed scrutiny, the work provides a modular, detector- and planner-agnostic mechanism for enforcing persistent semantic commitment in navigation, which could meaningfully reduce oscillation and premature abandonment in practical zero-shot settings. The training-free nature and real-world validation strengthen its potential applicability in robotics.
major comments (2)
- Experimental Evaluation: The central claim of 11.4% SR and 7.9% SPL gains on MP3D (and SOTA status) is presented without quantitative details on baseline implementations, statistical variance across runs, number of episodes evaluated, or exact hyperparameter settings for the controlled baseline and compared methods, rendering the improvements difficult to reproduce or assess for significance.
- Persistent Candidate Memory and Finite-State Executive Controller: The accumulation of cross-frame semantic evidence into stable hypotheses and the guarded phase transitions assume open-vocabulary detector outputs remain sufficiently reliable to avoid locking onto false positives or misses (common in HM3D/MP3D due to occlusions and viewpoint changes). No independent semantic verification, confidence thresholding, or backtracking mechanism is described beyond Stability-Aware Action Control's focus on rotational stagnation and unverified stopping, which could allow systematic error propagation into the executive state.
minor comments (1)
- Abstract and Experiments: Explicitly define the 'controlled baseline' and list all compared zero-shot methods with their key implementation references to allow direct comparison of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of reproducibility and robustness that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: Experimental Evaluation: The central claim of 11.4% SR and 7.9% SPL gains on MP3D (and SOTA status) is presented without quantitative details on baseline implementations, statistical variance across runs, number of episodes evaluated, or exact hyperparameter settings for the controlled baseline and compared methods, rendering the improvements difficult to reproduce or assess for significance.
Authors: We agree that the experimental section would benefit from greater specificity to support reproducibility. In the revised manuscript we will add: explicit descriptions of baseline re-implementations (including any adaptations made to the controlled baseline), the precise evaluation protocol with episode counts per dataset, all relevant hyperparameter values in a dedicated table or appendix, and statistical variance (means and standard deviations) computed over multiple random seeds or runs. These additions will allow readers to more readily verify the reported gains and assess their significance. revision: yes
-
Referee: Persistent Candidate Memory and Finite-State Executive Controller: The accumulation of cross-frame semantic evidence into stable hypotheses and the guarded phase transitions assume open-vocabulary detector outputs remain sufficiently reliable to avoid locking onto false positives or misses (common in HM3D/MP3D due to occlusions and viewpoint changes). No independent semantic verification, confidence thresholding, or backtracking mechanism is described beyond Stability-Aware Action Control's focus on rotational stagnation and unverified stopping, which could allow systematic error propagation into the executive state.
Authors: We acknowledge the valid concern regarding potential propagation of detector errors. The Persistent Candidate Memory accumulates detections over multiple frames precisely to filter transient false positives and misses caused by occlusions or viewpoint variation, while the guarded transitions of the Finite-State Executive Controller limit rapid state changes based on single unreliable observations. Stability-Aware Action Control further reduces the risk of unverified stopping. That said, the framework does not introduce separate confidence thresholding or explicit backtracking beyond these mechanisms, as the goal is to remain training-free and detector-agnostic. In the revision we will add a limitations subsection that discusses failure modes arising from persistent detector errors, supported by qualitative examples drawn from the existing experiments, and note possible future extensions. revision: partial
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper introduces a training-free zero-shot navigation framework with three modules (Finite-State Executive Controller, Persistent Candidate Memory, Stability-Aware Action Control) that coordinate semantic phases and action stability. No equations, fitted parameters, or first-principles derivations appear; the central claims are empirical improvements (SR +11.4%, SPL +7.9% on MP3D) measured against external baselines on public datasets HM3D/MP3D. Ablations and real-world tests provide independent verification. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps, and results do not reduce to quantities defined by the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Open-vocabulary detectors and image-text models supply usable semantic evidence that can be accumulated and phased without systematic bias
invented entities (1)
-
Semantic Executive
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Batra, Dhruv and Gokaslan, Aaron and Kembhavi, Aniruddha and Maksymets, Oleksandr and Mottaghi, Roozbeh and Savva, Manolis and Toshev, Alexander and Wijmans, Erik , journal =
-
[2]
Savva, Manolis and Kadian, Abhishek and Maksymets, Oleksandr and Zhao, Yili and Wijmans, Erik and Jain, Bhavana and Straub, Julian and Liu, Jia and Koltun, Vladlen and Malik, Jitendra and Parikh, Devi and Batra, Dhruv , booktitle =
-
[3]
Ramakrishnan, Santhosh K. and Gokaslan, Aaron and Wijmans, Erik and Maksymets, Oleksandr and Clegg, Alexander and Turner, John and Undersander, Eric and Galuba, Wojciech and Westbury, Andrew and Chang, Angel X. and Savva, Manolis and Zhao, Yili and Batra, Dhruv , booktitle =
-
[4]
Chang, Angel X. and Dai, Angela and Funkhouser, Thomas and Halber, Maciej and Niessner, Matthias and Savva, Manolis and Song, Shuran and Zeng, Andy and Zhang, Yinda , booktitle =. Matterport3D: Learning from
-
[5]
Wijmans, Erik and Kadian, Abhishek and Morcos, Ari and Lee, Stefan and Essa, Irfan and Parikh, Devi and Batra, Dhruv and Maksymets, Oleksandr , booktitle =
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Object Goal Navigation using Goal-Oriented Semantic Exploration , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[7]
and Al-Halah, Ziad and Grauman, Kristen , booktitle =
Ramakrishnan, Santhosh K. and Al-Halah, Ziad and Grauman, Kristen , booktitle =
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Habitat-Web: Learning Embodied Object-Goal Navigation from Human Demonstrations at Scale , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[9]
Yadav, Karmesh and Ramrakhya, Ram and Majumdar, Arjun and Berges, Vincent-Pierre and Kuhar, Sachit and Batra, Dhruv and Baevski, Alexei and Maksymets, Oleksandr , journal =
-
[10]
Khandelwal, Apoorv and Weihs, Luca and Mottaghi, Roozbeh and Kembhavi, Aniruddha , booktitle =. Simple but Effective:
-
[11]
Majumdar, Arjun and Aggarwal, Gunjan and Devnani, Bhavika and Hoffman, Judy and Batra, Dhruv , booktitle =
-
[12]
Gadre, Samir Yitzhak and Wortsman, Mitchell and Ilharco, Gabriel and Schmidt, Ludwig and Song, Shuran , booktitle =
-
[13]
Yokoyama, Naoki and Ha, Sehoon and Batra, Dhruv and Wang, Jiuguang and Bucher, Bernadette , booktitle =
-
[14]
Yu, Bangguo and Tan, Jie and Sarkar, Aurojit and Sherif, Muhammed and Burgard, Wolfram and Kulić, Dana , booktitle =
-
[15]
Proceedings of the Conference on Robot Learning (CoRL) , year =
Shah, Dhruv and Osi. Proceedings of the Conference on Robot Learning (CoRL) , year =
-
[16]
Liang, Zhiyuan and others , journal =
-
[17]
A Frontier-Based Approach for Autonomous Exploration , author =. Proceedings of the IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA) , year =
-
[18]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =
- [19]
-
[20]
Wang, Chien-Yao and Bochkovskiy, Alexey and Liao, Hong-Yuan Mark , booktitle =
-
[21]
Faster Segment Anything: Towards Lightweight
Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung-Ho and Lee, Seungkyu and Hong, Choong Seon , journal =. Faster Segment Anything: Towards Lightweight
-
[22]
Automated Planning: Theory and Practice , author =
-
[23]
and Precup, Doina and Singh, Satinder , journal =
Sutton, Richard S. and Precup, Doina and Singh, Satinder , journal =. Between
-
[24]
Artificial Intelligence , volume =
Planning and Acting in Partially Observable Stochastic Domains , author =. Artificial Intelligence , volume =
-
[25]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Learning Transferable Visual Models from Natural Language Supervision , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[26]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Segment Anything , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Visual Instruction Tuning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[28]
arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Emerging Properties in Self-Supervised Vision Transformers , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[30]
International Conference on Learning Representations (ICLR) , year =
Open-Vocabulary Object Detection via Vision and Language Knowledge Distillation , author =. International Conference on Learning Representations (ICLR) , year =
-
[31]
Proceedings of the European Conference on Computer Vision (ECCV) , year =
Simple Open-Vocabulary Object Detection with Vision Transformers , author =. Proceedings of the European Conference on Computer Vision (ECCV) , year =
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Grounded Language-Image Pre-Training , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[33]
Zhou, Kaiwen and Zheng, Kaizhi and Pryor, Connor and Shen, Yilin and Jin, Hongxia and Getoor, Lise and Wang, Xin Eric , booktitle =
-
[34]
Rajvanshi, Abhinav and Sikka, Karan and Lin, Xiao and Lee, Bhoram and Chiu, Han-Pang and Velasquez, Alvaro , booktitle =
-
[35]
Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =
Bridging Zero-shot Object Navigation and Foundation Models through Pixel-Guided Navigation Skill , author =. Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =
-
[36]
Kuang, Yuxuan and Lin, Hai and Jiang, Meng , booktitle =
-
[37]
Long, Yuxing and Cai, Wenzhe and Wang, Hongcheng and Chen, Guanqi and Dong, Hao , journal =
-
[38]
Zhang, Lingfeng and Zhang, Qiang and Wang, Hao and Xiao, Erjia and Jiang, Zixuan and Chen, Honglei and Xu, Renjing , journal =
-
[39]
Yin, Hang and Xu, Xiuwei and Wu, Zhenyu and Zhou, Jie and Lu, Jiwen , journal =
-
[40]
Zhang, Jiazhao and Wang, Kunyu and Xu, Rongtao and Geng, Gengze and Zhao, Yicong and Chen, Xiaomeng and Wei, Shibo and Zhao, Peng and Xu, Kai and He, Xuelong and Liu, Zuxuan and Li, Yu-Gang , booktitle =
-
[41]
Learning to Explore Using Active Neural
Chaplot, Devendra Singh and Gandhi, Dhiraj and Gupta, Saurabh and Gupta, Abhinav and Salakhutdinov, Ruslan , booktitle =. Learning to Explore Using Active Neural
-
[42]
Ramrakhya, Ram and Batra, Dhruv and Wijmans, Erik and Das, Abhishek , booktitle =
-
[43]
Deitke, Matt and VanderBilt, Eli and Herrasti, Alvaro and Weihs, Luca and Ehsani, Kiana and Salvador, Jordi and Han, Winson and Kolve, Eric and Kembhavi, Aniruddha and Mottaghi, Roozbeh , booktitle =
-
[44]
Maksymets, Oleksandr and Cartillier, Vincent and Gokaslan, Aaron and Wijmans, Erik and Galuba, Wojciech and Lee, Stefan and Batra, Dhruv , booktitle =
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Hierarchical Object-to-Zone Graph for Object Navigation , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[46]
Hong, Yicong and Wu, Qi and Qi, Yuankai and Rodriguez-Opazo, Cristian and Gould, Stephen , booktitle =
-
[47]
An, Dong and Wang, Hanqing and Wang, Wenguan and Wang, Zun and Dai, Yan and He, Jianbing and Shen, Linyi and Wang, Jiao and Zhang, Liang , journal =
-
[48]
On Evaluation of Embodied Navigation Agents
On Evaluation of Embodied Navigation Agents , author =. arXiv preprint arXiv:1807.06757 , year =
work page internal anchor Pith review arXiv
-
[49]
Duan, Jiafei and Yu, Samson and Tan, Hui Li and Zhu, Hongyuan and Tan, Cheston , journal =. A Survey of Embodied
-
[50]
Rosinol, Antoni and Abate, Marcus and Chang, Yun and Carlone, Luca , booktitle =
-
[51]
and Leutenegger, Stefan , booktitle =
McCormac, John and Handa, Ankur and Davison, Andrew J. and Leutenegger, Stefan , booktitle =
-
[52]
Planning Algorithms , author =
- [53]
-
[54]
IEEE Robotics & Automation Magazine , volume =
The Dynamic Window Approach to Collision Avoidance , author =. IEEE Robotics & Automation Magazine , volume =
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Flamingo: A Visual Language Model for Few-Shot Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[56]
Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Tober, Marc and Zeng, Andy...
-
[57]
Chen, Deyao and Liu, Zongyu and Zhu, Jingliao and Ren, Zeqian and Yan, Jianfeng and Che, Wanxiang and Liu, Ting , booktitle =
-
[58]
Navigating to Objects in the Real World , author =. Science Robotics , year =
-
[59]
Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =
Visual Language Maps for Robot Navigation , author =. Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , year =
-
[60]
Shah, Dhruv and Eysenbach, Benjamin and Kahn, Gregory and Levine, Sergey , booktitle =
-
[61]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Think Before You Act: Decision Transformers with Working Memory , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[62]
Brohan, Anthony and Brown, Noah and Carbajal, Justice and Chebotar, Yevgen and Chen, Xi and Choromanski, Krzysztof and Ding, Tianli and Driess, Danny and Dubey, Avinava and Finn, Chelsea and others , journal =
-
[63]
Ahn, Michael and Brohan, Anthony and Brown, Noah and Chebotar, Yevgen and Cortes, Omar and David, Byron and Finn, Chelsea and Fu, Chuyuan and Gober, Keerthana and Gopalakrishnan, Karol and others , booktitle =. Do As
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[65]
International Conference on Learning Representations (ICLR) , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations (ICLR) , year =
-
[66]
Mur-Artal, Raul and Montiel, J. M. M. and Tard. IEEE Transactions on Robotics , volume =
-
[67]
IEEE Transactions on Robotics , volume =
Campos, Carlos and Elvira, Richard and Rodr. IEEE Transactions on Robotics , volume =
-
[68]
Quigley, Morgan and Conley, Ken and Gerkey, Brian and Faust, Josh and Foote, Tully and Leibs, Jeremy and Wheeler, Rob and Ng, Andrew Y. , booktitle =
-
[69]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Habitat 2.0: Training Home Assistants to Rearrange their Habitat , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.