Recognition: unknown
Key-Value Means: Transformers with Expandable Block-Recurrent Compressed Memory
Pith reviewed 2026-05-14 20:55 UTC · model grok-4.3
The pith
A transformer using averaged key-value blocks over fixed segments maintains competitive long-context accuracy with subquadratic prefill and sublinear state growth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Key-Value Means compresses the attention cache by replacing blocks of key-value pairs with their vector means, supporting either constant-size state or an expandable growing cache. When inserted into a transformer, the fixed-size version produces an O(N) chunked recurrent network with negligible extra parameters. The growable version, trained end-to-end, reaches competitive scores on long-context tasks while requiring only subquadratic prefill time and sublinear state growth during decoding.
What carries the argument
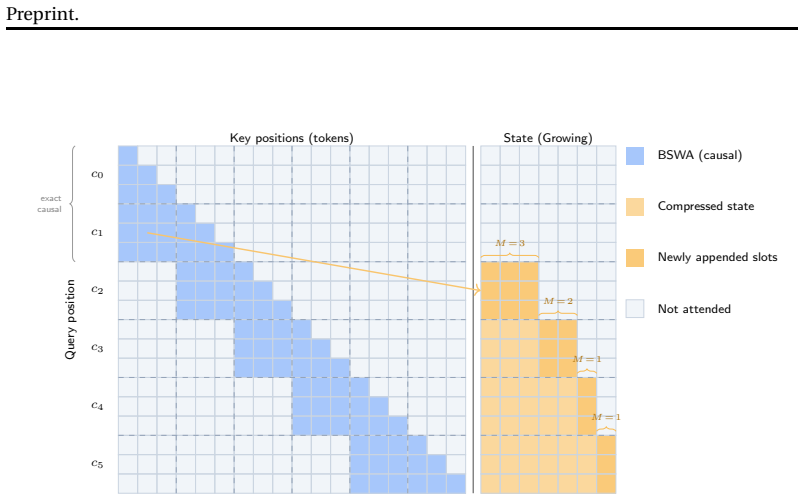
Key-Value Means (KVM), the replacement of key-value sequences by their block-wise averages to form a compressed recurrent attention state.
If this is right
- KVM layers can replace standard attention on every layer to reduce KV-cache memory footprint.
- Prefill complexity can be set anywhere between O(N) and O(N^2) by choosing block size, allowing tunable speed-memory trade-offs.
- Hybrid models that combine KVM layers with linear RNN layers gain sublinear memory growth for extended context lengths.
- Chunk-wise parallel training and prefill remain available without custom kernels or changes to the optimizer.
Where Pith is reading between the lines
- The same averaging idea could be applied to other attention variants to test whether block compression generalizes beyond standard softmax attention.
- Because state growth is sublinear, the method may enable practical deployment of longer contexts on memory-limited hardware without full retraining.
- If block averaging works well, future work could explore learned or adaptive block sizes that preserve more signal in critical regions.
Load-bearing premise
Averaging keys and values over blocks preserves enough information for the model to stay competitive with full attention on long-context tasks.
What would settle it
A clear performance gap versus the full-attention baseline on a long-context retrieval benchmark such as needle-in-haystack when block size is increased would show that the averaging discards necessary details.
Figures


read the original abstract
We present Key-Value Means ("KVM"), a novel block-recurrence for attention that can accommodate either fixed-size or growing state. Equipping a strong transformer baseline with fixed-size KVM attention layers yields a strong $O(N)$ chunked RNN, while adding only an insignificant number of new parameters. We train a transformer with a growable KVM cache and show it performs competitively on long-context tests with only subquadratic prefill time and sublinear state growth. KVM is implementable with standard operations and without custom kernels, and supports chunk-wise parallelizable training and prefill. It provides many of the benefits of both traditional transformers (expandable context memory, chunk-wise parallelizable training and prefill) and linear RNNs in a single unified package. It can be used on every layer, saving KV-cache memory, and allowing a continuous range of choices of prefill time complexity between $O(N)$ and $O(N^2)$. It can also be implemented in a hybrid solution in tandem with LRNN layers in place of traditional attention, to supplement the LRNN with improved sublinear memory growth context length usage and long context decoding. We release our code at https://github.com/recursal/KVM-paper and trained models at https://huggingface.co/collections/recursal/key-value-means under the Apache 2.0 license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Key-Value Means (KVM), a block-recurrent attention mechanism that replaces per-token key-value pairs with block-wise averages to support either fixed-size or growable compressed memory states in transformers. It claims this yields O(N) chunked RNN behavior with subquadratic prefill, sublinear state growth, competitive long-context performance, and compatibility with standard operations, chunk-parallel training/prefill, and hybrid LRNN use.
Significance. If the performance claims are validated, KVM would provide a practical, parameter-light bridge between full-attention transformers and linear RNNs, enabling tunable memory-compute trade-offs and reduced KV-cache footprint while preserving expandability. The public release of code and trained models is a clear strength for reproducibility.
major comments (3)
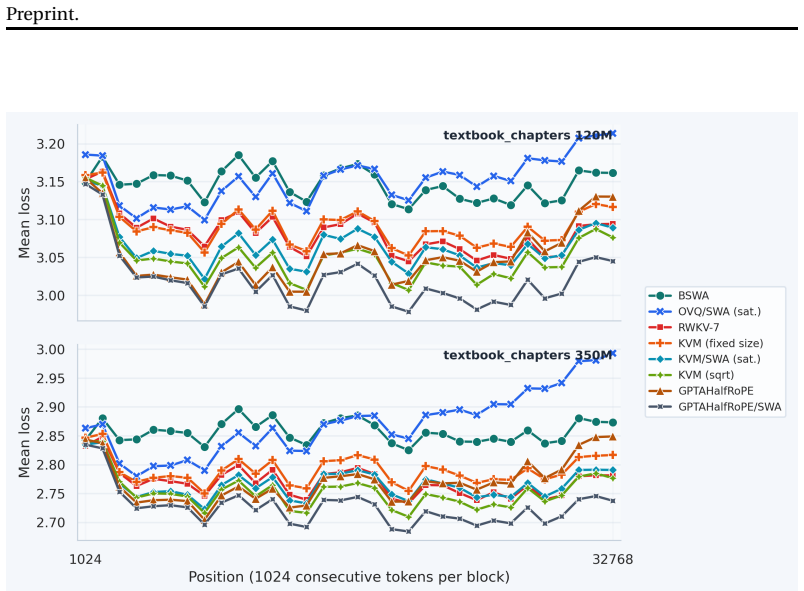
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that a growable KVM cache 'performs competitively on long-context tests' is unsupported by any reported metrics, baselines, ablation tables, or error bars; without these the competitiveness assertion cannot be evaluated.
- [§3.2] §3.2 (KVM definition): block-wise averaging of keys and values is presented without any analysis, bound, or empirical measurement of accumulated approximation error across layers or cache merges; this directly bears on whether sublinear state growth preserves the information needed for the claimed long-context accuracy.
- [§3.1 and §4] §3.1 and §4: the stated O(N) prefill and sublinear growth are asserted but not accompanied by wall-clock timings, memory scaling plots, or comparisons against full attention and other compressed-memory baselines, leaving the complexity claims unverified.
minor comments (2)
- [§3] Notation for block size and merge operations could be made more explicit in the equations to aid re-implementation.
- [Figures] Figure captions should explicitly state which baseline each curve corresponds to.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional empirical support and analysis will strengthen the manuscript. We will revise the paper to include the requested metrics, error analysis, and scaling measurements while preserving the core technical contributions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that a growable KVM cache 'performs competitively on long-context tests' is unsupported by any reported metrics, baselines, ablation tables, or error bars; without these the competitiveness assertion cannot be evaluated.
Authors: We agree that the current version does not include sufficient quantitative results to fully support the competitiveness claim for the growable KVM variant. In the revision we will add a dedicated long-context evaluation section with tables reporting perplexity or accuracy on standard benchmarks (e.g., LongBench, PG-19), direct comparisons against full-attention baselines and recent compressed-memory methods, ablation studies on block size and merge frequency, and error bars from at least three random seeds. These additions will allow readers to evaluate the claim directly. revision: yes
-
Referee: [§3.2] §3.2 (KVM definition): block-wise averaging of keys and values is presented without any analysis, bound, or empirical measurement of accumulated approximation error across layers or cache merges; this directly bears on whether sublinear state growth preserves the information needed for the claimed long-context accuracy.
Authors: The observation is correct: §3.2 currently presents the averaging operation without accompanying error analysis. We will expand this section with (1) a simple analytic bound on the per-merge approximation error under standard assumptions on key/value distributions, (2) empirical measurements of cosine similarity and downstream task degradation after repeated merges across multiple layers, and (3) a short ablation showing how error accumulates with cache size. These additions will clarify the information-preservation properties of sublinear growth. revision: yes
-
Referee: [§3.1 and §4] §3.1 and §4: the stated O(N) prefill and sublinear growth are asserted but not accompanied by wall-clock timings, memory scaling plots, or comparisons against full attention and other compressed-memory baselines, leaving the complexity claims unverified.
Authors: We acknowledge the absence of concrete runtime and memory measurements. The revised manuscript will include (a) wall-clock prefill timings on sequences up to 128k tokens for KVM versus full attention, (b) memory-footprint scaling plots demonstrating sublinear growth, and (c) side-by-side comparisons against both full attention and representative linear/compressed baselines. All measurements will be obtained on the same hardware to ensure fair verification of the claimed complexity benefits. revision: yes
Circularity Check
KVM proposal is an independent architectural construction with no load-bearing reductions to self-defined quantities
full rationale
The paper introduces Key-Value Means as a block-recurrence attention mechanism that replaces per-token KV pairs with block averages, enabling fixed or growable state. No equations are presented that define a quantity in terms of itself or rename a fitted parameter as a prediction. Central claims rest on empirical training results and external code release rather than any self-citation chain or uniqueness theorem imported from prior author work. The derivation is therefore self-contained as a design choice whose validity is tested against long-context benchmarks outside the method's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Averaging keys and values over blocks preserves enough information for competitive attention performance
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression , author=. 2024 , eprint=
work page 2024
- [3]
-
[4]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
- [5]
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[8]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
work page 2021
-
[9]
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. 2019 , eprint=
work page 2019
-
[10]
RWKV-7 "Goose" with Expressive Dynamic State Evolution , author=. 2025 , eprint=
work page 2025
-
[11]
DataComp-LM: In search of the next generation of training sets for language models , author=. 2024 , journal=
work page 2024
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Gated Delta Networks: Improving Mamba2 with Delta Rule , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
- [14]
-
[15]
TransformerFAM: Feedback attention is working memory , author=. 2024 , eprint=
work page 2024
-
[16]
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
work page 2024
-
[17]
Attention Score is not All You Need for Token Importance Indicator in KV Cache Reduction: Value Also Matters , author=. 2024 , eprint=
work page 2024
-
[18]
The Fourteenth International Conference on Learning Representations , year=
Test-Time Training Done Right , author=. The Fourteenth International Conference on Learning Representations , year=
-
[19]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Titans: Learning to Memorize at Test Time , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[20]
Kimi Linear: An Expressive, Efficient Attention Architecture , author=. 2025 , eprint=
work page 2025
-
[21]
Block-Recurrent Transformers , url =
Hutchins, DeLesley and Schlag, Imanol and Wu, Yuhuai and Dyer, Ethan and Neyshabur, Behnam , booktitle =. Block-Recurrent Transformers , url =
-
[22]
The Thirteenth International Conference on Learning Representations , year=
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters , author=. The Thirteenth International Conference on Learning Representations , year=
- [23]
-
[24]
Learning to (Learn at Test Time):
Yu Sun and Xinhao Li and Karan Dalal and Jiarui Xu and Arjun Vikram and Genghan Zhang and Yann Dubois and Xinlei Chen and Xiaolong Wang and Sanmi Koyejo and Tatsunori Hashimoto and Carlos Guestrin , booktitle=. Learning to (Learn at Test Time):. 2025 , url=
work page 2025
- [25]
-
[26]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Rope to Nope and Back Again: A New Hybrid Attention Strategy , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[27]
International Conference on Learning Representations , year=
Compressive Transformers for Long-Range Sequence Modelling , author=. International Conference on Learning Representations , year=
-
[28]
How to Train Long-Context Language Models (Effectively) , author=. ACL , year=
-
[29]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[30]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Don't be lazy: CompleteP enables compute-efficient deep transformers , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[31]
Why Gradients Rapidly Increase Near the End of Training , author=. 2025 , eprint=
work page 2025
-
[32]
Joshua Ainslie and James Lee-Thorp and Michiel de Jong and Yury Zemlyanskiy and Federico Lebron and Sumit Sanghai , booktitle=. 2023 , url=
work page 2023
-
[33]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
work page 2024
-
[34]
International Conference on Machine Learning , pages=
Linear Transformers Are Secretly Fast Weight Programmers , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[35]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks , author=. Neural Computation , volume=. 1992 , publisher=
work page 1992
-
[36]
The LAMBADA dataset: Word prediction requiring a broad discourse context
The LAMBADA dataset: Word prediction requiring a broad discourse context , author=. arXiv preprint arXiv:1606.06031 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg , booktitle=. 2024 , url=
work page 2024
-
[38]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. 2024 , eprint=
work page 2024
-
[39]
Test-time regression: a unifying framework for designing sequence models with associative memory , author=. 2025 , eprint=
work page 2025
-
[40]
Straight to Zero: Why Linearly Decaying the Learning Rate to Zero Works Best for LLMs , author=. 2025 , eprint=
work page 2025
-
[41]
Forty-first International Conference on Machine Learning , year=
Language Models as Science Tutors , author=. Forty-first International Conference on Machine Learning , year=
-
[42]
The Impact of Positional Encoding on Length Generalization in Transformers , author=. 2023 , eprint=
work page 2023
-
[43]
Transformer Language Models without Positional Encodings Still Learn Positional Information
Haviv, Adi and Ram, Ori and Press, Ofir and Izsak, Peter and Levy, Omer. Transformer Language Models without Positional Encodings Still Learn Positional Information. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.99
-
[44]
Flex Attention: A Programming Model for Generating Optimized Attention Kernels , author=. 2024 , eprint=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.