Recognition: no theorem link
M2A: Synergizing Mathematical and Agentic Reasoning in Large Language Models
Pith reviewed 2026-05-12 04:40 UTC · model grok-4.3
The pith
M2A merges mathematical reasoning into agent models solely in the null space of agent-critical features, raising SWE-Bench Verified success from 44 percent to 51.2 percent without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
M2A is a model-merging paradigm that identifies the feature subspace critical for agent behavior and merges the mathematical reasoning task vector exclusively along its null space. This injects mathematical capability in directions that do not perturb agent behavior, thereby extending reasoning depth in agentic settings while exposing the merge coefficient as a direct control for reasoning length.
What carries the argument
The feature subspace critical for agent behavior and its null space, into which the mathematical reasoning task vector is merged to avoid altering agent performance.
If this is right
- Agent models gain extended reasoning depth on complex, multi-turn tasks without any gradient updates.
- The merge coefficient directly controls reasoning length, providing a tunable knob absent in standard fine-tuning.
- Substantial gains appear on real-world coding agent benchmarks such as SWE-Bench Verified.
- The approach avoids the misalignment that arises when mathematical and agentic patterns are learned jointly through SFT or RL.
Where Pith is reading between the lines
- Similar null-space merges could decouple other pairs of reasoning styles that currently interfere in LLMs.
- The method implies that capability directions in parameter space can be treated as approximately orthogonal for targeted injection.
- If the subspace identification step proves robust across model families, the technique could be applied to combine additional capabilities such as tool use and formal verification.
Load-bearing premise
The critical feature subspace for agent behavior can be identified accurately enough that merging the math vector only in its null space adds reasoning without reducing agent stability or performance.
What would settle it
A measurable drop in agent success rate on SWE-Bench Verified or other agent benchmarks after the merge, or no improvement on tasks that require both math and multi-turn interaction, would show the null-space injection failed to preserve agent behavior.
Figures




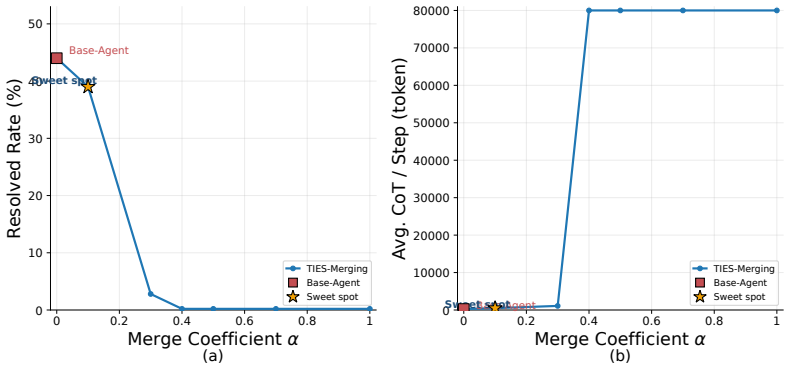
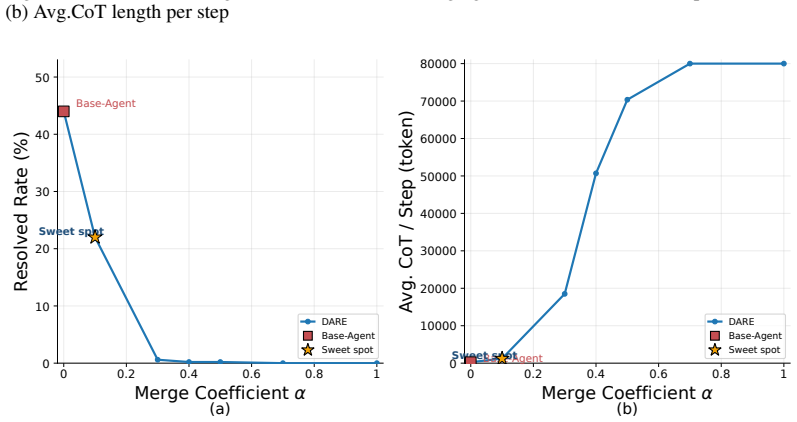





read the original abstract
While reasoning has become a central capability of large language models (LLMs), the reasoning patterns required for different scenarios are often misaligned. Mathematical reasoning typically relies on intrinsic logic to solve closed-world problems in a single response, whereas agentic reasoning requires not only internal reasoning but also multi-turn interaction with external environments, interleaving thought and action. This misalignment prevents mathematical and agentic reasoning from effectively benefiting from each other, often yielding unstable reasoning behavior and only limited performance gains under multi-task learning. In this paper, we propose M2A, a novel paradigm that synergizes mathematical and agentic reasoning via model merging. To avoid overfitting to superficial reasoning patterns under joint training, M2A operates directly in parameter space: it identifies the feature subspace critical for agent behavior, and merges the mathematical reasoning task vector only along its null space, thereby injecting reasoning capability along directions that do not perturb agent behavior. Unlike SFT or RL, M2A requires no additional gradient-update and exposes the merging coefficient as a simple knob for controlling reasoning length. Experiments in a challenging real-world coding agent setting show that our method effectively extends agentic reasoning depth and delivers substantial performance improvements. Applied to a fine-tuned Qwen3-8B, M2A improves its SWE-Bench Verified resolved rate from 44.0% to 51.2% without retraining the model. Code is available at https://github.com/laplucky/M2A.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes M2A, a model merging method to combine mathematical and agentic reasoning in LLMs. It identifies the feature subspace critical for agent behavior and merges the mathematical reasoning task vector exclusively along the null space of that subspace, thereby adding math capabilities without perturbing agentic behavior. The approach requires no gradient updates or retraining; the merging coefficient acts as a control for reasoning depth. On a fine-tuned Qwen3-8B model, M2A raises the resolved rate on SWE-Bench Verified from 44.0% to 51.2%.
Significance. If the subspace isolation and null-space guarantee hold, the work offers a practical, training-free route to reconcile misaligned reasoning modes that joint SFT or RL often destabilize. The explicit control knob and code release are clear strengths for reproducibility and usability. The reported gain on a real-world coding benchmark is notable, but the overall significance remains provisional until the preservation of agent behavior is more rigorously demonstrated across metrics and tasks.
major comments (2)
- [§3] §3 (Method): The subspace identification step is presented at a conceptual level but lacks an explicit equation or algorithm for computing the agent-critical subspace (e.g., no definition of how activations are sampled across trajectories, whether SVD or mean-difference is used, or how the null-space projector is constructed). This detail is load-bearing for the central claim that merging occurs strictly in directions orthogonal to all agentic computations.
- [§4] §4 (Experiments): The reported SWE-Bench improvement is shown only as an aggregate resolved rate; no ablation or auxiliary metric confirms that multi-turn agent behavior, tool-use accuracy, or trajectory stability remain unchanged after merging. Without such verification, the assertion that null-space merging adds math reasoning “without any negative effect” rests on a single downstream number rather than direct evidence.
minor comments (1)
- [Abstract] Abstract: The phrase “exposes the merging coefficient as a simple knob for controlling reasoning length” is not accompanied by any quantitative plot or table showing length vs. coefficient; adding this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additional evidence.
read point-by-point responses
-
Referee: [§3] §3 (Method): The subspace identification step is presented at a conceptual level but lacks an explicit equation or algorithm for computing the agent-critical subspace (e.g., no definition of how activations are sampled across trajectories, whether SVD or mean-difference is used, or how the null-space projector is constructed). This detail is load-bearing for the central claim that merging occurs strictly in directions orthogonal to all agentic computations.
Authors: We agree that the current description in Section 3 remains at a conceptual level and would benefit from explicit equations and an algorithmic outline. In the revised manuscript we will add the precise definitions: how activations are sampled across agent trajectories, the procedure used to compute the agent-critical subspace, and the construction of the null-space projector. These additions will make the orthogonality guarantee fully explicit and reproducible. revision: yes
-
Referee: [§4] §4 (Experiments): The reported SWE-Bench improvement is shown only as an aggregate resolved rate; no ablation or auxiliary metric confirms that multi-turn agent behavior, tool-use accuracy, or trajectory stability remain unchanged after merging. Without such verification, the assertion that null-space merging adds math reasoning “without any negative effect” rests on a single downstream number rather than direct evidence.
Authors: We acknowledge that an aggregate resolved rate alone does not directly verify preservation of multi-turn agent behavior. In the revised version we will add auxiliary metrics and ablations, including tool-use accuracy, multi-turn subtask success rates, and trajectory stability indicators, to provide direct evidence that agentic capabilities remain intact after merging. revision: yes
Circularity Check
No significant circularity in M2A subspace identification or merging procedure
full rationale
The paper's core method identifies an agent-critical feature subspace (via activation differences or similar) and merges the mathematical task vector exclusively in its null space. This is a direct algorithmic procedure described in the abstract and method, not a self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations reduce the claimed performance gain (44.0% to 51.2% on SWE-Bench) to the input data by construction; the subspace isolation and null-space projection are presented as independent operations whose validity is tested empirically rather than assumed tautologically. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- merging coefficient
axioms (1)
- domain assumption A well-defined feature subspace exists that is critical for agent behavior and whose null space can accept mathematical reasoning updates without perturbing that behavior.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, February 2026. Accessed: 2026-04-25
work page 2026
-
[2]
Haoyue Bai, Yiyou Sun, Wenjie Hu, Shi Qiu, Maggie Ziyu Huan, Peiyang Song, Robert Nowak, and Dawn Song. How and why llms generalize: A fine-grained analysis of llm reasoning from cognitive behaviors to low-level patterns.arXiv preprint arXiv:2512.24063, 2025
-
[3]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Math- arena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Parameter competition balancing for model merging
Guodong Du, Junlin Lee, Jing Li, Runhua Jiang, Yifei Guo, Shuyang Yu, Hanting Liu, Sim K Goh, Ho-Kin Tang, Daojing He, et al. Parameter competition balancing for model merging. Advances in Neural Information Processing Systems, 37:84746–84776, 2024
work page 2024
-
[6]
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Shi Jie, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Alphaedit: Null-space constrained knowledge editing for language models. arXiv preprint arXiv:2410.02355, 2024
-
[7]
Arcee’s mergekit: A toolkit for merging large language models
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s mergekit: A toolkit for merging large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 477–485, 2024
work page 2024
-
[8]
Google DeepMind. Gemini 3.1 pro. https://deepmind.google/models/gemini/pro/,
-
[9]
Accessed: 2026-04-25
work page 2026
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Pooven- dran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning.arXiv preprint arXiv:2507.00432, 2025
-
[13]
Zhehao Huang, Yuhang Liu, Baijiong Lin, Yixin Lou, Zhengbao He, Hanling Tian, Tao Li, and Xiaolin Huang. Rain-merging: A gradient-free method to enhance instruction following in large reasoning models with preserved thinking format.arXiv preprint arXiv:2602.22538, 2026
-
[14]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Ha- jishirzi, and Ali Farhadi. Editing models with task arithmetic. InThe Eleventh International Conference on Learning Representations
-
[15]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022. 10
work page 2022
-
[18]
mini-swe-agent-plus: The 100-line AI agent that solves GitHub issues with text-edit tool
Kwai-Klear. mini-swe-agent-plus: The 100-line AI agent that solves GitHub issues with text-edit tool. https://github.com/Kwai-Klear/mini-swe-agent-plus , 2025. GitHub Repository
work page 2025
-
[19]
Yu Li, Mingyang Yi, Xiuyu Li, Ju Fan, Fuxin Jiang, Binbin Chen, Peng Li, Jie Song, and Tieying Zhang. Reasoning and tool-use compete in agentic rl: From quantifying interference to disentangled tuning.arXiv preprint arXiv:2602.00994, 2026
-
[20]
SWE-AGILE: A Software Agent Framework for Efficiently Managing Dynamic Reasoning Context
Shuquan Lian, Juncheng Liu, Yazhe Chen, Yuhong Chen, and Hui Li. Swe-agile: A soft- ware agent framework for efficiently managing dynamic reasoning context.arXiv preprint arXiv:2604.11716, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
M. Luo, N. Jain, J. Singh, S. Tan, A. Patel, Q. Wu, A. Ariyak, C. Cai, T. Venkat, S. Zhu, B. Athiwaratkun, M. Roongta, C. Zhang, L. E. Li, R. A. Popa, K. Sen, and I. Stoica. DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling RL. https://www. together.ai/blog/deepswe, July 2025. Together AI Blog post
work page 2025
-
[22]
Led-merging: Mitigating safety-utility conflicts in model merging with location-election-disjoint
Qianli Ma, Dongrui Liu, Qian Chen, Linfeng Zhang, and Jing Shao. Led-merging: Mitigating safety-utility conflicts in model merging with location-election-disjoint. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21749–21767, 2025
work page 2025
-
[23]
General- reasoner: Advancing llm reasoning across all domains.arXiv preprint arXiv:2505.14652,
Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, and Wenhu Chen. General- reasoner: Advancing llm reasoning across all domains.arXiv preprint arXiv:2505.14652, 2025
-
[24]
OpenAI. Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-2/ , De- cember 2025. Accessed: 2026-04-25
work page 2025
-
[25]
OpenHands critic 32b exp 20250417
OpenHands Team. OpenHands critic 32b exp 20250417. https://huggingface.co/ OpenHands/openhands-critic-32b-exp-20250417, 2025. Accessed: 2025-12-08
work page 2025
-
[26]
Reasoning curriculum: Bootstrapping broad llm reasoning from math, 2025
Bo Pang, Deqian Kong, Silvio Savarese, Caiming Xiong, and Yingbo Zhou. Reasoning curriculum: Bootstrapping broad llm reasoning from math.arXiv preprint arXiv:2510.26143, 2025
-
[27]
Less is more: Efficient model merging with binary task switch
Biqing Qi, Fangyuan Li, Zhen Wang, Junqi Gao, Dong Li, Peng Ye, and Bowen Zhou. Less is more: Efficient model merging with binary task switch. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15265–15274, 2025
work page 2025
-
[28]
Multi-task grpo: Reliable llm reasoning across tasks.arXiv preprint arXiv:2602.05547, 2026
Shyam Sundhar Ramesh, Xiaotong Ji, Matthieu Zimmer, Sangwoong Yoon, Zhiyong Wang, Haitham Bou Ammar, Aurelien Lucchi, and Ilija Bogunovic. Multi-task grpo: Reliable llm reasoning across tasks.arXiv preprint arXiv:2602.05547, 2026
-
[29]
Sera: Soft-verified efficient repository agents, 2026
Ethan Shen, Danny Tormoen, Saurabh Shah, Ali Farhadi, and Tim Dettmers. Sera: Soft-verified efficient repository agents.arXiv preprint arXiv:2601.20789, 2026
-
[30]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[31]
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu. Crossing the reward bridge: Expanding rl with verifiable rewards across diverse domains.arXiv preprint arXiv:2503.23829, 2025
-
[32]
Swe-world: Building software engineering agents in docker-free environments, 2026
Shuang Sun, Huatong Song, Lisheng Huang, Jinhao Jiang, Ran Le, Zhihao Lv, Zongchao Chen, Yiwen Hu, Wenyang Luo, Wayne Xin Zhao, et al. Swe-world: Building software engineering agents in docker-free environments.arXiv preprint arXiv:2602.03419, 2026
-
[33]
Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving, 2026
Chaofan Tao, Jierun Chen, Yuxin Jiang, Kaiqi Kou, Shaowei Wang, Ruoyu Wang, Xiaohui Li, Sidi Yang, Yiming Du, Jianbo Dai, et al. Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving.arXiv preprint arXiv:2601.01426, 2026. 11
-
[34]
Haoqing Wang, Xiang Long, Ziheng Li, Yilong Xu, Tingguang Li, and Yehui Tang. To mix or to merge: Toward multi-domain reinforcement learning for large language models.arXiv preprint arXiv:2602.12566, 2026
-
[35]
Swe-dev: Building software engineering agents with training and inference scaling
Haoran Wang, Zhenyu Hou, Yao Wei, Jie Tang, and Yuxiao Dong. Swe-dev: Building software engineering agents with training and inference scaling. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3742–3761, 2025
work page 2025
-
[36]
Junhao Wang, Daoguang Zan, Shulin Xin, Siyao Liu, Yurong Wu, and Kai Shen. Swe- mirror: Scaling issue-resolving datasets by mirroring issues across repositories.arXiv preprint arXiv:2509.08724, 2025
-
[37]
Training networks in null space of feature covariance for continual learning
Shipeng Wang, Xiaorong Li, Jian Sun, and Zongben Xu. Training networks in null space of feature covariance for continual learning. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 184–193, 2021
work page 2021
-
[38]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[39]
arXiv preprint arXiv:2601.12538 (2026)
Tianxin Wei, Ting-Wei Li, Zhining Liu, Xuying Ning, Ze Yang, Jiaru Zou, Zhichen Zeng, Ruizhong Qiu, Xiao Lin, Dongqi Fu, et al. Agentic reasoning for large language models.arXiv preprint arXiv:2601.12538, 2026
-
[40]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational conference on machine learning, pages 23965–23998. P...
work page 2022
-
[41]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
work page 2023
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Adamerging: Adaptive model merging for multi-task learning.arXiv preprint arXiv:2310.02575, 2023
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao. Adamerging: Adaptive model merging for multi-task learning.arXiv preprint arXiv:2310.02575, 2023
-
[44]
Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, Jie Zhang, and Dacheng Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportu- nities.ACM Computing Surveys, 58(8):1–41, 2026
work page 2026
-
[45]
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
-
[46]
Orthogonal model merging.arXiv preprint arXiv:2602.05943, 2026
Sihan Yang, Kexuan Shi, and Weiyang Liu. Orthogonal model merging.arXiv preprint arXiv:2602.05943, 2026
-
[47]
Kimi-dev: Agentless training as skill prior for swe-agents, 2025 c
Zonghan Yang, Shengjie Wang, Kelin Fu, Wenyang He, Weimin Xiong, Yibo Liu, Yibo Miao, Bofei Gao, Yejie Wang, Yingwei Ma, et al. Kimi-dev: Agentless training as skill prior for swe-agents.arXiv preprint arXiv:2509.23045, 2025
-
[48]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[49]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InForty-first International Conference on Machine Learning, 2024. 12
work page 2024
-
[50]
Unraveling lora interference: Orthogonal subspaces for robust model merging
Haobo Zhang and Jiayu Zhou. Unraveling lora interference: Orthogonal subspaces for robust model merging. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26459–26472, 2025
work page 2025
-
[51]
Shenghe Zheng, Hongzhi Wang, Chenyu Huang, Xiaohui Wang, Tao Chen, Jiayuan Fan, Shuyue Hu, and Peng Ye. Decouple and orthogonalize: A data-free framework for lora merging.arXiv preprint arXiv:2505.15875, 2025. 13 Appendix A Additional Experimental Details A.1 SWE-Bench Verified Evaluation Setup Evaluation Dataset.We primarily evaluate agentic reasoning on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.