Recognition: unknown
SWE-AGILE: A Software Agent Framework for Efficiently Managing Dynamic Reasoning Context
Pith reviewed 2026-05-10 15:06 UTC · model grok-4.3
The pith
SWE-AGILE solves the context dilemma in reasoning software agents by combining a sliding window of detailed steps with compressed historical digests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
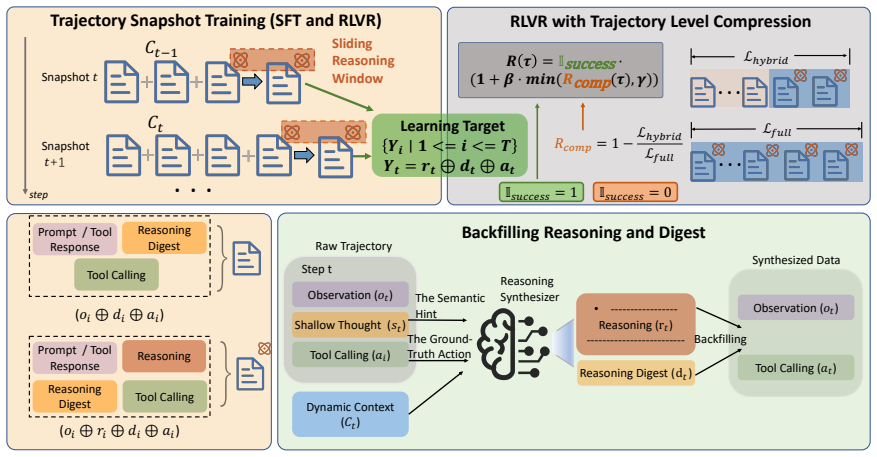
SWE-AGILE is a software agent framework that bridges reasoning depth and context constraints through a Dynamic Reasoning Context strategy. It keeps a sliding window of detailed reasoning for immediate continuity to avoid redundant re-analysis, while compressing prior reasoning into concise Reasoning Digests. This enables handling of complex edge cases in multi-turn software engineering without the lost-in-the-middle effect or context overflow.
What carries the argument
Dynamic Reasoning Context strategy: a combination of sliding-window detailed reasoning and compressed Reasoning Digests that maintains continuity and efficiency in agent decision-making.
If this is right
- Agents can process longer sequences of software engineering steps without context length limits degrading performance.
- Small models achieve high accuracy on verified benchmarks with far less training data than typical approaches.
- Reduces redundant computation by preserving key historical insights in digest form.
- Supports explicit System-2 style deep analysis in practical autonomous coding tasks.
Where Pith is reading between the lines
- The method may extend to other multi-step reasoning domains like automated theorem proving or scientific hypothesis generation where history compression is needed.
- One could test whether the digest compression ratio can be tuned dynamically based on task difficulty to further optimize performance.
- Applying similar strategies to larger language models might yield even greater gains by allowing more extensive reasoning chains.
Load-bearing premise
The compression of historical reasoning steps into concise digests retains every detail required to correctly resolve complex edge cases in subsequent steps of the task.
What would settle it
A direct comparison on SWE-Bench-Verified tasks with many turns and subtle interdependencies, measuring if full-history agents outperform the digest-based ones on edge-case resolution rates.
Figures




read the original abstract
Prior representative ReAct-style approaches in autonomous Software Engineering (SWE) typically lack the explicit System-2 reasoning required for deep analysis and handling complex edge cases. While recent reasoning models demonstrate the potential of extended Chain-of-Thought (CoT), applying them to the multi-turn SWE task creates a fundamental dilemma: retaining full reasoning history leads to context explosion and ``Lost-in-the-Middle'' degradation, while discarding it would force the agent to redundantly re-reason at every step. To address these challenges, we propose SWE-AGILE, a novel software agent framework designed to bridge the gap between reasoning depth, efficiency, and context constraints. SWE-AGILE introduces a Dynamic Reasoning Context strategy, maintaining a ``sliding window'' of detailed reasoning for immediate continuity to prevent redundant re-analyzing, while compressing historical reasoning content into concise Reasoning Digests. Empirically, SWE-AGILE sets a new standard for 7B-8B models on SWE-Bench-Verified using only 2.2k trajectories and 896 tasks. Code is available at https://github.com/KDEGroup/SWE-AGILE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-AGILE, a software agent framework for autonomous software engineering that addresses the context-explosion vs. redundant-reasoning tradeoff in multi-turn ReAct-style agents. It proposes a Dynamic Reasoning Context strategy that maintains a sliding window of detailed recent reasoning for continuity while compressing earlier history into concise Reasoning Digests. The central empirical claim is that this approach sets a new standard for 7B-8B models on SWE-Bench-Verified when trained on only 2.2k trajectories and evaluated across 896 tasks, with code released at a GitHub repository.
Significance. If the empirical results hold with proper controls, the work could meaningfully advance practical context management for long-horizon agentic systems in software engineering, where retaining reasoning depth without prohibitive token costs is a recurring bottleneck. The open release of code is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and abstract: the claim that SWE-AGILE 'sets a new standard' for 7B-8B models is unsupported because no performance numbers, baseline comparisons (e.g., vanilla ReAct, other CoT variants), error bars, or statistical tests are provided, nor is the exact evaluation protocol on SWE-Bench-Verified described. This directly undermines the central empirical contribution.
- [§3.2 (Reasoning Digests)] §3.2 (Reasoning Digests): the compression procedure is not specified (model used, prompt template, length target, or any information-loss metric), yet the framework's correctness rests on the assumption that digests preserve all information needed for complex edge cases. Without this, the 'no performance loss' claim cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: the phrase 'using only 2.2k trajectories and 896 tasks' is ambiguous—clarify whether 896 refers to training tasks, evaluation tasks, or the full benchmark size.
- [§1 (Introduction)] Notation: 'ReAct' and 'CoT' appear without first-use definitions, although they are standard; a brief parenthetical expansion would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important gaps in the presentation of our empirical results and methodological details. We will revise the manuscript to strengthen these sections while preserving the core contributions of the Dynamic Reasoning Context approach.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and abstract: the claim that SWE-AGILE 'sets a new standard' for 7B-8B models is unsupported because no performance numbers, baseline comparisons (e.g., vanilla ReAct, other CoT variants), error bars, or statistical tests are provided, nor is the exact evaluation protocol on SWE-Bench-Verified described. This directly undermines the central empirical contribution.
Authors: We acknowledge that the current manuscript version presents the 'new standard' claim in the abstract and §4 without accompanying numerical results, baseline comparisons, error bars, statistical tests, or a full description of the evaluation protocol. This omission weakens the central empirical claim. In the revised manuscript, we will expand §4 with a detailed results table reporting exact performance metrics on SWE-Bench-Verified (including the success rate for the 7B-8B models), direct comparisons to vanilla ReAct and other CoT variants, any available variance measures or error bars, and a precise account of the evaluation protocol, including selection of the 896 tasks and training details on the 2.2k trajectories. These additions will provide the necessary evidence to support the claim. revision: yes
-
Referee: [§3.2 (Reasoning Digests)] §3.2 (Reasoning Digests): the compression procedure is not specified (model used, prompt template, length target, or any information-loss metric), yet the framework's correctness rests on the assumption that digests preserve all information needed for complex edge cases. Without this, the 'no performance loss' claim cannot be evaluated.
Authors: We agree that §3.2 does not adequately specify the Reasoning Digest compression procedure, including the model used, prompt template, target length, or information-loss metrics. This limits evaluation of the assumption that digests preserve critical information for edge cases. In the revision, we will detail the compression process by specifying the model (e.g., the base 7B-8B model), the full prompt template, the target digest length or compression ratio, and any validation metrics such as manual review of information retention or ablation experiments demonstrating maintained performance on complex scenarios. This will clarify how the sliding window and digests together avoid performance loss. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents SWE-AGILE as an empirical framework for managing dynamic reasoning context in software engineering agents via a sliding window of detailed reasoning combined with compressed Reasoning Digests. No equations, derivations, fitted parameters, or mathematical claims are present in the provided text. The core contribution is a practical strategy addressing context explosion versus redundant re-reasoning, evaluated directly on the SWE-Bench-Verified benchmark using a fixed number of trajectories and tasks. The argument relies on standard empirical comparison rather than any self-referential definitions, self-citation chains, or reductions of predictions to inputs by construction. This makes the derivation chain self-contained with no detectable circular steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
HCRE: LLM-based Hierarchical Classification for Cross-Document Relation Extraction with a Prediction-then-Verification Strategy
HCRE improves cross-document relation extraction by having LLMs classify relations level-by-level down a tree structure while verifying predictions at each step to reduce errors.
-
M2A: Synergizing Mathematical and Agentic Reasoning in Large Language Models
M2A uses null-space model merging to combine mathematical and agentic reasoning in LLMs, raising SWE-Bench Verified performance from 44.0% to 51.2% on Qwen3-8B without retraining.
Reference graph
Works this paper leans on
-
[1]
Training language models to reason efficiently.ArXiv, abs/2502.04463, 2025
Swe-search: Enhancing software agents with monte carlo tree search and iterative refine- ment.ICLR. https://openreview.net/forum? id=G7sIFXugTX. Daman Arora and Andrea Zanette. 2025. Training lan- guage models to reason efficiently.arXiv Preprint. https://arxiv.org/abs/2502.04463. Shiyi Cao, Sumanth Hegde, Dacheng Li, Tyler Griggs, and et al. 2025. Skyrl-...
-
[2]
Ui-agile: Advancing gui agents with effective reinforcement learning and precise inference-time grounding.Preprint, arXiv:2507.22025. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Trans. Assoc. Comput. Linguistics, 12:157–173. H...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. 2025. Training software engineering agents and verifiers with swe-gym. InICML. Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, and et al. 2025. UI-TARS: pioneering automated GUI interaction w...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Direct preference optimization: Your language model is secretly a reward model. InNeurIPS. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, and et al. 2024. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv Preprint. https://arxiv. org/abs/2402.03300. Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Beyond turn limits: Training deep search agents with dynamic context window.Preprint, arXiv:2510.08276. Hongyuan Tao, Ying Zhang, Zhenhao Tang, Hongen Peng, Xukun Zhu, Bingchang Liu, Yingguang Yang, Ziyin Zhang, Zhaogui Xu, Haipeng Zhang, Linchao Zhu, Rui Wang, Hang Yu, Jianguo Li, and Peng Di
-
[6]
Code graph model (CGM): A graph-integrated large language model for repository-level software engineering tasks.arXiv Preprint. https://arxiv. org/abs/2505.16901. MiroMind Team, S. Bai, L. Bing, L. Lei, R. Li, X. Li, X. Lin, and et al. 2026. Mirothinker-1.7 & h1: To- wards heavy-duty research agents via verification. Preprint, arXiv:2603.15726. Haoran Wan...
-
[7]
SWE-RL: advancing LLM reasoning via re- inforcement learning on open software evolution. arXiv Preprint. https://arxiv.org/abs/2502. 18449. Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025a. Demystifying llm-based software engineering agents.Proc. ACM Softw. Eng., 2(FSE):801–824. Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and...
-
[8]
Agentfold: Long-horizon web agents with proactive context management.arXiv Preprint. https://arxiv.org/abs/2510.24699. Jiahao Yu, Zelei Cheng, Xian Wu, and Xinyu Xing. 2025a. Building coding agents via entropy-enhanced multi-turn preference optimization.arXiv Preprint. https://arxiv.org/abs/2509.12434. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- ...
-
[9]
Adaptive Reasoning Depth
search tool, although using the bash tool can basically achieve the same effect of a search tool. Therefore, we further collect about 200 trajectories on tasks from R2E-Gym using the four tools to supplement SFT data. The detailed prompts are provided in Fig. 4 and Fig. 5. B Detailed Hyperparameters Tabs. 3 and 4 provide more detailed hyperparame- ters. C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.