Recognition: 1 theorem link
· Lean TheoremDissecting Jet-Tagger Through Mechanistic Interpretability
Pith reviewed 2026-05-12 04:45 UTC · model grok-4.3
The pith
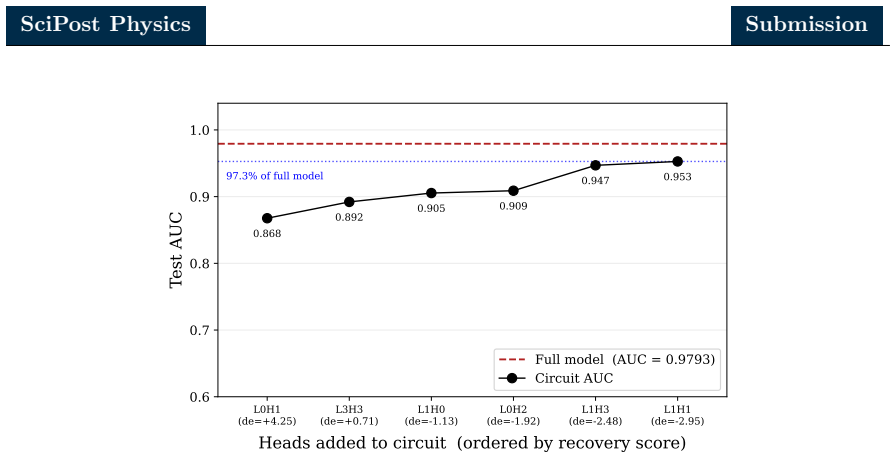
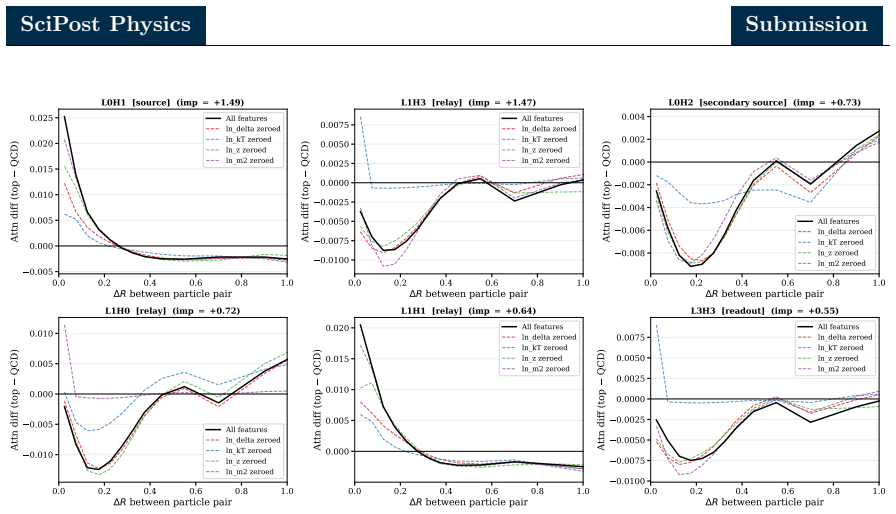
A six-head circuit in a particle transformer recovers most top-quark jet tagging performance through a source-relay-readout structure aligned with energy correlators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
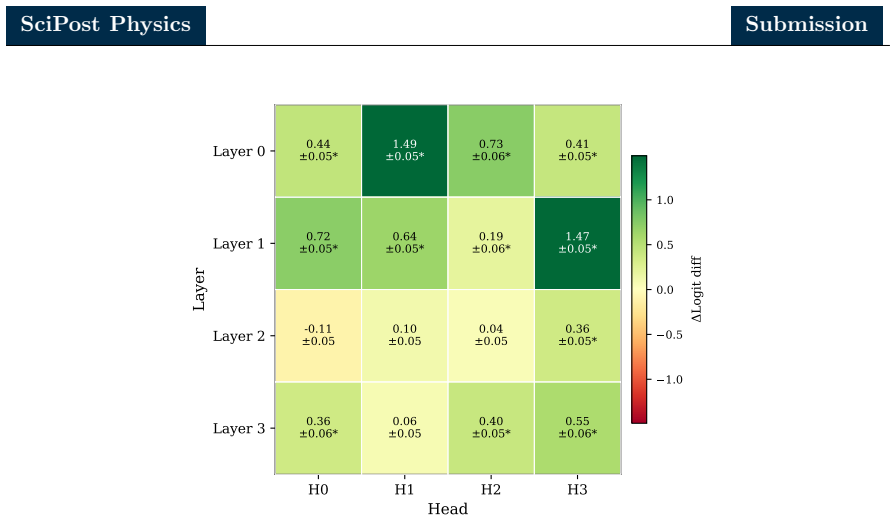
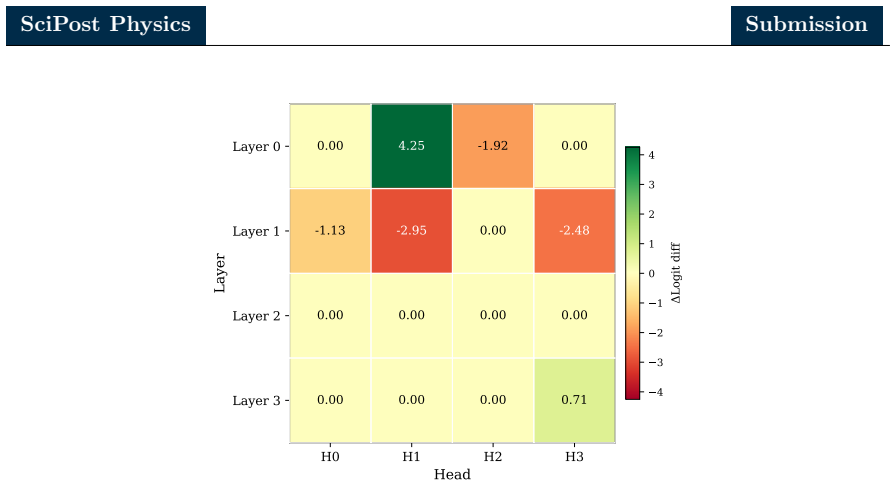
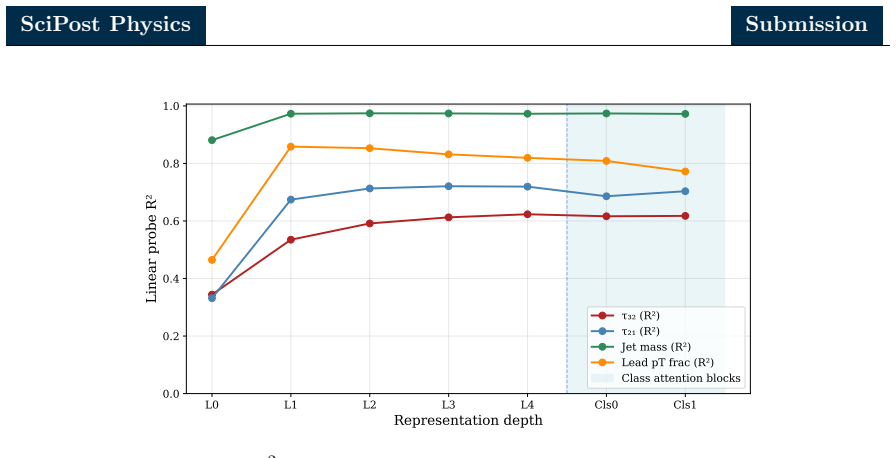
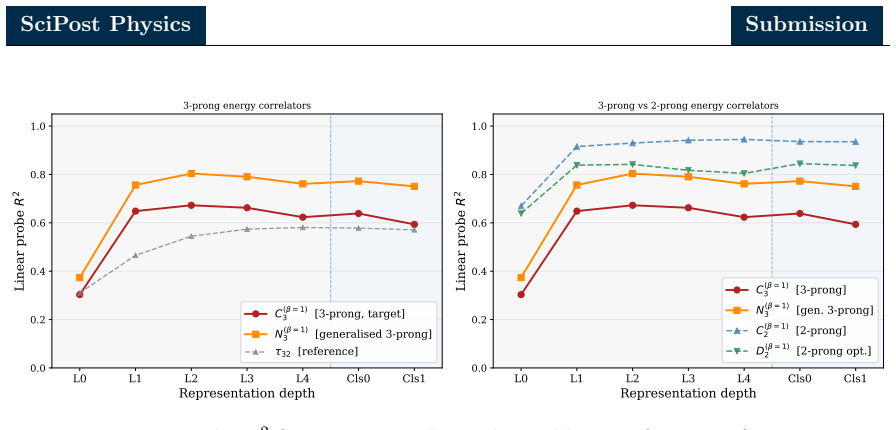
Combining zero ablation, path patching with two complementary on-manifold corruption strategies, and linear probing of the residual stream, the authors identify a sparse six-head circuit that recovers the great majority of the full model performance while admitting a clean source-relay-readout interpretation. In this circuit a single early-layer head serves as the primary causal source, a cluster of middle-layer heads acts as relays selectively attending to hard pairwise substructure, and a single late-layer head reads out the aggregated signal. Linear probes show that the residual stream is preferentially aligned with the energy correlator basis over the N-subjettiness basis, with stronger
What carries the argument
The sparse six-head circuit recovered by zero ablation and path patching, which implements source-relay-readout flow and aligns the residual stream with energy correlator observables.
If this is right
- The bulk of the classification decision can be explained by a small, human-readable subgraph rather than the full network.
- The internal representations encode two-prong jet substructure observables drawn from the energy correlator family.
- The model performs an internal basis rotation early in the network rather than committing to a classification in a single step.
- Gradient descent applied to jet data can rediscover physically meaningful structures without explicit supervision.
- Mechanistic interpretability methods developed for language models transfer directly to jet-physics classifiers.
Where Pith is reading between the lines
- The discovered circuit could be used as a starting point for constructing lighter, more verifiable jet taggers that implement the same logic explicitly.
- The preference for energy correlators suggests the model exploits QCD symmetries that might be missed by architectures trained only on N-subjettiness variables.
- Repeating the analysis on other tagging datasets or architectures would test whether different training regimes produce different circuits or the same energy-correlator alignment.
Load-bearing premise
The chosen on-manifold corruption strategies and zero-ablation interventions isolate the true causal circuit without introducing new artifacts that the model was never trained to handle.
What would settle it
Ablating every head outside the six identified ones and checking whether the performance drop is as small as claimed, or running linear probes and verifying that alignment with energy correlator features exceeds alignment with N-subjettiness features.
Figures






read the original abstract
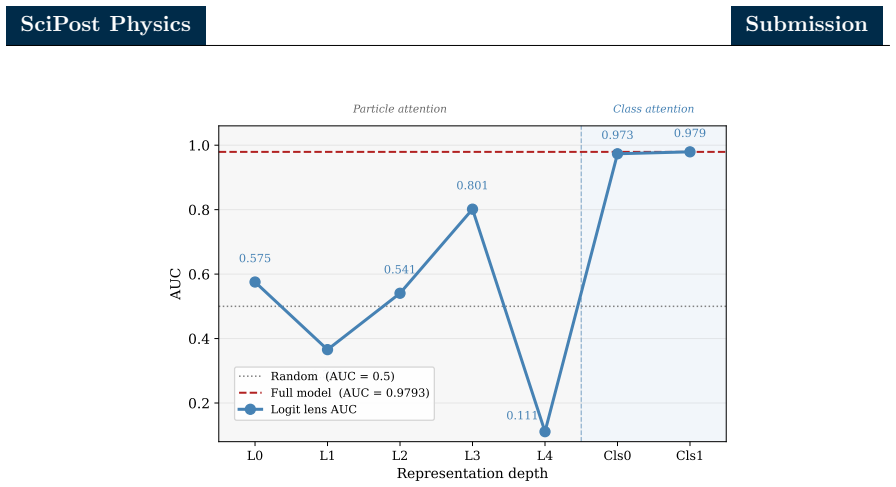
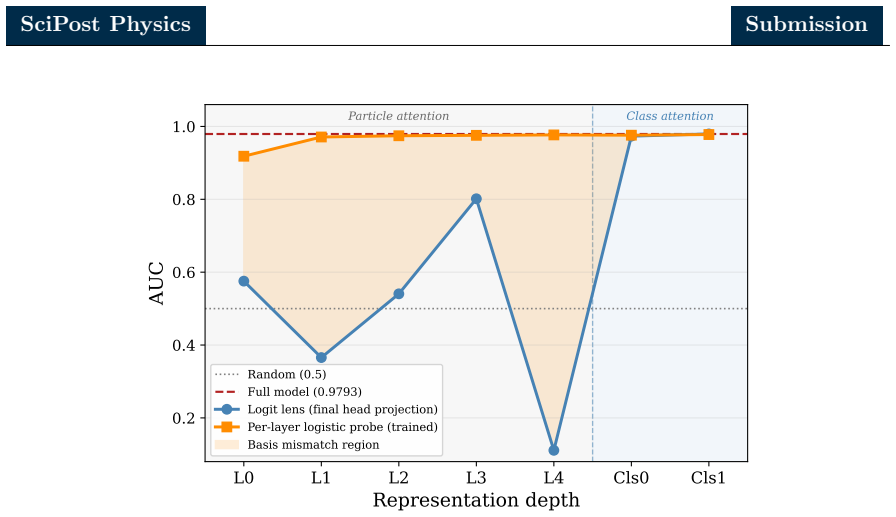
Mechanistic interpretability seeks to reverse engineer a trained neural network by identifying the minimal subset of internal components. We perform a mechanistic interpretability analysis of the Particle Transformer architecture, trained on the Top Quark Tagging reference dataset, with the goal of identifying the computational circuit responsible for jet classification and characterizing the physical content of its internal representations. Combining zero ablation, path patching with two complementary on-manifold corruption strategies and linear probing of the residual stream, we identify a sparse six-head circuit that recovers the great majority of the full model performance while admitting a clean source-relay-readout interpretation. In this circuit, a single early layer head serves as the primary causal source, a cluster of middle-layer heads acts as relays selectively attending to hard pairwise substructure and a single late-layer head reads out the aggregated signal. Linear probes show that the residual stream is preferentially aligned with the energy correlator basis over the $N$-subjettiness basis. Within the energy correlator basis, the model preferentially encodes 2-prong substructure observables over the 3-prong observables. A per-layer trained probe further reveals that the apparent single step commitment of the model to a classification decision in the first class attention block is in fact a basis rotation, with the discriminating signal already saturating in the particle attention stack. These results demonstrate that mechanistic interpretability methods developed for natural language models can be used for jet physics classifiers and indicate that gradient descent may rediscover physically meaningful aspects of jet tagging without supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies mechanistic interpretability methods (zero ablation, path patching with two on-manifold corruption strategies, and linear probing of the residual stream) to a Particle Transformer trained on the Top Quark Tagging dataset. It identifies a sparse six-head circuit—an early source head, middle-layer relay heads attending to pairwise substructure, and a late readout head—that recovers the great majority of the full model's jet classification performance. Linear probes indicate that the residual stream preferentially encodes energy-correlator observables (especially 2-prong substructure) over N-subjettiness, and that an apparent early commitment to classification is actually a basis rotation already saturated in the particle attention stack.
Significance. If the circuit identification and causal interventions hold, the work demonstrates that standard MI techniques transfer successfully to high-energy physics classifiers and that gradient descent can rediscover physically meaningful jet substructure features without supervision. The quantitative performance recovery, clean source-relay-readout decomposition, and explicit comparison of probe bases constitute concrete strengths; the absence of fitted parameters or invented entities in the analysis further supports its empirical grounding.
major comments (2)
- [§4.2] §4.2 (path patching): the two on-manifold corruption strategies are described as complementary, but the manuscript does not state whether they were pre-specified before any ablation runs or selected after observing initial results; post-hoc choice would weaken the claim that the recovered six-head circuit is the minimal faithful one.
- [§5.1] §5.1 and Table 3: the linear-probe results claim preferential alignment with the energy-correlator basis, yet the probe training details (regularization, number of dimensions retained, and random baseline accuracy) are not reported, so it is impossible to judge whether the reported preference exceeds what would be expected from the residual-stream dimensionality alone.
minor comments (3)
- [Abstract] Abstract: the phrase 'great majority of the full model performance' should be replaced by the exact recovered fraction (e.g., 87 % top-tagging accuracy) for precision.
- [Figure 4] Figure 4 caption: the color scale for attention maps is not labeled with numerical values, making it difficult to compare attention strengths across heads.
- [§3.1] §3.1: the Particle Transformer architecture diagram omits the exact number of heads per layer and the residual-stream dimension, which are needed to interpret the six-head circuit size.
Simulated Author's Rebuttal
We thank the referee for their thorough review and positive recommendation for minor revision. We address the two major comments below and will incorporate clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (path patching): the two on-manifold corruption strategies are described as complementary, but the manuscript does not state whether they were pre-specified before any ablation runs or selected after observing initial results; post-hoc choice would weaken the claim that the recovered six-head circuit is the minimal faithful one.
Authors: The two on-manifold corruption strategies were pre-specified prior to performing the ablation runs. They were chosen to be complementary in probing the circuit's dependence on different aspects of the input distribution. We will revise §4.2 to state this explicitly and thereby strengthen the claim that the six-head circuit is the minimal faithful one. revision: yes
-
Referee: [§5.1] §5.1 and Table 3: the linear-probe results claim preferential alignment with the energy-correlator basis, yet the probe training details (regularization, number of dimensions retained, and random baseline accuracy) are not reported, so it is impossible to judge whether the reported preference exceeds what would be expected from the residual-stream dimensionality alone.
Authors: We agree that these details are essential for evaluating the probe results. We will add to §5.1 and Table 3 the regularization method and strength used for training the linear probes, the number of dimensions retained from the residual stream, and the random baseline accuracy. This will allow readers to confirm that the observed preference for the energy-correlator basis exceeds what would be expected from dimensionality considerations alone. revision: yes
Circularity Check
No circularity: purely empirical circuit identification via interventions
full rationale
The paper's central results rest on zero ablation, path patching, and linear probing applied to a pre-trained Particle Transformer on the external Top Quark Tagging dataset. These are interventional measurements that quantify causal contributions; the recovered six-head circuit and its source-relay-readout interpretation are outputs of those measurements rather than inputs redefined as predictions. No equations derive a quantity from itself, no fitted parameters are relabeled as predictions, and no load-bearing claims reduce to self-citations or imported uniqueness theorems. The analysis is self-contained against the held-out test set and standard interpretability benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Interventional methods such as zero ablation and path patching isolate the causal contributions of individual attention heads without creating out-of-distribution artifacts that the model exploits.
- domain assumption Linear probes trained on the residual stream accurately measure the presence of physical observables such as energy correlators.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearCombining zero ablation, path patching with two complementary on-manifold corruption strategies and linear probing of the residual stream, we identify a sparse six-head circuit...
Reference graph
Works this paper leans on
-
[1]
G. P. Salam,Towards Jetography, Eur. Phys. J. C67, 637 (2010), doi:10.1140/epjc/s10052- 010-1314-6,0906.1833
-
[2]
Kogleret al.,Jet Substructure at the Large Hadron Collider: Experimental Review, Rev
R. Kogleret al.,Jet Substructure at the Large Hadron Collider: Experimental Review, Rev. Mod. Phys.91(4), 045003 (2019), doi:10.1103/RevModPhys.91.045003, 1803.06991
-
[3]
A. J. Larkoski, I. Moult and B. Nachman,Jet substructure at the large hadron collider: A review of recent advances in theory and machine learning, Physics Reports841, 1 (2020), doi:https://doi.org/10.1016/j.physrep.2019.11.001, Jet substructure at the Large Hadron Collider: A review of recent advances in theory and machine learning
-
[4]
L. de Oliveira, M. Kagan, L. Mackey, B. Nachman and A. Schwartzman,Jet-images — deep learning edition, JHEP07, 069 (2016), doi:10.1007/JHEP07(2016)069, 1511.05190
-
[5]
H. Qu and L. Gouskos,ParticleNet: Jet Tagging via Particle Clouds, Phys. Rev. D 101(5), 056019 (2020), doi:10.1103/PhysRevD.101.056019,1902.08570
- [6]
-
[7]
J. Shlomi, P. Battaglia and J.-R. Vlimant,Graph Neural Networks in Particle Physics (2020), doi:10.1088/2632-2153/abbf9a,2007.13681
- [8]
-
[9]
J. Thaler and K. Van Tilburg,Identifying Boosted Objects with N-subjettiness, JHEP03, 015 (2011), doi:10.1007/JHEP03(2011)015,1011.2268
-
[10]
J. Thaler and K. Van Tilburg,Maximizing Boosted Top Identification by Minimizing N-subjettiness, JHEP02, 093 (2012), doi:10.1007/JHEP02(2012)093,1108.2701
-
[11]
A. J. Larkoski, G. P. Salam and J. Thaler,Energy Correlation Functions for Jet Substructure, JHEP06, 108 (2013), doi:10.1007/JHEP06(2013)108,1305.0007
-
[12]
I. Moult, L. Necib and J. Thaler,New Angles on Energy Correlation Functions, JHEP 12, 153 (2016), doi:10.1007/JHEP12(2016)153,1609.07483
-
[13]
A. Butteret al.,The Machine Learning landscape of top taggers, SciPost Phys.7, 014 (2019), doi:10.21468/SciPostPhys.7.1.014,1902.09914
-
[14]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser and I. Polosukhin,Attention Is All You Need, arXiv e-prints arXiv:1706.03762 (2017), doi:10.48550/arXiv.1706.03762,1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
- [15]
-
[16]
K. Wang, A. Variengien, A. Conmy, B. Shlegeris and J. Steinhardt,Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small, arXiv e-prints arXiv:2211.00593 (2022), doi:10.48550/arXiv.2211.00593,2211.00593
work page internal anchor Pith review doi:10.48550/arxiv.2211.00593 2022
-
[17]
A. Conmy, A. N. Mavor-Parker, A. Lynch, S. Heimersheim and A. Garriga-Alonso, Towards Automated Circuit Discovery for Mechanistic Interpretability, arXiv e-prints arXiv:2304.14997 (2023), doi:10.48550/arXiv.2304.14997,2304.14997
-
[18]
G. Kasieczka, T. Plehn, J. Thompson and M. Russel,Top quark tagging reference dataset, doi:10.5281/zenodo.2603256 (2019)
-
[19]
G. Agarwal, L. Hay, I. Iashvili, B. Mannix, C. McLean, M. Morris, S. Rappoccio and U. Schubert,Explainable AI for ML jet taggers using expert variables and layerwise relevance propagation, JHEP05, 208 (2021), doi:10.1007/JHEP05(2021)208, 2011.13466
-
[21]
B. Bhattacherjee, C. Bose, A. Chakraborty and R. Sengupta,Boosted top tagging and its interpretation using Shapley values, Eur. Phys. J. Plus139(12), 1131 (2024), doi:10.1140/epjp/s13360-024-05910-9,2212.11606
-
[22]
P. D. Patel and S. Ganguly,Explainable AI for Jet Tagging: A Comparative Study of GNNExplainer, GNNShap, and GradCAM for Jet Tagging in the Lund Jet Plane(2026), 2604.25885
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
F. Mokhtar, R. Kansal, D. Diaz, J. Duarte, J. Pata, M. Pierini and J.-R. Vlimant, Explaining machine-learned particle-flow reconstruction, In35th Conference on Neural Information Processing Systems(2021),2111.12840
-
[24]
L. Maglianella, L. Nicoletti, S. Giagu, C. Napoli and S. Scardapane,Convergent approaches to AI explainability for HEP muonic particles pattern recognition, Computing and Software for Big Science7(1), 8 (2023), doi:10.1007/s41781-023-00102-z
-
[25]
A. Khot, X. Wang, A. Roy, V. Kindratenko and M. S. Neubauer,Evidential deep learning for uncertainty quantification and out-of-distribution detection in jet identification using deep neural networks, Mach. Learn. Sci. Tech.6(3), 035003 (2025), doi:10.1088/2632- 2153/ade51b,2501.05656
-
[26]
F. Mokhtar, R. Kansal and J. Duarte,Do graph neural networks learn traditional jet substructure?, In36th Conference on Neural Information Processing Systems: Workshop on Machine Learning and the Physical Sciences(2022),2211.09912
-
[27]
A. Andreassen, I. Feige, C. Frye and M. D. Schwartz,Binary JUNIPR: an inter- pretable probabilistic model for discrimination, Phys. Rev. Lett.123(18), 182001 (2019), doi:10.1103/PhysRevLett.123.182001,1906.10137
-
[28]
J. Bendavid, D. Conde, M. Morales-Alvarado, V. Sanz and M. Ubiali,Angular coefficients from interpretable machine learning with symbolic regression, JHEP02, 081 (2026), doi:10.1007/JHEP02(2026)081,2508.00989. 38 SciPost Physics Submission
-
[29]
P. Konar, V. S. Ngairangbam, M. Spannowsky and D. Srivastava,Stable and inter- pretable jet physics with IRC-safe equivariant feature extraction, JHEP03, 219 (2026), doi:10.1007/JHEP03(2026)219,2509.22059
-
[30]
L. Bradshaw, S. Chang and B. Ostdiek,Creating simple, interpretable anomaly de- tectors for new physics in jet substructure, Phys. Rev. D106(3), 035014 (2022), doi:10.1103/PhysRevD.106.035014,2203.01343
-
[31]
D. Genovese, A. Sgroi, A. Devoto, S. Valentine, L. Wood, C. Sebastiani, S. Scardapane, M. D’Onofrio and S. Giagu,Mixture-of-experts graph transformers for interpretable particle collision detection, Sci. Rep.15(1), 27906 (2025), doi:10.1038/s41598-025-12003-9, 2501.03432
-
[32]
S. Vent, R. Winterhalder and T. Plehn,The Physics Behind ML-based Quark-Gluon Taggers, SciPost Phys.20, 084 (2026), doi:10.21468/SciPostPhys.20.3.084,2507.21214
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21468/scipostphys.20.3.084 2026
-
[33]
IAFormer: Interaction-Aware Transformer network for collider data analysis
W. Esmail, A. Hammad and M. Nojiri,IAFormer: Interaction-Aware Trans- former network for collider data analysis, SciPost Phys.20(4), 108 (2026), doi:10.21468/SciPostPhys.20.4.108,2505.03258
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21468/scipostphys.20.4.108 2026
- [34]
-
[35]
T. Legge, A. Wang, J. Ortiz, V. Limouzi, Z. Zhao, A. Gandrakota, E. E. Khoda, J. Nga- diuba, J. Duarte and R. Cavanaugh,Why Is Attention Sparse In Particle Transformer?, In39th Annual Conference on Neural Information Processing Systems: Includes Machine Learning and the Physical Sciences (ML4PS)(2025),2512.00210
-
[36]
What exactly did the Transformer learn from our physics data?
M. Erdmann, N. Langner, J. Schulte and D. Wirtz,What Exactly Did the Trans- former Learn from Our Physics Data?, Comput. Softw. Big Sci.9(1), 16 (2025), doi:10.1007/s41781-025-00145-4,2505.21042
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s41781-025-00145-4 2025
-
[37]
nostalgebraist,interpreting GPT: the logit lens, LessWrong (2020)
work page 2020
-
[38]
Understanding intermediate layers using linear classifier probes
G. Alain and Y. Bengio,Understanding intermediate layers using linear classifier probes, arXiv e-prints arXiv:1610.01644 (2016), doi:10.48550/arXiv.1610.01644,1610.01644
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.01644 2016
-
[39]
W. N. van Wieringen,Lecture notes on ridge regression, arXiv e-prints arXiv:1509.09169 (2015), doi:10.48550/arXiv.1509.09169,1509.09169
-
[40]
A comprehensive guide to the physics and usage of PYTHIA 8.3
C. Bierlichet al.,A comprehensive guide to the physics and usage of PYTHIA 8.3, SciPost Phys. Codeb.2022, 8 (2022), doi:10.21468/SciPostPhysCodeb.8,2203.11601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21468/scipostphyscodeb.8 2022
-
[41]
M. Cacciari, G. P. Salam and G. Soyez,The anti- kt jet clustering algorithm, JHEP04, 063 (2008), doi:10.1088/1126-6708/2008/04/063,0802.1189
-
[42]
M. Cacciari, G. P. Salam and G. Soyez,FastJet User Manual, Eur. Phys. J. C72, 1896 (2012), doi:10.1140/epjc/s10052-012-1896-2,1111.6097
-
[43]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter,Decoupled Weight Decay Regularization, arXiv e-prints arXiv:1711.05101 (2017), doi:10.48550/arXiv.1711.05101,1711.05101. 39 SciPost Physics Submission
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2017
-
[44]
Normformer: Improved transformer pretraining with extra normalization
S. Shleifer, J. Weston and M. Ott,NormFormer: Improved Transformer Pretraining with Extra Normalization, arXiv e-prints arXiv:2110.09456 (2021), doi:10.48550/arXiv.2110.09456,2110.09456
-
[45]
A. J. Larkoski, I. Moult and D. Neill,Power Counting to Better Jet Observables, JHEP 12, 009 (2014), doi:10.1007/JHEP12(2014)009,1409.6298
-
[46]
A. J. Larkoski, I. Moult and D. Neill,Analytic Boosted Boson Discrimination, JHEP05, 117 (2016), doi:10.1007/JHEP05(2016)117,1507.03018
-
[47]
C. R. Harris, K. J. Millman, S. J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picuset al.,Array programming with NumPy, Nature585(7825), 357 (2020), doi:10.1038/s41586-020-2649-2
-
[48]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit and N. Houlsby,An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, arXiv e-prints arXiv:2010.11929 (2020), doi:10.48550/arXiv.2010.11929,2010.11929. 40
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.