Recognition: no theorem link
Network-Efficient World Model Token Streaming
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
An adaptive keyframe-delta protocol for streaming discrete world model tokens reduces embedding distortion and next-token perplexity over periodic baselines at matched bitrates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
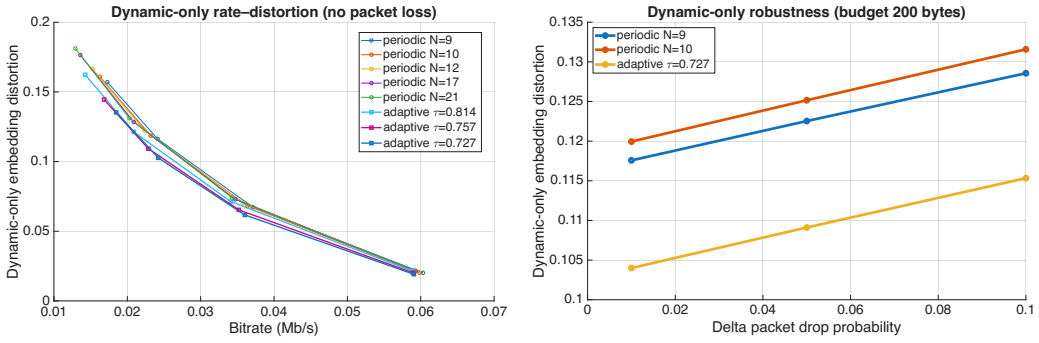
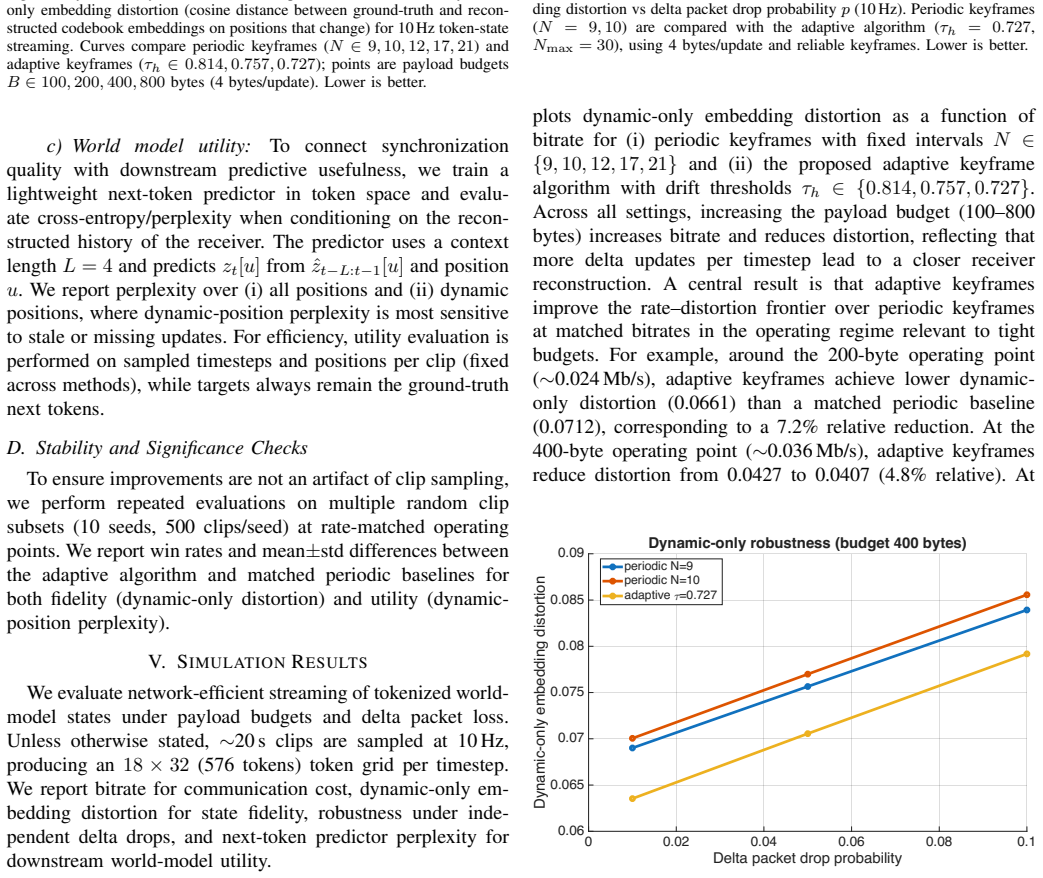
A fully online, label-free algorithm prioritizes delta updates via cosine distance in codebook embedding space and triggers keyframes adaptively using a Hamming-drift threshold. This policy improves the rate-distortion frontier over periodic keyframes at matched bitrates, dropping dynamic-only embedding distortion from 0.0712 to 0.0661 at 0.024 Mb/s and from 0.0427 to 0.0407 at 0.036 Mb/s. Under 10 percent delta packet loss at 200 bytes the distortion remains lower than the periodic baseline. The same policy also lowers next-token perplexity from 206.0 to 193.1 at the lower rate and from 158.9 to 155.6 at the higher rate when a lightweight predictor is conditioned on the streamed receiver s
What carries the argument
The online, label-free keyframe-delta scheduler that ranks token changes by cosine distance inside the fixed VQ codebook embedding space and inserts keyframes when Hamming drift on token IDs exceeds a threshold.
If this is right
- At 0.024 Mb/s the adaptive policy yields 7.2 percent lower embedding distortion than periodic keyframes at the same byte budget.
- At 0.036 Mb/s the same policy yields 4.8 percent lower embedding distortion.
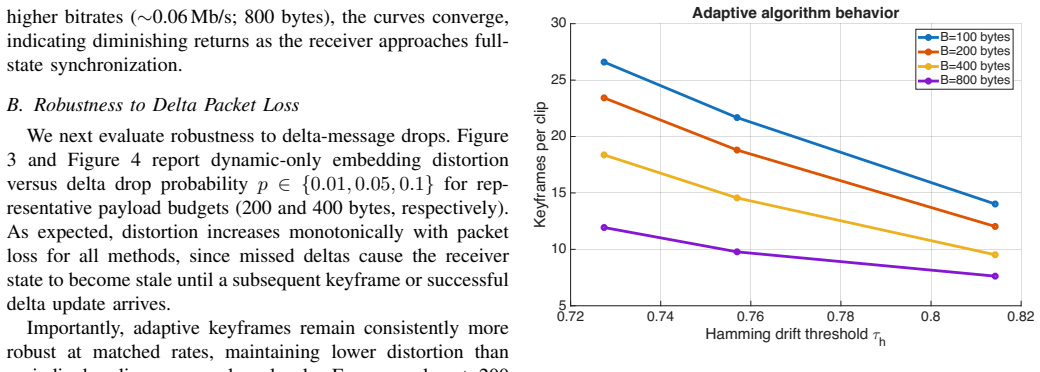
- Under 10 percent packet loss the adaptive stream still shows lower distortion than the periodic baseline at 200-byte messages.
- Next-token perplexity on the receiver side improves by 6.3 percent at the lower bitrate and 2.1 percent at the higher bitrate.
Where Pith is reading between the lines
- The same prioritization logic could be applied to other discrete latent streams such as tokenized video or LiDAR representations.
- The method supplies a practical systems layer that lets multiple vehicles or edge nodes maintain a shared world model under realistic wireless constraints.
- If the proxy metrics track real planning performance, the approach opens a path to bandwidth-aware multi-agent world-model synchronization.
Load-bearing premise
Cosine distance in the fixed codebook embedding space and Hamming drift on token IDs are sufficient proxies for which updates preserve downstream world-model utility.
What would settle it
A direct comparison of driving-task metrics such as trajectory prediction error when the adaptive stream and a matched periodic stream are each fed to the same world model over an emulated lossy vehicular channel.
Figures


read the original abstract
Generative driving world models rely on compact latent state representations that must be efficiently transmitted and synchronized across distributed compute and connected vehicles. We study network-efficient streaming of a discrete world model state, where a stride-16 VQ-U-Net tokenizer (codebook size 8,192) maps each 288x512 frame to an 18x32 grid of token IDs (576 tokens/frame), equivalent to 936 bytes/frame under fixed-length coding. We consider a keyframe--delta protocol under strict per-message payload budgets and packet loss, and propose a fully online, label-free algorithm that prioritizes delta updates via cosine distance in codebook embedding space and triggers keyframes adaptively using a Hamming-drift threshold. The adaptive algorithm consistently improves the rate distortion frontier over periodic keyframes at matched bitrates: at 0.024 Mb/s (200-byte budget) dynamic-only embedding distortion drops from 0.0712 to 0.0661 (7.2\%), and at 0.036 Mb/s (400-byte budget) from 0.0427 to 0.0407 (4.8\%). Under 10\% delta packet loss at 200 bytes, dynamic-only distortion is 0.0757 versus 0.0789 for a matched periodic baseline. To connect state fidelity to world model usefulness, we train a lightweight next-token predictor and evaluate perplexity conditioned on streamed receiver states: at 0.024 Mb/s, dynamic-position perplexity improves from 206.0 to 193.1 (6.3\%), and at 0.036 Mb/s from 158.9 to 155.6 (2.1\%). These results support discrete token-state streaming as a practical systems layer for bandwidth-aware synchronization and improved downstream token-dynamics utility under vehicular networking constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive keyframe-delta streaming protocol for discrete token representations of driving world models. Using a stride-16 VQ-U-Net tokenizer producing 18x32 token grids, it introduces a label-free online algorithm that prioritizes delta updates based on cosine distance in the codebook embedding space and triggers keyframes via a Hamming-drift threshold on token IDs. Under fixed payload budgets and packet loss, it reports improvements in embedding distortion (4.8-7.2%) and next-token predictor perplexity (2.1-6.3%) compared to periodic keyframe baselines at matched bitrates.
Significance. If the central empirical claims hold after additional validation, the work provides a practical contribution to bandwidth-aware synchronization of generative world models for connected vehicles. The fully online and label-free design, together with the explicit evaluation of downstream next-token perplexity, strengthens the systems relevance. The moderate soundness of the current evidence, however, means the significance is promising but not yet definitive.
major comments (3)
- Evaluation section: The reported gains (distortion from 0.0712 to 0.0661 at 0.024 Mb/s; perplexity from 206.0 to 193.1) are presented without dataset size, number of sequences, run-to-run variance, or statistical significance tests, which is load-bearing for interpreting the 4.8-7.2% improvements as reliable.
- Method section: The central adaptive mechanism relies on cosine distance in the fixed VQ codebook and a Hamming-drift threshold as proxies for delta prioritization and keyframe insertion; the manuscript provides no ablation or correlation analysis showing these proxies align with actual reconstruction error or next-token prediction loss, leaving open the possibility that the gains are artifacts of the chosen metrics rather than genuine rate-distortion improvement.
- Experiments section: Periodic baseline implementations are not fully specified (exact keyframe interval selection under identical payload budgets and loss rates), and no comparison to alternative prioritization strategies (e.g., predictor-loss-based) is included, which directly affects the claim of consistent improvement over periodic methods.
minor comments (2)
- Abstract: Terms such as 'dynamic-only embedding distortion' and 'dynamic-position perplexity' are used without a brief inline definition, which may confuse readers before the method section.
- Notation: The conversion from 576 tokens to 936 bytes per frame under fixed-length coding is stated but would benefit from an explicit equation or calculation for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: Evaluation section: The reported gains (distortion from 0.0712 to 0.0661 at 0.024 Mb/s; perplexity from 206.0 to 193.1) are presented without dataset size, number of sequences, run-to-run variance, or statistical significance tests, which is load-bearing for interpreting the 4.8-7.2% improvements as reliable.
Authors: We agree that additional statistical details are required. In the revised manuscript we will report the exact dataset size and number of sequences, include run-to-run standard deviations across multiple trials, and add statistical significance tests (e.g., paired t-tests with p-values) to substantiate the reported gains. revision: yes
-
Referee: Method section: The central adaptive mechanism relies on cosine distance in the fixed VQ codebook and a Hamming-drift threshold as proxies for delta prioritization and keyframe insertion; the manuscript provides no ablation or correlation analysis showing these proxies align with actual reconstruction error or next-token prediction loss, leaving open the possibility that the gains are artifacts of the chosen metrics rather than genuine rate-distortion improvement.
Authors: Cosine distance and Hamming drift were chosen for their low computational cost and fully label-free online operation. We will add a correlation analysis in the revision, quantifying how well these proxies track embedding distortion and next-token perplexity on held-out sequences, to demonstrate they are not arbitrary. revision: yes
-
Referee: Experiments section: Periodic baseline implementations are not fully specified (exact keyframe interval selection under identical payload budgets and loss rates), and no comparison to alternative prioritization strategies (e.g., predictor-loss-based) is included, which directly affects the claim of consistent improvement over periodic methods.
Authors: We will expand the baseline description to specify the exact keyframe interval selection procedure that matches the adaptive method's payload budgets and loss rates. A predictor-loss-based alternative requires the downstream model at the transmitter, which conflicts with the label-free design; we will add a discussion of this limitation and, space permitting, a limited comparison. revision: partial
Circularity Check
No circularity: empirical gains are measured outcomes, not reductions to fitted inputs or self-definitions
full rationale
The paper defines a heuristic online algorithm that uses cosine distance in the fixed VQ codebook for delta prioritization and a Hamming-drift threshold on token IDs for adaptive keyframe insertion. It then reports direct empirical comparisons of resulting embedding distortion and next-token perplexity against periodic-keyframe baselines at matched bitrates and packet-loss rates. These improvements (e.g., 7.2% distortion drop at 200-byte budget) are computed from the streamed receiver states and do not reduce by construction to any parameter fitted inside the paper or to a quantity defined in terms of the decision proxies themselves. No self-citations, uniqueness theorems, or ansatzes are invoked to justify load-bearing steps; the central claims rest on independent experimental measurements rather than tautological re-derivations.
Axiom & Free-Parameter Ledger
free parameters (2)
- Hamming-drift threshold
- Payload budget
axioms (2)
- domain assumption Cosine distance in codebook embedding space is a suitable proxy for prioritizing which token deltas to transmit
- domain assumption Hamming distance on token IDs adequately measures state drift for keyframe decisions
Reference graph
Works this paper leans on
-
[1]
D. Ha and J. Schmidhuber, “World Models,” arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering Diverse Do- mains through World Models (DreamerV3),” arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Neural Discrete Representation Learning
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural Discrete Representation Learning,” arXiv:1711.00937, 2017
work page Pith review arXiv 2017
-
[4]
Taming Transformers for High- Resolution Image Synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming Transformers for High- Resolution Image Synthesis,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[5]
MaskGIT: Masked Generative Image Transformer,
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “MaskGIT: Masked Generative Image Transformer,” arXiv:2202.04200, 2022
-
[6]
GAIA-1: A Generative World Model for Autonomous Driving
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado, “GAIA-1: A Generative World Model for Autonomous Driving,” arXiv:2309.17080, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
C. Sommer and F. Dressler,Vehicular Networking. Cambridge, UK: Cambridge University Press, 2015
work page 2015
-
[8]
Wireless Access for V2X Commu- nications: Research, Challenges and Opportunities,
J. Clancy, D. Mullins, B. Deegan, J. Horgan, E. Ward, C. Eising, P. Denny, E. Jones, and M. Glavin, “Wireless Access for V2X Commu- nications: Research, Challenges and Opportunities,”IEEE Communica- tions Surveys & Tutorials, vol. 26, no. 3, pp. 2082–2119, 2024, doi: 10.1109/COMST.2024.3384132
-
[9]
Overview of the H.264/A VC Video Coding Standard,
T. Wiegand, G. J. Sullivan, G. Bjøntegaard, and A. Luthra, “Overview of the H.264/A VC Video Coding Standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560–576, Jul. 2003
work page 2003
-
[10]
Region-of-interest- based rate control scheme for high-efficiency video coding,
M. Meddeb, M. Cagnazzo, and B. Pesquet-Popescu, “Region-of-interest- based rate control scheme for high-efficiency video coding,”APSIPA Transactions on Signal and Information Processing, vol. 3, 2014, doi: 10.1017/ATSIP.2014.15
-
[11]
H. Mareen, M. Courteaux, J. V ounckx, P. Lambert, and G. Van Wallendael, “Keyframe Insertion for Random Access and Packet- Loss Repair in H.264/A VC, H.265/HEVC, and H.266/VVC,” in Proc. Data Compression Conference (DCC), 2022, pp. 472–472, doi: 10.1109/DCC52660.2022.00083
-
[12]
Generating diverse high-fidelity images with VQ-V AE-2.arXiv:1906.00446, 2019
A. Razavi, A. van den Oord, and O. Vinyals, “Generating Diverse High- Fidelity Images with VQ-V AE-2,” inAdvances in Neural Information Processing Systems (NeurIPS), 2019, arXiv:1906.00446
-
[13]
VideoGPT: Video Generation using VQ-VAE and Transformers
W. Yan, Y . Zhang, P. Abbeel, and A. Srinivas, “VideoGPT: Video Generation using VQ-V AE and Transformers,” arXiv:2104.10157, 2021
work page internal anchor Pith review arXiv 2021
-
[14]
High-Resolution Image Synthesis with Latent Diffusion Models
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- Resolution Image Synthesis with Latent Diffusion Models,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2022, arXiv:2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
and Ohm, Jens-Rainer and Han, Woo-Jin and Wiegand, Thomas , urldate =
G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the High Efficiency Video Coding (HEVC) Standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649– 1668, Dec. 2012, doi: 10.1109/TCSVT.2012.2221191
-
[16]
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.- R. Ohm, “Overview of the Versatile Video Coding (VVC) Standard and Its Applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, Oct. 2021, doi: 10.1109/TCSVT.2021.3101956
-
[17]
Where2comm: Communication-Efficient Collaborative Perception via Spatial Confi- dence Maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-Efficient Collaborative Perception via Spatial Confi- dence Maps,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022, arXiv:2209.12836
-
[18]
COOPERNAUT: End- to-End Driving with Cooperative Perception for Networked Vehicles,
J. Cui, H. Qiu, D. Chen, P. Stone, and Y . Zhu, “COOPERNAUT: End- to-End Driving with Cooperative Perception for Networked Vehicles,” inProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2022, arXiv:2205.02222
-
[19]
PhysicalAI Autonomous Vehicles,
NVIDIA Corporation, “PhysicalAI Autonomous Vehicles,” Hugging Face Datasets, Oct. 28, 2025. [Online]. Available: https://huggingface. co/datasets/nvidia/PhysicalAI-Autonomous-Vehicles. Accessed: Feb. 2, 2026
work page 2025
-
[20]
Enhancing physics- informed neural networks through feature engineering,
S. Fazliani, Z. Frangella, and M. Udell, “Enhancing physics- informed neural networks through feature engineering,”arXiv preprint arXiv:2502.07209, 2025
-
[21]
Turbocharging gaussian process inference with approximate sketch-and-project,
P. Rathore, Z. Frangella, S. Garg, S. Fazliani, M. Derezi ´nski, and M. Udell, “Turbocharging gaussian process inference with approximate sketch-and-project,”arXiv preprint arXiv:2505.13723, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.