Recognition: 1 theorem link
· Lean TheoremDeterministic vs. LLM-Controlled Orchestration for COBOL-to-Python Modernization
Pith reviewed 2026-05-12 04:20 UTC · model grok-4.3
The pith
Deterministic orchestration achieves the same accuracy as LLM-controlled orchestration for COBOL-to-Python modernization but with better robustness and up to 3.5 times lower token consumption.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a controlled study holding models, prompts, tools, and source programs constant, deterministic orchestration—following a fixed execution policy with explicit validation stages—produces functional correctness comparable to LLM-controlled orchestration across multiple models. However, it improves worst-case robustness, reduces performance variability across repeated runs, and cuts token consumption by up to 3.5 times.
What carries the argument
Orchestration strategy, defined as whether a predetermined sequence of actions or the LLM itself selects and sequences the tool executions and validation checks in the modernization workflow.
If this is right
- Functional correctness remains the same whether control is fixed or delegated to the model.
- Worst-case outcomes improve under deterministic control because bad runs are less likely.
- Variability in results across multiple executions of the same task decreases.
- Operational costs drop significantly due to lower token usage in deterministic runs.
- Structured workflows with clear validation points favor fixed policies over full agentic control for stability and efficiency.
Where Pith is reading between the lines
- Similar benefits may appear in other legacy code migration tasks where the steps are well understood in advance.
- Teams handling production modernization might choose deterministic methods to avoid unpredictable costs and outputs.
- Hybrid systems could be explored where the LLM suggests but does not control the overall flow.
- The findings question whether agentic LLM workflows are necessary for all software engineering tasks with defined processes.
Load-bearing premise
That the tested COBOL programs and evaluation metrics capture the full range of real-world modernization challenges and that fixing all other factors completely isolates the impact of the orchestration method.
What would settle it
Finding a set of COBOL programs or metrics where LLM-controlled orchestration produces measurably higher correctness or lower overall costs than the deterministic version.
Figures
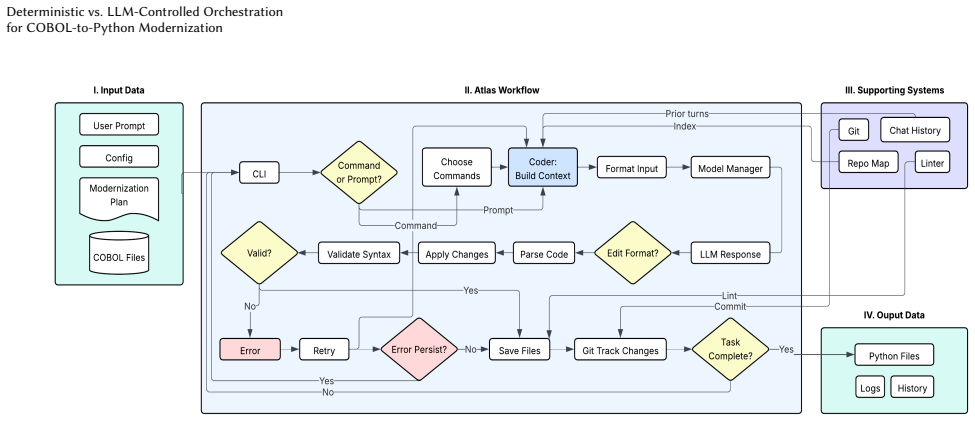



read the original abstract
Modernizing legacy COBOL systems remains difficult due to scarce expertise, large and long-lived codebases, and strict correctness requirements. Recent large language model (LLM)-based modernization systems increasingly rely on agentic workflows in which the model controls multi-step tool execution. However, it remains unclear whether delegating execution control to the LLM improves correctness, robustness, or efficiency in structured software engineering workflows. We present a controlled empirical study of deterministic and LLM-controlled orchestration for COBOL-to-Python modernization. Using a unified experimental framework, we hold the language models, prompts, tools, configurations, and source programs constant while varying only the execution control strategy. This isolates orchestration as the sole experimental variable. We evaluate both approaches using functional correctness, robustness across repeated stochastic runs, and computational efficiency. Across multiple models, deterministic orchestration achieves comparable computational accuracy to LLM-controlled orchestration while improving worst-case robustness and reducing performance variability across runs. Deterministic execution also reduces token consumption by up to 3.5x, leading to substantially lower operational cost. These results suggest that, in structured modernization workflows with explicit validation stages, fixed execution policies provide more stable and cost-efficient behavior than fully agentic orchestration without reducing translation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a controlled empirical comparison of deterministic orchestration versus LLM-controlled (agentic) orchestration for COBOL-to-Python code modernization. By fixing the underlying models, prompts, tools, configurations, and source programs, and varying only the execution control strategy, the study evaluates functional correctness, robustness across stochastic runs, and computational efficiency (token consumption). The key finding is that deterministic orchestration matches LLM-controlled in accuracy while offering better worst-case robustness, lower run-to-run variability, and up to 3.5× reduction in token usage.
Significance. If these results hold under broader conditions, the work has significant implications for the design of LLM-based software modernization tools. The strength of the study lies in its controlled design that isolates the orchestration variable, providing clear evidence against the assumption that delegating control to LLMs always improves outcomes in structured workflows. This could encourage more hybrid or deterministic approaches in agentic systems, leading to more reliable and cost-effective solutions in legacy system modernization.
major comments (2)
- [Experimental Setup] The representativeness of the source COBOL programs is not sufficiently addressed. The manuscript does not specify the size, complexity, or features (such as database interactions, file I/O, or intricate business rules) of the programs used. As noted in the stress-test, if these are limited to simple procedural code, the advantages in robustness and the 3.5x token reduction may not extend to typical real-world COBOL modernization workloads, weakening the generalizability of the conclusions.
- [Results and Analysis] The claims regarding reduced performance variability and improved worst-case robustness lack supporting statistical analysis, such as standard deviation calculations, variance tests, or p-values across the repeated runs. Without these, the quantitative support for 'reducing performance variability' remains qualitative.
minor comments (1)
- [Abstract] Consider specifying the exact number of models tested and the number of repeated runs to allow readers to better gauge the reliability of the 'across multiple models' and variability claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments below in detail. We believe these suggestions will help improve the clarity and rigor of the work, and we indicate where revisions will be made in the next version.
read point-by-point responses
-
Referee: [Experimental Setup] The representativeness of the source COBOL programs is not sufficiently addressed. The manuscript does not specify the size, complexity, or features (such as database interactions, file I/O, or intricate business rules) of the programs used. As noted in the stress-test, if these are limited to simple procedural code, the advantages in robustness and the 3.5x token reduction may not extend to typical real-world COBOL modernization workloads, weakening the generalizability of the conclusions.
Authors: We agree that the manuscript would benefit from more explicit characterization of the COBOL programs to address concerns about representativeness. In the revised version, we will add a new subsection in the Experimental Setup detailing the programs' sizes (LOC), structural complexity, and key features including file I/O, database interactions, and business rules. The selected programs come from an established benchmark for COBOL modernization and include a range of complexities, as partially indicated in our stress-test. We will also expand the discussion of limitations to note that while our controlled comparison isolates orchestration effects, further validation on larger, more diverse real-world codebases is warranted. revision: yes
-
Referee: [Results and Analysis] The claims regarding reduced performance variability and improved worst-case robustness lack supporting statistical analysis, such as standard deviation calculations, variance tests, or p-values across the repeated runs. Without these, the quantitative support for 'reducing performance variability' remains qualitative.
Authors: We concur that incorporating formal statistical analysis would strengthen the evidence for our claims on variability and robustness. The revised manuscript will report standard deviations and other descriptive statistics for the metrics across repeated runs. We will also include results from variance tests (e.g., F-test or Levene's test) comparing the two orchestration strategies and discuss the statistical significance of the observed differences in variability. This will move the support from qualitative to quantitative while maintaining the integrity of the original findings. revision: yes
Circularity Check
No circularity: purely empirical comparison without derivations or self-referential reductions
full rationale
The paper conducts a controlled empirical study that isolates orchestration strategy by holding models, prompts, tools, configurations, and source programs fixed while reporting functional correctness, robustness, and token consumption directly from experimental runs. No equations, fitted parameters, derivations, or self-citations appear in the load-bearing claims; results are not reduced to prior quantities by construction. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a controlled empirical study of deterministic and LLM-controlled orchestration for COBOL-to-Python modernization... deterministic orchestration achieves comparable computational accuracy... reduces token consumption by up to 3.5x
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.12973 (2025)
Aamer Aljagthami, Mohammed Banabila, Musab Alshehri, Mohammed Kabini, and Mohammad D. Alahmadi. 2025. Evaluating Large Language Models for Code Translation: Effects of Prompt Language and Prompt Design. arXiv:2509.12973 [cs.SE] https://arxiv.org/abs/2509.12973
-
[2]
Agnieszka Ciborowska, Aleksandar Chakarov, and Rahul Pandita. 2021. Contemporary COBOL: Developers’ Perspectives on Defects and Defect Location. In2021 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 227–238. doi:10.1109/icsme52107.2021.00027
-
[3]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Large Language Model based Multi-Agents: A Survey of Progress and Challenges. arXiv:2402.01680 [cs.CL] https://arxiv.org/abs/2402.01680
work page internal anchor Pith review arXiv 2024
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310. 06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
- [6]
-
[7]
Gabriel Orlanski, Kefan Xiao, Xavier Garcia, Jeffrey Hui, Joshua Howland, Jonathan Malmaud, Jacob Austin, Rishabh Singh, and Michele Catasta
-
[8]
Measuring the impact of programming language distribution
Measuring The Impact Of Programming Language Distribution. arXiv:2302.01973 [cs.SE] https://arxiv.org/abs/2302.01973
-
[9]
Jialing Pan, Adrien Sadé, Jin Kim, Eric Soriano, Guillem Sole, and Sylvain Flamant
-
[10]
Stelocoder: a decoder-only llm for multi-language to pyth on code translation,
SteloCoder: a Decoder-Only LLM for Multi-Language to Python Code Translation. arXiv:2310.15539 [cs.CL] https://arxiv.org/abs/2310.15539
- [11]
-
[12]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761 [cs.CL] https://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
- [14]
- [15]
- [16]
-
[17]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Qianqian Zhang, Jiajia Liao, Heting Ying, Yibo Ma, Haozhan Shen, Jingcheng Li, Peng Liu, Lu Zhang, Chunxin Fang, Kyusong Lee, Ruochen Xu, and Tiancheng Zhao. 2025. Unifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research. arXiv:2505.24354 [cs.CL] https://arxiv.org/abs/2505.24354
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.