Recognition: no theorem link
Tube-Structured Incremental Semantic HARQ for Generative Video Receivers
Pith reviewed 2026-05-12 04:45 UTC · model grok-4.3
The pith
Tube-structured package requests stabilize generative video recovery earlier than block-based HARQ under budget constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
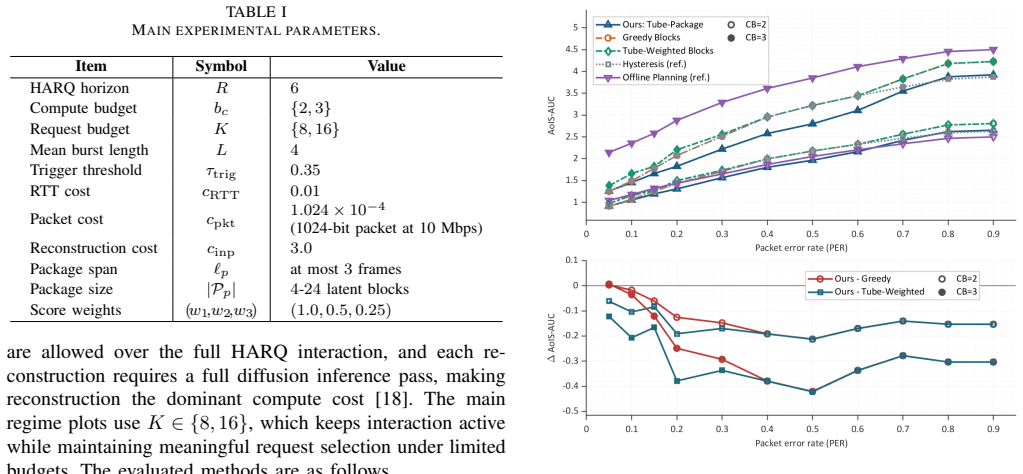
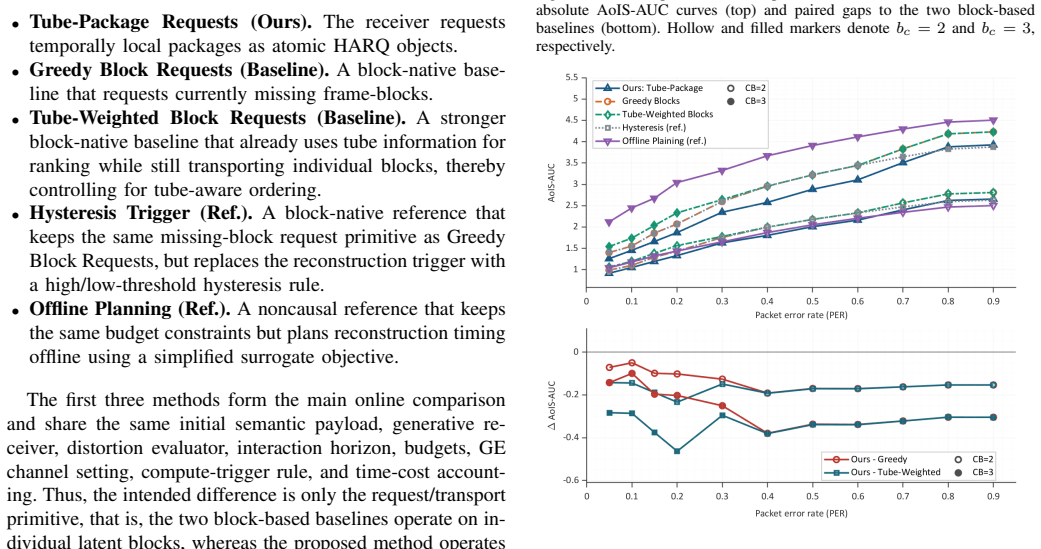
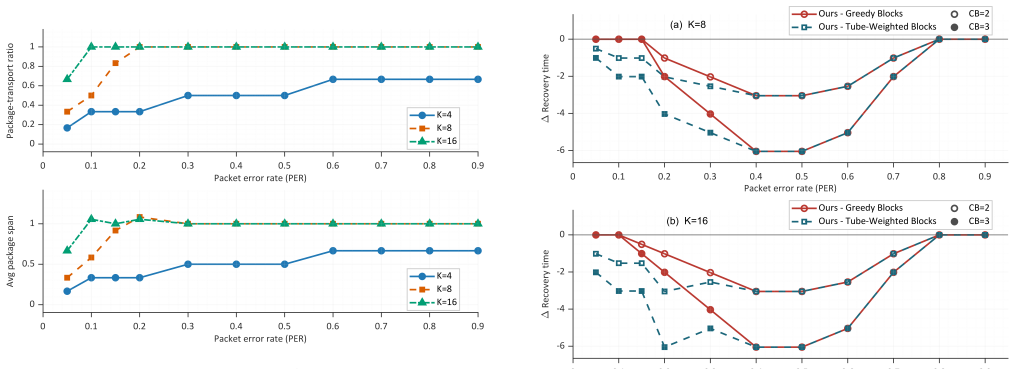
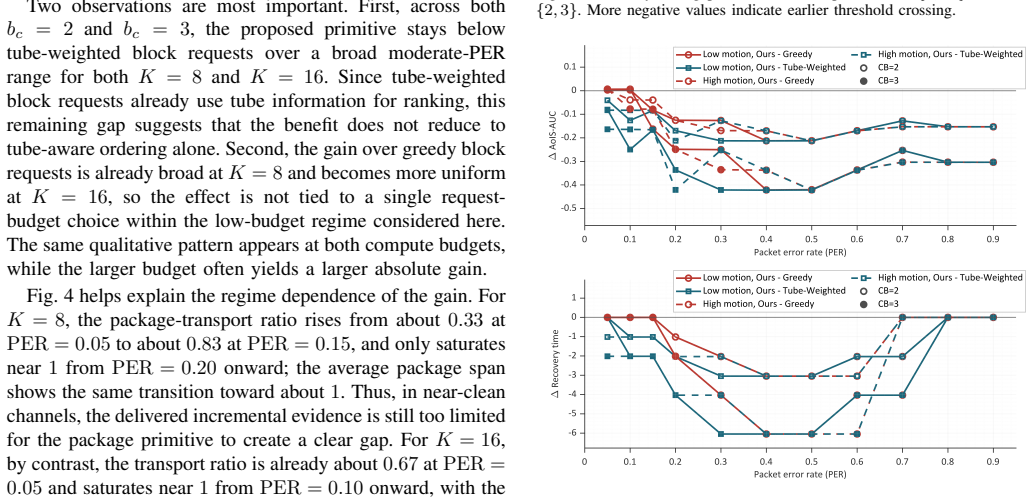
Under a controlled comparison with matched backbone, budgets, and channel model, the tube-structured package-native requests yield lower time-weighted recovery cost than competitive block-based baselines in moderate-to-harsh regimes. The gain appears mainly as earlier stabilization of the recovery trajectory, while final-quality endpoints remain broadly comparable, and the advantage holds even against a tube-aware block-ranking baseline.
What carries the argument
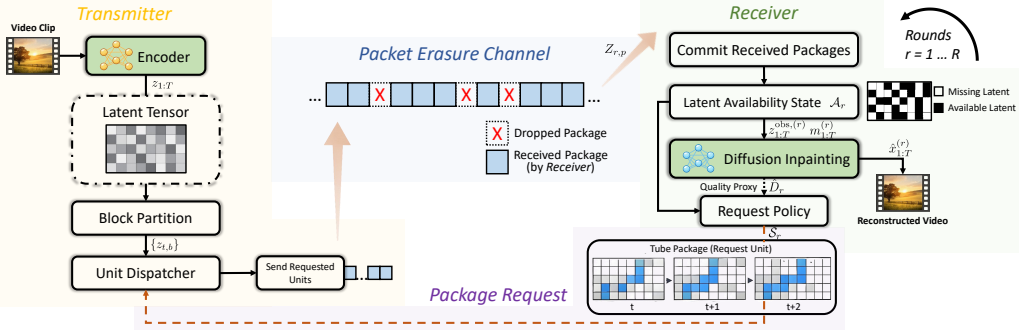
Tube-structured package-native requests, treating temporally local packages as the channel-visible HARQ objects that are transmitted, dropped, received, and committed at package granularity.
Load-bearing premise
That the retransmission primitive can be isolated as the only differing variable in comparisons while matching the generative backbone, budgets, and channel model, and that the chosen objective metric reflects real practical recovery quality.
What would settle it
An experiment replicating the controlled protocol but finding no reduction in time-weighted recovery cost for the tube-structured method compared to block-based baselines in moderate-to-harsh regimes.
Figures

read the original abstract
Generative semantic communication uses receiver-side generative priors to reconstruct visual content from compact semantics, making it attractive for bandwidth-limited multimedia delivery. For video, reliable recovery remains difficult because errors accumulate over time, useful evidence is temporally correlated, and the receiver must make decisions under limited interaction, retransmission, and reconstruction budgets. Existing generative semantic communication studies mainly emphasize representation, compression, or generative reconstruction, while recent error-resilient and semantic-HARQ methods still largely operate on encoder-defined or frame-block retransmission units. This paper studies receiver-driven semantic HARQ for generative video reconstruction under a budget-constrained AoIS-AUC objective and argues that the retransmission primitive is itself an important system design variable. We propose tube-structured package-native requests, in which temporally local packages are the channel-visible HARQ objects and are transmitted, dropped, received, and committed at package granularity. Under a controlled comparison protocol with matched backbone, budgets, and channel model, this primitive yields lower time-weighted recovery cost than competitive block-based baselines in practically relevant moderate-to-harsh regimes, while the gap naturally shrinks in near-clean channels. The gain mainly appears as earlier stabilization of the recovery trajectory, while final-quality endpoints remain broadly comparable, and it persists even against a tube-aware block-ranking baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes tube-structured package-native retransmission units for receiver-driven semantic HARQ in generative video reconstruction. It claims that, under a controlled comparison with matched generative backbone, budgets, and channel model, this primitive achieves lower time-weighted recovery cost (AoIS-AUC objective) than block-based baselines in moderate-to-harsh regimes, with the advantage manifesting as earlier stabilization of the recovery trajectory while final-quality endpoints remain comparable; the gap shrinks in near-clean channels.
Significance. If the controlled experimental comparison holds, the work would usefully isolate the retransmission primitive as an independent design variable in semantic communication systems, separate from the generative model. This could inform more efficient budget-constrained video delivery protocols where temporal error accumulation is a concern.
minor comments (2)
- The abstract asserts quantitative gains in time-weighted recovery cost but does not reference specific figures, tables, or numerical values (with error bars or statistical tests) that would allow readers to assess the magnitude and robustness of the reported advantage over baselines.
- Implementation details for the tube-structured requests (e.g., exact package definition, commitment rules, and interaction with the generative decoder) are only sketched at a high level; a dedicated subsection with pseudocode or a diagram would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work and the recommendation for minor revision. We appreciate the recognition that the controlled comparison isolates the retransmission primitive as an independent design variable and that the tube-structured approach yields earlier stabilization under the AoIS-AUC objective in moderate-to-harsh regimes.
Circularity Check
No significant circularity detected in derivation or claims
full rationale
The paper advances a receiver-driven tube-structured semantic HARQ primitive for generative video and supports its advantage solely through controlled empirical comparisons against external block-based baselines, with matched generative backbones, budgets, channel models, and AoIS-AUC objective. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description that would reduce the claimed earlier stabilization or lower time-weighted recovery cost to an input by construction. The central argument treats the retransmission unit as an isolatable design variable evaluated against independent baselines, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semantic communications for future internet: Fundamentals, applications, and challenges,
W. Yang, H. Du, Z. Q. Liew, W. Y . B. Lim, Z. Xiong, D. Niyato, X. Chi, X. Shen, and C. Miao, “Semantic communications for future internet: Fundamentals, applications, and challenges,”IEEE Communications Surveys & Tutorials, vol. 25, no. 1, pp. 213–250, 2022
work page 2022
-
[2]
Generative AI-Driven Semantic Communication Networks: Architecture, Technologies, and Applications,
C. Liang, H. Du, Y . Sun, D. Niyato, J. Kang, D. Zhao, and M. A. Imran, “Generative AI-Driven Semantic Communication Networks: Architecture, Technologies, and Applications,”IEEE Transactions on Cognitive Communications and Networking, vol. 11, no. 1, pp. 27–47, 2025
work page 2025
-
[3]
Generative semantic communication: Architectures, technologies, and applications,
J. Ren, Y . Sun, H. Du, W. Yuan, C. Wang, X. Wang, Y . Zhou, Z. Zhu, F. Wang, and S. Cui, “Generative semantic communication: Architectures, technologies, and applications,”Engineering, vol. 56, no. 1, pp. 46–51, 2025
work page 2025
-
[4]
Diffusion-Driven Semantic Communication for Generative Models with Bandwidth Constraints,
L. Guo, W. Chen, Y . Sun, B. Ai, N. Pappas, and T. Q. S. Quek, “Diffusion-Driven Semantic Communication for Generative Models with Bandwidth Constraints,”IEEE Transactions on Wireless Commu- nications, vol. 24, no. 8, pp. 6490–6503, 2025
work page 2025
-
[5]
Diffusion-Aided Bandwidth- Efficient Semantic Communication with Adaptive Requests,
X. Wang, X. Xie, M. Li, and Z. Liu, “Diffusion-Aided Bandwidth- Efficient Semantic Communication with Adaptive Requests,”arXiv preprint arXiv:2510.26442, 2025
-
[6]
Deep Flow-Guided Video Inpainting,
J. Ren, X. Gong, L. Yuan, Y . Wei, and W. Zuo, “Deep Flow-Guided Video Inpainting,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 3723–3732
work page 2019
-
[7]
Dif- fueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018, 2025
X. Li, H. Xue, P. Ren, and L. Bo, “DiffuEraser: A Diffusion Model for Video Inpainting,”Technical Report arXiv:2501.10018, 2025
-
[8]
Generative Video Semantic Communication via Multimodal Semantic Fusion with Large Model,
H. Yin, L. Qiao, Y . Ma, S. Sun, K. Li, Z. Gao, and D. Niyato, “Generative Video Semantic Communication via Multimodal Semantic Fusion with Large Model,”IEEE Transactions on V ehicular Technology, vol. 75, no. 1, pp. 1701–1706, 2026
work page 2026
-
[9]
Goal-Oriented Semantic Commu- nication for Wireless Video Transmission via Generative AI,
N. Li, Y . Deng, and D. Niyato, “Goal-Oriented Semantic Commu- nication for Wireless Video Transmission via Generative AI,”IEEE Transactions on Wireless Communications, vol. 25, pp. 10 841–10 854, 2026
work page 2026
-
[10]
Generative Feature Imput- ing: A Technique for Error-resilient Semantic Communication,
J. Huang, Q. Zeng, H. Du, and K. Huang, “Generative Feature Imput- ing: A Technique for Error-resilient Semantic Communication,”arXiv preprint arXiv:2508.17957, 2025
-
[11]
SemHARQ: Semantic- Aware HARQ for Multi-task Semantic Communications,
J. Hu, F. Wang, W. Xu, H. Gao, and P. Zhang, “SemHARQ: Semantic- Aware HARQ for Multi-task Semantic Communications,”IEEE Trans- actions on Wireless Communications, 2025, early access
work page 2025
-
[12]
Semantic HARQ: Joint Source-Channel Coding-Powered Reliable Retransmissions for IoT Net- works,
Y . Li, X. Wang, Z. Shi, D. Wang, and Y . Fu, “Semantic HARQ: Joint Source-Channel Coding-Powered Reliable Retransmissions for IoT Net- works,”IEEE Internet of Things Journal, 2026, published version of the semantic-HARQ work cited in the related-work discussion
work page 2026
-
[13]
Toward Intelligent Resource Allocation on Task-Oriented Semantic Commu- nication,
H. Zhang, H. Wang, Y . Li, K. Long, and V . C. M. Leung, “Toward Intelligent Resource Allocation on Task-Oriented Semantic Commu- nication,”IEEE Wireless Communications, vol. 30, no. 3, pp. 70–77, 2023
work page 2023
-
[14]
QoE-based semantic-aware resource allocation for multi-task networks,
L. Yan, Z. Qin, C. Li, R. Zhang, Y . Li, and X. Tao, “QoE-based semantic-aware resource allocation for multi-task networks,”IEEE Transactions on Wireless Communications, vol. 23, no. 9, pp. 11 958– 11 971, 2024
work page 2024
-
[15]
The Age of Incorrect Information: An Enabler of Semantics-Empowered Communication,
A. Maatouk, M. Assaad, and A. Ephremides, “The Age of Incorrect Information: An Enabler of Semantics-Empowered Communication,” IEEE Transactions on Wireless Communications, vol. 22, no. 5, pp. 2621–2635, 2023
work page 2023
-
[16]
Age of Semantic Information-Aware Wireless Transmission for Remote Monitoring Systems,
X. Han, B. Feng, Y . Wu, X.-G. Xia, W. Zhang, and S. Sun, “Age of Semantic Information-Aware Wireless Transmission for Remote Monitoring Systems,”IEEE Transactions on Wireless Communications, 2025
work page 2025
-
[17]
K. Bountrogiannis, A. Ephremides, P. Tsakalides, and G. Tzagkarakis, “Age of incorrect information with hybrid ARQ under a resource constraint for N-ary symmetric Markov sources,”IEEE Transactions on Networking, vol. 33, no. 2, pp. 640–653, 2024
work page 2024
-
[18]
Y . Hu, X. Chen, and X. Cun, “EasyOmnimatte: Taming Pretrained Inpainting Diffusion Models for End-to-End Video Layered Decom- position,”arXiv preprint arXiv:2512.21865, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.