Recognition: 2 theorem links
· Lean TheoremRADAR: Redundancy-Aware Diffusion for Multi-Agent Communication Structure Generation
Pith reviewed 2026-05-12 04:22 UTC · model grok-4.3
The pith
A step-by-step diffusion process generates communication topologies for multi-agent LLM systems that cuts token use on simple tasks while raising performance on complex ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Communication topology design is formulated as a step-by-step generation process guided by the effective size of the graph using conditional discrete graph diffusion models in order to actively reduce communication overhead in multi-agent systems.
What carries the argument
Conditional discrete graph diffusion model that builds communication topologies incrementally while conditioned on the effective size of the graph to control redundancy.
If this is right
- Token consumption drops on simple tasks relative to fixed or single-step topologies.
- Accuracy rises on code generation, mathematical reasoning, and planning benchmarks.
- Robustness improves when the same method is applied to varied task difficulties and agent counts.
- Fine-grained structural exploration becomes possible because connections are added gradually rather than chosen in one step.
- Flexible composition of agent groups is supported without forcing unnecessary links on every query.
Where Pith is reading between the lines
- If the diffusion sampling can be made fast enough, the same machinery could reconfigure an agent group mid-task when the query difficulty changes.
- The query-adaptive guidance idea could be tested on non-LLM agent teams such as robotic swarms that must share limited bandwidth.
- Measuring the effective graph size might be replaced or combined with other signals such as estimated latency or privacy cost in future extensions.
- Deployed systems that bill per token could see measurable cost reductions once the method is integrated into production multi-agent frameworks.
Load-bearing premise
Formulating communication topology design as a step-by-step generation process guided by the effective size of the graph will actively reduce overhead while preserving or improving capability on complex tasks.
What would settle it
A controlled test on a simple benchmark task in which the generated topology consumes the same number or more tokens than a fixed complete graph while achieving equal or lower accuracy would falsify the central claim.
Figures





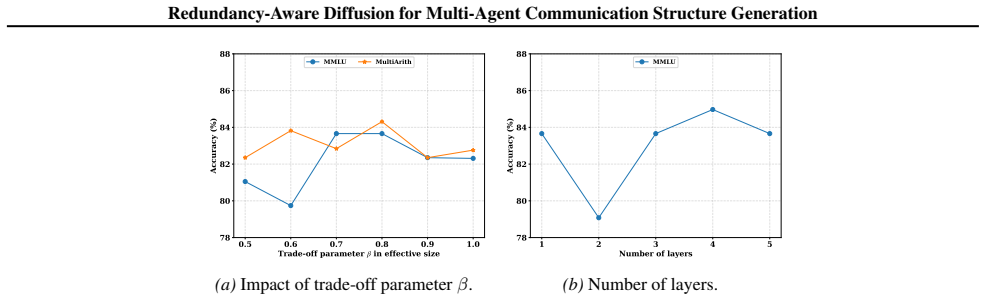

read the original abstract
Compared with individual agents, large language model based multi-agent systems have shown great capabilities consistently across diverse tasks, including code generation, mathematical reasoning, and planning, etc. Despite their impressive performance, the effectiveness and robustness of these systems heavily rely on their communication topology, which is often fixed or generated in a single step. This restricts fine-grained structural exploration and flexible composition, resulting in excessive token utilization on simple tasks while limiting capability on complicated tasks. To mitigate this challenge, we introduce RADAR, a redundancy-aware and query-adaptive generative framework that actively reduce communication overhead. Motivated by recent progress in conditional discrete graph diffusion models, we formulate communication topology design as a step-by-step generation process, guided by the effective size of the graph. Comprehensive experiments on six benchmarks demonstrate that RADAR consistently outperforms recent baselines, achieving higher accuracy, lower token consumption, and greater robustness across diverse scenarios. Our code and data are available at https://github.com/cszhangzhen/RADAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RADAR, a redundancy-aware generative framework for designing communication topologies in LLM-based multi-agent systems. It formulates topology generation as a step-by-step conditional discrete graph diffusion process guided by the effective size of the graph, with the goal of reducing token overhead on simple tasks while preserving or improving performance on complex ones. Comprehensive experiments on six benchmarks are reported to show consistent outperformance over recent baselines in accuracy, lower token consumption, and robustness, with code and data released.
Significance. If the central mechanism is validated, the work could meaningfully advance practical multi-agent LLM systems by replacing fixed or single-step topologies with a query-adaptive generative process. The use of discrete graph diffusion conditioned on effective size is a novel angle for this domain, and the code release supports reproducibility. However, the significance hinges on demonstrating that the guidance mechanism causally drives the reported efficiency gains rather than ancillary factors.
major comments (3)
- [§3.2] §3.2 (Method, effective size guidance): The paper does not provide a precise definition, equation, or computation procedure for the 'effective size of the graph' scalar used to condition the diffusion process. Without this, it is impossible to verify whether the conditioning produces meaningfully less redundant topologies or simply correlates with query difficulty.
- [§5] §5 (Experiments): No ablation studies isolate the contribution of the effective-size guidance (e.g., RADAR without guidance vs. with guidance) on token consumption or accuracy. The central claim that the step-by-step diffusion guided by effective size reduces overhead while preserving capability therefore rests on an untested causal link; gains could arise from other design choices such as prompting, base LLM, or search budget.
- [Tables 1-6] Table 1–6 (benchmark results): The reported improvements in accuracy and token use lack error bars, statistical significance tests, or details on the exact baselines and hyper-parameters. This makes it difficult to assess whether the outperformance is robust or sensitive to implementation details.
minor comments (2)
- [Abstract] Abstract: The claim of 'consistent outperformance' and 'higher accuracy, lower token consumption' would be stronger if accompanied by at least one quantitative example (e.g., average token reduction percentage) rather than remaining purely qualitative.
- [§2] Notation: The term 'effective size' is used without an initial formal definition or reference to prior graph-theoretic literature; a short paragraph clarifying its relation to standard metrics such as graph density or diameter would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We appreciate the positive assessment of the work's potential impact and the recognition of the novelty in applying conditional discrete graph diffusion to multi-agent communication topology generation. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for greater clarity and rigor.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Method, effective size guidance): The paper does not provide a precise definition, equation, or computation procedure for the 'effective size of the graph' scalar used to condition the diffusion process. Without this, it is impossible to verify whether the conditioning produces meaningfully less redundant topologies or simply correlates with query difficulty.
Authors: We agree that a precise definition is essential for reproducibility and to clarify the mechanism. The manuscript introduces the effective size as a conditioning scalar in §3.2 but does not supply the explicit equation or computation steps. We will add a new subsection in the revised §3.2 that provides the mathematical definition (effective size as a query-dependent measure of minimal sufficient nodes/edges after redundancy pruning), the exact formula, and the algorithmic procedure for its calculation from the input query and task complexity. This will enable readers to verify how the conditioning influences topology redundancy. revision: yes
-
Referee: [§5] §5 (Experiments): No ablation studies isolate the contribution of the effective-size guidance (e.g., RADAR without guidance vs. with guidance) on token consumption or accuracy. The central claim that the step-by-step diffusion guided by effective size reduces overhead while preserving capability therefore rests on an untested causal link; gains could arise from other design choices such as prompting, base LLM, or search budget.
Authors: We concur that an internal ablation isolating the effective-size guidance is necessary to establish causality. Our current results compare the full RADAR framework against external baselines, but we did not report a controlled variant with the guidance component disabled. We will perform and include new ablation experiments in the revised §5, holding all other elements (prompting, base LLM, diffusion steps, and search budget) fixed while toggling only the effective-size conditioning. Results will be reported on token consumption and accuracy to directly test the guidance's contribution. revision: yes
-
Referee: [Tables 1-6] Table 1–6 (benchmark results): The reported improvements in accuracy and token use lack error bars, statistical significance tests, or details on the exact baselines and hyper-parameters. This makes it difficult to assess whether the outperformance is robust or sensitive to implementation details.
Authors: We acknowledge that the current experimental reporting lacks statistical detail and implementation transparency. In the revised manuscript we will augment Tables 1–6 with error bars (standard deviation across five independent runs), include p-values from appropriate statistical tests (paired t-tests for accuracy and token metrics), and add a comprehensive experimental appendix listing exact baseline configurations, hyper-parameters, random seeds, and hardware settings to support full reproducibility and robustness assessment. revision: yes
Circularity Check
No circularity: RADAR introduces an independent generative framework without self-referential reductions.
full rationale
The paper presents RADAR as a new redundancy-aware diffusion model that formulates multi-agent topology generation as a conditional step-by-step discrete graph diffusion process guided by effective graph size. This is motivated by external progress in conditional discrete graph diffusion models rather than derived from the paper's own outputs. No equations, predictions, or uniqueness claims reduce by construction to fitted parameters, self-definitions, or self-citation chains. Performance results are reported via independent empirical evaluation on six benchmarks against baselines, with no load-bearing steps that equate outputs to inputs tautologically. The derivation chain remains self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
we incorporate the concept of effective size (Burt, 1992), which measures the non-redundant portion of a node’s ego network, into the graph generation process to guide the construction of low-redundancy multi-agent communication structures... φi(vk)=|Ni(vk)|−∑j,q∈Ni(vk)AjqI[r(j)=r(q)]/|Ni(vk)|
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formulate communication topology design as a step-by-step generation process, guided by the effective size of the graph
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CodeAgent: Enhancing Code Generation with Tool-Integrated Agent Systems for Real-World Repo-level Coding Challenges , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Generate-on-Graph: Treat LLM as both Agent and KG for Incomplete Knowledge Graph Question Answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
Multiagentbench: Evaluating the collaboration and competition of llm agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Shall we team up: Exploring spontaneous cooperation of competing llm agents , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[6]
Cut the Crap: An Economical Communication Pipeline for
Guibin Zhang and Yanwei Yue and Zhixun Li and Sukwon Yun and Guancheng Wan and Kun Wang and Dawei Cheng and Jeffrey Xu Yu and Tianlong Chen , booktitle=. Cut the Crap: An Economical Communication Pipeline for. 2025 , url=
work page 2025
-
[7]
Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of
Giorgio Piatti and Zhijing Jin and Max Kleiman-Weiner and Bernhard Sch. Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[8]
DebateCoder: Towards Collective Intelligence of LLMs via Test Case Driven LLM Debate for Code Generation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
arXiv preprint arXiv:2511.02755 , year =
Controlling Performance and Budget of a Centralized Multi-agent LLM System with Reinforcement Learning , author=. arXiv preprint arXiv:2511.02755 , year=
-
[10]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[11]
arXiv preprint arXiv:2503.18891 , year=
Agentdropout: Dynamic agent elimination for token-efficient and high-performance llm-based multi-agent collaboration , author=. arXiv preprint arXiv:2503.18891 , year=
-
[12]
International conference on machine learning , pages=
Autoregressive diffusion model for graph generation , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[13]
Ronald S. Burt , publisher=. Structural Holes: The Social Structure of Competition , year=
-
[14]
Yongliang Shen and Kaitao Song and Xu Tan and Dongsheng Li and Weiming Lu and Yueting Zhuang , booktitle=. Hugging. 2023 , url=
work page 2023
-
[15]
Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key? , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Llm-planner: Few-shot grounded planning for embodied agents with large language models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[17]
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. Meta. The Twelfth International Conference on Learning Representations , year=
-
[18]
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
work page 2024
-
[19]
International Conference on Machine Learning , pages=
Efficient and Degree-Guided Graph Generation via Discrete Diffusion Modeling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[20]
Advances in Neural Information Processing Systems , volume=
Graph diffusion transformers for multi-conditional molecular generation , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Graph denoising diffusion for inverse protein folding , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
International Conference on Learning Representations , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. International Conference on Learning Representations , year=
-
[24]
Advances in neural information processing systems , volume=
Inductive representation learning on large graphs , author=. Advances in neural information processing systems , volume=
-
[25]
International Conference on Learning Representations , year=
Graph Attention Networks , author=. International Conference on Learning Representations , year=
-
[26]
Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
H2mn: Graph similarity learning with hierarchical hypergraph matching networks , author=. Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
-
[27]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[28]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[29]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
Solving general arithmetic word problems , author=. Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
work page 2015
-
[31]
Are NLP Models really able to Solve Simple Math Word Problems? , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
work page 2021
-
[32]
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
work page 2021
-
[33]
Advances in neural information processing systems , volume=
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in neural information processing systems , volume=
Revisiting, benchmarking and understanding unsupervised graph domain adaptation , author=. Advances in neural information processing systems , volume=
-
[35]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
European semantic web conference , pages=
Modeling relational data with graph convolutional networks , author=. European semantic web conference , pages=. 2018 , organization=
work page 2018
-
[37]
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
-
[39]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[40]
Advances in Neural Information Processing Systems , volume=
Directional diffusion models for graph representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Towards Unsupervised Open-Set Graph Domain Adaptation via Dual Reprogramming , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Are more llm calls all you need? towards the scaling properties of compound ai systems , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Llm agents making agent tools , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
Evoagent: Towards automatic multi-agent generation via evolutionary algorithms , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[45]
The Eleventh International Conference on Learning Representations , year=
Automatic Chain of Thought Prompting in Large Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[46]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[47]
The Eleventh International Conference on Learning Representations , year=
Complexity-Based Prompting for Multi-step Reasoning , author=. The Eleventh International Conference on Learning Representations , year=
-
[48]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[49]
Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[50]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[51]
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[52]
First Conference on Language Modeling , year=
A dynamic llm-powered agent network for task-oriented agent collaboration , author=. First Conference on Language Modeling , year=
-
[53]
The Twelfth International Conference on Learning Representations , year=
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , author=. The Twelfth International Conference on Learning Representations , year=
-
[54]
The Thirteenth International Conference on Learning Representations , year=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. The Thirteenth International Conference on Learning Representations , year=
-
[55]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
AutoAgents: a framework for automatic agent generation , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
-
[56]
Forty-first International Conference on Machine Learning , year=
Mingchen Zhuge and Wenyi Wang and Louis Kirsch and Francesco Faccio and Dmitrii Khizbullin and J. Forty-first International Conference on Machine Learning , year=
-
[57]
The Thirteenth International Conference on Learning Representations , year=
Automated Design of Agentic Systems , author=. The Thirteenth International Conference on Learning Representations , year=
-
[58]
Yu Shang and Yu Li and Keyu Zhao and Likai Ma and Jiahe Liu and Fengli Xu and Yong Li , booktitle=. AgentSquare: Automatic. 2025 , url=
work page 2025
-
[59]
Jiayi Zhang and Jinyu Xiang and Zhaoyang Yu and Fengwei Teng and Xiong-Hui Chen and Jiaqi Chen and Mingchen Zhuge and Xin Cheng and Sirui Hong and Jinlin Wang and Bingnan Zheng and Bang Liu and Yuyu Luo and Chenglin Wu , booktitle=. 2025 , url=
work page 2025
-
[60]
Forty-second International Conference on Machine Learning , year=
G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks , author=. Forty-second International Conference on Machine Learning , year=
-
[61]
Forty-second International Conference on Machine Learning , year=
Multi-agent Architecture Search via Agentic Supernet , author=. Forty-second International Conference on Machine Learning , year=
-
[62]
arXiv preprint arXiv:2507.18224 , year=
Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation , author=. arXiv preprint arXiv:2507.18224 , year=
-
[63]
Dynamic generation of multi-llm agents communication topologies with graph diffusion models
Dynamic Generation of Multi-LLM Agents Communication Topologies with Graph Diffusion Models , author=. arXiv preprint arXiv:2510.07799 , year=
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Vector field oriented diffusion model for crystal material generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.