Recognition: 2 theorem links
· Lean TheoremTeam-Based Self-Play With Dual Adaptive Weighting for Fine-Tuning LLMs
Pith reviewed 2026-05-12 04:51 UTC · model grok-4.3
The pith
Team-based self-play with dual adaptive weighting enables stable self-supervised alignment of LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TPAW adopts a team-based framework in which the current policy model both collaborates with and competes against historical checkpoints, combined with a response reweighting scheme that adjusts the importance of target responses and a player weighting strategy that dynamically modulates each team member's contribution during training, allowing iterative refinement of alignment without requiring additional human supervision.
What carries the argument
The team-based self-play framework with dual adaptive weighting, in which the current policy interacts with historical checkpoints while response importance and player contributions are adjusted dynamically to sustain training progress.
Where Pith is reading between the lines
- Similar team competition structures could stabilize self-training loops in domains such as code generation or mathematical reasoning where synthetic data quality also varies.
- The method may lower reliance on external reward models by using internal model comparisons to maintain signal strength.
- Varying the number or selection strategy of historical checkpoints could be tested to optimize the diversity of the competing signals.
Load-bearing premise
That the team-based self-play framework and the two adaptive weighting mechanisms sufficiently resolve sensitivity to synthetic data quality and the diminishing positive-negative gap without introducing new instabilities or biases.
What would settle it
Running TPAW and a standard self-training baseline on identical base models and synthetic data for the same number of iterations, then measuring win rates on a benchmark such as MT-Bench or AlpacaEval; failure of TPAW to exceed the baseline would falsify the performance claim.
Figures



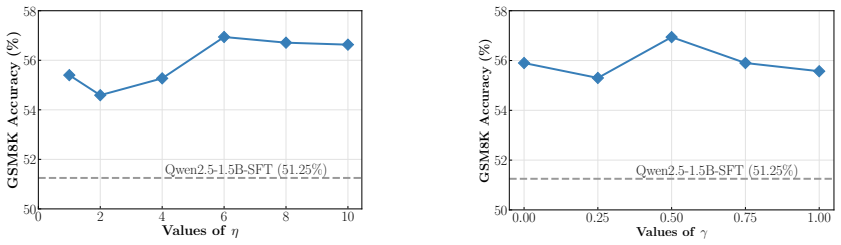
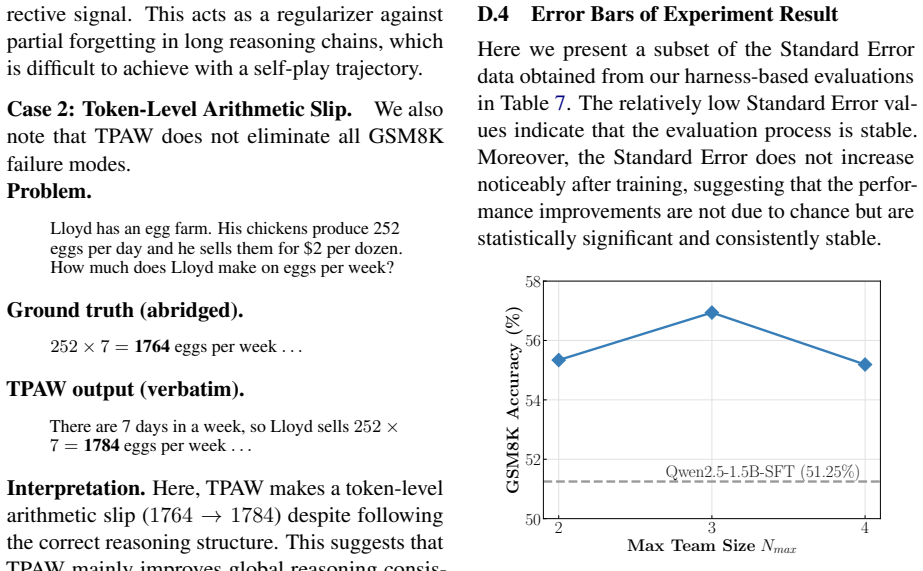
read the original abstract
While recent self-training approaches have reduced reliance on human-labeled data for aligning LLMs, they still face critical limitations: (i) sensitivity to synthetic data quality, leading to instability and bias amplification in iterative training; (ii) ineffective optimization due to a diminishing gap between positive and negative responses over successive training iterations. In this paper, we propose Team-based self-Play with dual Adaptive Weighting (TPAW), a novel self-play algorithm designed to improve alignment in a fully self-supervised setting. TPAW adopts a team-based framework in which the current policy model both collaborates with and competes against historical checkpoints, promoting more stable and efficient optimization. To further enhance learning, we design two adaptive weighting mechanisms: (i) a response reweighting scheme that adjusts the importance of target responses, and (ii) a player weighting strategy that dynamically modulates each team member's contribution during training. Initialized from a SFT model, TPAW iteratively refines alignment without requiring additional human supervision. Experimental results demonstrate that TPAW consistently outperforms existing baselines across various base models and LLM benchmarks. Our code is publicly available at https://github.com/lab-klc/TPAW.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Team-based self-Play with dual Adaptive Weighting (TPAW), a self-supervised algorithm for aligning LLMs. It introduces a team-based framework in which the current policy model collaborates and competes against historical checkpoints, combined with two adaptive weighting mechanisms (response reweighting to adjust target response importance and player weighting to modulate team member contributions). Initialized from an SFT model, TPAW iteratively refines alignment without human supervision. The central claim is that TPAW consistently outperforms existing baselines across various base models and LLM benchmarks, with public code released.
Significance. If the experimental results hold under scrutiny, the work provides a concrete algorithmic advance for reducing instability and bias in iterative self-training of LLMs. The team-based self-play plus dual weighting directly targets the stated problems of synthetic data sensitivity and shrinking positive-negative gaps. Public code availability strengthens the contribution by enabling direct verification and extension.
major comments (2)
- [§4] §4 (Experiments): The claim of consistent outperformance is central, yet the manuscript provides no quantitative details on effect sizes, statistical significance, or variance across runs in the main results tables. Without these, it is impossible to determine whether the reported gains exceed baseline variability or arise from post-hoc hyperparameter choices.
- [§3.2] §3.2 (Adaptive Weighting Mechanisms): The response reweighting and player weighting are presented as solving the diminishing gap problem, but the manuscript does not include an ablation isolating each component's contribution to stability (e.g., training curves with and without each weighting). This leaves open whether the dual weighting is load-bearing or whether simpler reweighting suffices.
minor comments (3)
- [§2] The abstract states the two limitations but does not quantify them (e.g., how rapidly the positive-negative gap shrinks in prior methods). Adding a short illustrative plot or metric in §2 would strengthen the motivation.
- [§3] Notation for the team members and weighting functions is introduced without a consolidated table; a single table summarizing symbols, their meanings, and update rules would improve readability.
- [Appendix] The public code link is welcome, but the manuscript should include a brief reproducibility checklist (random seeds, exact hyperparameter ranges, hardware) in the appendix.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which have helped us improve the clarity and rigor of our work. We address each major comment below and have revised the manuscript to incorporate additional analyses and details where feasible.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The claim of consistent outperformance is central, yet the manuscript provides no quantitative details on effect sizes, statistical significance, or variance across runs in the main results tables. Without these, it is impossible to determine whether the reported gains exceed baseline variability or arise from post-hoc hyperparameter choices.
Authors: We agree that reporting variance, effect sizes, and statistical significance is essential to substantiate the performance claims. In the revised manuscript, we have updated all main results tables in Section 4 to include standard deviations computed over five independent runs with different random seeds. We also report Cohen's d effect sizes for the key performance differences and include p-values from paired t-tests against each baseline. To address potential concerns about hyperparameter selection, we have added a dedicated paragraph in Section 4.1 describing the tuning protocol, which used a fixed held-out validation split and grid search performed prior to final test evaluation. revision: yes
-
Referee: [§3.2] §3.2 (Adaptive Weighting Mechanisms): The response reweighting and player weighting are presented as solving the diminishing gap problem, but the manuscript does not include an ablation isolating each component's contribution to stability (e.g., training curves with and without each weighting). This leaves open whether the dual weighting is load-bearing or whether simpler reweighting suffices.
Authors: We acknowledge that isolating the contribution of each weighting mechanism is necessary to establish their individual and joint importance. In the revised version, we have expanded Section 3.2 with new ablation experiments and added a corresponding appendix subsection. These include training dynamics plots (positive-negative response gap and reward curves) for the full TPAW model, the model without response reweighting, the model without player weighting, and a single-weighting baseline. The results indicate that both mechanisms are required to sustain the gap and prevent instability; removing either leads to measurable degradation in stability and final performance, with the combination providing benefits beyond simpler reweighting alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents TPAW as a novel algorithmic contribution consisting of a team-based self-play framework and two explicitly designed adaptive weighting mechanisms (response reweighting and player weighting). The abstract and high-level description frame these as new constructs initialized from an SFT model, with performance claims tied to experimental outperformance rather than any reduction to fitted parameters, self-defined quantities, or prior self-citations. Public code availability allows independent reproduction. No load-bearing derivation step is shown to collapse to its own inputs by construction, and the central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
- [3]
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
- [10]
- [11]
-
[12]
Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
Self-play fine-tuning convertsweak language models to strong language models , author=. Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[14]
Advances in neural information processing systems (NeurIPS) , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[15]
Advances in neural information processing systems (NeurIPS) , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[16]
Advances in neural information processing systems (NeurIPS) , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[17]
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[18]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Forty-first International Conference on Machine Learning (ICML) , year =
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Xian Li and Sainbayar Sukhbaatar and Jing Xu and Jason Weston , title =. Forty-first International Conference on Machine Learning (ICML) , year =
-
[20]
Smith and Daniel Khashabi and Hannaneh Hajishirzi , editor =
Yizhong Wang and Yeganeh Kordi and Swaroop Mishra and Alisa Liu and Noah A. Smith and Daniel Khashabi and Hannaneh Hajishirzi , editor =. Self-Instruct: Aligning Language Models with Self-Generated Instructions , booktitle =
-
[21]
Zhaoyang Wang and Weilei He and Zhiyuan Liang and Xuchao Zhang and Chetan Bansal and Ying Wei and Weitong Zhang and Huaxiu Yao , booktitle=
-
[22]
Smaug: Fixing failure modes of preference optimisation with dpo-positive , author=. arXiv preprint arXiv:2402.13228 , year=
-
[23]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[24]
Yi Ren and Danica J. Sutherland , booktitle=. Learning Dynamics of
-
[25]
The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS) , year=
Bias Amplification in Language Model Evolution: An Iterated Learning Perspective , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[26]
Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[27]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Self-Improvement in Language Models: The Sharpening Mechanism , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[28]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
- [29]
-
[30]
Rafael Rafailov and Joey Hejna and Ryan Park and Chelsea Finn , booktitle=. From \ r\ to \ Q
-
[31]
Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
Preference fine-tuning of LLMs should leverage suboptimal, on-policy data , author=. Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Iterative reasoning preference optimization , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[33]
Provably Mitigating Overoptimization in
Zhihan Liu and Miao Lu and Shenao Zhang and Boyi Liu and Hongyi Guo and Yingxiang Yang and Jose Blanchet and Zhaoran Wang , booktitle=. Provably Mitigating Overoptimization in
-
[34]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
- [36]
-
[37]
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2023
-
[38]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Clémentine Fourrier and Nathan Habib and Alina Lozovskaya and Konrad Szafer and Thomas Wolf , title =. 2024 , publisher =
work page 2024
-
[40]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[41]
Edward Beeching and Clémentine Fourrier and Nathan Habib and Sheon Han and Nathan Lambert and Nazneen Rajani and Omar Sanseviero and Lewis Tunstall and Thomas Wolf , title =. 2023 , publisher =
work page 2023
-
[42]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track (NeurIPS) , year=
-
[43]
Proceedings of the International Conference on Learning Representations , year=
MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning , author=. Proceedings of the International Conference on Learning Representations , year=
-
[44]
Gpqa: A graduate-level google-proof q&a benchmark , author=. 2024 , booktitle=
work page 2024
-
[45]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , booktitle=
work page 2021
-
[46]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author=. ACL (Findings) , year=
-
[47]
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
work page 2023
-
[48]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
work page 2018
-
[49]
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[50]
9th International Conference on Learning Representations (ICLR) , year =
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations (ICLR) , year =
-
[51]
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[52]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
-
[53]
Mastering the game of go without human knowledge , author=. nature , volume=
-
[54]
Self-play with execution feedback: Improving instruction-following capabilities of large language models , author=. arXiv preprint arXiv:2406.13542 , year=
-
[55]
Training language models to follow instructions with human feedback , volume =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[56]
Forty-first International Conference on Machine Learning (ICML)) , year =
Harrison Lee and Samrat Phatale and Hassan Mansoor and Thomas Mesnard and Johan Ferret and Kellie Lu and Colton Bishop and Ethan Hall and Victor Carbune and Abhinav Rastogi and Sushant Prakash , title =. Forty-first International Conference on Machine Learning (ICML)) , year =
-
[57]
Yann Dubois and Chen Xuechen Li and Rohan Taori and Tianyi Zhang and Ishaan Gulrajani and Jimmy Ba and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[58]
KTO: Model Alignment as Prospect Theoretic Optimization
Kto: Model alignment as prospect theoretic optimization , author=. arXiv preprint arXiv:2402.01306 , year=
work page internal anchor Pith review arXiv
-
[59]
Yu Meng and Mengzhou Xia and Danqi Chen , title =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[60]
Manning and Stefano Ermon and Chelsea Finn , title =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , title =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[61]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Neural networks for machine learning lecture 6a overview of mini-batch gradient descent , author=. Cited on , volume=
-
[63]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. arXiv preprint arXiv:2307.08691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Zero: Memory optimizations toward training trillion parameter models , author=. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , pages=. 2020 , organization=
work page 2020
-
[65]
arXiv preprint arXiv:2405.00675 , year=
Self-play preference optimization for language model alignment , author=. arXiv preprint arXiv:2405.00675 , year=
-
[66]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Absolute Zero: Reinforced Self-play Reasoning with Zero Data , author=. arXiv preprint arXiv:2505.03335 , year=
work page internal anchor Pith review arXiv
-
[67]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Self-playing adversarial language game enhances llm reasoning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[68]
arXiv preprint arXiv:2401.04056 , year=
A minimaximalist approach to reinforcement learning from human feedback , author=. arXiv preprint arXiv:2401.04056 , year=
-
[69]
IBM Journal of research and development , volume=
Some studies in machine learning using the game of checkers , author=. IBM Journal of research and development , volume=. 1959 , publisher=
work page 1959
-
[70]
Communications of the ACM , volume=
Temporal difference learning and TD-Gammon , author=. Communications of the ACM , volume=
-
[71]
Safety Alignment via Constrained Knowledge Unlearning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.