Recognition: 2 theorem links
· Lean TheoremOpenZL: Using Graphs to Compress Smaller and Faster
Pith reviewed 2026-05-12 04:00 UTC · model grok-4.3
The pith
Representing compression as a directed acyclic graph of modular codecs makes application-specific compressors fast to build and practical to deploy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Compression can be expressed as a directed acyclic graph of modular codecs that produces a self-describing wire format; any such graph is decompressible by one universal decoder, so tailored compressors become simple to construct, maintain, and run at high speed.
What carries the argument
The graph model: a directed acyclic graph whose nodes are modular codecs and whose edges define data flow, allowing arbitrary composition into a single self-describing stream.
If this is right
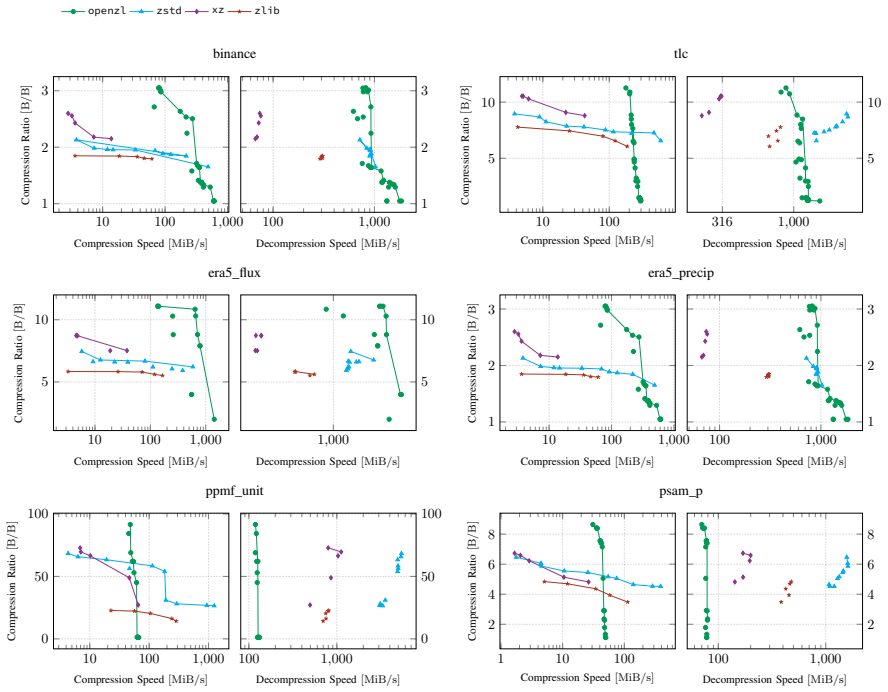
- Outperforms state-of-the-art general-purpose compressors in both ratio and throughput on multiple real-world datasets.
- Matches ratio-focused deep-learning compressors while remaining many orders of magnitude faster.
- Reduces custom-compressor development time from months to days in production settings.
- Delivers consistent size or speed gains inside large-scale deployments without sacrificing maintainability.
- Supports any configuration through a single universal decoder because the wire format is self-describing.
Where Pith is reading between the lines
- The same modular-graph approach could be applied to other data-transformation pipelines such as encoding or serialization.
- Standard libraries of codec nodes might emerge, lowering the barrier for new domains to adopt tailored compression.
- Performance on streaming or incremental data could be tested by measuring how graph depth affects latency.
- Integration with existing compression ecosystems would let organizations mix OpenZL graphs with legacy formats.
Load-bearing premise
Non-experts can configure the graph to exploit data semantics without reintroducing the development and maintenance costs that previously limited custom compressors.
What would settle it
A dataset on which every OpenZL configuration yields both worse ratio and lower speed than a hand-written application-specific compressor that required comparable or less engineering effort.
Figures







read the original abstract
In the last few decades, research techniques have improved lossless compression ratios by significantly increasing processing time. However, these techniques have not gained popularity in industry because production systems require high throughput and low resource utilization. Instead, real world improvements in compression are increasingly realized by building application-specific compressors which can exploit knowledge about the structure and semantics of the data being compressed. Application-specific compressor systems outperform even the best generic compressors, but these techniques have severe drawbacks -- they are inherently limited in applicability, are hard to develop, and are difficult to maintain and deploy. In this work, we show that these challenges can be overcome with a new compression strategy. We propose the "graph model" of compression, a new theoretical framework for representing compression as a directed acyclic graph of modular codecs. OpenZL implements this framework and compresses data into a self-describing wire format, any configuration of which can be decompressed by a universal decoder. OpenZL's design enables rapid development of application-specific compressors with minimal code. Experimental results demonstrate that OpenZL achieves superior compression ratios and speeds compared to state-of-the-art general-purpose compressors on a variety of real-world datasets. Compared to ratio-focused deep-learning compressors, OpenZL is competitive on ratio while being many orders of magnitude faster. Internal deployments at Meta have also shown consistent improvements in size and/or speed, with development timelines reduced from months to days. OpenZL thus represents a significant advance in practical, scalable, and maintainable data compression for modern data-intensive applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 'graph model' of lossless compression in which data is compressed via a directed acyclic graph (DAG) of modular codecs. OpenZL implements this model, emitting self-describing wire formats that a single universal decoder can decompress regardless of the chosen graph. The central thesis is that this framework permits rapid construction of application-specific compressors with minimal code, thereby avoiding the limited applicability, high development cost, and maintenance burden of traditional bespoke compressors. The manuscript reports that OpenZL outperforms state-of-the-art general-purpose compressors in both ratio and speed on real-world datasets, remains competitive in ratio with deep-learning compressors while being orders of magnitude faster, and has yielded size/speed gains in internal Meta deployments with development times reduced from months to days.
Significance. If the experimental claims are reproducible and the reported gains are attainable under the 'minimal code' constraint emphasized in the abstract, the work would be significant for production data pipelines. It offers a concrete middle path between generic compressors (fast but ratio-limited) and hand-crafted application-specific ones (high ratio but expensive to build and maintain). The universal-decoder property and the DAG abstraction could lower the barrier to exploiting data semantics at scale. The internal-deployment anecdotes, if substantiated with before/after metrics, would strengthen the practicality argument.
major comments (2)
- [Abstract and Experimental Results] The abstract asserts that 'OpenZL's design enables rapid development of application-specific compressors with minimal code' and that internal deployments reduced timelines 'from months to days.' However, the manuscript provides no description of the graph configurations used in the reported experiments (e.g., number of nodes, lines of configuration code, or whether they were authored by domain experts versus non-expert users following a simple recipe). This information is load-bearing for the central claim that the framework overcomes the historical drawbacks of application-specific compressors.
- [Abstract] The abstract states that 'Experimental results demonstrate that OpenZL achieves superior compression ratios and speeds compared to state-of-the-art general-purpose compressors on a variety of real-world datasets' yet supplies no quantitative numbers, dataset names, baseline implementations, or methodology details. Without these, the superiority claim cannot be evaluated and the comparison to deep-learning compressors remains unverifiable.
minor comments (2)
- [Abstract] The abstract would be strengthened by the inclusion of at least one or two concrete ratio/speed numbers and the names of the primary baselines and datasets.
- [Introduction / Graph Model section] Notation for the graph model (nodes, edges, codec interfaces) should be introduced with a small diagram or formal definition early in the paper to aid readers unfamiliar with the DAG representation.
Simulated Author's Rebuttal
Thank you for your constructive review and for highlighting areas where the manuscript can be strengthened. We address each of the major comments below and commit to revisions that improve clarity and verifiability without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The abstract asserts that 'OpenZL's design enables rapid development of application-specific compressors with minimal code' and that internal deployments reduced timelines 'from months to days.' However, the manuscript provides no description of the graph configurations used in the reported experiments (e.g., number of nodes, lines of configuration code, or whether they were authored by domain experts versus non-expert users following a simple recipe). This information is load-bearing for the central claim that the framework overcomes the historical drawbacks of application-specific compressors.
Authors: We agree that concrete details on the graph configurations and authoring effort are essential to substantiate the rapid-development claim. The current manuscript describes the high-level experimental graphs in the results section but does not quantify node counts, configuration code length, or the expertise required. In the revision we will add a dedicated paragraph and table in the experimental section that reports, for each dataset, the number of nodes in the DAG, approximate lines of configuration code, and notes that the graphs were authored by the paper's authors following the framework's modular recipe rather than by domain experts. This addition will directly support the 'minimal code' assertion. revision: yes
-
Referee: [Abstract] The abstract states that 'Experimental results demonstrate that OpenZL achieves superior compression ratios and speeds compared to state-of-the-art general-purpose compressors on a variety of real-world datasets' yet supplies no quantitative numbers, dataset names, baseline implementations, or methodology details. Without these, the superiority claim cannot be evaluated and the comparison to deep-learning compressors remains unverifiable.
Authors: We acknowledge that the abstract currently omits specific quantitative results, dataset names, and baseline details. While abstracts are constrained by length, we agree that including representative numbers would make the claims more immediately evaluable. We will revise the abstract to incorporate concise quantitative highlights (e.g., ratio and speed improvements on named datasets versus named general-purpose baselines) while preserving the overall length and flow. The full methodology, all dataset names, and complete baseline comparisons remain available in the experimental sections of the manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces the graph model of compression as a directed acyclic graph of modular codecs, implemented in OpenZL with a self-describing wire format and universal decoder. Claims of overcoming application-specific compressor drawbacks rest on this framework plus empirical results against general-purpose and deep-learning compressors on real-world datasets. No mathematical derivations, equations, fitted parameters, or predictions appear that reduce by construction to inputs or self-citations. The work is a systems contribution validated against external benchmarks, with no load-bearing steps that are self-definitional, fitted-input renamings, or uniqueness theorems imported from the authors' prior work.
Axiom & Free-Parameter Ledger
invented entities (1)
-
graph model of compression
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the 'graph model' of compression, a new theoretical framework for representing compression as a directed acyclic graph of modular codecs.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OpenZL achieves superior compression ratios and speeds... with development timelines reduced from months to days.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A machine learning perspective on predictive coding with paq8,
B. Knoll and N. d. Freitas, “A machine learning perspective on predictive coding with paq8,” in2012 Data Compression Conference, April 2012, pp. 377–386
work page 2012
-
[2]
B. Knoll, “Cmix compressor,” https://www.byronknoll.com/cmix.html, 2014, accessed: 2025-04-30
work page 2014
-
[3]
Lossless data compression with neural networks,
F. Bellard, “Lossless data compression with neural networks,” 2019. [Online]. Available: https://bellard.org/nncp/nncp.pdf
work page 2019
-
[4]
Dzip: Improved general-purpose lossless compression based on novel neural network modeling,
M. Goyal, K. Tatwawadi, S. Chandak, and I. Ochoa, “Dzip: Improved general-purpose lossless compression based on novel neural network modeling,” in2020 Data Compression Conference (DCC), March 2020, pp. 372–372
work page 2020
-
[5]
B. Knoll, “lstm-compress,” https://github.com/byronknoll/lstm-compre ss, 2017
work page 2017
-
[6]
Trace: A fast transformer-based general-purpose lossless compressor,
Y . Mao, Y . Cui, T.-W. Kuo, and C. J. Xue, “Trace: A fast transformer-based general-purpose lossless compressor,” inProceedings of the ACM Web Conference 2022, ser. WWW ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 1829–1838. [Online]. Available: https://doi.org/10.1145/3485447.3511987
-
[7]
Lossless compression with probabilistic circuits,
A. Liu, S. Mandt, and G. V . den Broeck, “Lossless compression with probabilistic circuits,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/for um?id=X_hByk2-5je
work page 2022
-
[8]
Compression for better: A general and stable lossless compression framework,
B. Zhang, D. Cheng, Y . Zhang, F. Liu, and W. Chen, “Compression for better: A general and stable lossless compression framework,” 2024. [Online]. Available: https://arxiv.org/abs/2412.06868
-
[9]
Modern lossless compression techniques: Review, comparison and analysis,
A. Gupta, A. Bansal, and V . Khanduja, “Modern lossless compression techniques: Review, comparison and analysis,” in2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT). IEEE, 2017, pp. 1–8
work page 2017
-
[10]
Zstandard - fast real-time compression algorithm,
Y . Collet, “Zstandard - fast real-time compression algorithm,” Facebook, Open source project, 2015. [Online]. Available: https: //github.com/facebook/zstd
work page 2015
-
[11]
R. Jumar, H. Maaß, and V . Hagenmeyer, “Comparison of lossless compression schemes for high rate electrical grid time series for smart grid monitoring and analysis,”Computers & Electrical Engineering, vol. 71, pp. 465–476, 2018. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0045790617334791
work page 2018
-
[12]
A comparison of lossless compression algorithms for altimeter data,
M. Thevenin, S. Pigoury, O. Thomine, and F. Gouillon, “A comparison of lossless compression algorithms for altimeter data,” EGUsphere, vol. 2022, pp. 1–28, 2022. [Online]. Available: https: //egusphere.copernicus.org/preprints/2022/egusphere-2022-1094/
work page 2022
-
[13]
Performance comparison of lossless compression strategies for dynamic vision sensor data,
K. Iqbal, N. Khan, and M. G. Martini, “Performance comparison of lossless compression strategies for dynamic vision sensor data,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2020, pp. 4427–4431
work page 2020
- [14]
- [15]
-
[16]
Sparse and skew hashing of k-mers,
G. E. Pibiri, “Sparse and skew hashing of k-mers,”Bioinformatics, vol. 38, no. Supplement_1, pp. i185–i194, 06 2022. [Online]. Available: https://doi.org/10.1093/bioinformatics/btac245
-
[17]
On weighted k-mer dictionaries,
——, “On weighted k-mer dictionaries,”Algorithms for Molecular Biology, vol. 18, no. 1, p. 3, 2023. [Online]. Available: https: //doi.org/10.1186/s13015-023-00226-2
-
[18]
Batched k-mer lookup on the spectral burrows-wheeler transform,
J. N. Alanko, E. Biagi, J. Mackenzie, and S. J. Puglisi, “Batched k-mer lookup on the spectral burrows-wheeler transform,” in2025 Proceedings of the Symposium on Algorithm Engineering and Experiments (ALENEX), 2025, pp. 95–106. [Online]. Available: https://epubs.siam.org/doi/abs/10.1137/1.9781611978339.8
-
[19]
Spring: a next-generation compressor for fastq data,
S. Chandak, K. Tatwawadi, I. Ochoa, M. Hernaez, and T. Weissman, “Spring: a next-generation compressor for fastq data,”Bioinformatics, vol. 35, no. 15, pp. 2674–2676, 12 2018. [Online]. Available: https://doi.org/10.1093/bioinformatics/bty1015
-
[20]
Genozip: a universal extensible genomic data compressor,
D. Lan, R. Tobler, Y . Souilmi, and B. Llamas, “Genozip: a universal extensible genomic data compressor,”Bioinformatics, vol. 37, no. 16, pp. 2225–2230, 02 2021. [Online]. Available: https: //doi.org/10.1093/bioinformatics/btab102
-
[21]
Hapzipper: sharing hapmap populations just got easier,
P. Chanda, E. Elhaik, and J. S. Bader, “Hapzipper: sharing hapmap populations just got easier,”Nucleic acids research, vol. 40, no. 20, pp. e159–e159, 2012
work page 2012
-
[22]
Learning better lossless compression using lossy compression,
F. Mentzer, L. Van Gool, and M. Tschannen, “Learning better lossless compression using lossy compression,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020, pp. 6637–6646
work page 2020
-
[23]
High throughput jpeg 2000 (htj2k): Algorithm, performance and potential,
D. Taubman, A. Naman, R. Mathew, M. Smith, O. Watanabe, and P. Lemieux, “High throughput jpeg 2000 (htj2k): Algorithm, performance and potential,”International Telecommunications Union (ITU), pp. 15 444–15, 2019
work page 2000
-
[24]
Lossless float image compression,
A. Pranckevi ˇcius, “Lossless float image compression,” 07 2025. [Online]. Available: https://aras-p.info/blog/2025/07/08/Lossless-Float- Image-Compression/
work page 2025
-
[25]
A. Kapoulkine, “meshoptimizer,” https://github.com/zeux/meshoptimize r, 2017
work page 2017
-
[26]
Lossless and near-lossless compression for foundation models,
M. Hershcovitch, L. Choshen, A. Wood, I. Enmouri, P. Chin, S. Sundararaman, and D. Harnik, “Lossless and near-lossless compression for foundation models,” 2024. [Online]. Available: https://arxiv.org/abs/2404.15198
-
[27]
Computational graphs, and backpropagation,
M. Collins, “Computational graphs, and backpropagation,”Lecture Notes, Columbia University, pp. 11–23, 2018
work page 2018
-
[28]
A mathematical theory of communication,
C. Shannon, “A mathematical theory of communication,”The Bell System Technical Journal, vol. 27, pp. 379–423, 1948
work page 1948
-
[29]
A method for the construction of minimum-redundancy codes,
D. A. Huffman, “A method for the construction of minimum-redundancy codes,”Proceedings of the IRE, vol. 40, no. 9, pp. 1098–1101, 1952
work page 1952
-
[30]
Arithmetic coding for data compression,
I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression,”Commun. ACM, vol. 30, no. 6, p. 520–540, Jun. 1987. [Online]. Available: https://doi.org/10.1145/214762.214771
-
[31]
J. Duda, “Asymmetric numeral systems: entropy coding combining speed of huffman coding with compression rate of arithmetic coding,”
-
[32]
[Online]. Available: https://arxiv.org/abs/1311.2540
-
[33]
Finite state entropy - a new breed of entropy coder,
Y . Collet, “Finite state entropy - a new breed of entropy coder,” https: //fastcompression.blogspot.com/2013/12/finite-state-entropy-new- breed-of.html, 2013
work page 2013
-
[34]
A block-sorting lossless data compression algorithm,
M. Burrows and D. J. Wheeler, “A block-sorting lossless data compression algorithm,” Digital Equipment Corporation, Systems Research Center, Palo Alto, CA, SRC Research Report 124, May 1994, sRC Research Report 124. [Online]. Available: https: //www.cs.jhu.edu/~langmea/resources/burrows_wheeler.pdf
work page 1994
-
[35]
A locally adaptive data compression scheme,
J. L. Bentley, D. D. Sleator, R. E. Tarjan, and V . K. Wei, “A locally adaptive data compression scheme,”Commun. ACM, vol. 29, no. 4, p. 320–330, Apr. 1986. [Online]. Available: https://doi.org/10.1145/5684.5688
-
[36]
Results of a prototype television bandwidth compression scheme,
A. Robinson and C. Cherry, “Results of a prototype television bandwidth compression scheme,”Proceedings of the IEEE, vol. 55, no. 3, pp. 356– 364, 1967
work page 1967
-
[37]
A universal algorithm for sequential data compression,
J. Ziv and A. Lempel, “A universal algorithm for sequential data compression,”IEEE Transactions on Information Theory, vol. 23, no. 3, pp. 337–343, 1977
work page 1977
-
[38]
LZ4 - Extremely fast compression,
Y . Collet, “LZ4 - Extremely fast compression,” https://github.com/lz4/l z4, self-published, Open source project, 2011
work page 2011
-
[39]
Snappy: A fast compressor/decompressor,
S. H. Gunderson, “Snappy: A fast compressor/decompressor,” 2011, open source project. [Online]. Available: https://github.com/google/sn appy
work page 2011
-
[40]
DEFLATE compressed data format specification version 1.3,
P. Deutsch, “DEFLATE compressed data format specification version 1.3,” Internet Requests for Comments, RFC Editor, RFC 1951, May 1996, rFC1951. [Online]. Available: https://www.rfc-editor.org/rfc/rfc 1951.txt
work page 1951
-
[41]
GZIP file format specification version 4.3,
L. P. Deutsch, “GZIP file format specification version 4.3,” RFC 1952, May 1996. [Online]. Available: https://datatracker.ietf.org/doc/html/rfc1 952
work page 1952
-
[42]
Brotli compressed data format,
J. Alakuijala and Z. Szabadka, “Brotli compressed data format,” Internet Requests for Comments, RFC Editor, RFC 7932, July 2016. [Online]. Available: https://www.rfc-editor.org/rfc/rfc7932.txt
work page 2016
-
[43]
Zstandard compression and the application/zstd media type,
Y . Collet and M. Kucherawy, “Zstandard compression and the application/zstd media type,” Internet Requests for Comments, RFC Editor, RFC 8878, October 2018, rFC8878. [Online]. Available: https://www.rfc-editor.org/rfc/rfc8878.txt
work page 2018
-
[44]
I. Pavlov, “LZMA algorithm description,” 2013, 7-zip documentation. [Online]. Available: https://www.7-zip.org/7z.html
work page 2013
-
[45]
Data compression using adaptive coding and partial string matching,
J. Cleary and I. Witten, “Data compression using adaptive coding and partial string matching,”IEEE Transactions on Communications, vol. 32, no. 4, pp. 396–402, 1984
work page 1984
-
[46]
Data compression using dynamic markov modelling,
G. V . Cormack and R. N. S. Horspool, “Data compression using dynamic markov modelling,”The Computer Journal, vol. 30, no. 6, pp. 541–550, 12 1987. [Online]. Available: https://doi.org/10.1093/comjnl/30.6.541
-
[47]
The PAQ data compression programs,
M. Mahoney, “The PAQ data compression programs,” 2013, website documenting various PAQ iterations. [Online]. Available: http: //mattmahoney.net/dc/paq.html
work page 2013
-
[48]
PNG (Portable Network Graphics) Specification Version 1.0,
T. Boutell, “PNG (Portable Network Graphics) Specification Version 1.0,” RFC 2083, March 1997. [Online]. Available: https://www.rfc- editor.org/info/rfc2083
work page 2083
-
[49]
T. B. D. Team, “Blosc documentation,” 2010. [Online]. Available: https://www.blosc.org
work page 2010
-
[50]
A. S. Foundation, “parquet-format,” https://parquet.apache.org/docs/file- format/data-pages/compression/, Apache Software Foundation, Tech. Rep., 2024
work page 2024
-
[51]
Btune: Making compression better,
T. B. D. Team, “Btune: Making compression better,” https://blosc.org/ pages/btune, IronArray SLU, Tech. Rep., 2023
work page 2023
-
[52]
The zpaq compression algorithm,
M. Mahoney, “The zpaq compression algorithm,” self-published, Technical Report ZPAQ-2015-12-29, Dec. 2015. [Online]. Available: https://mattmahoney.net/dc/zpaq_compression.pdf
work page 2015
-
[53]
Practical neural networks for NLP: From theory to code,
C. Dyer, Y . Goldberg, and G. Neubig, “Practical neural networks for NLP: From theory to code,” inProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts, B. Yang and R. Hwa, Eds. Austin, Texas: Association for Computational Linguistics, Nov. 2016. [Online]. Available: https://aclanthology.org/D16-2001/
work page 2016
-
[54]
Universal lossless data compression algorithms,
S. Deorowicz, “Universal lossless data compression algorithms,” Ph.D. dissertation, Silesian University of Technology, 2003
work page 2003
-
[55]
“Sao star catalog,” 2002. [Online]. Available: http://tdc-www.harvard. edu/software/catalogs/sao.html
work page 2002
-
[56]
J. Smit, “Binance full history,” https://www.kaggle.com/datasets/jorijn smit/binance-full-history, 2025
work page 2025
-
[57]
“TLC trip record data,” https://www.nyc.gov/site/tlc/about/tlc-trip- record-data.page, 2022
work page 2022
-
[58]
Era5 hourly data on single levels from 1940 to present,
H. Hersbach, B. Bell, P. Berrisford, G. Biavati, A. Horányi, J. Muñoz Sabater, J. Nicolas, C. Peubey, R. Radu, I. Rozum, D. Schepers, A. Simmons, C. Soci, D. Dee, and J.-N. Thépaut, “Era5 hourly data on single levels from 1940 to present,” 2023
work page 1940
-
[59]
2020 census privacy-protected microdata file (ppmf) readme,
U. C. Bureau, “2020 census privacy-protected microdata file (ppmf) readme,” 2024. [Online]. Available: https://www2.census.gov/programs- surveys/decennial/2020/data/privacy-protected-microdata-file/2024-08- 05-privacy-protected-microdata-file-README.pdf
work page 2020
-
[60]
A. C. S. Office, “5-year pums data (2023),” 2024. [Online]. Available: https://www2.census.gov/programs-surveys/acs/data/pums/2023/5-Year/
work page 2023
-
[61]
A fast and elitist multiobjective genetic algorithm: Nsga-ii,
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: Nsga-ii,”IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182–197, 2002
work page 2002
-
[62]
J. R. Koza,Genetic Programming: On the Programming of Computers by Means of Natural Selection. Cambridge, MA, USA: MIT Press, 1992
work page 1992
-
[63]
Understanding data compression in warehouse-scale datacenter services,
G. Jeong, B. Sharma, N. Terrell, A. Dhanotia, Z. Zhao, N. Agarwal, A. Kejariwal, and T. Krishna, “Understanding data compression in warehouse-scale datacenter services,” in2022 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2022, pp. 221–223
work page 2022
-
[64]
Thrift: Scalable cross-language services implementation,
M. Slee, A. Agarwal, and M. Kwiatkowski, “Thrift: Scalable cross-language services implementation,” Facebook, Technical Report,
-
[65]
Available: https://thrift.apache.org/static/files/thrift- 20070401.pdf
[Online]. Available: https://thrift.apache.org/static/files/thrift- 20070401.pdf
-
[66]
https://github.com/facebookincubator/nimble
(2024) nimble. https://github.com/facebookincubator/nimble. Facebook Incubator
work page 2024
-
[67]
M. Karpathiotakis, D. Wernli, and M. Stojanovic. (2019) Scribe: Transporting petabytes per hour via a distributed, buffered queueing system. https://engineering.fb.com/2019/10/07/core-infra/scribe/
work page 2019
-
[68]
5 ways Facebook improved compression at scale with Zstandard,
W. F. Handte, Y . Collet, and N. Terrell, “5 ways Facebook improved compression at scale with Zstandard,” 2018. [Online]. Available: https://engineering.fb.com/2018/12/19/core-infra/zstandard/
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.