Recognition: 2 theorem links
· Lean TheoremJODA: Composable Joint Dynamics for Articulated Objects
Pith reviewed 2026-05-12 04:20 UTC · model grok-4.3
The pith
JODA represents joint dynamics for articulated objects as a three-channel field capturing conservative forces, dry friction, and damping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
JODA generates joint-level dynamics as a structured three-channel field over the joint degree of freedom that captures conservative forces, dry friction, and damping; when instantiated with shape-constrained piecewise cubic interpolation, this yields a compact expressive function space that is interpretable and compatible with differentiable simulation, enabling inference of structured dynamical primitives from multimodal inputs, their composition into a unified field, and subsequent direct manipulation or gradient-based refinement.
What carries the argument
The JODA three-channel field over the joint degree of freedom, instantiated via shape-constrained piecewise cubic interpolation (PCHIP), that composes conservative forces, dry friction, and damping into a single dynamics profile.
If this is right
- Diverse joint behaviors become expressible and controllable through a single compact representation.
- Multimodal inference, editing, and optimization share the same differentiable interface.
- Joint dynamics can be refined by gradient descent without leaving the simulation loop.
- Realistic effects such as frictional holding and detents are modeled without hand-crafted per-joint equations.
Where Pith is reading between the lines
- The representation could be directly imported into existing physics engines to raise the fidelity of contact-rich manipulation tasks without increasing computational cost.
- Learned JODA profiles from one object class might transfer to similar mechanisms, reducing the need for per-instance data collection.
- Because the field is defined over a scalar degree of freedom, it could be composed with kinematic chains to simulate multi-joint systems such as robotic arms or folding mechanisms.
Load-bearing premise
A vision-language model can reliably propose structured dynamical primitives from visual observations and joint context which, when composed, accurately capture real-world joint behaviors.
What would settle it
Compare real-world motion traces of a physical joint (such as a door hinge or drawer slide) under known applied forces against the trajectories produced by a differentiable simulator driven by the JODA field inferred for that joint; systematic mismatch in holding torque, velocity decay, or snap behavior would falsify the claim.
Figures








read the original abstract
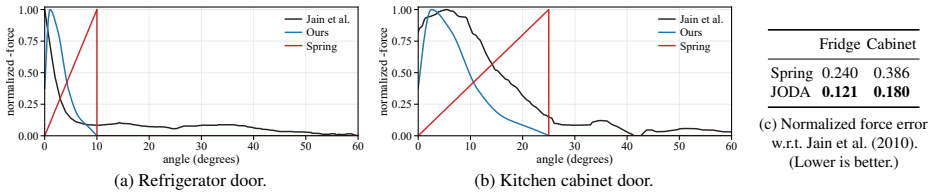
Articulated objects used in simulation and embodied AI are typically specified by geometry and kinematic structure, but lack the fine-grained dynamical effects that govern realistic mechanical behavior, such as frictional holding, detents, soft closing, and snap latching. Existing approaches either ignore the detailed structure of dynamics entirely, or use simple models with limited expressiveness. We introduce JODA, a framework for generating joint-level dynamics as a structured three-channel field over the joint degree of freedom, capturing conservative forces, dry friction, and damping. Instantiated using shape-constrained piecewise cubic interpolation (PCHIP), this formulation defines a compact and expressive function space that is both interpretable and compatible with differentiable simulation. Building on this representation, we develop methods for inferring and refining joint dynamics from multimodal inputs. Given visual observations and joint context, a vision-language model proposes structured dynamical primitives, which are composed into a unified dynamics field. The resulting representation supports both direct manipulation and gradient-based refinement. We demonstrate that JODA enables plausible and controllable modeling of diverse joint behaviors, providing a unified interface for inference, editing, and optimization. Code and example assets with their generated profiles will be released upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JODA, a framework for modeling joint-level dynamics in articulated objects as a structured three-channel field over the joint degree of freedom, capturing conservative forces, dry friction, and damping. The field is instantiated via shape-constrained piecewise cubic interpolation (PCHIP) to yield a compact, expressive, interpretable representation compatible with differentiable simulation. Inference proceeds by using a vision-language model to propose structured dynamical primitives from visual observations and joint context; these are composed into the unified field, which then supports direct editing and gradient-based optimization. The authors claim this enables plausible and controllable modeling of behaviors such as frictional holding, detents, soft closing, and snap latching.
Significance. If the VLM-driven inference and PCHIP composition can be shown to reproduce measured joint behavior, the work would supply a useful, unified interface for adding fine-grained, editable dynamics to kinematic models in robotics simulation and embodied AI. The emphasis on interpretability, composability, and differentiability could facilitate downstream tasks such as optimization and control that current simple friction or spring models do not support.
major comments (2)
- [Abstract] Abstract: the central claim that JODA 'enables plausible and controllable modeling of diverse joint behaviors' is asserted without any reported error metrics, torque-angle curve comparisons, baseline methods, or ablation studies on primitive selection. This absence leaves the effectiveness of the VLM proposal step unverified and makes the downstream editing/optimization claims impossible to assess.
- [Inference pipeline] Inference pipeline (described in the abstract and §3): the assumption that a vision-language model, given only visual observations and joint context, will reliably propose primitives whose PCHIP composition reproduces real-world effects (detents, bistable snap latching, frictional holding) is load-bearing for the entire framework. No quantitative validation against physical measurements is supplied; systematic mis-estimation of friction or missed bistable regions would invalidate the controllability and simulation-compatibility claims regardless of PCHIP expressiveness.
minor comments (1)
- [Representation] The three-channel field definition would be clearer if an explicit functional form or pseudocode for the composition of conservative, friction, and damping channels were provided in the main text rather than left to the supplementary material.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need to better substantiate the inference claims. We agree that the current manuscript relies on qualitative demonstrations and will revise the abstract, §3, and add supporting material to qualify the claims and illustrate the composed fields. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that JODA 'enables plausible and controllable modeling of diverse joint behaviors' is asserted without any reported error metrics, torque-angle curve comparisons, baseline methods, or ablation studies on primitive selection. This absence leaves the effectiveness of the VLM proposal step unverified and makes the downstream editing/optimization claims impossible to assess.
Authors: We acknowledge that the manuscript presents only qualitative demonstrations of behaviors such as frictional holding and snap latching via the composed PCHIP fields, without quantitative error metrics, baseline comparisons, or ablations. The emphasis is on the representation and inference pipeline rather than a benchmark evaluation. In revision we will (1) temper the abstract to 'supports plausible and controllable modeling of diverse joint behaviors via VLM-proposed primitives', (2) add torque-angle curve visualizations for the demonstrated examples, and (3) include a limited ablation on primitive composition choices in an appendix. Physical error metrics and full baseline studies would require new data collection and are noted as future work. revision: partial
-
Referee: [Inference pipeline] Inference pipeline (described in the abstract and §3): the assumption that a vision-language model, given only visual observations and joint context, will reliably propose primitives whose PCHIP composition reproduces real-world effects (detents, bistable snap latching, frictional holding) is load-bearing for the entire framework. No quantitative validation against physical measurements is supplied; systematic mis-estimation of friction or missed bistable regions would invalidate the controllability and simulation-compatibility claims regardless of PCHIP expressiveness.
Authors: The referee is correct that reliable primitive proposal is central. The manuscript describes the VLM as proposing structured dynamical primitives from visual and contextual input, which are then composed into the three-channel field; it does not claim exact reproduction of measured real-world dynamics. We will revise §3 to detail the prompting strategy, composition rules, and potential failure modes (e.g., missed bistable regions), and add simulated examples comparing the resulting fields to expected qualitative behaviors. We agree that without physical torque measurements the framework cannot be fully validated for simulation fidelity, and will explicitly state this limitation while noting that the PCHIP representation itself guarantees a differentiable, well-behaved field once primitives are supplied. revision: partial
- Quantitative validation of VLM-proposed primitives against physical joint torque measurements, as no such experimental data were collected for the current manuscript.
Circularity Check
No circularity in JODA framework derivation or claims
full rationale
The paper introduces JODA as a new three-channel field representation for joint dynamics, instantiated via PCHIP and inferred via VLM proposals from visual inputs. No equations, predictions, or first-principles results are presented that reduce by construction to fitted parameters, self-referential definitions, or self-citation chains. The central claims rest on the expressiveness of the proposed representation and compatibility with differentiable simulation, which are independent modeling choices rather than tautological outputs of prior steps. No self-citations appear load-bearing, and the demonstration of plausible modeling does not involve renaming known results or smuggling ansatzes. The derivation chain is self-contained as an original framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shape-constrained piecewise cubic interpolation (PCHIP) defines a compact, expressive, interpretable, and differentiable function space suitable for joint dynamics
invented entities (1)
-
Structured three-channel dynamics field (conservative forces, dry friction, damping)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce JODA, a framework for generating joint-level dynamics as a structured three-channel field over the joint degree of freedom, capturing conservative forces, dry friction, and damping. Instantiated using shape-constrained piecewise cubic interpolation (PCHIP)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a vision-language model proposes structured dynamical primitives, which are composed into a unified dynamics field
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Graphics , year =
Learning to Predict Part Mobility from a Single Static Snapshot , author =. ACM Transactions on Graphics , year =
-
[2]
and Yi, Li and Tripathi, Subarna and Guibas, Leonidas J
Mo, Kaichun and Zhu, Shilin and Chang, Angel X. and Yi, Li and Tripathi, Subarna and Guibas, Leonidas J. and Su, Hao , booktitle =. 2019 , url =
work page 2019
-
[3]
Xiang, Fanbo and Qin, Yuzhe and Mo, Kaichun and Xia, Yikuan and Zhu, Hao and Liu, Fangchen and Liu, Minghua and Jiang, Hanxiao and Yuan, Yifu and Wang, He and Yi, Li and Chang, Angel X. and Guibas, Leonidas J. and Su, Hao , booktitle =. 2020 , url =
work page 2020
-
[4]
Chen, Zoey and Walsman, Aaron and Memmel, Marius and Mo, Kaichun and Fang, Alex and Vemuri, Karthikeya and Wu, Alan and Fox, Dieter and Gupta, Abhishek , journal =. 2024 , url =
work page 2024
-
[5]
Mandi, Zhao and Weng, Yijia and Bauer, Dominik and Song, Shuran , booktitle =. 2025 , url =
work page 2025
-
[6]
International Conference on Learning Representations , year =
Articulate-Anything: Automatic Modeling of Articulated Objects via a Vision-Language Foundation Model , author =. International Conference on Learning Representations , year =
-
[7]
and Savva, Manolis and Mahdavi-Amiri, Ali , booktitle =
Liu, Jiayi and Iliash, Denys and Chang, Angel X. and Savva, Manolis and Mahdavi-Amiri, Ali , booktitle =. 2025 , url =
work page 2025
-
[8]
Gu, Jiayuan and Xiang, Fanbo and Li, Xuanlin and Ling, Zhan and Liu, Xiqiang and Mu, Tongzhou and Tang, Yihe and Tao, Stone and Wei, Xinyue and Yao, Yunchao and Yuan, Xiaodi and Xie, Pengwei and Huang, Zhiao and Chen, Rui and Su, Hao , journal =. 2023 , url =
work page 2023
-
[9]
Li, Chengshu and Zhang, Ruohan and Wong, Josiah and Gokmen, Cem and Srivastava, Sanjana and Martin-Martin, Roberto and Wang, Chen and Levine, Gabrael and Ai, Wensi and Martinez, Benjamin and others , journal =. 2024 , url =
work page 2024
-
[10]
Todorov, Emanuel and Erez, Tom and Tassa, Yuval , booktitle =. 2012 , url =
work page 2012
-
[11]
Makoviychuk, Viktor and Wawrzyniak, Lukasz and Guo, Yunrong and Lu, Michelle and Storey, Kier and Macklin, Miles and Hoeller, David and Rudin, Nikita and Allshire, Arthur and Handa, Ankur and State, Gavriel , journal =. 2021 , url =
work page 2021
-
[12]
Freeman, C. Daniel and Frey, Erik and Raichuk, Anton and Girgin, Sertan and Mordatch, Igor and Bachem, Olivier , booktitle =. 2021 , url =
work page 2021
-
[13]
Spark: Sim-ready part-level articulated reconstruction with vlm knowledge,
SPARK: Sim-ready Part-level Articulated Reconstruction with VLM Knowledge , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 2512.01629 , archivePrefix=
-
[14]
and Le Cleac'h, Simon and Brudigam, Jan and Chen, Qianzhong and Sun, Jiankai and Kolter, J
Howell, Taylor A. and Le Cleac'h, Simon and Brudigam, Jan and Chen, Qianzhong and Sun, Jiankai and Kolter, J. Zico and Schwager, Mac and Manchester, Zachary , journal =. 2022 , url =
work page 2022
-
[15]
Zakka, Kevin and Wu, Philipp and Smith, Laura and Gileadi, Nimrod and Howell, Taylor and Peng, Xue Bin and Singh, Sumeet and Tassa, Yuval and Florence, Pete and Zeng, Andy and Abbeel, Pieter , booktitle =. 2023 , url =
work page 2023
-
[16]
Conference on Robot Learning , year =
Learning to Open and Traverse Doors with a Legged Manipulator , author =. Conference on Robot Learning , year =
-
[17]
IEEE RAS/EMBS International Conference on Biomedical Robotics and Biomechatronics , year =
The Complex Structure of Simple Devices: A Survey of Trajectories and Forces that Open Doors and Drawers , author =. IEEE RAS/EMBS International Conference on Biomedical Robotics and Biomechatronics , year =
-
[18]
The Mechanics of Jointed Structures: Recent Research and Open Challenges for Developing Predictive Models for Structural Dynamics , editor =. 2018 , doi =
work page 2018
- [19]
-
[20]
Soft-Down and Lift Assist Stays: Lid Supports , author =. n.d. , url =
-
[21]
Non-smooth and Stiff Dynamics in Multibody Approaches Applied to Piano Action Simulation , author =. Meccanica , year =
-
[22]
Multibody-Based Piano Action: Validation of a Haptic Key , author =. Machines , volume =. 2020 , doi =
work page 2020
- [23]
-
[24]
DRAWER: Digital Reconstruction and Articulation With Environment Realism , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.