Recognition: 2 theorem links
· Lean TheoremOZ-TAL: Online Zero-Shot Temporal Action Localization
Pith reviewed 2026-05-12 02:43 UTC · model grok-4.3
The pith
A training-free framework using off-the-shelf vision-language models detects previously unseen actions in streaming videos online.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the OZ-TAL task for detecting previously unseen actions in an online fashion from untrimmed streaming videos. We propose a training-free framework that leverages off-the-shelf Vision-Language Models while introducing additional mechanisms to enhance visual representations and mitigate their inherent biases, establishing new benchmarks on THUMOS14 and ActivityNet-1.3 where it substantially outperforms existing state-of-the-art approaches under both offline and online zero-shot settings.
What carries the argument
The training-free framework that integrates off-the-shelf vision-language models with additional mechanisms for enhancing visual representations and mitigating biases.
Load-bearing premise
Off-the-shelf vision-language models plus unspecified additional mechanisms can reliably improve visual representations, reduce biases, and detect unseen actions in a true online streaming setting without any task-specific training.
What would settle it
A live streaming video containing actions outside the vision-language model's training distribution where the method's temporal localization accuracy falls below a simple baseline that ignores visual input.
Figures






read the original abstract
Online Temporal Action Localization (On-TAL) aims to detect the occurrence time and category of actions in untrimmed streaming videos immediately upon their completion. Recent advancements in this field focus on developing more sophisticated frameworks, shifting from Online Action Detection (OAD)-based aggregation paradigm to instance-level understanding. However, existing approaches are typically trained on specific domains and often exhibit limited generalization capabilities when applied to arbitrary videos, particularly in the presence of previously unseen actions. In this paper, we introduce a new task called Online Zero-shot Temporal Action Localization (OZ-TAL), which aims to detect previously unseen actions in an online fashion. Furthermore, we propose a training-free framework that leverages off-the-shelf Vision-Language Models (VLMs) while introducing additional mechanisms to enhance visual representations and mitigate their inherent biases. We establish new benchmarks and representative baselines for OZ-TAL on THUMOS14 and ActivityNet-1.3, and extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches under both offline and online zero-shot settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new task called Online Zero-Shot Temporal Action Localization (OZ-TAL) for detecting previously unseen actions in streaming videos. It proposes a training-free framework that uses off-the-shelf Vision-Language Models (VLMs) augmented with additional mechanisms to enhance visual representations and mitigate biases. New benchmarks and baselines are established on THUMOS14 and ActivityNet-1.3, with claims that the method substantially outperforms existing state-of-the-art approaches in both offline and online zero-shot settings.
Significance. If the training-free framework with the additional mechanisms can be shown to reliably handle unseen actions in a true online streaming setting, this would be a significant contribution to open-world temporal action localization by reducing reliance on task-specific training data and improving generalization. The introduction of the OZ-TAL task and associated benchmarks is a clear positive, as is the emphasis on leveraging existing VLMs to avoid training costs.
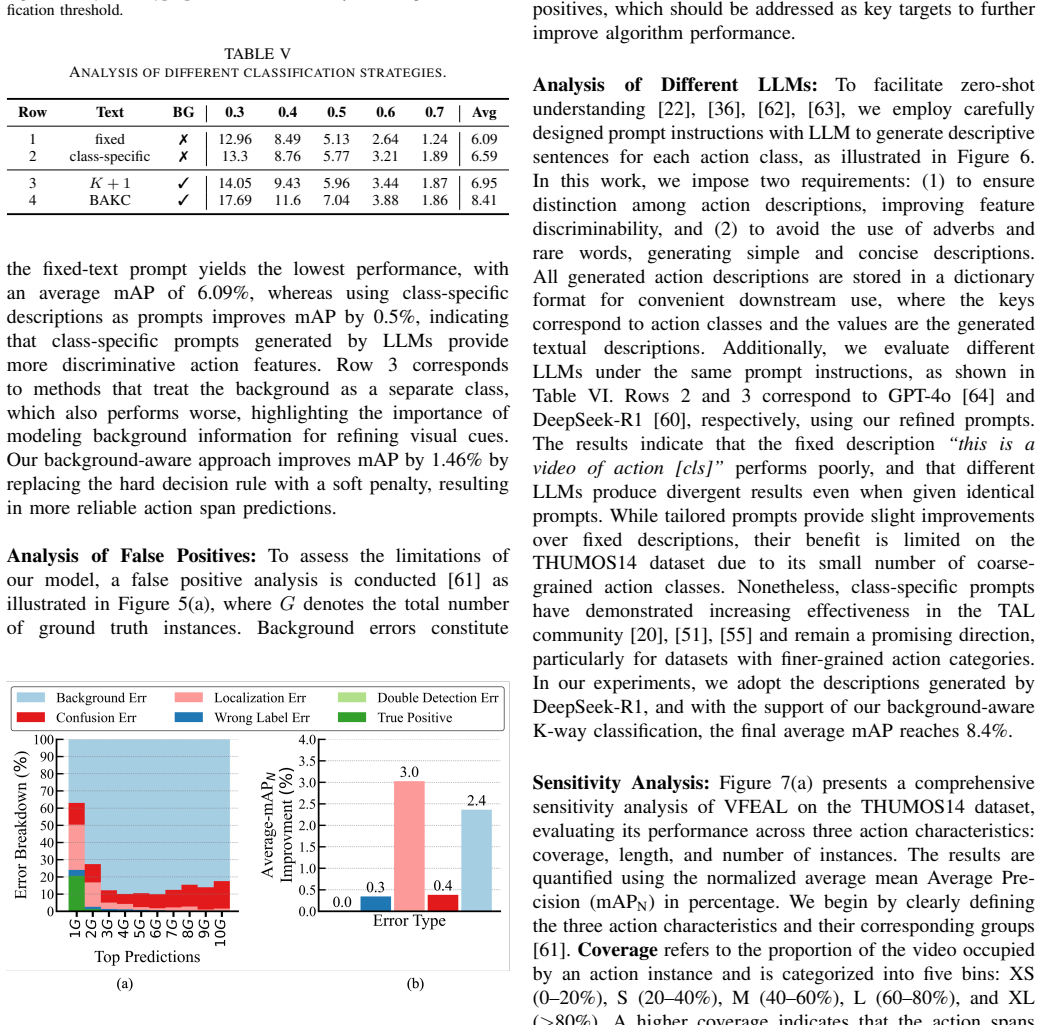
major comments (2)
- Abstract: The central claim that the method 'substantially outperforms existing state-of-the-art approaches under both offline and online zero-shot settings' is asserted without any quantitative metrics, tables, or specific results, which is load-bearing for evaluating the performance contribution.
- Methods (framework description): The 'additional mechanisms' to enhance visual representations and mitigate VLM biases are referenced but not detailed with algorithms, equations, pseudocode, or implementation specifics, preventing verification that the approach is strictly training-free and operates without lookahead in a streaming regime.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: The central claim that the method 'substantially outperforms existing state-of-the-art approaches under both offline and online zero-shot settings' is asserted without any quantitative metrics, tables, or specific results, which is load-bearing for evaluating the performance contribution.
Authors: The abstract is a concise summary; the full quantitative results, including mAP improvements over baselines on THUMOS14 and ActivityNet-1.3, appear in Tables 1-4 and the associated figures in the Experiments section. We will revise the abstract to incorporate a small number of key performance metrics to make the claim more self-contained. revision: yes
-
Referee: Methods (framework description): The 'additional mechanisms' to enhance visual representations and mitigate VLM biases are referenced but not detailed with algorithms, equations, pseudocode, or implementation specifics, preventing verification that the approach is strictly training-free and operates without lookahead in a streaming regime.
Authors: Section 3 details the visual enhancement and bias-mitigation components, which operate on frozen off-the-shelf VLMs with no task-specific training or parameter updates. The online pipeline processes the video stream frame-by-frame without access to future frames. We will add explicit pseudocode, equations, and implementation notes in the revision to facilitate verification. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces the OZ-TAL task and proposes a training-free framework that leverages existing off-the-shelf VLMs plus unspecified additional mechanisms for bias mitigation. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the provided text. Claims of outperformance rest on empirical benchmarks rather than any closed-loop mathematical reduction to the inputs themselves. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe propose a training-free framework that leverages off-the-shelf Vision-Language Models (VLMs) while introducing additional mechanisms to enhance visual representations and mitigate their inherent biases
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearMemory-Guided Feature Enhancement... Background-Aware K-way Classification... Online Action Span Prediction
Reference graph
Works this paper leans on
-
[1]
T. Yu, K. Fu, J. Zhang, Q. Huang, and J. Yu, “Multi-granularity con- trastive cross-modal collaborative generation for end-to-end long-term video question answering,”IEEE Transactions on Image Processing, vol. 33, pp. 3115–3129, 2024
work page 2024
-
[2]
Video moment retrieval with cross-modal neural architecture search,
X. Yang, S. Wang, J. Dong, J. Dong, M. Wang, and T.-S. Chua, “Video moment retrieval with cross-modal neural architecture search,”IEEE Transactions on Image Processing, vol. 31, pp. 1204–1216, 2022
work page 2022
-
[3]
G. Li, D. Cheng, N. Wang, J. Li, and X. Gao, “Neighbor-guided pseudo- label generation and refinement for single-frame supervised temporal action localization,”IEEE Transactions on Image Processing, vol. 33, pp. 2419–2430, 2024
work page 2024
-
[4]
Adaptive prototype learning for weakly-supervised temporal action localization,
W. Luo, H. Ren, T. Zhang, W. Yang, and Y . Zhang, “Adaptive prototype learning for weakly-supervised temporal action localization,”IEEE Transactions on Image Processing, vol. 34, pp. 3154–3168, 2024
work page 2024
-
[5]
M. Wu, C. Zhao, A. Su, D. Di, T. Fu, D. An, M. He, Y . Gao, M. Ma, K. Yanet al., “Hypergraph multi-modal large language model: Exploiting eeg and eye-tracking modalities to evaluate heterogeneous responses for video understanding,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 7316–7325
work page 2024
-
[6]
Efficient dual-confounding eliminating for weakly-supervised temporal action localization,
A. Li, H. Liu, J. Sheng, Z. Chen, and Y . Ge, “Efficient dual-confounding eliminating for weakly-supervised temporal action localization,” inPro- ceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 8179–8188
work page 2024
-
[7]
Online temporal action local- ization with memory-augmented transformer,
Y . Song, D. Kim, M. Cho, and S. Kwak, “Online temporal action local- ization with memory-augmented transformer,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 74–91
work page 2024
-
[8]
Hat: History- augmented anchor transformer for online temporal action localization,
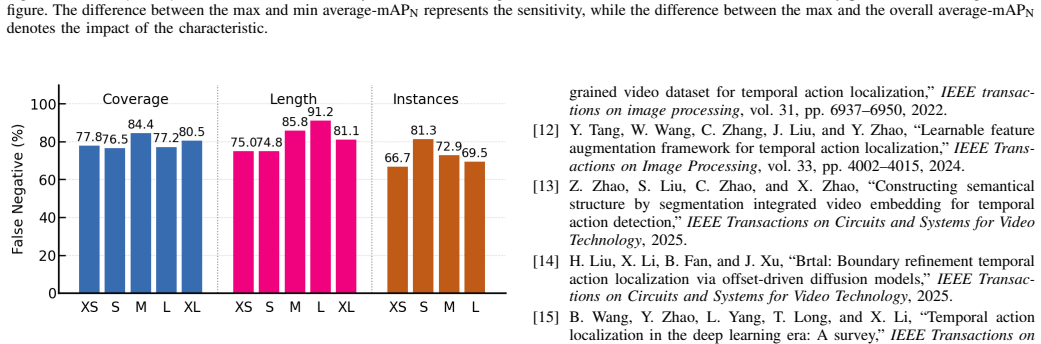
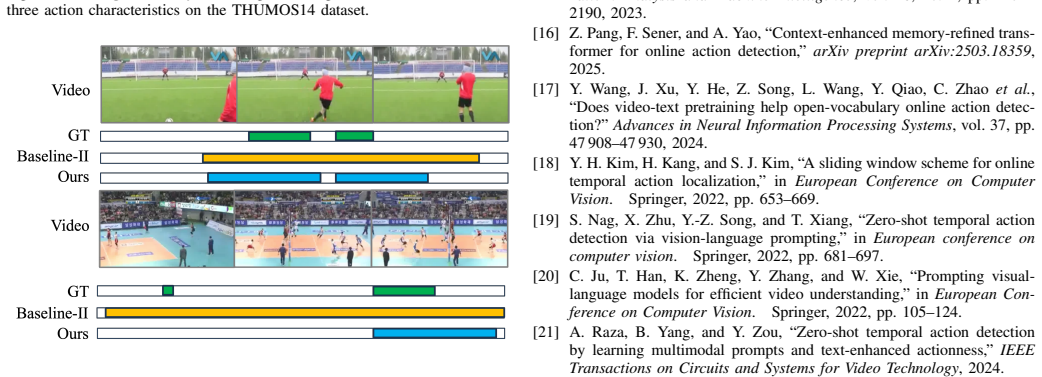
S. Reza, Y . Zhang, M. Moghaddam, and O. Camps, “Hat: History- augmented anchor transformer for online temporal action localization,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 205– 222. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10 Fig. 7.Sensitivity analysis of VFEAL.(a) Sensivity of VFEAL’s average mAP to action charac...
work page 2024
-
[9]
Actionswitch: Class- agnostic detection of simultaneous actions in streaming videos,
H. Kang, J. Hyun, J. An, Y . Yu, and S. J. Kim, “Actionswitch: Class- agnostic detection of simultaneous actions in streaming videos,” in European Conference on Computer Vision. Springer, 2024, pp. 383– 400
work page 2024
-
[10]
A temporal-aware relation and attention network for temporal action localization,
Y . Zhao, H. Zhang, Z. Gao, W. Guan, J. Nie, A. Liu, M. Wang, and S. Chen, “A temporal-aware relation and attention network for temporal action localization,”IEEE Transactions on Image Processing, vol. 31, pp. 4746–4760, 2022
work page 2022
-
[11]
Fineaction: A fine- grained video dataset for temporal action localization,
Y . Liu, L. Wang, Y . Wang, X. Ma, and Y . Qiao, “Fineaction: A fine- grained video dataset for temporal action localization,”IEEE transac- tions on image processing, vol. 31, pp. 6937–6950, 2022
work page 2022
-
[12]
Learnable feature augmentation framework for temporal action localization,
Y . Tang, W. Wang, C. Zhang, J. Liu, and Y . Zhao, “Learnable feature augmentation framework for temporal action localization,”IEEE Trans- actions on Image Processing, vol. 33, pp. 4002–4015, 2024
work page 2024
-
[13]
Z. Zhao, S. Liu, C. Zhao, and X. Zhao, “Constructing semantical structure by segmentation integrated video embedding for temporal action detection,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[14]
Brtal: Boundary refinement temporal action localization via offset-driven diffusion models,
H. Liu, X. Li, B. Fan, and J. Xu, “Brtal: Boundary refinement temporal action localization via offset-driven diffusion models,”IEEE Transac- tions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[15]
Temporal action localization in the deep learning era: A survey,
B. Wang, Y . Zhao, L. Yang, T. Long, and X. Li, “Temporal action localization in the deep learning era: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 4, pp. 2171– 2190, 2023
work page 2023
-
[16]
Context-enhanced memory-refined trans- former for online action detection,
Z. Pang, F. Sener, and A. Yao, “Context-enhanced memory-refined trans- former for online action detection,”arXiv preprint arXiv:2503.18359, 2025
-
[17]
Does video-text pretraining help open-vocabulary online action detec- tion?
Y . Wang, J. Xu, Y . He, Z. Song, L. Wang, Y . Qiao, C. Zhaoet al., “Does video-text pretraining help open-vocabulary online action detec- tion?”Advances in Neural Information Processing Systems, vol. 37, pp. 47 908–47 930, 2024
work page 2024
-
[18]
A sliding window scheme for online temporal action localization,
Y . H. Kim, H. Kang, and S. J. Kim, “A sliding window scheme for online temporal action localization,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 653–669
work page 2022
-
[19]
Zero-shot temporal action detection via vision-language prompting,
S. Nag, X. Zhu, Y .-Z. Song, and T. Xiang, “Zero-shot temporal action detection via vision-language prompting,” inEuropean conference on computer vision. Springer, 2022, pp. 681–697
work page 2022
-
[20]
Prompting visual- language models for efficient video understanding,
C. Ju, T. Han, K. Zheng, Y . Zhang, and W. Xie, “Prompting visual- language models for efficient video understanding,” inEuropean Con- ference on Computer Vision. Springer, 2022, pp. 105–124
work page 2022
-
[21]
Zero-shot temporal action detection by learning multimodal prompts and text-enhanced actionness,
A. Raza, B. Yang, and Y . Zou, “Zero-shot temporal action detection by learning multimodal prompts and text-enhanced actionness,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[22]
Temporal action detection model compression by progressive block drop,
X. Chen, Y . Guo, J. Liang, S. Zhuang, R. Zeng, and X. Hu, “Temporal action detection model compression by progressive block drop,”arXiv preprint arXiv:2503.16916, 2025
-
[23]
Boundary denoising for video activity localization,
M. Xu, M. Soldan, J. Gao, S. Liu, J. P ´erez-R´ua, and B. Ghanem, “Boundary denoising for video activity localization,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
work page 2024
-
[24]
Benchmarking the robustness of temporal action detection models against temporal corruptions,
R. Zeng, X. Chen, J. Liang, H. Wu, G. Cao, and Y . Guo, “Benchmarking the robustness of temporal action detection models against temporal corruptions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 263–18 274
work page 2024
-
[25]
Unimd: Towards unifying mo- ment retrieval and temporal action detection,
Y . Zeng, Y . Zhong, C. Feng, and L. Ma, “Unimd: Towards unifying mo- ment retrieval and temporal action detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 286–304. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
work page 2024
-
[26]
Adapting short-term trans- formers for action detection in untrimmed videos,
M. Yang, H. Gao, P. Guo, and L. Wang, “Adapting short-term trans- formers for action detection in untrimmed videos,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 18 570–18 579
work page 2024
-
[27]
End-to-end temporal action detection with 1b parameters across 1000 frames,
S. Liu, C.-L. Zhang, C. Zhao, and B. Ghanem, “End-to-end temporal action detection with 1b parameters across 1000 frames,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 18 591–18 601
work page 2024
-
[28]
Dual detrs for multi-label temporal action detection,
Y . Zhu, G. Zhang, J. Tan, G. Wu, and L. Wang, “Dual detrs for multi-label temporal action detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 559–18 569
work page 2024
-
[29]
Dyfadet: Dynamic feature aggregation for temporal action detection,
L. Yang, Z. Zheng, Y . Han, H. Cheng, S. Song, G. Huang, and F. Li, “Dyfadet: Dynamic feature aggregation for temporal action detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 305– 322
work page 2024
-
[30]
2pesnet: Towards online processing of temporal action localization,
Y . H. Kim, S. Nam, and S. J. Kim, “2pesnet: Towards online processing of temporal action localization,”Pattern Recognition, vol. 131, p. 108871, 2022
work page 2022
-
[31]
E2e-load: end-to- end long-form online action detection,
S. Cao, W. Luo, B. Wang, W. Zhang, and L. Ma, “E2e-load: end-to- end long-form online action detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 422–10 432
work page 2023
-
[32]
Miniroad: Minimal rnn framework for online action detection,
J. An, H. Kang, S. H. Han, M.-H. Yang, and S. J. Kim, “Miniroad: Minimal rnn framework for online action detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 341–10 350
work page 2023
-
[33]
Colar: Effective and efficient on- line action detection by consulting exemplars,
L. Yang, J. Han, and D. Zhang, “Colar: Effective and efficient on- line action detection by consulting exemplars,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3160–3169
work page 2022
-
[34]
H. Kang, K. Kim, Y . Ko, and S. J. Kim, “Cag-qil: Context-aware actionness grouping via q imitation learning for online temporal action localization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 729–13 738
work page 2021
-
[35]
Simon: a simple framework for online temporal action localization,
T. N. Tang, J. Park, K. Kim, and K. Sohn, “Simon: a simple framework for online temporal action localization,”arXiv preprint arXiv:2211.04905, 2022
-
[36]
Zstad: Zero-shot temporal activity detection,
L. Zhang, X. Chang, J. Liu, M. Luo, S. Wang, Z. Ge, and A. Hauptmann, “Zstad: Zero-shot temporal activity detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 879–888
work page 2020
-
[37]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,”arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[38]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[39]
Tn-zstad: Transferable network for zero-shot temporal activity detec- tion,
L. Zhang, X. Chang, J. Liu, M. Luo, Z. Li, L. Yao, and A. Hauptmann, “Tn-zstad: Transferable network for zero-shot temporal activity detec- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3848–3861, 2022
work page 2022
-
[40]
Test-time zero-shot temporal action localization,
B. Liberatori, A. Conti, P. Rota, Y . Wang, and E. Ricci, “Test-time zero-shot temporal action localization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 18 720–18 729
work page 2024
-
[41]
Coca: Con- trastive captioners are image-text foundation models
J. Yu, Z. Wang, V . Vasudevan, L. Yeung, M. Seyedhosseini, and Y . Wu, “Coca: Contrastive captioners are image-text foundation models,”arXiv preprint arXiv:2205.01917, 2022
-
[42]
Palm: Scal- ing language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmannet al., “Palm: Scal- ing language modeling with pathways,”Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023
work page 2023
-
[43]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,”arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
work page 2022
-
[47]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
work page 2023
-
[48]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 296–26 306
work page 2024
-
[49]
Sharegpt4video: Improving video understanding and generation with better captions,
L. Chen, X. Wei, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, Z. Tang, L. Yuanet al., “Sharegpt4video: Improving video understanding and generation with better captions,”Advances in Neural Information Processing Systems, vol. 37, pp. 19 472–19 495, 2024
work page 2024
-
[50]
VideoChat: Chat-Centric Video Understanding
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao, “Videochat: Chat-centric video understanding,”arXiv preprint arXiv:2305.06355, 2023
work page internal anchor Pith review arXiv 2023
-
[51]
Detal: open- vocabulary temporal action localization with decoupled networks,
Z. Li, Y . Zhong, R. Song, T. Li, L. Ma, and W. Zhang, “Detal: open- vocabulary temporal action localization with decoupled networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[52]
Text-infused attention and foreground-aware modeling for zero-shot temporal action detection,
Y . Lee, H.-J. Kim, and S.-W. Lee, “Text-infused attention and foreground-aware modeling for zero-shot temporal action detection,” Advances in Neural Information Processing Systems, vol. 37, pp. 9864– 9884, 2024
work page 2024
-
[53]
Internvid: A large-scale video-text dataset for multimodal understanding and generation
Y . Wang, Y . He, Y . Li, K. Li, J. Yu, X. Ma, X. Li, G. Chen, X. Chen, Y . Wanget al., “Internvid: A large-scale video-text dataset for multi- modal understanding and generation,”arXiv preprint arXiv:2307.06942, 2023
-
[54]
Vita-clip: Video and text adaptive clip via multimodal prompting,
S. T. Wasim, M. Naseer, S. Khan, F. S. Khan, and M. Shah, “Vita-clip: Video and text adaptive clip via multimodal prompting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023, pp. 23 034–23 044
work page 2023
-
[55]
An information compensation framework for zero-shot skeleton-based action recognition,
H. Xu, Y . Gao, J. Li, and X. Gao, “An information compensation framework for zero-shot skeleton-based action recognition,”IEEE Trans- actions on Multimedia, 2025
work page 2025
-
[56]
End-to-end spatio-temporal action localisation with video transformers,
A. A. Gritsenko, X. Xiong, J. Djolonga, M. Dehghani, C. Sun, M. Lu- cic, C. Schmid, and A. Arnab, “End-to-end spatio-temporal action localisation with video transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 373–18 383
work page 2024
-
[57]
Semantics guided contrastive learning of transformers for zero-shot temporal activity detection,
S. Nag, O. Goldstein, and A. K. Roy-Chowdhury, “Semantics guided contrastive learning of transformers for zero-shot temporal activity detection,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 6243–6253
work page 2023
-
[58]
The thumos challenge on action recognition for videos “in the wild
H. Idrees, A. R. Zamir, Y .-G. Jiang, A. Gorban, I. Laptev, R. Sukthankar, and M. Shah, “The thumos challenge on action recognition for videos “in the wild”,”Computer Vision and Image Understanding, vol. 155, pp. 1–23, 2017
work page 2017
-
[59]
Activitynet: A large-scale video benchmark for human activity under- standing,
F. Caba Heilbron, V . Escorcia, B. Ghanem, and J. Carlos Niebles, “Activitynet: A large-scale video benchmark for human activity under- standing,” inProceedings of the ieee conference on computer vision and pattern recognition, 2015, pp. 961–970
work page 2015
-
[60]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Diagnosing error in temporal action detectors,
H. Alwassel, F. C. Heilbron, V . Escorcia, and B. Ghanem, “Diagnosing error in temporal action detectors,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 256–272
work page 2018
-
[62]
A review of generalized zero-shot learning meth- ods,
F. Pourpanah, M. Abdar, Y . Luo, X. Zhou, R. Wang, C. P. Lim, X.-Z. Wang, and Q. J. Wu, “A review of generalized zero-shot learning meth- ods,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 4, pp. 4051–4070, 2022
work page 2022
-
[63]
Towards open vocabulary learning: A survey,
J. Wu, X. Li, S. Xu, H. Yuan, H. Ding, Y . Yang, X. Li, J. Zhang, Y . Tong, X. Jianget al., “Towards open vocabulary learning: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 5092–5113, 2024
work page 2024
-
[64]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.