Recognition: 2 theorem links
· Lean TheoremFederated Language Models Under Bandwidth Budgets: Distillation Rates and Conformal Coverage
Pith reviewed 2026-05-12 02:53 UTC · model grok-4.3
The pith
Federated language models achieve explicit high-probability KL-consistency and distribution-free coverage bounds even when each node faces a hard bandwidth budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We obtain a high-probability KL-consistency rate for FPLD that depends simultaneously on K nodes, n samples per node, quantization budget B, probe-set size m, and vocabulary V, with bandwidth appearing only through an exponentially small quantization term. For FC-RAG we prove a distribution-free marginal coverage bound whose novel retrieval-bandwidth slack is given by f_max times the square root of K to the minus two times the sum over nodes of v(B_i); arithmetic aggregation over nodes therefore shrinks the slack as K to the minus one-half under uniform per-node budgets. A Pinsker-type corollary composes the training consistency and inference calibration into an end-to-end coverage guarantee
What carries the argument
Federated Probe-Logit Distillation (FPLD) for training and Federated Conformal RAG (FC-RAG) for inference, together with the retrieval-bandwidth slack term Delta_RAG that makes per-node bandwidth a first-class parameter in the coverage bound.
If this is right
- The exponentially vanishing quantization term implies that modest per-node bandwidths already suffice for near-centralized training consistency.
- The K to the minus one-half shrinkage of the coverage slack shows that adding more nodes improves statistical guarantees even if each node's retrieval budget stays fixed.
- The end-to-end coverage guarantee obtained by composing the two bounds lets practitioners allocate bandwidth between training and inference stages to meet a target coverage level.
- The predicted scaling laws can be verified directly on synthetic data by varying K, n, B, m, and V one at a time.
Where Pith is reading between the lines
- The same slack construction could be applied to other federated inference tasks that combine retrieval with conformal calibration.
- The explicit dependence on B suggests a practical design rule: set quantization bits so the exponential penalty is smaller than the target statistical error.
- Because bandwidth now appears inside the coverage bound, system designers can treat communication cost as an explicit knob when optimizing for both accuracy and coverage.
- The framework leaves open whether similar rates hold for non-exchangeable data streams that arise in online federated settings.
Load-bearing premise
The data distributions across nodes satisfy the conditions needed for the underlying concentration inequalities and conformal exchangeability to hold, and the Pinsker-type composition is valid.
What would settle it
Run the synthetic scaling experiments while systematically varying only the per-node quantization budget B and check whether the observed KL divergence fails to decrease at the predicted exponential rate or whether the empirical coverage for FC-RAG falls below the stated bound when retrieval bandwidths differ across nodes.
Figures

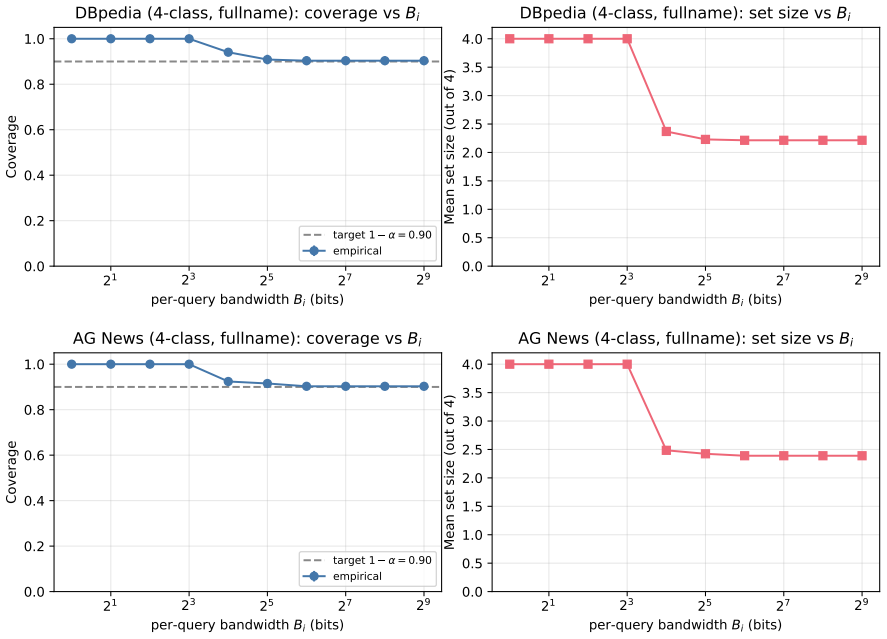
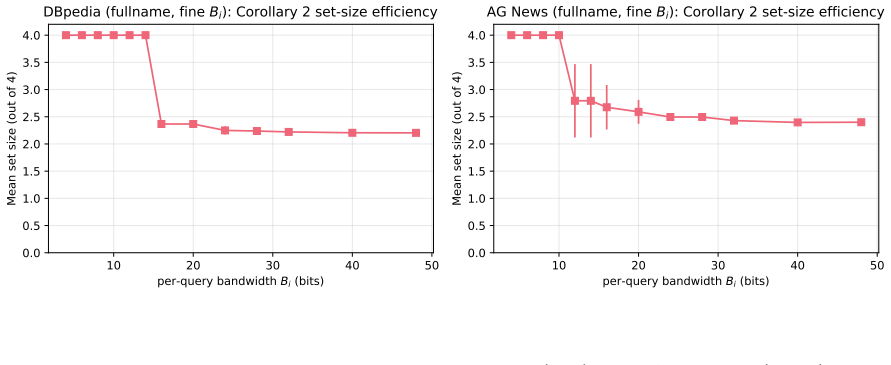
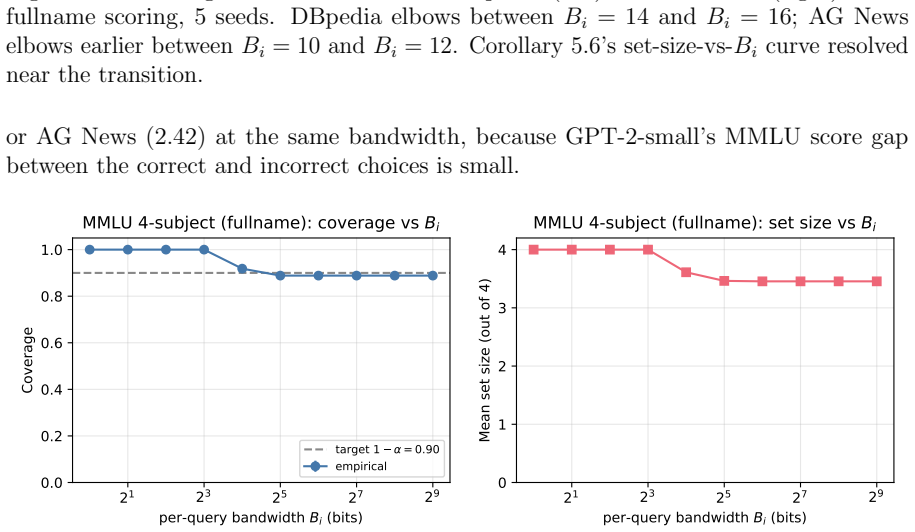
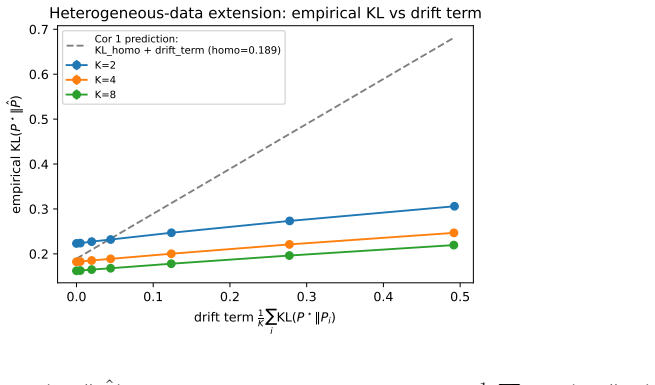


read the original abstract
Training a language model on data scattered across bandwidth-limited nodes that cannot be centralized is a setting that arises in clinical networks, enterprise knowledge bases, and scientific consortia. We study the regime in which data must remain distributed across nodes, and ask what statistical guarantees are in principle achievable under explicit bandwidth budgets; we aim to characterize what is provably possible, not to demonstrate a deployment-ready system. Existing theory treats either training-time consistency or inference-time calibration in isolation, and none makes bandwidth a first-class statistical parameter. We analyze two protocols, Federated Probe-Logit Distillation (FPLD) for training and Federated Conformal RAG (FC-RAG) for inference, as the analytical vehicles for our results. Our first main result is an explicit high-probability KL-consistency rate for FPLD with simultaneous dependence on node count $K$, per-node sample size $n$, quantization budget $B$, probe-set size $m$, and vocabulary size $V$; bandwidth enters only through an exponentially vanishing quantization term. Our second main result is a distribution-free marginal-coverage bound for FC-RAG, whose novel retrieval-bandwidth slack $\Delta_{\mathrm{RAG}} = f_{\max}\sqrt{K^{-2}\sum_i v(B_i)}$ makes per-node retrieval bandwidth a first-class statistical parameter, with arithmetic aggregation across $K$ nodes shrinking the slack as $K^{-1/2}$ in the per-node-uniform regime. A Pinsker-type corollary composes the two bounds into an end-to-end coverage guarantee. Synthetic experiments verify the predicted scaling along the bounds' parameters; small-scale experiments on a GPT-2 testbed illustrate that the qualitative bandwidth-accuracy tradeoff survives on a real language model. A deployment-scale empirical evaluation is out of scope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes federated language model training and inference under explicit bandwidth budgets using two protocols: Federated Probe-Logit Distillation (FPLD) for training and Federated Conformal RAG (FC-RAG) for inference. It claims an explicit high-probability KL-consistency rate for FPLD depending simultaneously on node count K, per-node samples n, quantization budget B, probe-set size m, and vocabulary size V, with bandwidth entering only via an exponentially vanishing term. For FC-RAG it claims a distribution-free marginal coverage bound whose novel slack is Δ_RAG = f_max √(K^{-2} ∑_i v(B_i)), which shrinks as K^{-1/2} under uniform per-node bandwidth. A Pinsker-type corollary is asserted to compose the two into an end-to-end coverage guarantee. Synthetic experiments are said to verify the predicted scaling; small-scale GPT-2 experiments illustrate the bandwidth-accuracy tradeoff.
Significance. If the derivations are rigorous and the necessary assumptions hold, the work is significant for treating bandwidth as a first-class statistical parameter rather than a mere implementation constraint. The simultaneous multi-parameter rate for FPLD and the explicit retrieval-bandwidth slack in the FC-RAG coverage bound provide concrete, falsifiable scaling predictions that could inform protocol design in distributed clinical or enterprise settings. The attempt to compose training consistency and conformal inference guarantees via Pinsker is analytically novel in this domain.
major comments (1)
- [Abstract (and the corollary statement)] Abstract (Pinsker-type corollary): The end-to-end coverage guarantee is obtained by converting the high-probability KL bound into a total-variation distance via Pinsker and then controlling the deviation of the coverage indicator. This step requires the nonconformity score (which depends on bandwidth-limited retrieved contexts) to be bounded or Lipschitz with respect to the model output; without such a condition the coverage deviation can be as large as the TV distance itself. The manuscript does not state or verify this boundedness/Lipschitz assumption, nor does it specify how the high-probability KL event is intersected with the coverage event. This is load-bearing for the claim that the slack is controlled solely by the stated Δ_RAG term.
minor comments (2)
- [Abstract] The function v(B_i) appearing in Δ_RAG is not defined in the abstract; its meaning (e.g., variance or volume term) should be stated explicitly when the slack is introduced.
- [Abstract] The abstract asserts that 'synthetic experiments verify the predicted scaling along the bounds' parameters' but does not indicate which parameters are varied, what quantitative metrics are used, or how the empirical coverage is compared to the theoretical slack.
Simulated Author's Rebuttal
Thank you for the thorough review and positive assessment of the work's significance. We address the single major comment point-by-point below and will incorporate the necessary clarifications in the revised manuscript.
read point-by-point responses
-
Referee: Abstract (Pinsker-type corollary): The end-to-end coverage guarantee is obtained by converting the high-probability KL bound into a total-variation distance via Pinsker and then controlling the deviation of the coverage indicator. This step requires the nonconformity score (which depends on bandwidth-limited retrieved contexts) to be bounded or Lipschitz with respect to the model output; without such a condition the coverage deviation can be as large as the TV distance itself. The manuscript does not state or verify this boundedness/Lipschitz assumption, nor does it specify how the high-probability KL event is intersected with the coverage event. This is load-bearing for the claim that the slack is controlled solely by the stated Δ_RAG term.
Authors: We appreciate this observation, which identifies a gap in the explicit statement of assumptions for the corollary. The nonconformity score in FC-RAG is the negative log-likelihood of the response token given the query and retrieved contexts, which is bounded in [0, log V] for vocabulary size V. This boundedness implies that the difference in expected scores under two distributions is at most log(V) times the total variation distance. We will add this as a standing assumption in the revised paper and derive the Lipschitz constant explicitly. For the event intersection, the KL-consistency event holds with probability at least 1-δ (from the FPLD theorem) and the conformal coverage holds with probability at least 1-δ (from the standard conformal theorem, conditional on the model), so their intersection holds with probability at least 1-2δ by the union bound. On this event, the coverage slack is bounded by the Pinsker-converted TV term plus Δ_RAG. We will revise the abstract, the corollary statement in Section 4, and add a remark clarifying the composition. This revision clarifies but does not change the technical claims. revision: yes
Circularity Check
No significant circularity; bounds derived from standard inequalities
full rationale
The paper states explicit high-probability KL-consistency rates for FPLD (depending on K, n, B, m, V with exponential quantization term) and distribution-free marginal coverage for FC-RAG (with slack Δ_RAG = f_max √(K^{-2} ∑ v(B_i))), composed via a Pinsker-type corollary. These are presented as derived from concentration tools and Pinsker's inequality applied to the new protocols. No self-definitional reductions, fitted inputs renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the stated results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-probability bounds hold under standard concentration assumptions for federated settings
- standard math Distribution-free marginal coverage property of conformal prediction
invented entities (2)
-
Federated Probe-Logit Distillation (FPLD)
no independent evidence
-
Federated Conformal RAG (FC-RAG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearA Pinsker-type corollary composes the two bounds into an end-to-end coverage guarantee... Δ_train = f_max (KL + √(2 KL))
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclearquantization budget B... exponentially vanishing quantization term... 2^{-2B/V}
Reference graph
Works this paper leans on
-
[1]
van der Vaart, A. W. , title =. 2000 , series =
work page 2000
-
[2]
and Mendelson, Shahar , title =
Bartlett, Peter L. and Mendelson, Shahar , title =. Journal of Machine Learning Research , volume =. 2002 , url =
work page 2002
- [3]
-
[4]
Vovk, Vladimir and Gammerman, Alexander and Shafer, Glenn , title =. 2005 , isbn =
work page 2005
-
[5]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Lei, Jing and Wasserman, Larry , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2014 , publisher =
work page 2014
- [6]
-
[7]
Shamir, Ohad and Srebro, Nathan , title =. 2014 52nd Annual Allerton Conference on Communication, Control, and Computing (Allerton) , publisher =. 2014 , doi =
work page 2014
-
[8]
Yuchen Zhang and John C. Duchi and Martin J. Wainwright , title =. Journal of Machine Learning Research , year =
-
[9]
Mathematical Programming , volume =
Huang, Cheng and Huo, Xiaoming , title =. Mathematical Programming , volume =. 2019 , publisher =
work page 2019
- [10]
-
[11]
Advances in Neural Information Processing Systems , editor =
Lin, Tao and Kong, Lingjing and Stich, Sebastian U and Jaggi, Martin , title =. Advances in Neural Information Processing Systems , editor =. 2020 , url =
work page 2020
-
[12]
Advances in Neural Information Processing Systems , year =
Li, Yichen and Wang, Xiuying and Xu, Wenchao and Wang, Haozhao and Qi, Yining and Dong, Jiahua and Li, Ruixuan , title =. Advances in Neural Information Processing Systems , year =
-
[13]
Nature Communications , volume =
Wu, Chuhan and Wu, Fangzhao and Lyu, Lingjuan and Huang, Yongfeng and Xie, Xing , title =. Nature Communications , volume =. 2022 , publisher =
work page 2022
-
[14]
Yao, Yuhang and Zhang, Jianyi and Wu, Junda and Huang, Chengkai and Xia, Yu and Yu, Tong and Zhang, Ruiyi and Kim, Sungchul and Rossi, Ryan and Li, Ang and Yao, Lina and McAuley, Julian and Chen, Yiran and Joe-Wong, Carlee , title =. 2025 , eprint =
work page 2025
-
[15]
Li, Shuo and Park, Sangdon and Lee, Insup and Bastani, Osbert , title =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , month = jun, year =. doi:10.18653/v1/2024.naacl-long.210 , pages =
-
[16]
Feng, Naihe and Sui, Yi and Hou, Shiyi and Cresswell, Jesse C. and Wu, Ga , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , series =. 2025 , doi =
work page 2025
-
[17]
Advances in Information Retrieval , publisher =
Chakraborty, Debashish and Yang, Eugene and Khashabi, Daniel and Lawrie, Dawn and Duh, Kevin , title =. Advances in Information Retrieval , publisher =. 2026 , isbn =
work page 2026
-
[18]
Wen, Haifeng and Simeone, Osvaldo and Xing, Hong , title =. 2026 , eprint =
work page 2026
-
[19]
Xu, Rui and Chen, Xingyuan and Huang, Wenxing and Huang, Minxuan and Xie, Yun and Chen, Weiyan and Xie, Sihong , title =. 2025 , eprint =
work page 2025
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.