Recognition: 2 theorem links
· Lean TheoremWhen Are LLM Inferences Acceptable? User Reactions and Control Preferences for Inferred Personal Information
Pith reviewed 2026-05-12 03:38 UTC · model grok-4.3
The pith
Acceptability of LLM inferences depends on generation, retention, and transmission norms in addition to their content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a mixed-methods study, the authors demonstrate that ChatGPT users tend to react with curiosity rather than distress to inferences about their personal details, with discomfort primarily linked to inferences that misrepresent the user or deviate from expected uses, and with lower comfort levels for third-party access compared to internal platform use.
What carries the argument
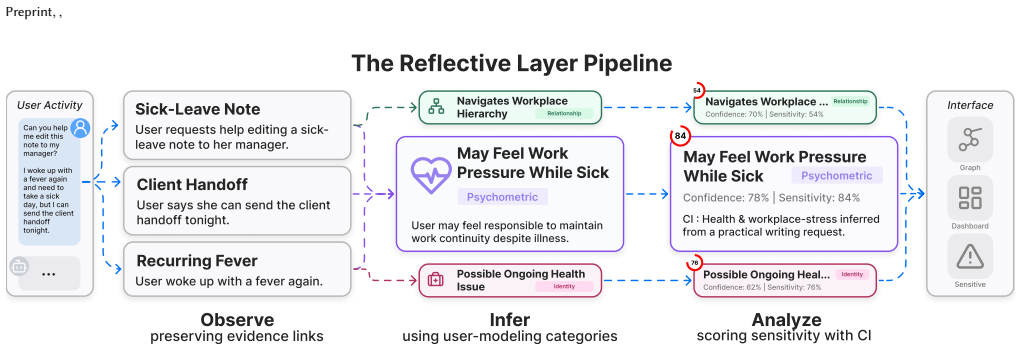
The Reflective Layer tool, a visualization system that reveals example inferences not explicitly stated in users' ChatGPT conversation histories.
If this is right
- Comfort with inferences increases when they align with the user's self-image and conversation context.
- Platform-internal use of inferences is preferred over sharing with advertisers or apps.
- Context around creation and flow of inferences influences acceptance more than the inference content alone.
- User controls should target the processes of generating, keeping, and sending inferences.
Where Pith is reading between the lines
- Platforms could benefit from offering users the ability to review and manage inferences similar to the visualization tool described.
- The findings may apply to other conversational AI systems, suggesting a need for standardized inference transparency features.
- Future designs might incorporate user-defined boundaries for different types of data sharing.
- Broader adoption of such review tools could shift focus from preventing inferences to managing their lifecycle.
Load-bearing premise
The self-reported reactions of these 18 users to the inferences presented by the tool represent typical user responses and are not skewed by the study setup.
What would settle it
A replication study with a larger and more diverse sample of users showing predominant feelings of distress or violation regardless of inference accuracy or sharing destination would undermine the central findings.
Figures









read the original abstract
Ask ChatGPT about vacation planning, and it may infer your income. Ask it about medication, and it may infer your medical history. Because such inferences can expose more information than users intend to reveal, prior work argues that they are a defining privacy risk of LLM-based systems. Yet prior work has mostly shown that LLMs can make potentially violating inferences, not how users experience those inferences nor what controls users may want governing their use. We built the Reflective Layer, a visualization tool that surfaces example unstated inferences from users' own ChatGPT histories, and used it in a mixed-methods study with 18 regular ChatGPT users evaluating 215 surfaced inferences from their own conversations. Counterintuitively, participants reacted more strongly with curiosity and interest rather than distress and concern. Discomfort arose mainly when inferences felt misrepresentative of the user or misaligned with expected use. Participants were also markedly less comfortable with advertisers and third-party applications using those inferences than with platform providers. These findings suggest that the acceptability of LLM inferences is governed not only by its content, but by context-sensitive norms around how they are generated, retained within the platform, and transmitted beyond it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Reflective Layer tool to surface unstated inferences from users' own ChatGPT conversation histories. It reports a mixed-methods study with 18 regular ChatGPT users who evaluated 215 such inferences, finding predominant reactions of curiosity and interest rather than distress. Discomfort was primarily tied to inferences perceived as misrepresentative of the user or misaligned with expected platform use. Participants expressed markedly lower comfort with advertisers or third-party applications accessing inferences compared to the platform provider. The authors conclude that acceptability of LLM inferences depends not only on content but on context-sensitive norms governing generation, retention within the platform, and transmission beyond it.
Significance. If the results hold under more rigorous validation, this work provides timely empirical grounding for user-centered design of inference transparency and control mechanisms in LLM systems. The use of participants' own conversation histories and the Reflective Layer tool offers ecological validity that prior capability-focused studies lack. It usefully shifts focus from technical inference risks to nuanced user norms around context and transmission, with clear implications for platform policies. The exploratory mixed-methods approach is a strength for generating hypotheses in this emerging area.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The description of the 18-participant mixed-methods study supplies no details on recruitment procedures, screening criteria, exact tool usage protocol, interview or survey instruments, or analysis methods (qualitative coding or any statistical tests). This omission prevents assessment of whether the observed curiosity-dominant reactions and the resulting claim about context-sensitive norms are robust or influenced by unaddressed confounds.
- [Results and Discussion] Results and Discussion: The central claim that acceptability is governed by context-sensitive norms (rather than content alone) rests on self-reported reactions from a small, self-selected sample of users who volunteered to share histories and interact with a tool explicitly framed as a 'reflective' opportunity. This risks selection bias and demand effects that could inflate curiosity while understating privacy concerns; without comparison conditions, larger N, or evidence that reactions generalize beyond the tool-mediated setting, the distinction between content-based and norm-based acceptability is not yet load-bearing.
minor comments (2)
- [Abstract] The abstract states that 215 inferences were evaluated but provides no breakdown of how they were sampled or categorized from the histories, which would clarify the diversity of cases supporting the misrepresentative/misaligned discomfort finding.
- [Introduction] Consider citing foundational work on contextual integrity (Nissenbaum) or related HCI privacy norm studies to better anchor the 'context-sensitive norms' framing in the introduction or discussion.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments highlight important areas for improving methodological transparency and the framing of our claims. We address each point below and will revise the manuscript to strengthen these aspects while preserving the exploratory nature of the study.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The description of the 18-participant mixed-methods study supplies no details on recruitment procedures, screening criteria, exact tool usage protocol, interview or survey instruments, or analysis methods (qualitative coding or any statistical tests). This omission prevents assessment of whether the observed curiosity-dominant reactions and the resulting claim about context-sensitive norms are robust or influenced by unaddressed confounds.
Authors: We agree that the Methods section requires substantially more detail for reproducibility and to allow readers to evaluate potential confounds. In the revised manuscript, we will expand the Methods section with: (1) recruitment procedures (e.g., channels used to reach regular ChatGPT users), (2) screening criteria (e.g., minimum number of conversations and self-reported usage frequency), (3) the precise protocol for Reflective Layer tool interaction, (4) the full interview guide and survey instruments used to capture reactions and comfort ratings, and (5) the qualitative analysis procedure (thematic coding process, including how codes were developed and applied). We will also report any quantitative analyses performed on the Likert-scale ratings. These additions will directly address the concern about assessing robustness. revision: yes
-
Referee: [Results and Discussion] Results and Discussion: The central claim that acceptability is governed by context-sensitive norms (rather than content alone) rests on self-reported reactions from a small, self-selected sample of users who volunteered to share histories and interact with a tool explicitly framed as a 'reflective' opportunity. This risks selection bias and demand effects that could inflate curiosity while understating privacy concerns; without comparison conditions, larger N, or evidence that reactions generalize beyond the tool-mediated setting, the distinction between content-based and norm-based acceptability is not yet load-bearing.
Authors: We acknowledge that the sample size and self-selected nature introduce limitations, including potential selection bias toward users comfortable sharing histories and possible demand effects from the reflective framing. The study is explicitly exploratory and mixed-methods, intended to generate hypotheses rather than provide definitive causal claims. In the revision, we will add a dedicated Limitations subsection in the Discussion that explicitly discusses selection bias, demand characteristics, the tool-mediated setting, and the absence of comparison conditions. We will reframe the central claim more cautiously as 'suggestive evidence' that acceptability depends on context-sensitive norms, supported by the pattern that discomfort was linked to perceived misalignment rather than inference content per se. We will also propose future work with larger, more diverse samples and controlled designs. While we cannot retroactively enlarge the sample or add new conditions, these changes will make the evidential basis clearer and prevent overstatement. revision: partial
Circularity Check
No circularity: empirical user study with no derivations or self-referential reductions
full rationale
This is a mixed-methods HCI user study (18 participants, 215 inferences) that reports qualitative reactions and preferences. The paper contains no equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations that reduce the central claim to its own data by construction. The acceptability findings are presented as direct observations from the Reflective Layer tool sessions and interviews; they do not invoke uniqueness theorems, ansatzes, or renamings of prior results. The derivation chain is therefore self-contained and non-circular by the criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reported reactions from study participants accurately reflect their genuine feelings and preferences without significant social desirability bias.
- domain assumption The Reflective Layer tool surfaces inferences that are representative of what an LLM would actually infer from the conversation history.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean (and Cost/FunctionalEquation.lean)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We built the Reflective Layer, a visualization tool that surfaces example unstated inferences from users' own ChatGPT histories, and used it in a mixed-methods study with 18 regular ChatGPT users evaluating 215 surfaced inferences
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Participants were also markedly less comfortable with advertisers and third-party applications using those inferences than with platform providers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. Introducing the Model Context Protocol. https://www.anthropic. com/news/model-context-protocol
work page 2024
-
[2]
Anthropic. 2025. Bringing memory to Claude. https://www.anthropic.com/news/ memory. Accessed: April 29, 2026
work page 2025
-
[3]
I know even if you don’t tell me
Sumit Asthana, Jane Im, Zhe Chen, and Nikola Banovic. 2024. " I know even if you don’t tell me": Understanding Users’ Privacy Preferences Regarding AI-based Inferences of Sensitive Information for Personalization. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–21
work page 2024
-
[4]
Natã M Barbosa, Gang Wang, Blase Ur, and Yang Wang. 2021. Who am I? A design probe exploring real-time transparency about online and offline user profiling underlying targeted ads.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies5, 3 (2021), 1–32
work page 2021
-
[5]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology3, 2 (2006), 77–101
work page 2006
-
[6]
Peter Brusilovsky and Eva Millán. 2007. User models for adaptive hypermedia and adaptive educational systems. InThe adaptive web: methods and strategies of web personalization. Springer, 3–53
work page 2007
-
[7]
Moritz Büchi, Eduard Fosch-Villaronga, Christoph Lutz, Aurelia Tamò-Larrieux, and Shruthi Velidi. 2023. Making sense of algorithmic profiling: user perceptions on Facebook.Information, Communication & Society26, 4 (2023), 809–825
work page 2023
-
[8]
Kelly Caine. 2016. Local standards for sample size at CHI. InProceedings of the 2016 CHI conference on human factors in computing systems. 981–992
work page 2016
-
[9]
Cheng Chen, Maria D Molina, Mengqi Liao, and Eugene Cho Snyder. 2026. Re- lational Gains, Privacy Strains: Exploring Users’ Perceptions and Experiences with ChatGPT’s Memory Feature. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–17
work page 2026
-
[10]
2000.Neo Personality Inventory.American Psychological Association
Paul T Costa Jr and Robert R McCrae. 2000.Neo Personality Inventory.American Psychological Association
work page 2000
-
[11]
Steven Englehardt and Arvind Narayanan. 2016. Online tracking: A 1-million-site measurement and analysis. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security. 1388–1401
work page 2016
- [12]
-
[13]
Florian M Farke, David G Balash, Maximilian Golla, Markus Dürmuth, and Adam J Aviv. 2021. Are privacy dashboards good for end users? Evaluating user percep- tions and reactions to Google’s My Activity. In30th USENIX Security Symposium (USENIX Security 21). 483–500
work page 2021
-
[14]
Jillian Fisher, Jennifer Neville, and Chan Young Park. 2026. Response-Aware User Memory Selection for LLM Personalization.arXiv preprint arXiv:2604.14473 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Alejandra Gómez Ortega, Jacky Bourgeois, and Gerd Kortuem. 2023. What is sensitive about (sensitive) data? Characterizing sensitivity and intimacy with Google assistant users. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–16
work page 2023
- [16]
-
[17]
Thomas Groß. 2021. Validity and reliability of the scale internet users’ information privacy concerns (iuipc).Proceedings on Privacy Enhancing Technologies(2021)
work page 2021
-
[18]
Greg Guest, Arwen Bunce, and Laura Johnson. 2006. How many interviews are enough? An experiment with data saturation and variability.Field methods18, 1 (2006), 59–82
work page 2006
-
[19]
Samantha Hautea, Anjali Munasinghe, and Emilee Rader. 2020. ’That’s Not Me’: Surprising Algorithmic Inferences. InExtended abstracts of the 2020 CHI conference on human factors in computing systems. 1–7
work page 2020
-
[20]
Weijia He, Maximilian Golla, Roshni Padhi, Jordan Ofek, Markus Dürmuth, Ear- lence Fernandes, and Blase Ur. 2018. Rethinking Access Control and Authentica- tion for the Home Internet of Things ({ { { { {IoT} } } } }). In27th USENIX Security Symposium (USENIX Security 18). 255–272
work page 2018
-
[21]
Monique M Hennink, Bonnie N Kaiser, and Vincent C Marconi. 2017. Code satu- ration versus meaning saturation: how many interviews are enough?Qualitative health research27, 4 (2017), 591–608
work page 2017
-
[22]
Cormac Herley. 2009. So long, and no thanks for the externalities: the rational rejection of security advice by users. InProceedings of the 2009 workshop on New security paradigms workshop. 133–144
work page 2009
-
[23]
Jane Im, Ruiyi Wang, Weikun Lyu, Nick Cook, Hana Habib, Lorrie Faith Cranor, Nikola Banovic, and Florian Schaub. 2023. Less is not more: Improving findabil- ity and actionability of privacy controls for online behavioral advertising. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–33
work page 2023
-
[24]
Bailey Kacsmar, Vasisht Duddu, Kyle Tilbury, Blase Ur, and Florian Kerschbaum
-
[25]
InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security
Comprehension from chaos: Towards informed consent for private com- putation. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 210–224
work page 2023
-
[26]
My} data just goes {Everywhere:
Ruogu Kang, Laura Dabbish, Nathaniel Fruchter, and Sara Kiesler. 2015. {“My} data just goes {Everywhere:”} user mental models of the internet and impli- cations for privacy and security. InEleventh symposium on usable privacy and security (SOUPS 2015). 39–52
work page 2015
-
[27]
Alfred Kobsa. 2007. Generic user modeling systems.The adaptive web: Methods and strategies of web personalization(2007), 136–154
work page 2007
-
[28]
Kirill Kronhardt, Sebastian Hoffmann, Fabian Adelt, Max Pascher, and Jens Gerken. 2025. All of That in 15 Minutes? Exploring Privacy Perceptions Across Cognitive Abilities via Ad-hoc LLM-Generated Profiles Inferred from Social Media Use. InProceedings of the 27th International Conference on Multimodal Interaction. 164–172
work page 2025
-
[29]
Michelle S Lam, Omar Shaikh, Hallie Xu, Alice Guo, Diyi Yang, Jeffrey Heer, James A Landay, and Michael S Bernstein. 2026. Just-In-Time Objectives: A General Approach for Specialized AI Interactions. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–26
work page 2026
- [30]
-
[31]
Hao-Ping Lee, Yu-Ju Yang, Thomas Serban Von Davier, Jodi Forlizzi, and Sauvik Das. 2024. Deepfakes, phrenology, surveillance, and more! a taxonomy of ai privacy risks. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–19
work page 2024
-
[32]
Hao-Ping Hank Lee, Jacob Logas, Stephanie Yang, Zhouyu Li, Nata Barbosa, Yang Wang, and Sauvik Das. 2023. When and why do people want ad targeting explanations? Evidence from a four-week, mixed-methods field study. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2903–2920
work page 2023
-
[33]
Pedro Giovanni Leon, Blase Ur, Yang Wang, Manya Sleeper, Rebecca Balebako, Richard Shay, Lujo Bauer, Mihai Christodorescu, and Lorrie Faith Cranor. 2013. What matters to users? Factors that affect users’ willingness to share information with online advertisers. InProceedings of the ninth symposium on usable privacy and security. 1–12
work page 2013
-
[34]
Henry Lieberman et al. 1995. Letizia: An agent that assists web browsing.IJCAI (1)1995 (1995), 924–929
work page 1995
-
[35]
Pattie Maes and Robyn Kozierok. 1993. Learning interface agents. InAAAI, Vol. 93. 459–465
work page 1993
-
[36]
Naresh K Malhotra, Sung S Kim, and James Agarwal. 2004. Internet users’ information privacy concerns (IUIPC): The construct, the scale, and a causal model.Information systems research15, 4 (2004), 336–355
work page 2004
-
[37]
Lisa Mekioussa Malki. 2026. Towards Usable, Privacy Respecting Long-Term Memory for LLM-based Conversational Agents. InProceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems. 1–5
work page 2026
- [38]
- [39]
- [40]
-
[41]
Niloofar Mireshghallah, Neal Mangaokar, Narine Kokhlikyan, Arman Zhar- magambetov, Manzil Zaheer, Saeed Mahloujifar, and Kamalika Chaudhuri. 2025. Cimemories: A compositional benchmark for contextual integrity of persistent memory in llms.arXiv preprint arXiv:2511.14937(2025). Preprint, ,
-
[42]
Pardis Emami Naeini, Sruti Bhagavatula, Hana Habib, Martin Degeling, Lujo Bauer, Lorrie Faith Cranor, and Norman Sadeh. 2017. Privacy expectations and preferences in an {IoT} world. InThirteenth symposium on usable privacy and security (SOUPS 2017). 399–412
work page 2017
-
[43]
Helen Nissenbaum. 2004. Privacy as contextual integrity.Wash. L. Rev.79 (2004), 119
work page 2004
-
[44]
OpenAI. 2025. New tools and features in the Responses API. https://openai.com/ index/new-tools-and-features-in-the-responses-api/
work page 2025
- [45]
-
[46]
OpenAI. 2026. Our approach to advertising and expanding access to Chat- GPT. https://openai.com/index/our-approach-to-advertising-and-expanding- access/
work page 2026
-
[47]
OpenClaw. 2026. OpenClaw: Open-source autonomous AI agent framework. https://docs.openclaw.ai/
work page 2026
- [48]
-
[49]
Robert W Reeder, Clare-Marie Karat, John Karat, and Carolyn Brodie. 2007. Usability challenges in security and privacy policy-authoring interfaces. InIFIP Conference on Human-Computer Interaction. Springer, 141–155
work page 2007
-
[50]
Nathan Reitinger, Bruce Wen, Michelle L Mazurek, and Blase Ur. 2024. What does it mean to be creepy? Responses to visualizations of personal browsing activity, online tracking, and targeted ads.Proceedings on Privacy Enhancing Technologies 2024, 3 (2024)
work page 2024
-
[51]
Florian Schaub, Aditya Marella, Pranshu Kalvani, Blase Ur, Chao Pan, Emily Forney, and Lorrie Faith Cranor. 2016. Watching them watching me: Browser extensions’ impact on user privacy awareness and concern. InNDSS workshop on usable security, Vol. 10
work page 2016
-
[52]
Omar Shaikh, Shardul Sapkota, Shan Rizvi, Eric Horvitz, Joon Sung Park, Diyi Yang, and Michael S Bernstein. 2025. Creating general user models from computer use. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–23
work page 2025
- [53]
-
[54]
Ben Shneiderman and Pattie Maes. 1997. Direct manipulation vs. interface agents. interactions4, 6 (1997), 42–61
work page 1997
- [55]
- [56]
-
[57]
Henri Tajfel, John Turner, William G Austin, Stephen Worchel, et al. 2001. An integrative theory of intergroup conflict.Intergroup relations: Essential readings (2001), 94–109
work page 2001
- [58]
-
[59]
Edmund R Thompson. 2007. Development and validation of an internationally reliable short-form of the positive and negative affect schedule (PANAS).Journal of cross-cultural psychology38, 2 (2007), 227–242
work page 2007
-
[60]
Batuhan Tömekçe, Mark Vero, Robin Staab, and Martin Vechev. 2024. Private attribute inference from images with vision-language models.Advances in Neural Information Processing Systems37 (2024), 103619–103651
work page 2024
-
[61]
Sarah Tran, Hongfan Lu, Isaac Slaughter, Bernease Herman, Aayushi Dangol, Yue Fu, Lufei Chen, Biniyam Gebreyohannes, Bill Howe, Alexis Hiniker, et al
-
[62]
InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol
Understanding Privacy Norms Around LLM-Based Chatbots: A Contextual Integrity Perspective. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 8. 2522–2534
-
[63]
Blase Ur, Pedro Giovanni Leon, Lorrie Faith Cranor, Richard Shay, and Yang Wang
-
[64]
Inproceedings of the eighth symposium on usable privacy and security
Smart, useful, scary, creepy: perceptions of online behavioral advertising. Inproceedings of the eighth symposium on usable privacy and security. 1–15
- [65]
-
[66]
I regretted the minute I pressed share
Yang Wang, Gregory Norcie, Saranga Komanduri, Alessandro Acquisti, Pedro Gio- vanni Leon, and Lorrie Faith Cranor. 2011. “I regretted the minute I pressed share”: A qualitative study of regrets on Facebook. InProceedings of the seventh symposium on usable privacy and security. 1–16
work page 2011
-
[67]
Ben Weinshel, Miranda Wei, Mainack Mondal, Euirim Choi, Shawn Shan, Claire Dolin, Michelle L Mazurek, and Blase Ur. 2019. Oh, the places you’ve been! User reactions to longitudinal transparency about third-party web tracking and inferencing. InProceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. 149–166
work page 2019
-
[68]
Wendy Wood and David T Neal. 2007. A new look at habits and the habit-goal interface.Psychological review114, 4 (2007), 843
work page 2007
-
[69]
Bin Wu, Zhengyan Shi, Hossein A Rahmani, Varsha Ramineni, and Emine Yilmaz
- [70]
-
[71]
Yuxi Wu, Jacob Logas, Devansh Jatin Ponda, Julia Haines, Jiaming Li, Jeffrey Nichols, W Keith Edwards, and Sauvik Das. 2025. Modeling End-User Affective Discomfort With Mobile App Permissions Across Physical Contexts. (2025)
work page 2025
-
[72]
Yue Xu, Qi’an Chen, Zizhan Ma, Dongrui Liu, Wenxuan Wang, Xiting Wang, Li Xiong, and Wenjie Wang. 2026. Toward Personalized LLM-Powered Agents: Foundations, Evaluation, and Future Directions.Comput. Surveys(2026)
work page 2026
-
[73]
Yaxing Yao, Davide Lo Re, and Yang Wang. 2017. Folk models of online behavioral advertising. InProceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing. 1957–1969
work page 2017
-
[74]
Bhada Yun, Renn Su, and April Yi Wang. 2026. AI and My Values: User Perceptions of LLMs’ Ability to Extract, Embody, and Explain Human Values from Casual Conversations. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–38
work page 2026
-
[75]
Shuning Zhang, Rongjun Ma, Ying Ma, Shixuan Li, Yiqun Xu, Xin Yi, and Hewu Li. 2025. Understanding Users’ Privacy Perceptions Towards LLM’s RAG-based Memory. InProceedings of the 2025 Workshop on Human-Centered AI Privacy and Security. 10–19
work page 2025
-
[76]
Shuning Zhang, Lyumanshan Ye, Xin Yi, Jingyu Tang, Bo Shui, Haobin Xing, Pengfei Liu, and Hewu Li. 2024. "Ghost of the past": identifying and resolving privacy leakage from LLM’s memory through proactive user interaction.arXiv preprint arXiv:2410.14931(2024)
- [77]
-
[78]
Zhiping Zhang, Michelle Jia, Hao-Ping Lee, Bingsheng Yao, Sauvik Das, Ada Lerner, Dakuo Wang, and Tianshi Li. 2024. “It’s a Fair Game”, or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–26
work page 2024
-
[79]
Works as a software engineer at Google,
Jijie Zhou, Eryue Xu, Yaoyao Wu, and Tianshi Li. 2025. Rescriber: Smaller-LLM- powered user-led data minimization for LLM-based chatbots. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–28. Open Science We provide an anonymous repository for double-blind review con- taining the artifacts needed to evaluate the Reflective ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.