Recognition: 2 theorem links
· Lean TheoremDifferentially Private Sampling from Distributions via Wasserstein Projection
Pith reviewed 2026-05-12 03:34 UTC · model grok-4.3
The pith
Wasserstein projection yields a minimax optimal mechanism for differentially private sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Wasserstein Projection Mechanism, obtained by projecting the original distribution onto the set of distributions satisfying the differential privacy constraint in the Wasserstein metric, is minimax optimal for the sampling problem, and that this projection can be computed approximately via efficient algorithms with convergence guarantees.
What carries the argument
The Wasserstein Projection Mechanism, which finds the distribution in the privacy-constrained set that is closest to the target distribution under the Wasserstein distance.
Load-bearing premise
That the Wasserstein distance serves as an appropriate and superior measure of utility for private samples compared to density-ratio measures, particularly when geometry or support differences are relevant.
What would settle it
Finding a dataset or distribution where samples from the Wasserstein Projection Mechanism are demonstrably less useful for downstream tasks than those from a KL-based mechanism, or where the approximation algorithm diverges.
Figures
read the original abstract
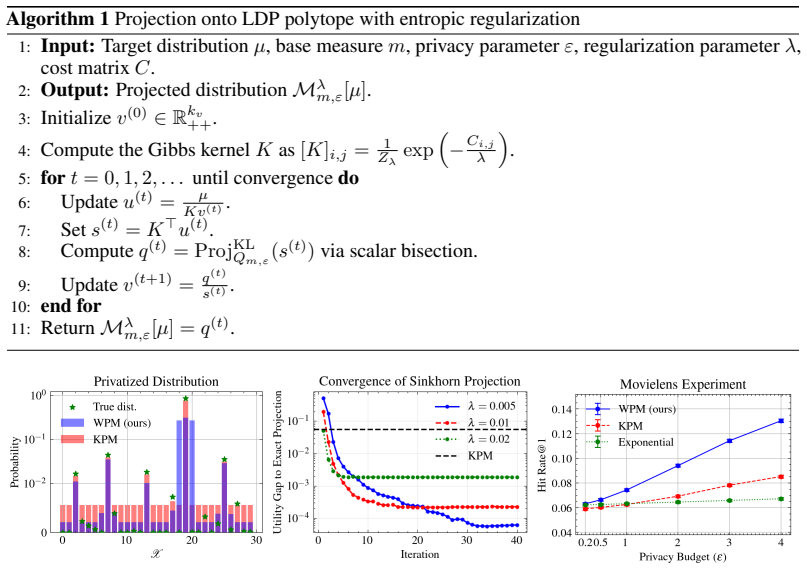
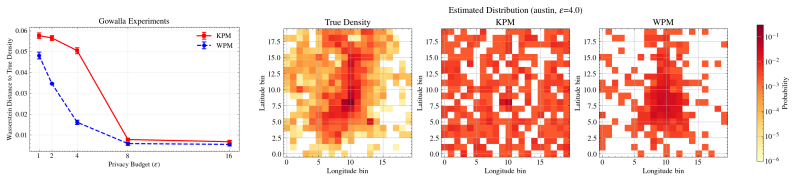
In this paper, we study the problem of sampling from a distribution under the constraint of differential privacy (DP). Prior works measure the utility of DP sampling with density ratio-based measures such as KL divergence. However, such formulations suffer from two key limitations: 1) they fail to capture the geometric structure of the support, and 2) they are not applicable when the supports of the distributions differ. To deal with these issues, we develop a novel framework for DP sampling with Wasserstein distance as the utility measure. In this formulation, we propose Wasserstein Projection Mechanism (WPM), a minimax optimal mechanism based on Wasserstein projection. Furthermore, we develop efficient algorithms for computing the proposed mechanisms approximately and provide convergence guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a framework for differentially private sampling from distributions that uses Wasserstein distance as the utility measure instead of density-ratio measures such as KL divergence. It introduces the Wasserstein Projection Mechanism (WPM) as a minimax-optimal mechanism obtained by projecting onto the set of DP-feasible distributions, develops efficient approximation algorithms for computing the mechanism, and supplies convergence guarantees for those algorithms. The approach is motivated by the inability of prior KL-based methods to capture geometric structure or to handle mismatched supports.
Significance. If the minimax optimality and convergence results hold, the work supplies a geometrically aware DP sampling primitive that directly addresses two well-known limitations of existing mechanisms. The explicit construction of tractable algorithms together with convergence guarantees is a concrete strength that improves the prospects for practical deployment in settings where Wasserstein geometry is natural (e.g., generative modeling or distribution learning under privacy constraints).
minor comments (3)
- [§3.2] §3.2, Definition 3.1: the precise statement of the Wasserstein projection optimization problem would benefit from an explicit display of the feasible set and the objective; the current prose description leaves the exact program implicit.
- [Theorem 4.3] Theorem 4.3: the convergence guarantee is stated in terms of iteration count, but the dependence on ambient dimension and on the Lipschitz constant of the cost function is not made explicit; this information is needed to assess scalability.
- [§6] §6 (Experiments): the reported results are confined to low-dimensional synthetic distributions; a brief discussion of how the observed error scales with dimension or with the privacy parameter ε would strengthen the empirical section.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our manuscript and for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a Wasserstein-based utility for DP sampling to address limitations of KL divergence, proposes the WPM as a minimax-optimal mechanism via projection onto the DP-feasible set, and derives approximate algorithms with convergence guarantees. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the framework is built from standard DP and optimal transport primitives without internal tautology. The central optimality and algorithmic claims remain independent of the inputs they are applied to.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard definition of differential privacy (epsilon-DP)
- standard math Wasserstein distance is a valid metric on probability measures
invented entities (1)
-
Wasserstein Projection Mechanism (WPM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWasserstein Projection Mechanism (WPM) ... arg min_{ν∈Q_{m,ε}} W_p(ν, μ) ... minimax optimal ... entropic regularization and alternating projections ... linear convergence guarantees
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearLDP polytope Q_{m,ε} ... base measure m ... convex optimization reformulation f(m) = max_i ϕ_i(m)
Reference graph
Works this paper leans on
-
[1]
Konstantinos Chatzikokolakis, Catuscia Palamidessi, and Marco Stronati. Constructing elastic distinguishability metrics for location privacy.arXiv preprint arXiv:1503.00756,
-
[2]
Rappor: Randomized aggregatable privacy- preserving ordinal response
Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova. Rappor: Randomized aggregatable privacy- preserving ordinal response. InProceedings of the 2014 ACM SIGSAC conference on computer and communications security, pages 1054–1067,
work page 2014
-
[3]
Locally optimal private sampling: Beyond the global minimax.arXiv preprint arXiv:2510.09485,
Hrad Ghoukasian, Bonwoo Lee, and Shahab Asoodeh. Locally optimal private sampling: Beyond the global minimax.arXiv preprint arXiv:2510.09485,
-
[4]
Differentially private wasserstein barycenters.arXiv preprint arXiv:2510.03021,
Anming Gu, Sasidhar Kunapuli, Mark Bun, Edward Chien, and Kristjan Greenewald. Differentially private wasserstein barycenters.arXiv preprint arXiv:2510.03021,
-
[5]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representa- tions in vector space.arXiv preprint arXiv:1301.3781,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Learning with differentially private (sliced) wasserstein gradients.arXiv preprint arXiv:2502.01701,
David Rodríguez-Vítores, Clément Lalanne, and Jean-Michel Loubes. Learning with differentially private (sliced) wasserstein gradients.arXiv preprint arXiv:2502.01701,
-
[7]
InvisibleInk: High-Utility and Low-Cost Text Generation with Differential Privacy
Vishnu Vinod, Krishna Pillutla, and Abhradeep Guha Thakurta. Invisibleink: High-utility and low-cost text generation with differential privacy.arXiv preprint arXiv:2507.02974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Then f( ¯mT )−f(m ∗)≤ βDp α r 2(1 + logk) T =O β α Dp r logk T !
Choose a constant stepsize ηt ≡η:= p 2(1 + logk) βDp √ T . Then f( ¯mT )−f(m ∗)≤ βDp α r 2(1 + logk) T =O β α Dp r logk T ! . Proof. By construction, g(t) ∈∂f(m (t)) for every t. By the regret bound for the unnormalized exponentiated gradient algorithm [Shalev-Shwartz, 2025, Theorem 2.23], for anym∈ M, TX t=1 ⟨g(t), m(t) −m⟩ ≤ DgKL(m∥m(1)) η + η 2 TX t=1 ...
work page 2025
-
[9]
Moreover, the mapp7→α ∗(p)is decreasing
d−2 2 , C d = Γ((d+ 1)/2)√πΓ(d/2) , gp(u) = (2−2u) p/2, S d(t) = Z 1 t fd(u) du, Ud,p(t) = Z 1 t gp(u)fd(u) du, H d,p = Z 1 −1 gp(u)fd(u) du, andt ∗ ∈(−1,1)is the unique solution of eε/2 −e −ε/2 Ud,p(t∗) +e −ε/2Hd,p =g p(t∗) e−ε/2 + eε/2 −e −ε/2 Sd(t∗) . Moreover, the mapp7→α ∗(p)is decreasing. The optimal mechanism Mm∗,ε can be interpreted as a generaliz...
work page 2022
-
[10]
Define Mp(t) := Z 1 −1 r(u)p µt(du) 1/p , F p(t) :=M p(t)−r(t)
Its defining equation is equivalent to Z 1 −1 gp(u)µ t∗(p)(du) =g p(t∗(p)), equivalently, Z 1 −1 r(u)p µt∗(p)(du) 1/p =r t∗(p) . Define Mp(t) := Z 1 −1 r(u)p µt(du) 1/p , F p(t) :=M p(t)−r(t). Thent ∗(p)is the unique zero ofF p. Fix t∈(−1,1) . Since c± >0 , fd(u)>0 for u∈(−1,1) , and Z(t)>0 , µt has positive density on (−1,1). Asris positive and nonconsta...
work page 1993
-
[11]
Therefore, X i,j Cijπij −λlogN≤ X i,j Cijπij +λ X i,j πij logπ ij ≤ X i,j Cijπij. Taking the minimum overπ∈Π(ν, µ)yields, for everyν, OT(ν, µ)−λlogN≤OT λ(ν, µ)≤OT(ν, µ).(3) Let ν∗ ∈arg min ν∈Q Wp(ν, µ), ν λ :=M λ m,ε[µ]. Sincex7→x 1/p is strictly increasing onR +, we also have ν∗ ∈arg min ν∈Q OT(ν, µ). By definition ofM λ m,ε[µ], νλ ∈arg min ν∈Q OTλ(ν, µ)...
work page 1957
-
[12]
We observe that WPM captures the true distribution more accurately than KPM, which demonstrates the advantage of WPM in preserving the geometric structure of the data. N Experimental Details DatasetsMovielens-100K [Harper and Konstan, 2015] contains 100,000 ratings from 1000 users on 1700 movies, which is distributed under a usage license that permits res...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.